Command Palette
Search for a command to run...
強化学習におけるグループレベルの自然言語フィードバックを用いたBootstrapping型探索
強化学習におけるグループレベルの自然言語フィードバックを用いたBootstrapping型探索
Lei Huang Xiang Cheng Chenxiao Zhao Guobin Shen Junjie Yang Xiaocheng Feng Yuxuan Gu Xing Yu Bing Qin
概要
大規模言語モデル(LLM)は通常、環境との相互作用を通じて多様な自然言語(NL)フィードバックを受け取ります。しかし、現在の強化学習(RL)アルゴリズムはスカラー報酬のみに依存しており、NLフィードバックに含まれる豊かな情報が十分に活用されず、結果として探索の効率性が低下しています。本研究では、グループレベルの言語フィードバック(Group-level Language Feedback)を明示的に活用し、実行可能な修正(actionable refinements)を通じて標的を絞った探索を導くRLフレームワーク「GOLF」を提案します。GOLFは、補完的な2つのフィードバックソースを集約します。(i) エラーを特定したり、的を絞った修正案を提示したりする「外部からの批判(external critiques)」、および (ii) 代替となる部分的なアイデアや多様な失敗パターンを提供する「グループ内の試行(intra-group attempts)」です。これらのグループレベルのフィードバックを集約することで高品質な修正案を生成し、それらをオフポリシーの足場(off-policy scaffolds)として学習プロセスに適応的に注入することで、報酬が疎な(sparse-reward)領域において的を絞ったガイダンスを提供します。同時に、GOLFは統一されたRLループ内で生成(generation)と修正(refinement)を共同で最適化し、両方の能力を継続的に向上させる好循環を構築します。検証可能なベンチマーク(verifiable benchmarks)および検証不可能なベンチマーク(non-verifiable benchmarks)の両方を用いた実験の結果、GOLFは優れた性能と探索効率を達成しました。具体的には、スカラー報酬のみで学習されたRL手法と比較して、サンプル効率において2.2倍の向上を実現しました。
One-sentence Summary
The authors propose GOLF, a reinforcement learning framework that bootstraps exploration by aggregating external critiques and intra-group attempts into group-level natural language feedback to produce actionable refinements adaptively injected as off-policy scaffolds for targeted guidance in sparse-reward regions and jointly optimizes generation and refinement within a unified RL loop, achieving 2.2× improvements in sample efficiency compared to RL methods trained solely on scalar rewards on verifiable and non-verifiable benchmarks.
Key Contributions
- The paper introduces GOLF, a reinforcement learning framework that aggregates external critiques and intra-group attempts to produce high-quality refinements. These refinements are adaptively injected into training as off-policy scaffolds to provide targeted guidance in sparse-reward regions.
- This work jointly trains problem solving and self-refinement under outcome rewards to create a virtuous cycle of improvement. The learned refinement capability generates high-quality samples that serve as adaptive guidance for exploration.
- Experiments on both verifiable and non-verifiable benchmarks demonstrate that the framework achieves superior performance and exploration efficiency. Results indicate a 2.2× improvement in sample efficiency compared to reinforcement learning methods trained solely on scalar rewards.
Introduction
Large language models typically rely on reinforcement learning driven by sparse scalar rewards, yet this approach hinders exploration efficiency because the policy lacks explicit guidance on how to correct errors. Although natural language feedback offers richer supervision, existing algorithms often underutilize this information or fail to leverage complementary signals from alternative attempts within the same rollout group. The authors propose GOLF, a framework that aggregates external critiques and intra-group attempts to produce actionable refinements. They inject these high-quality refinements as off-policy scaffolds to guide exploration in sparse-reward regions while jointly optimizing generation and refinement within a unified loop.
Dataset
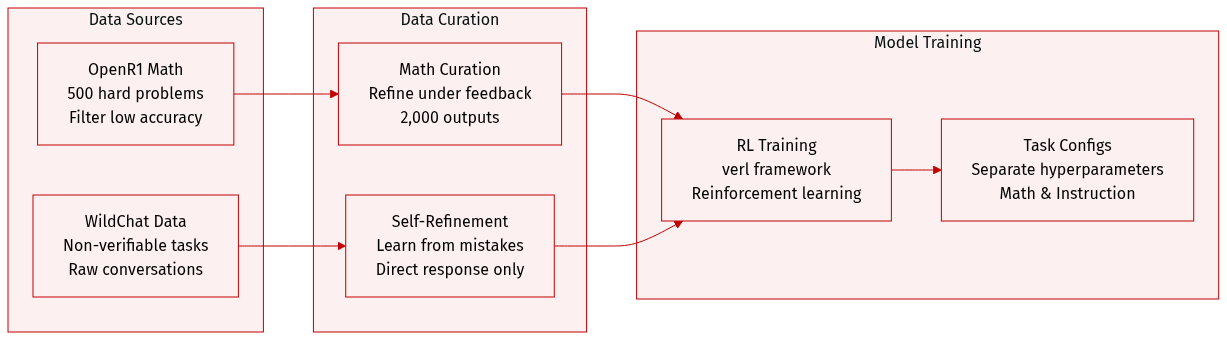
The authors construct datasets for mathematical reasoning and non-verifiable tasks using the following composition and processing strategies:
- Mathematical Reasoning: A challenging subset is derived from OpenR1 containing 500 problems. The authors filter for items where Qwen-3-8B achieves zero pass@4 accuracy. Refinement is performed under different feedback conditions to generate 2,000 outputs for evaluation.
- Non-Verifiable Tasks: The team utilizes WildChat data with a self-refinement prompt structure. Responses are synthesized by learning from mistakes and incorporating strengths from candidate responses and their associated feedback scores. Output generation is constrained to provide only the direct response without meta commentary or introductory text.
- Evaluation Benchmarks: Six benchmarks are used to measure performance with specific sizes and scoring protocols:
- AlpacaEval-v2: 805 prompts evaluated via head-to-head win rate using GPT-4o.
- WildBench: 1,024 prompts scored with instance level rubrics against a GPT-4 reference.
- ArenaHard-v2: 500 queries assessed with a GPT-4.1 judge using style control.
- CreativeWriting-v3: 96 story chapters evaluated on a 0 to 100 scale.
- IFEval: Over 500 prompts across 25 instruction types verified via Python functions.
- IFBench: 58 constraints curated to test generalization with out-of-domain prompts.
- Training and Processing: Reinforcement learning is implemented using the verl framework. Separate hyperparameter configurations are applied for mathematical reasoning, instruction following, and non-verifiable tasks.
Method
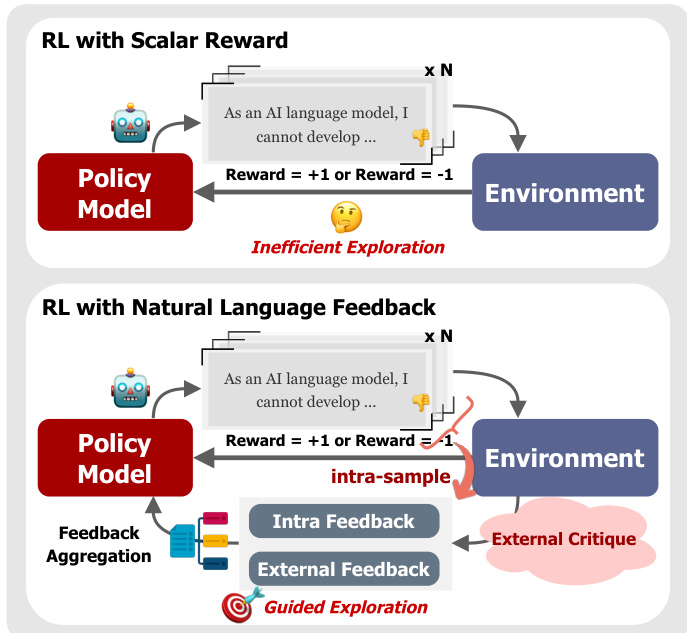
The proposed framework, GOLF, introduces a structured approach to Reinforcement Learning with Natural Language Feedback (RL-NL). Unlike standard RL methods that rely solely on scalar rewards, GOLF leverages rich textual critiques to guide the policy towards better solutions. Refer to the framework diagram below to visualize the transition from inefficient exploration with scalar rewards to guided exploration using natural language feedback.
The core of the method builds upon Group Relative Policy Optimization (GRPO), which simplifies Proximal Policy Optimization by eliminating the need for a trainable value function. For a given prompt x, the model samples a group of N responses {y(i)}i=1N. The advantage for each response is computed by normalizing the scalar rewards within the group:
A(i)=std({r(j)}j=1N)r(i)−mean({r(j)}j=1N)
The policy is then optimized using a clipped surrogate objective with a KL penalty against a reference policy. GOLF extends this baseline by integrating three tightly coupled components: Group-level Feedback Aggregated Refinement, Adaptive Guidance via Mixed Policy Optimization, and Joint Optimization for Self-Refinement.
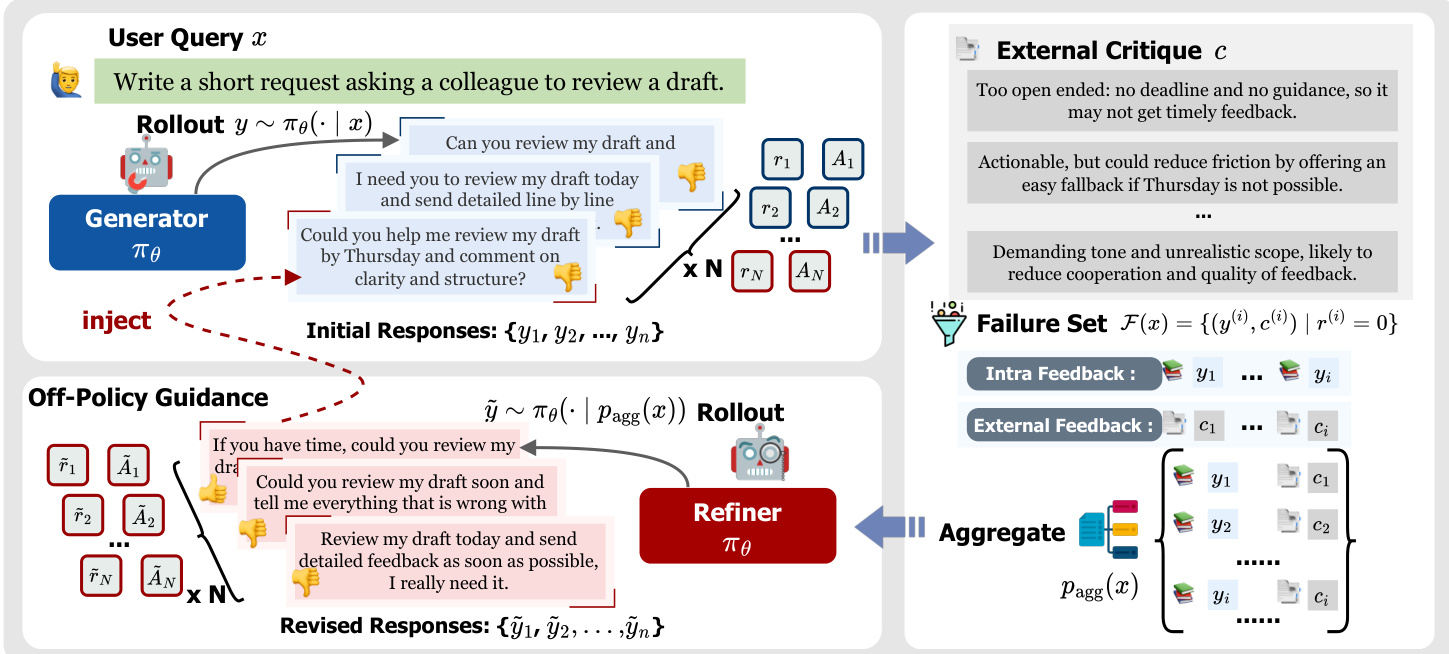
Group-level Feedback Aggregated Refinement
Instead of refining failures in isolation, the method aggregates multiple failed attempts and their corresponding critiques into a single context. For each prompt x, the generator produces initial responses and receives scalar rewards and external critiques (r(i),c(i)). The system identifies a failure set F(x) containing responses with zero reward. These failures, along with their critiques, are concatenated to form an aggregated refinement prompt pagg(x):
pagg(x)=CONCAT(x, F(x))
Conditioned on this prompt, the model samples a refinement group to produce improved responses. This process synthesizes diverse failure modes and complementary partial ideas.
As shown in the figure below, the architecture explicitly separates the generation of initial responses from the refinement process, utilizing both intra-group feedback and external critiques to construct the aggregated context for the refiner.
Adaptive Guidance via Mixed Policy Optimization
To address low-reward regimes where on-policy groups yield weak advantages, the authors treat high-quality refinements as off-policy scaffolds. An adaptive injection mechanism triggers when the average reward of the generation group s(x) falls below a threshold τ. In such cases, successful refinements are selected and injected into the rollout group by replacing failed responses.
The policy is updated using a mixed objective that combines on-policy and off-policy trajectories. The mixed objective IMixed(θ) is defined as:
IMixed(θ)=Z1[on-policy objectivei=1∑Nont=1∑∣τi∣CLIP(ri,ton(θ),A^i,ε)+off-policy objectivej=1∑Nofft=1∑∣τj∣CLIP(f(rj,toff(θ)),A^j,ε)]
Here, Z normalizes by the total token count, and f(u) is a reshaping function applied to off-policy ratios to emphasize low-probability yet effective actions. Advantages are computed by normalizing rewards within the augmented group containing both on-policy and injected off-policy samples.
Joint Optimization for Self-Refinement
Finally, the framework explicitly trains the language model to improve both direct problem-solving and feedback-conditioned refinement within a single integrated RL process. For each prompt, the system collects both generation and refinement rollout groups. These are concatenated into a joint batch, and advantages are computed separately for each group before updating the policy. This joint optimization creates a positive feedback loop where improved self-refinement produces higher-quality scaffolds for the mixed-policy optimization, enhancing the overall discovery of rewarding trajectories.
Experiment
This research evaluates the GOLF framework across non-verifiable tasks such as creative writing and verifiable domains including mathematical reasoning and code generation, comparing performance against multiple reinforcement learning baselines. Experimental results indicate that GOLF consistently achieves superior performance and faster convergence by aggregating group-level natural language feedback to densify learning signals. Further ablation studies reveal that combining external critiques with intra-group attempts significantly enhances exploration diversity and self-refinement capabilities, confirming the value of textual guidance in improving policy optimization.
The authors evaluate the GOLF method against Pairwise-GRPO baselines on the Llama-3.1-8B-Instruct model across five non-verifiable benchmarks. Results indicate that GOLF with a rollout of 8 consistently outperforms Pairwise-GRPO variants, achieving the highest average score and winning rates across most evaluation metrics. GOLF with a rollout of 8 achieves the best average score compared to Pairwise-GRPO baselines with rollouts of 8 and 16. Increasing the rollout size for Pairwise-GRPO improves its performance but does not surpass the results achieved by GOLF with fewer rollouts. GOLF demonstrates superior performance on specific benchmarks such as AlpacaEval-v2 and CreativeWriting-v3 relative to the baseline methods.

The authors conduct an ablation study to evaluate the effectiveness of different feedback sources, comparing simple baselines against intra-group, external, and mixed feedback strategies. Results indicate that while external feedback alone offers substantial improvements over intra-group feedback, combining both sources yields the best overall performance. This suggests that external critiques and intra-group attempts provide complementary signals that enhance both the diversity of solutions and the accuracy of the final output. Mixed feedback achieves the highest performance across both pass@4 and accuracy metrics. External feedback alone significantly outperforms intra-group feedback, indicating the strong value of external critiques. The Simple baseline fails to produce successful results, highlighting the necessity of the feedback mechanisms.

The the the table presents an ablation study on the GOLF method using the Llama-3.1-8B-Instruct model across four non-verifiable benchmarks. The full GOLF configuration achieves the highest average score, indicating that combining intra-group attempts with external critiques is more effective than relying on either source in isolation. Removing external feedback results in the most substantial performance decline across the majority of evaluated metrics. The full GOLF model achieves the highest average score compared to ablated variants. Removing external feedback leads to the lowest performance on AlpacaEval, ArenaHard, and CreativeWriting. Both intra-group and external feedback sources are necessary to achieve optimal results.

The the the table presents an ablation study on the Llama-3.1-8B-Instruct model, comparing the GOLF method with adaptive guidance against a non-adaptive variant. The results show that enabling adaptive injection consistently yields higher performance across all non-verifiable benchmarks, including AlpacaEval, WildBench, and ArenaHard. The text explains that this adaptive strategy improves training by targeting prompts where the model faces collapsed advantages, effectively converting uninformative groups into usable gradients. The adaptive configuration achieves higher average scores and win rates across all evaluated benchmarks compared to the non-adaptive variant. Performance gains are particularly notable in AlpacaEval-v2 and CreativeWriting-v3, where the adaptive method leads by a significant margin. Adaptive injection prevents performance degradation by selectively applying guidance to low-reward regimes rather than using a static injection strategy.

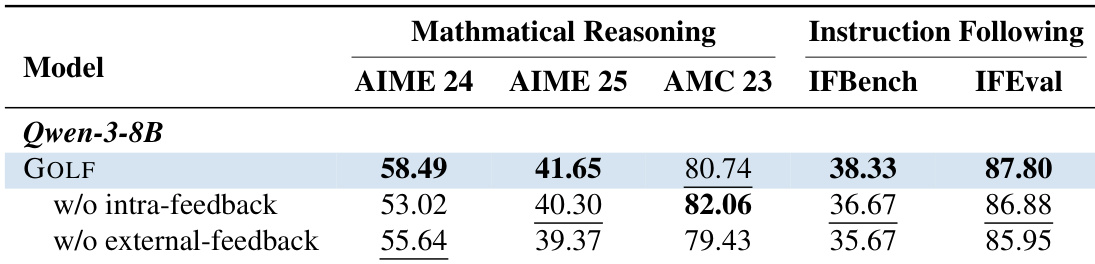
The authors present an ablation study on the Qwen-3-8B model to assess the contribution of different feedback sources within the GOLF framework. The results demonstrate that the full GOLF method generally outperforms variants that exclude either intra-group attempts or external critiques across mathematical reasoning and instruction following benchmarks. This suggests that aggregating both types of feedback is crucial for achieving optimal performance. The full GOLF model generally achieves higher performance than variants lacking intra-feedback or external feedback. Ablating either feedback component results in performance degradation across most mathematical and instruction following tasks. The findings confirm that combining internal attempts with external critiques provides complementary benefits for policy refinement.
The authors evaluate the GOLF method against Pairwise-GRPO baselines on Llama-3.1-8B-Instruct and Qwen-3-8B models across multiple non-verifiable benchmarks. Ablation studies reveal that combining intra-group attempts with external critiques yields superior performance compared to using either source alone, while adaptive guidance strategies further enhance results by targeting low-reward regimes. Overall, the experiments demonstrate that integrating diverse feedback mechanisms and adaptive injection is essential for optimal policy refinement across various tasks.