Command Palette
Search for a command to run...
効率的かつコスト効率の高い Retrieval-Augmented Generation システムに向けた Web Retrieval-Aware Chunking (W-RAC)
効率的かつコスト効率の高い Retrieval-Augmented Generation システムに向けた Web Retrieval-Aware Chunking (W-RAC)
Uday Allu Sonu Kedia Tanmay Odapally Biddwan Ahmed
概要
ご指定いただいた条件に基づき、提供された英文を専門的な学術・技術スタイルで日本語に翻訳いたしました。【翻訳文】Retrieval-Augmented Generation (RAG) システムは、検索品質、レイテンシ、および運用コストのバランスを最適化するために、効果的なドキュメント・チャンキング(chunking)戦略に決定的に依存している。固定サイズ方式、ルールベース方式、あるいは完全な Agentic なチャンキングといった従来のチャンキング手法は、特に大規模なウェブコンテンツの取り込み(ingestion)において、高い token 消費量、冗長なテキスト生成、スケーラビリティの限界、およびデバッグの困難さといった課題を抱えていることが多い。本論文では、ウェブベースのドキュメントに特化して設計された、新しいコスト効率の高いチャンキング・フレームワークである「Web Retrieval-Aware Chunking (W-RAC)」を提案する。W-RACは、パースされたウェブコンテンツを構造化された ID 指定可能なユニットとして表現し、LLM をテキスト生成のためではなく、検索を意識したグルーピングの意思決定のみに活用することで、テキスト抽出とセマンティックなチャンク計画を分離(decouple)する。これにより、token 使用量を大幅に削減し、ハルシネーション(hallucination)のリスクを排除するとともに、システムのオブザーバビリティ(observability)を向上させる。実験的な分析およびアーキテクチャの比較により、W-RAC は従来のチャンキング手法と同等またはそれ以上の検索性能を達成しつつ、チャンキングに関連する LLM コストを1桁(an order of magnitude)削減できることが示された。
One-sentence Summary
The authors propose Web Retrieval-Aware Chunking (W-RAC), a cost-efficient framework for web-based RAG systems that decouples text extraction from semantic planning by leveraging LLMs solely for retrieval-aware grouping decisions rather than text generation, thereby reducing token consumption and hallucination risks while maintaining high retrieval performance and improved observability.
Key Contributions
- The paper introduces Web Retrieval-Aware Chunking (W-RAC), a framework that reframes chunking as a semantic planning problem by decoupling deterministic web parsing from LLM-based grouping decisions.
- This method utilizes structured, ID-addressable representations of parsed web content to allow LLMs to make grouping decisions without regenerating text, which eliminates hallucination risks and improves system observability.
- Experimental results on the RAG-Multi-Corpus benchmark show that W-RAC achieves comparable or superior retrieval performance compared to agentic chunking while reducing LLM costs by 51.7% and output tokens by 84.6%.
Introduction
Retrieval-Augmented Generation (RAG) systems rely on effective document chunking to balance retrieval precision, latency, and operational costs, especially when ingesting large-scale web content. While fixed-size and rule-based methods often fail to preserve semantic integrity, agentic chunking approaches incur high computational overhead, risk hallucinations through text regeneration, and lack the scalability required for high-volume pipelines. The authors leverage a novel framework called Web Retrieval-Aware Chunking (W-RAC) that reframes chunking as a semantic planning problem rather than a generation task. By decoupling deterministic web parsing from LLM-based grouping decisions and using structured ID-addressable units, W-RAC achieves comparable retrieval performance to agentic methods while significantly reducing token consumption and total LLM costs.
Dataset
The authors introduce RAG-Multi-Corpus, a multi-format and multi-domain benchmark designed to simulate real-world enterprise knowledge bases. The dataset details include:
- Dataset Composition and Sources: The benchmark consists of 236 documents sourced from five fictional organizations. These documents cover diverse enterprise formats such as PDF, Markdown, HTML, DOCX, and PPTX to reflect the heterogeneity of production RAG pipelines.
- Query and Answer Details: The dataset includes 786 curated query-answer pairs, each accompanied by ground-truth citations. Queries are categorized into seven distinct types to ensure balanced coverage of factual recall, reasoning, comparison, and procedural understanding.
- Data Processing and Filtering: To ensure data quality, the authors applied filtering rules to remove irrelevant content, specifically targeting cookies, page navigation elements, and login information.
- Usage and Evaluation Strategy: The authors use this diverse query mix to evaluate retrieval robustness and assess how different chunking strategies impact retrieval quality. The distribution is specifically designed to test sensitivity to chunk boundaries and semantic coherence, particularly for procedural and comparative questions.
Method
The W-RAC system is designed around a three-stage pipeline that emphasizes retrieval-aware chunking while preserving the original source text and minimizing computational overhead. The framework begins with deterministic web parsing, where raw web content is transformed into structured representations—such as HTML to Markdown and then to an abstract syntax tree (AST). Each semantic unit, including headings and paragraphs, is assigned a stable, unique identifier to ensure consistency across processing stages. This structured representation forms the foundation for subsequent stages, enabling precise and reproducible operations.

As shown in the figure above, the system proceeds to LLM-based chunk planning, where the large language model (LLM) is tasked with generating chunk plans rather than regenerating text. Instead of receiving raw content, the LLM is provided with a set of identifiers, hierarchical relationships, ordering information, and optional metadata such as token counts and heading levels. The LLM then outputs a structured list of chunk plans, with each chunk represented as an ordered array of identifiers. This approach positions the LLM as a semantic grouping planner, responsible for determining optimal boundaries based on structural and contextual cues. The output is a JSON-formatted list of chunks, where each chunk contains a sequence of identifiers that correspond to the original text units.
Following chunk planning, the system enters a post-processing and indexing phase. Here, the chunk plans are resolved locally by mapping the identifier arrays back to their corresponding text content. Final chunks are assembled by concatenating the original text in the order specified by the plans, then embedded and indexed into the retrieval system. This ensures that the resulting chunks are both semantically coherent and optimized for downstream retrieval tasks.
A key aspect of W-RAC is its retrieval-aware design, which explicitly incorporates retrieval considerations into the chunk planning process. Chunk boundaries are influenced by multiple factors, including heading depth and section hierarchy, token-length constraints, entity density, and semantic cohesion. Additionally, content type—such as tables, figures, or code blocks—is treated as a cohesive unit and never split across chunks. This design ensures that chunks align more closely with real-world query patterns, improving both recall and precision.
The chunk planning process is guided by a set of strict rules and principles. The system enforces a three-level heading hierarchy, where each chunk group must include a top-level (Level 1), mid-level (Level 2), and immediate parent (Level 3) heading. Missing levels are filled using the best-matching existing heading ID, and reuse of heading IDs is permitted. When a parent heading has multiple children, the parent ID is included in every child group array, ensuring structural continuity. Procedural content—such as step-by-step instructions, numbered procedures, or sequential lists—is never split across chunks; instead, all steps are grouped into a single chunk array to preserve logical flow. Small or contextless chunks are merged with adjacent content or titles to ensure each chunk is fully contextual.
The system also prioritizes context and merging, using heading hierarchy, parent-child relationships, and sequential patterns to infer structure where it is not explicitly defined. Input is processed through a sequence of steps: mapping the heading hierarchy, identifying procedural content, tracing the three-level hierarchy for each chunk, and ensuring that parent headings are included in child groups. Finally, chunks are grouped into logical arrays and output in a specified JSON format without code blocks or backticks, with each array containing at least one heading or sufficient context. This structured output ensures clarity, completeness, and alignment with retrieval requirements.
Experiment
The experiments compare the W-RAC method against traditional agentic chunking using the RAG-Multi-CORPUS benchmark to evaluate ingestion efficiency and retrieval quality. The results demonstrate that W-RAC significantly reduces computational overhead, processing time, and costs by minimizing output token consumption. Furthermore, the method achieves superior precision across various query types while maintaining competitive recall and ranking performance, offering an optimal balance of operational efficiency and retrieval effectiveness for production systems.
The authors compare W-RAC against a baseline method in terms of retrieval quality across multiple metrics. Results show that W-RAC achieves higher precision while maintaining competitive recall and ranking scores, indicating improved relevance in retrieved results. W-RAC improves precision across all evaluation metrics compared to the baseline. W-RAC maintains competitive recall and ranking quality despite higher precision. The retrieval results demonstrate consistent gains in precision with minimal trade-offs in other metrics.

The authors compare traditional chunking, agentic chunking, and W-RAC across key dimensions such as cost, fidelity, and scalability. Results show that W-RAC achieves high performance in text fidelity and scalability while minimizing hallucination risk and LLM token cost. W-RAC achieves high text fidelity and low hallucination risk compared to traditional and agentic chunking. W-RAC demonstrates high scalability and web suitability, outperforming other methods in these dimensions. W-RAC has very low LLM token cost, making it more efficient than traditional and agentic chunking approaches.

The authors compare the cost efficiency of Agentic Chunking and W-RAC, focusing on input, cache, and output token consumption. Results show that W-RAC significantly reduces output token costs and overall expenses while increasing input token usage, leading to substantial cost savings. The method maintains competitive retrieval performance despite higher input token consumption. W-RAC reduces output token costs by over 80% compared to Agentic Chunking W-RAC increases input token usage by 50% but achieves significant overall cost savings The total cost of W-RAC is substantially lower than Agentic Chunking, demonstrating improved cost efficiency

The authors compare W-RAC with traditional agentic chunking across multiple organizations, evaluating token usage, processing time, and cost efficiency. Results show that W-RAC significantly reduces output tokens and processing time while increasing input tokens, leading to substantial cost savings. Despite higher input token usage, W-RAC maintains competitive retrieval performance with notable improvements in precision. W-RAC reduces output tokens and processing time significantly compared to agentic chunking. W-RAC increases input tokens but achieves substantial cost savings due to lower output token consumption. W-RAC improves retrieval precision across all organizations and query types while maintaining competitive recall and ranking quality.
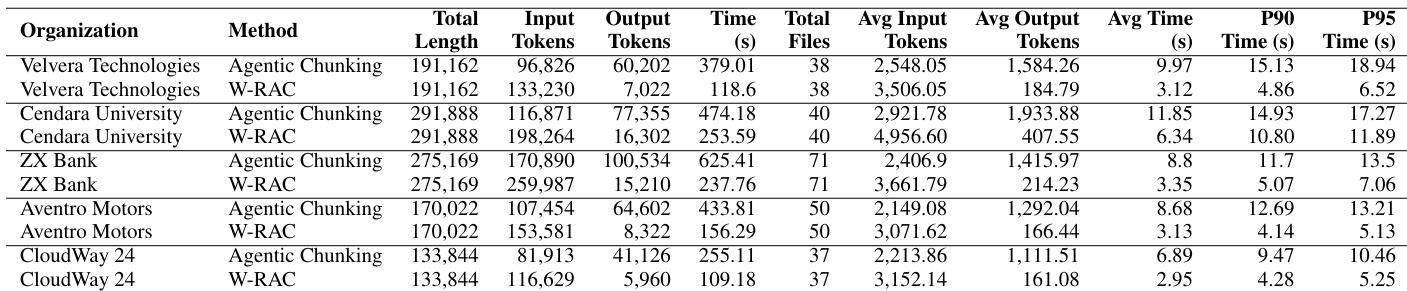
The authors compare W-RAC against a baseline method across various query types, evaluating retrieval effectiveness using standard metrics. Results show that W-RAC achieves higher precision across all query categories while maintaining competitive recall and ranking quality. W-RAC improves precision across all query types, with the largest gains in temporal and comparative queries. W-RAC maintains competitive recall and ranking metrics despite higher precision. Precision improvements are consistent across descriptive, procedural, analytical, and open-ended queries.
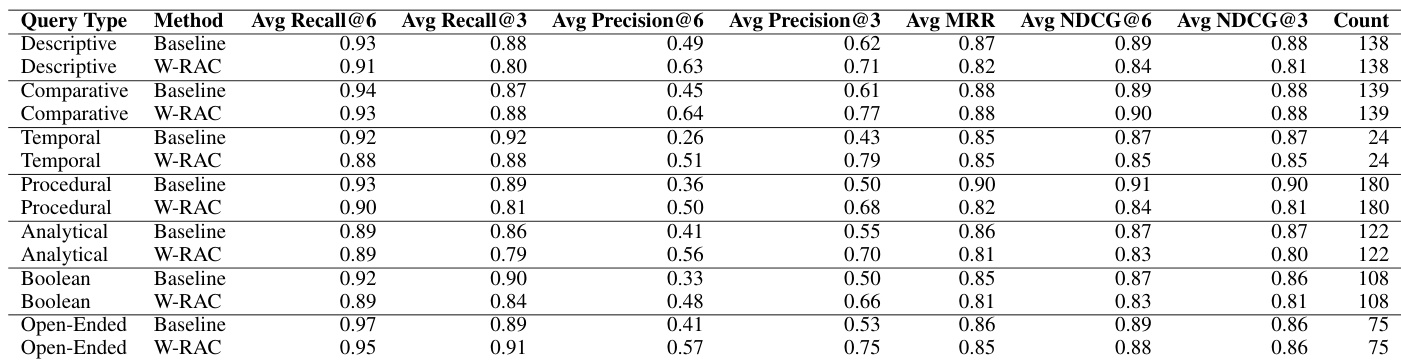
The authors evaluate W-RAC through comparative experiments against baseline and agentic chunking methods, focusing on retrieval quality, text fidelity, scalability, and cost efficiency. The results demonstrate that W-RAC consistently improves retrieval precision across various query types and organizations while maintaining competitive recall and ranking performance. Furthermore, the method offers superior text fidelity and scalability with significantly lower overall costs and processing times compared to existing chunking approaches.