Command Palette
Search for a command to run...
RSRCC: 検索拡張ベスト・オブ・N 順位付けによって構築されたリモートセンシング地域変化理解ベンチマーク
RSRCC: 検索拡張ベスト・オブ・N 順位付けによって構築されたリモートセンシング地域変化理解ベンチマーク
Roie Kazoom Yotam Gigi George Leifman Tomer Shekel Genady Beryozkin
概要
従来の変化検出(change detection)は、変化が生じた場所を特定するものの、自然言語を用いて何が変わったのかを説明するものではありません。既存のリモートセンシング用変化キャプションデータセットは、通常、画像全体レベルでの差異を記述するものであり、細粒度な局所的な意味的推論に関する領域はほとんど探求されていません。このギャップを埋めるため、本稿では126,000件の質問を含むリモートセンシング用変化質問応答(QA)の新たなベンチマーク「RSRCC」を提示します。このデータセットは、87,000件の学習用、17,100件の検証用、22,000件のテスト用インスタンスに分割されています。先行するデータセットとは異なり、RSRCCは特定の意味的変化について推論を行うことを必要とする、局所的かつ変化特異的な質問を中心に構築されています。著者らの知る限り、これはこのような細粒度な推論ベースの教師信号を明示的に目的として設計された、初めてのリモートセンシング用変化質問応答ベンチマークです。RSRCCの構築にあたり、我々は階層的半教師ありキュレーションパイプラインを導入しました。このパイプラインでは、最終的な曖昧さ解消段階として、Best-of-Nランキングが重要な役割を果たします。具体的には、まず意味的セグメンテーションマスクから候補の変化領域を抽出し、次に画像-テキスト埋め込みモデルを用いて初期スクリーニングを行い、最終的にRetrieval-Augmented Vision-LanguageキュレーションとBest-of-Nランキングを通じて検証を行います。このプロセスにより、意味的に意味のある変化を維持しつつ、ノイズや曖昧な候補のスケーラブルなフィルタリングが可能になります。本データセットは https://huggingface.co/datasets/google/RSRCC で公開されています。
One-sentence Summary
RSRCC is a remote sensing regional change comprehension benchmark containing 126k questions for fine-grained localized semantic reasoning, constructed via a hierarchical semi-supervised curation pipeline utilizing retrieval-augmented vision-language validation and Best-of-N ranking to resolve ambiguity and ensure scalable, high-quality supervision for change question-answering.
Key Contributions
- The paper presents RSRCC, a new benchmark for remote sensing change question-answering containing 126k questions designed for fine-grained reasoning about specific semantic changes. Unlike prior datasets focusing on overall image-level differences, this resource provides localized, change-specific supervision split into training, validation, and test instances.
- A hierarchical semi-supervised curation pipeline is introduced to construct the dataset, utilizing segmentation masks and image-text embedding models for initial candidate screening. The process concludes with a retrieval-augmented vision-language curation stage that applies Best-of-N ranking to resolve ambiguity.
- Vision-language encoders are employed to refine segmentation outputs instead of replacing them, complementing machine-readable localization with region-grounded language. This integration strategy enables the preservation of semantically meaningful changes while addressing the cost and scalability limits of dense mask annotation.
Introduction
Change detection identifies differences between multi-temporal remote sensing images to support applications like building monitoring and disaster response. Although deep learning models have advanced pixel-wise segmentation, these methods struggle to provide human-readable explanations and depend on expensive dense annotations. The authors address these gaps by leveraging vision-language encoders to complement traditional segmentation rather than replace it. Their approach integrates semantic screening into the curation pipeline to refine change candidates and ground localization with structured language.
Method
The authors propose a hierarchical semi-supervised curation pipeline designed to construct a high-quality dataset for remote sensing change detection. The framework operates in four primary stages: semantic segmentation for candidate localization, connected component analysis for region extraction, image-text semantic screening, and retrieval-augmented Best-of-N validation for ambiguous cases.
First, candidate change regions are localized using a transformer-based segmentation model. This model employs a ViT-L encoder to extract multi-scale visual features ϕ(I) and a lightweight ViT-Lite decoder to map them to dense semantic predictions S. To handle class imbalance, the model is trained with Dice loss. Following segmentation, connected component analysis partitions the difference mask D=I[Mt=Mt+Δt] into disjoint regions. These regions are filtered using adaptive thresholds to remove noise and retain structurally meaningful objects. Refer to the framework diagram for the initial segmentation and candidate extraction flow.
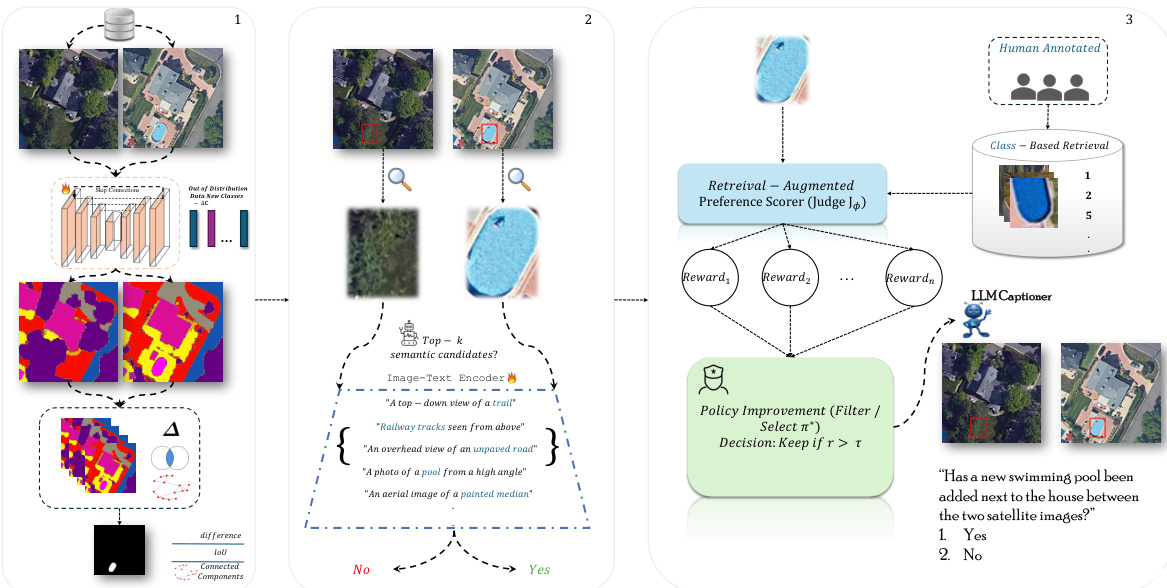
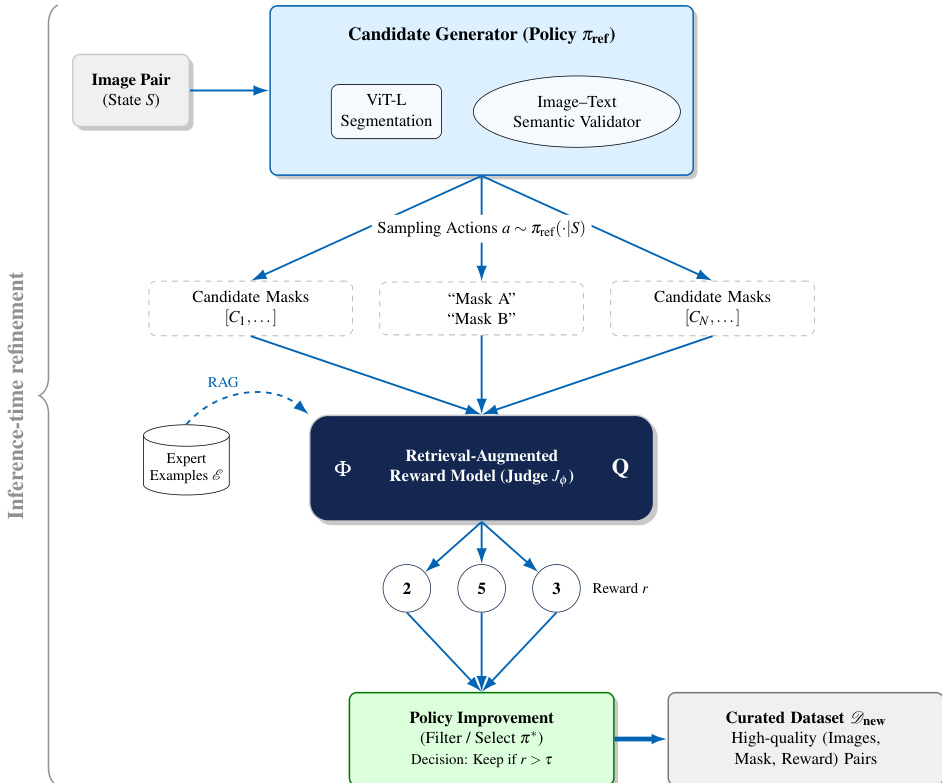
Next, the pipeline applies semantic filtering using a SigLIP-based vision-language encoder. For each candidate region, the encoder computes embeddings for the before and after image patches and compares them to class prompts. If the expected class does not appear in the top-k predictions with sufficient similarity, the candidate is discarded. For regions where the encoder yields ambiguous evidence, such as when the same class appears in both time steps, a second validation stage is invoked. This stage utilizes a retrieval-augmented Best-of-N ranking mechanism to resolve uncertainty.
The Best-of-N process functions as a preference-guided selection mechanism. A frozen generator produces multiple candidate interpretations or masks, which are then scored by a retrieval-augmented preference model (Judge Jϕ). The judge is conditioned on a set of semantically similar retrieved examples ER(q) to ensure consistency. The model scores each hypothesis hi as ri=Jϕ(hi∣ER(q)) and applies a decision rule to retain only high-confidence candidates. This workflow is illustrated in the preference-guided selection process diagram.
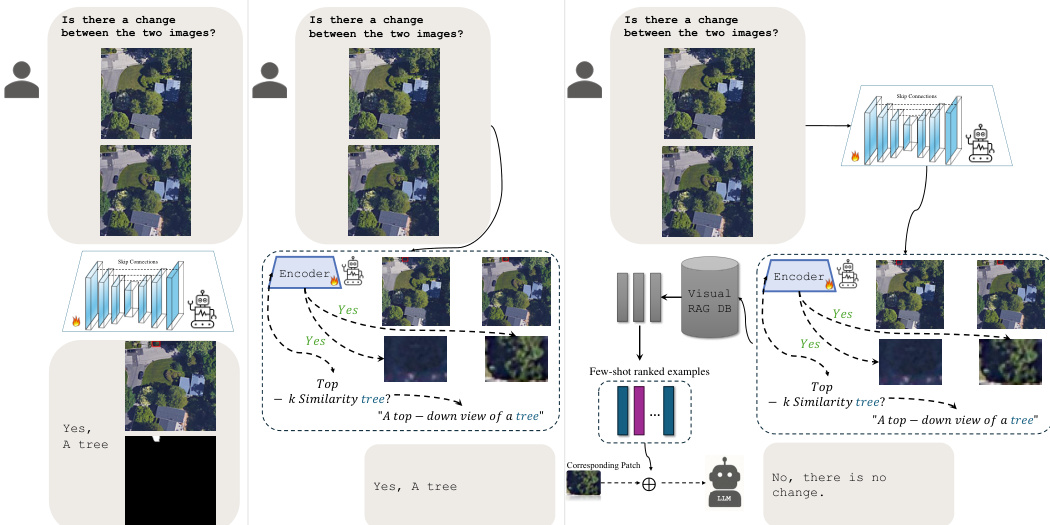
Finally, for the curated change instances, a Large Language Model generates diverse question-answer pairs. The LLM receives the cropped visual input and the validated semantic label to produce closed-ended, binary, or open-ended questions. This step ensures linguistic diversity while grounding the questions in the verified semantic changes. The progression from initial image comparison to final validated output, including cases where no change is detected despite visual similarity, is depicted in the validation logic illustration.
Experiment
The framework is evaluated using the LEVIR-CD dataset and human annotators to validate semantic consistency and change detection capabilities across multiple pipeline stages. Qualitative analysis indicates that the method successfully identifies fine-grained structural changes often overlooked in existing ground truth annotations while achieving superior human agreement compared to baseline models. Additional experiments confirm the robustness of the filtering mechanism against random noise and establish cosine similarity with SigLIP as the optimal strategy for semantic retrieval alignment.
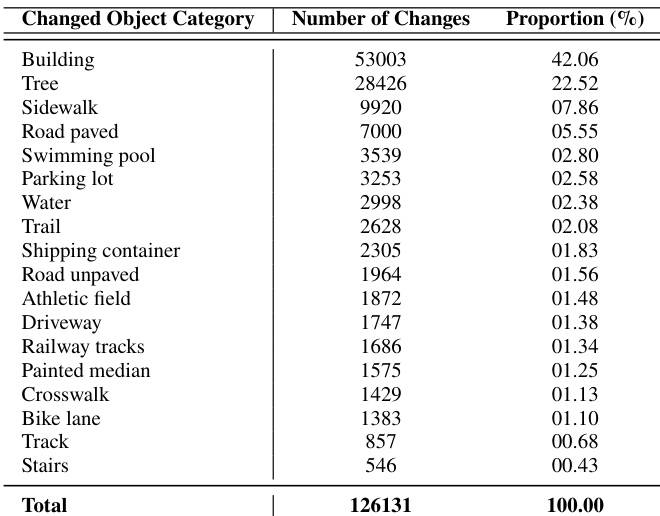
The data categorizes detected changes by object type, revealing that structural and natural elements dominate the distribution. Buildings account for the majority of instances, with trees forming the second largest group, while specialized infrastructure features are far less common. Buildings are the most prevalent category of change. Vegetation such as trees is the second most frequent category. Categories like stairs and tracks represent the smallest portion of changes.
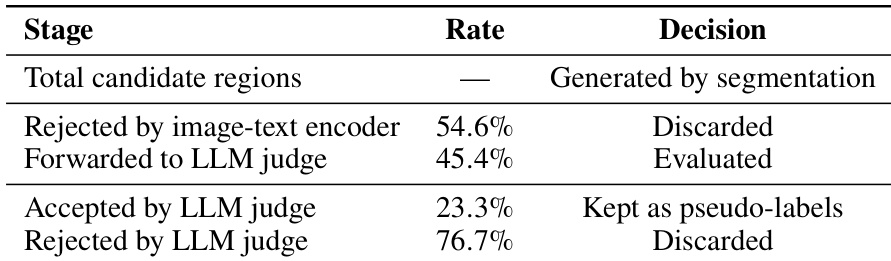
The authors evaluate the framework using binary and open-ended question formats to assess semantic consistency and factual accuracy. Results demonstrate that the model achieves the highest performance on multiple-choice questions, with binary tasks also showing strong reliability. Across all formats, the system exhibits greater accuracy in identifying instances where no change has occurred compared to actual changes. Multiple-Choice questions achieved the highest overall performance scores compared to Yes/No and Open-Ended formats. The model consistently performs better on No Change instances than on Change instances across all question types. Open-Ended responses show a significantly larger performance gap between change and no-change scenarios compared to binary question formats.

The the the table presents baseline benchmark performance for various large language models across different question types and evaluation metrics. Results indicate that models generally achieve higher performance scores when evaluating change cases compared to no-change cases. Among the tested models, the Gemini-2.5-Pro variant demonstrates superior performance relative to the Flash and Gemma variants across most metrics. Models consistently show higher scores for change detection compared to no-change identification across all metrics. Binary Yes/No questions result in higher accuracy than multiple-choice questions for every model tested. The Gemini-2.5-Pro model achieves the highest overall performance scores compared to Gemini-2.5-Flash and Gemma variants.
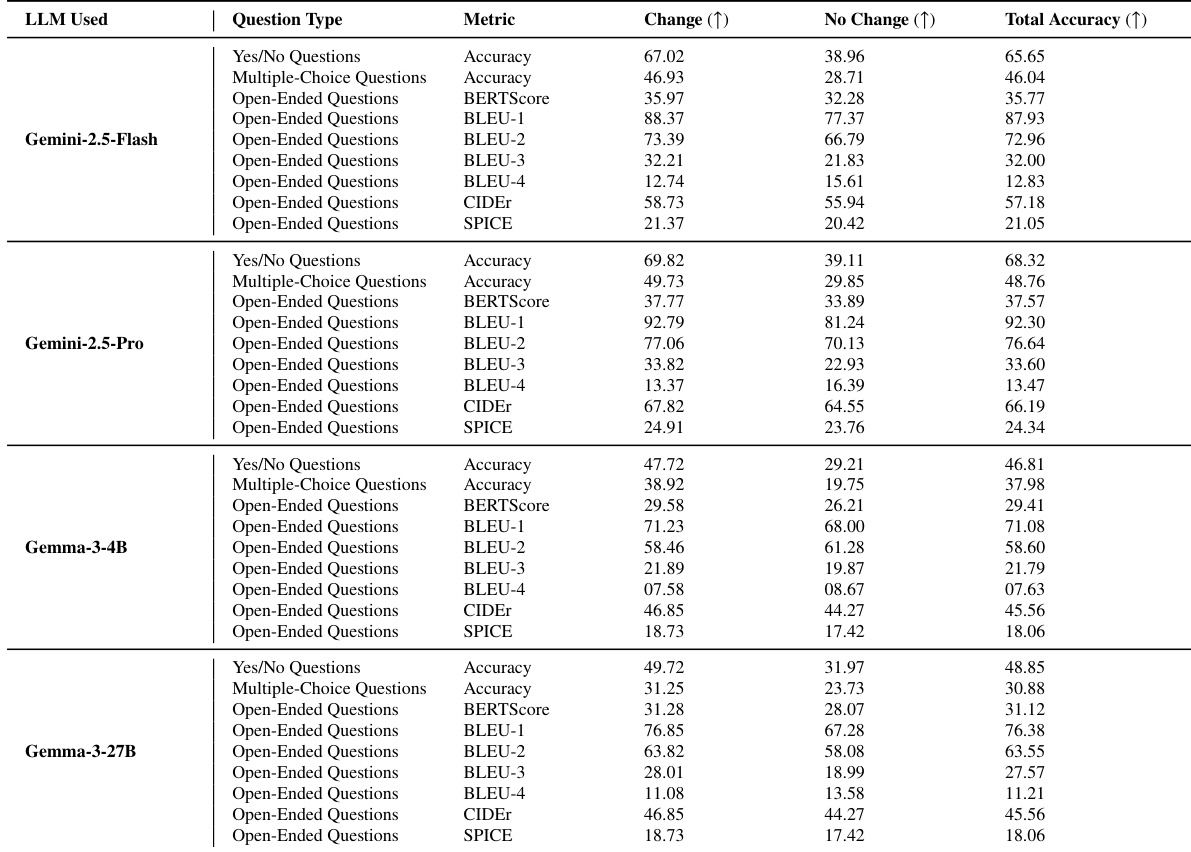
The authors evaluate human agreement across various dataset creation pipelines and baseline models to assess semantic consistency. The proposed full pipeline achieves the highest level of agreement, significantly outperforming ablated versions that isolate specific components like encoding or segmentation. Baseline large language models show lower agreement scores that improve with few-shot prompting but do not reach the performance of the complete system. The complete pipeline yields the highest human agreement, confirming the complementary role of each stage. Ablated pipelines relying solely on encoding or segmentation result in substantially lower agreement rates. Baseline models exhibit a performance gap compared to the proposed method, with few-shot settings generally outperforming zero-shot configurations.
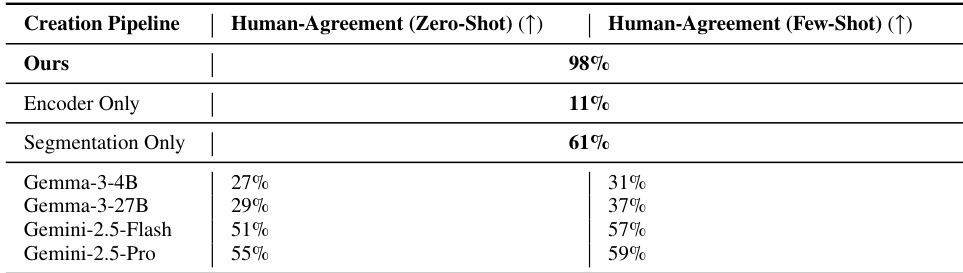
The authors analyze the filtering behavior of their unsupervised discovery pipeline, which employs an image-text encoder followed by an LLM judge. The encoder initially discards the majority of candidate regions generated by segmentation. The LLM judge then evaluates the remaining regions, accepting only a small fraction as valid pseudo-labels while discarding the rest. The image-text encoder rejects the majority of initial candidate regions. The LLM judge accepts only a minority of forwarded regions as valid pseudo-labels. Most regions evaluated by the LLM are ultimately discarded as spurious or low-confidence detections.
The experiments evaluate semantic consistency and factual accuracy using binary, multiple-choice, and open-ended question formats across data dominated by structural and natural elements. Findings indicate that the proposed full pipeline achieves the highest human agreement and outperforms baseline models, with the system showing particular strength in identifying instances where no change has occurred. Furthermore, the unsupervised discovery process utilizes a strict filtering mechanism where both the image-text encoder and LLM judge discard the majority of candidate regions to ensure valid pseudo-labels.