Command Palette
Search for a command to run...
VoxCPM: 文脈適応型音声生成および忠実なボイスクローニングのためのTokenizer-Free TTS
VoxCPM: 文脈適応型音声生成および忠実なボイスクローニングのためのTokenizer-Free TTS
VoxCPM Team
概要
音声合成における生成モデルは、根本的なトレードオフに直面しています。具体的には、離散的なtokenは安定性を確保できる一方で表現力に欠け、連続的な信号は音響的な豊かさを保持できるものの、タスクの絡み合い(task entanglement)による誤差の累積が課題となります。この課題を解決するために、事前学習済みの音声tokenizerに依存する多段階のpipelineが主流となってきましたが、これらは意味的表現と音響的表現の乖離(semantic-acoustic divide)を生じさせ、包括的かつ表現力豊かな音声生成を制限しています。本研究では、半離散的な残留表現(semi-discrete residual representations)を用いた階層的な意味・音響モデリング(hierarchical semantic-acoustic modeling)を通じてこのジレンマを解消し、新しいtokenizer-freeなTTSモデルである「VoxCPM」を提案します。本フレームワークは、自然な役割分担を誘発する微分可能な量子化ボトルネック(differentiable quantization bottleneck)を導入しています。具体的には、Text-Semantic Language Model (TSLM) が意味的・韻律的なプランを生成し、Residual Acoustic Model (RALM) が微細な音響詳細を復元します。この階層的な意味・音響表現が、局所的なdiffusionベースのdecoderをガイドすることで、高忠実度な音声latentsの生成を可能にします。極めて重要な点として、アーキテクチャ全体が単純なdiffusion objectiveの下でend-to-endで学習されるため、外部の音声tokenizerへの依存を排除しています。180万時間に及ぶ大規模なバイリンガルコーパスで学習されたVoxCPM-0.5Bモデルは、オープンソースのシステムの中で最先端(state-of-the-art)のzero-shot TTS性能を達成しており、提案手法が表現力豊かで安定した合成を実現できることを示しています。さらに、VoxCPMはテキストを理解して適切な韻律(prosody)やスタイルを推論・生成する能力を備えており、文脈に応じた表現力と自然な流れを持つ音声を生成します。コミュニティ主導の研究開発を促進するため、VoxCPMはApache 2.0ライセンスの下で公開されています。
One-sentence Summary
The VoxCPM Team proposes VoxCPM, a tokenizer-free text-to-speech framework that utilizes hierarchical semantic-acoustic modeling with semi-discrete residual representations and a differentiable quantization bottleneck to achieve state-of-the-art zero-shot performance in context-aware speech generation and voice cloning through end-to-end diffusion training.
Key Contributions
- The paper introduces VoxCPM, a novel tokenizer-free text-to-speech model that utilizes a unified end-to-end framework to resolve the trade-off between speech expressivity and stability.
- This work presents a hierarchical semantic-acoustic modeling approach featuring a differentiable quantization bottleneck that separates information into a discrete-like skeleton for content stability and continuous residual components for acoustic detail.
- Experiments conducted on a 1.8 million hour bilingual corpus demonstrate that the model achieves state-of-the-art zero-shot TTS performance among open-source systems in terms of intelligibility and speaker similarity.
Introduction
Modern text-to-speech (TTS) systems strive to balance acoustic richness with linguistic stability, a task critical for developing empathetic virtual assistants and immersive digital avatars. Current discrete token-based methods ensure stability but suffer from a quantization ceiling that discards fine-grained acoustic details, while continuous representation models preserve fidelity but often struggle with error accumulation and task entanglement. The authors leverage a hierarchical semantic-acoustic modeling framework to resolve this trade-off through a tokenizer-free, end-to-end architecture. By introducing a differentiable quantization bottleneck, VoxCPM induces a natural specialization where a Text-Semantic Language Model handles prosodic planning and a Residual Acoustic Model recovers fine-grained details.
Method
The authors propose VoxCPM, a hierarchical autoregressive architecture designed to generate sequences of continuous speech latents Z={z1,...,zM} conditioned on input text tokens T={t1,...,tN}. In this framework, each zi∈RP×D represents a patch of P frames containing D-dimensional VAE latent vectors. The generation process is formulated as:
\np(Z∣T)=∏i=1Mp(zi∣T,Z<i)
The core of the system is a hierarchical conditioning mechanism that separates semantic-prosodic planning from fine-grained acoustic synthesis. Refer to the framework diagram:
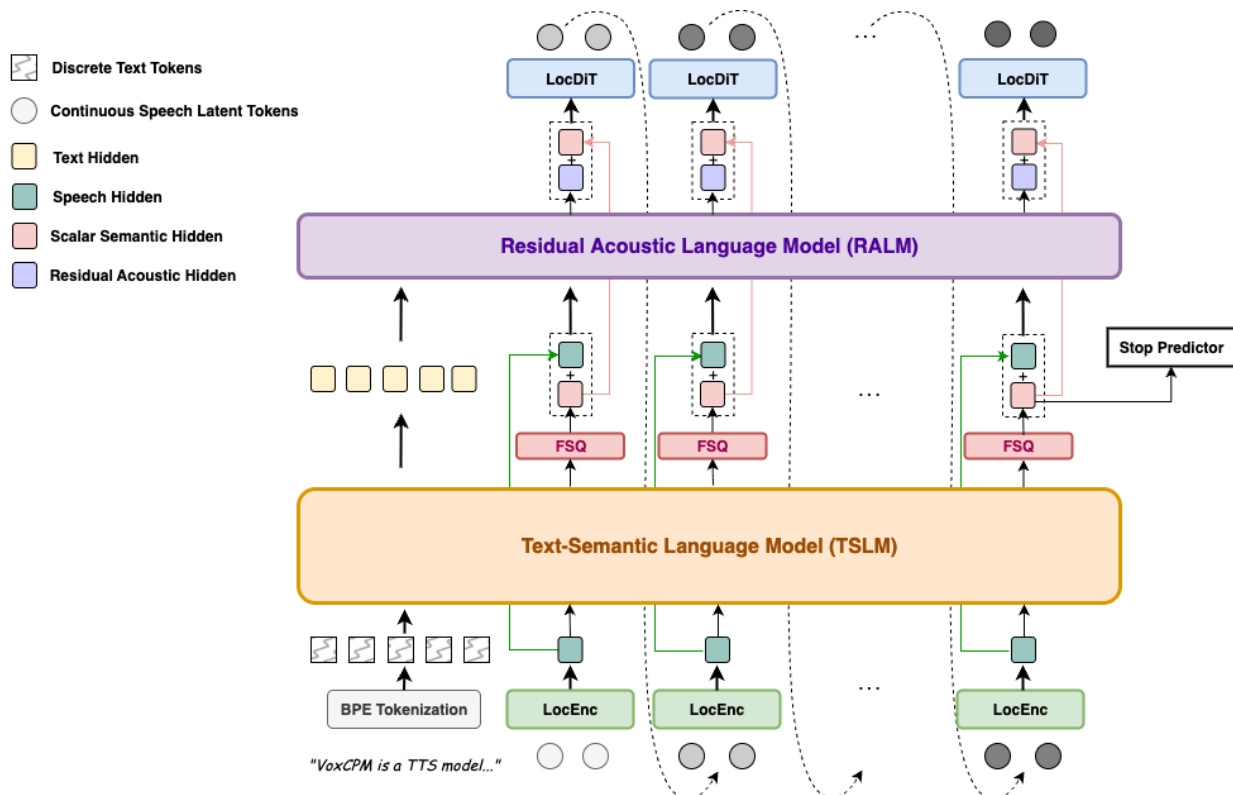
The architecture consists of four primary modules: a local audio encoder (LocEnc), a text-semantic language model (TSLM), a residual acoustic language model (RALM), and a local diffusion transformer decoder (LocDiT).
The process begins with the LocEnc, which compresses historical VAE latent patches into compact acoustic embeddings E<i=LocEnc(Z<i). These embeddings, along with the text tokens, are processed by the TSLM. The TSLM utilizes a pre-trained text language model as its backbone to capture high-level linguistic structures and prosodic patterns. To ensure a stable generation process, the TSLM's continuous hidden states are projected onto a structured lattice via a Finite Scalar Quantization (FSQ) layer. This FSQ operation produces a semi-discrete representation, defined as:
hi,jFSQ=Δ⋅clip(round(ΔhTSLM),−L,L)
where Δ is the quantization step size and L is the clipping range. This FSQ layer acts as a bottleneck that captures a coarse semantic-prosodic skeleton.
To recover the acoustic details lost during quantization, the RALM is employed. It reconstructs subtle vocal characteristics by conditioning on the TSLM hidden states, the semi-discrete FSQ representations, and the historical acoustic embeddings:
hiresidual=RALM(HtextTSLM,H<iFSQ⊕E<i)
The final conditioning signal hifinal is the sum of the stable semantic skeleton and the residual acoustic details:
zi∼LocDiT(hifinal),hifinal=stable skeletonFSQ(TSLM(T,E<i))+residual detailsRALM(⋅)
This signal guides the LocDiT, a bidirectional Transformer that performs a denoising diffusion process to generate the current latent patch zi. To improve consistency, the previous patch zi−1 is included as additional context.
The model is trained end-to-end using a conditional flow-matching objective to optimize the quality of the speech latents:
LFM=Et,zi0,ϵ[∣vθ(zit,t,hifinal,zi−1)−dtd(αtzi0+σtϵ)∣2]
Additionally, a stop predictor is trained using a binary cross-entropy loss to determine the endpoint of the speech sequence. This unified training approach ensures that the TSLM, FSQ, RALM, and LocDiT are all optimized toward coherent and high-fidelity speech synthesis.
Experiment
The experiments evaluate VoxCPM through comprehensive objective and subjective benchmarks, including SEED-TTS-EVAL and CV3-EVAL, to validate its performance against state-of-the-art open-source TTS systems. Results demonstrate that the hierarchical architecture effectively disentangles semantic planning from acoustic rendering, achieving superior intelligibility and speaker similarity through its semi-discrete bottleneck and residual acoustic modeling. Ablation studies and visual analyses further confirm that the model's design promotes stable learning, efficient data utilization, and context-aware prosody generation.
The authors conduct a subjective evaluation comparing VoxCPM and its variants against several state-of-the-art models. Results show that VoxCPM achieves high scores in both naturalness and speaker similarity across Chinese and English languages. VoxCPM achieves superior speaker similarity in both Chinese and English compared to the evaluated baselines In Chinese evaluations, VoxCPM shows high naturalness scores, though it trails IndexTTS 2 in this specific metric The VoxCPM-Emilia variant maintains competitive performance levels despite being trained on a smaller dataset
The authors compare different training phases and model variants using a two-phase Warmup-Stable-Decay learning rate schedule. The training configurations vary by model type, total iterations, and hardware resources used. The VoxCPM model undergoes a longer training process compared to the Emilia variant and the ablation model. The decay phase utilizes a larger batch size in terms of tokens compared to the stable phase. Training for the VoxCPM model requires more GPU resources than the other configurations shown.

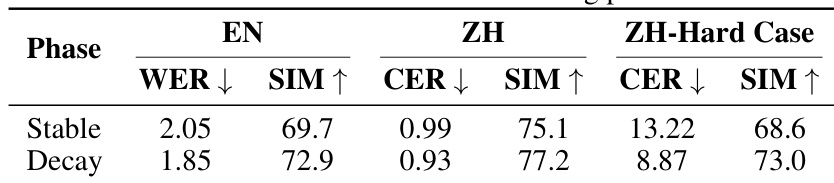
The authors evaluate the impact of a two-phase Warmup-Stable-Decay learning rate schedule on model performance. Results show that transitioning from the stable phase to the decay phase leads to consistent improvements across all measured metrics for both English and Chinese. The decay phase reduces error rates in both English and Chinese compared to the stable phase Speaker similarity scores improve across all tested languages during the decay phase The model demonstrates enhanced robustness on challenging Chinese cases following the decay phase
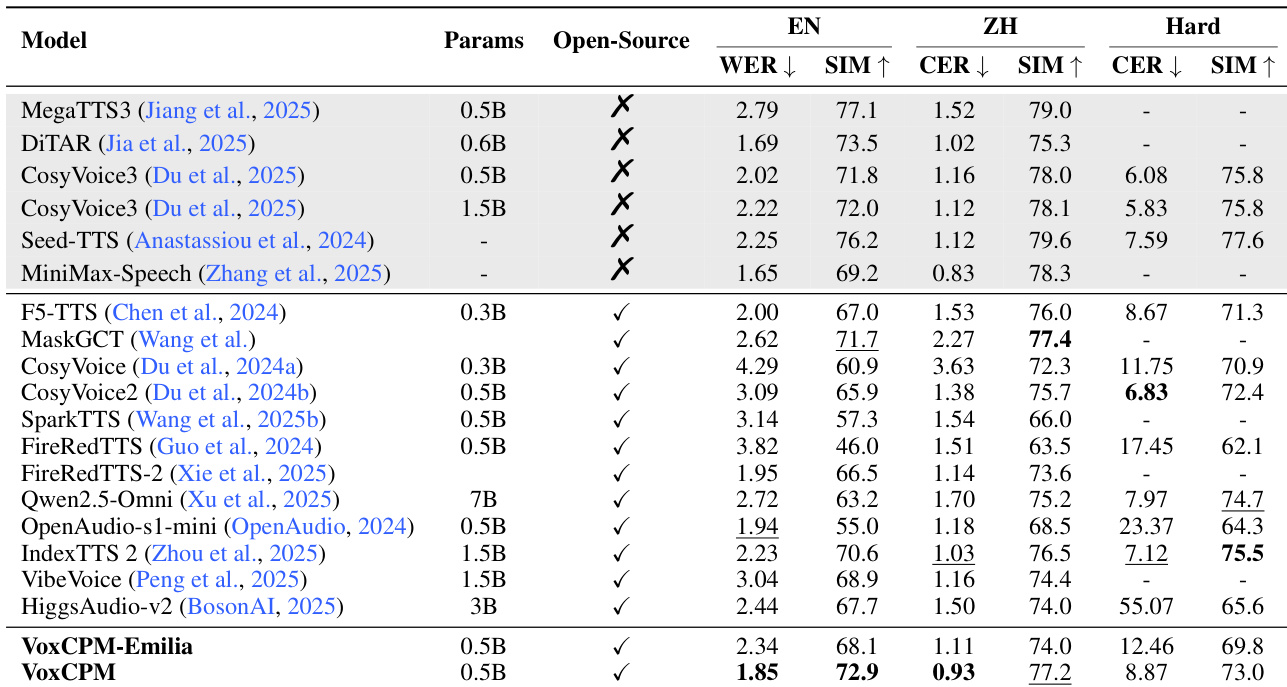
The authors compare VoxCPM and its Emilia variant against several state-of-the-art open-source and closed-source TTS models using English and Chinese benchmarks. Results show that VoxCPM achieves competitive performance in both intelligibility and speaker similarity across standard and challenging test sets. VoxCPM demonstrates superior English intelligibility and speaker similarity compared to most listed open-source models. On the challenging Hard test set, VoxCPM maintains high performance in both Chinese character error rates and speaker similarity. The VoxCPM-Emilia variant shows competitive results despite being trained on a smaller dataset, indicating architectural robustness.
The authors evaluate VoxCPM against several state-of-the-art TTS models using the CV3-EVAL benchmark, which focuses on expressive and in-the-wild performance. Results demonstrate that VoxCPM achieves superior performance in terms of intelligibility on both Chinese and English benchmarks compared to most baseline models. VoxCPM achieves the lowest error rates for both Chinese and English on the standard CV3-EVAL benchmark. On the more challenging CV3-Hard-EN subset, VoxCPM outperforms several competitive models in word error rate. While VoxCPM shows strong intelligibility, other models such as CosyVoice3 variants exhibit higher speaker similarity scores.
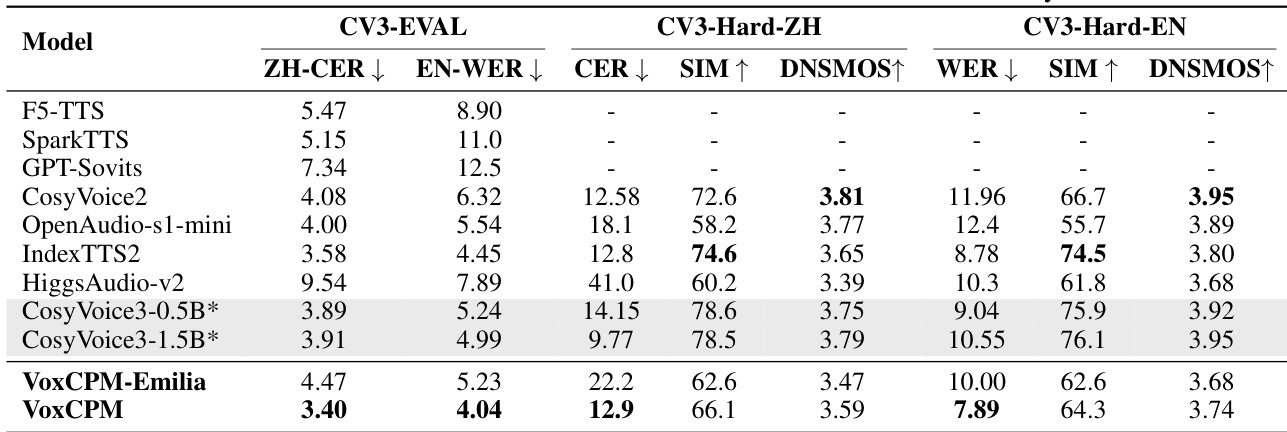
The authors conduct subjective and objective evaluations to compare VoxCPM and its variants against various state-of-the-art models across English and Chinese benchmarks. The experiments validate that VoxCPM achieves superior speaker similarity and high intelligibility, even when tested on challenging datasets or using the more efficient Emilia variant. Additionally, the results demonstrate that implementing a two-phase learning rate decay schedule significantly enhances model robustness and performance across all tested languages.