HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

MemLens: 大規模ビジョン・言語モデルにおけるマルチモーダル長期記憶の評価ベンチマーク
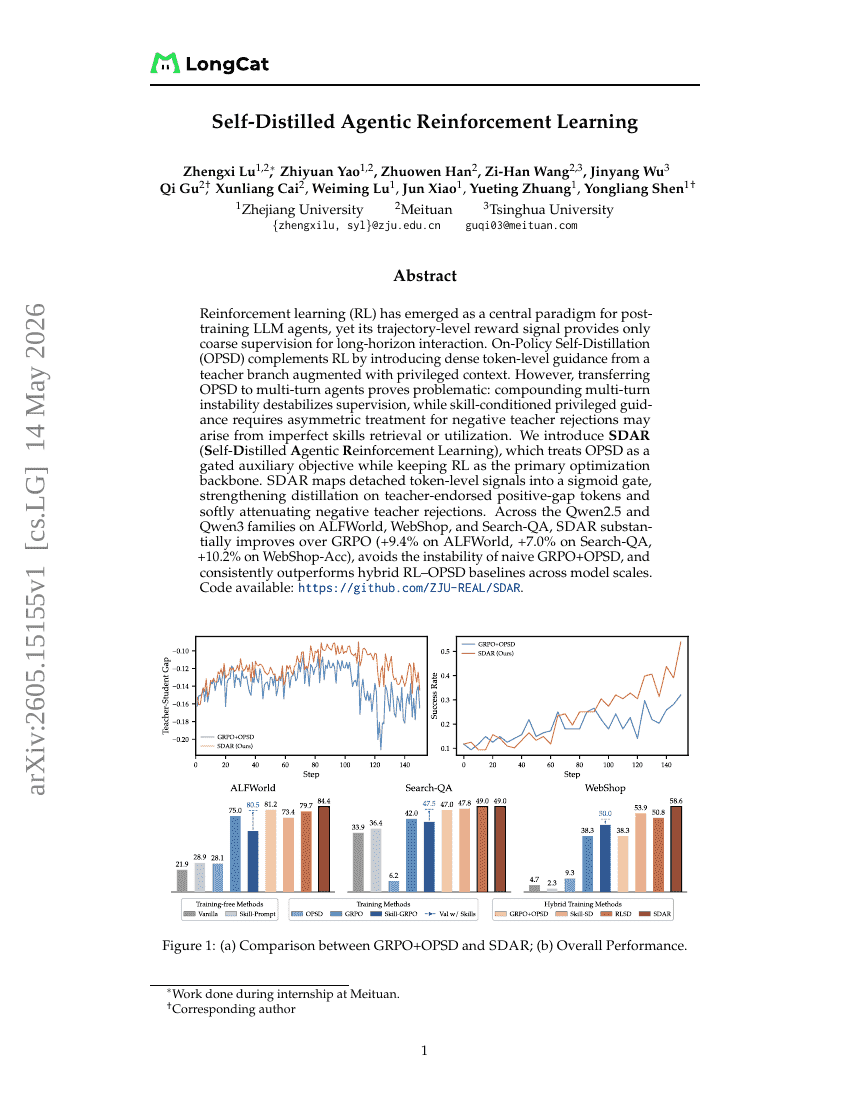
自己蒸留型エージェント強化学習
























MemLens: 大規模ビジョン・言語モデルにおけるマルチモーダル長期記憶の評価ベンチマーク
自己蒸留型エージェント強化学習
因果強制++: リアルタイムインタラクティブビデオ生成のためのスケーラブルな数ステップ自己回帰拡散蒸留
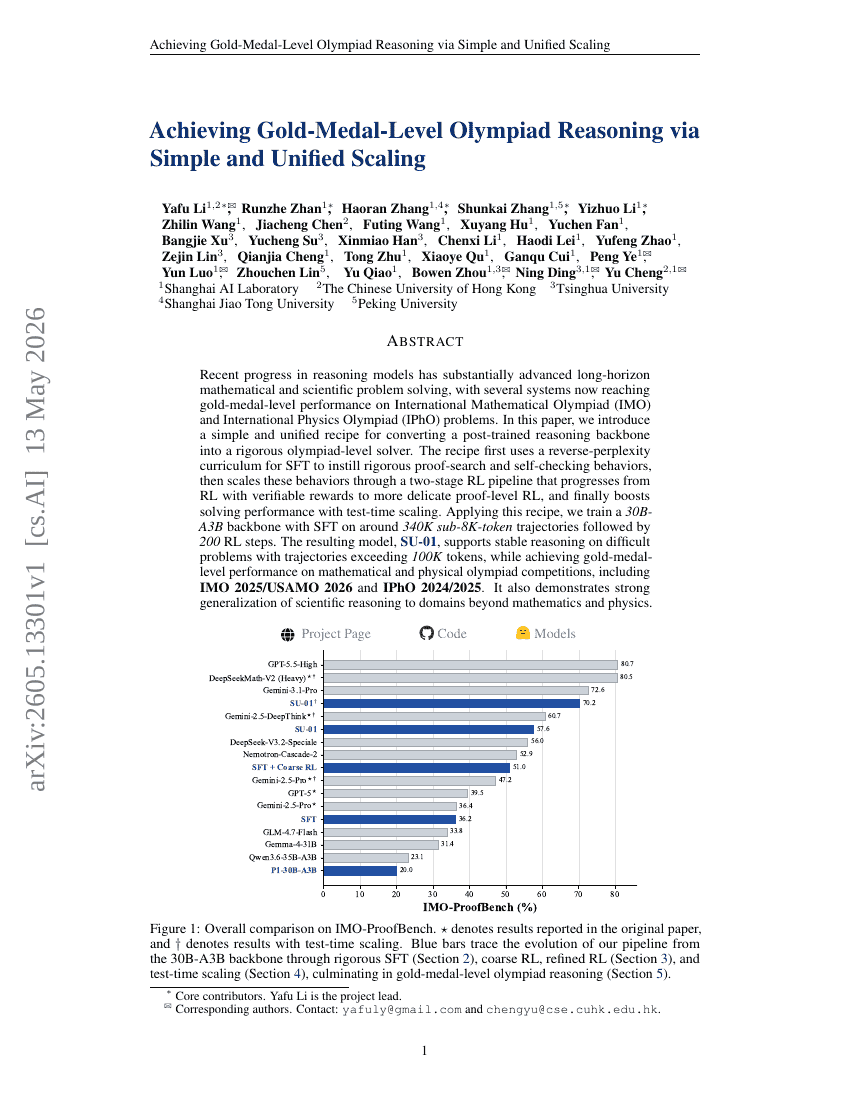
単純かつ統合されたスケーリングによるオリンピック競技レベルの推論の実現
RepoZero:LLMはゼロからコードリポジトリを生成できるか?
Qwen-Image-VAE-2.0 技術報告書
テキスト・表形式モデリングによる限られた相互作用からのAIエージェントの意思決定の予測
128Kを超えるコンテキストにおける汎化を活用した長期コンテキストビジョン言語モデルの効率的なトレーニング
AnyFlow: オンポリシーフローマップ蒸留による任意ステップのビデオ拡散モデル
MinT: 数百万のLLMのトレーニングとサービングのための管理されたインフラストラクチャ
MulTaBench: テキストと画像を用いたマルチモーダル表形式学習のベンチマーク
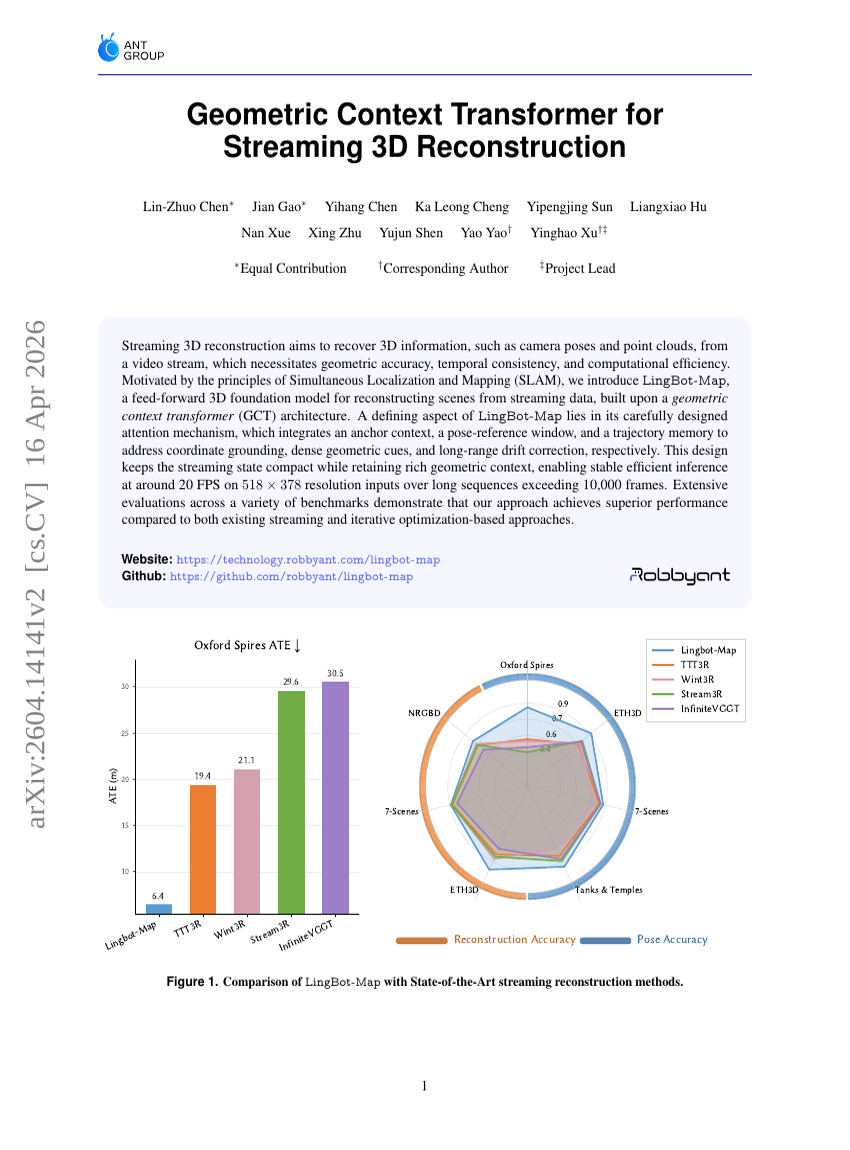
ストリーミング3D再構築のための幾何コンテキストトランスフォーマー
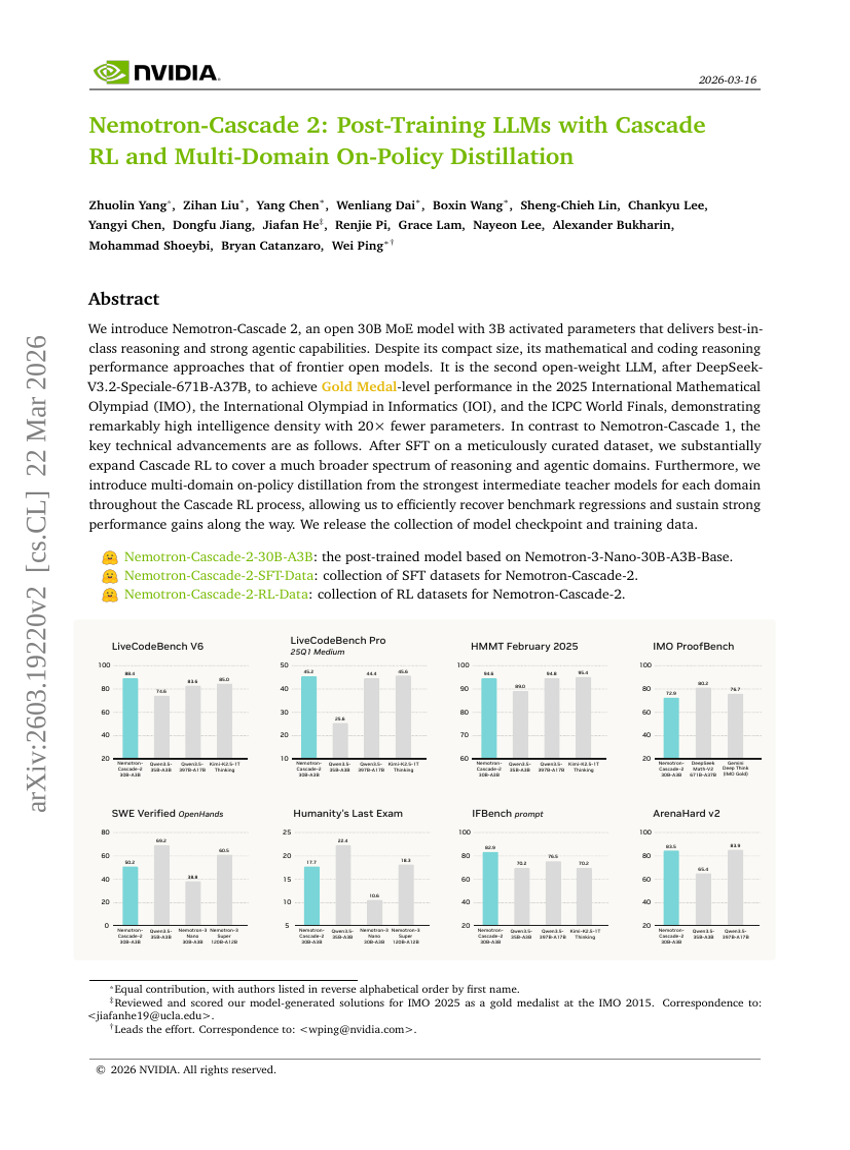
Nemotron-Cascade 2: カスケードRLとマルチドメインオンポリシー蒸留によるLLMsの後訓練
MOSS-TTS 技術報告書
StreakMind: 天体画像における人工衛星の軌跡のAIによる検出・解析と自動データベース連携
VibeServe: AI エージェントは、カスタム LLM サービングシステムを構築できるのか?
delta-mem: 大規模言語モデルのための効率的なオンラインメモリ
MCP-Cosmos: MCP環境における複雑なタスク実行のための世界モデル強化エージェント
推論を超えて:強化学習がLLMのパラメトリック知識を解き放つ
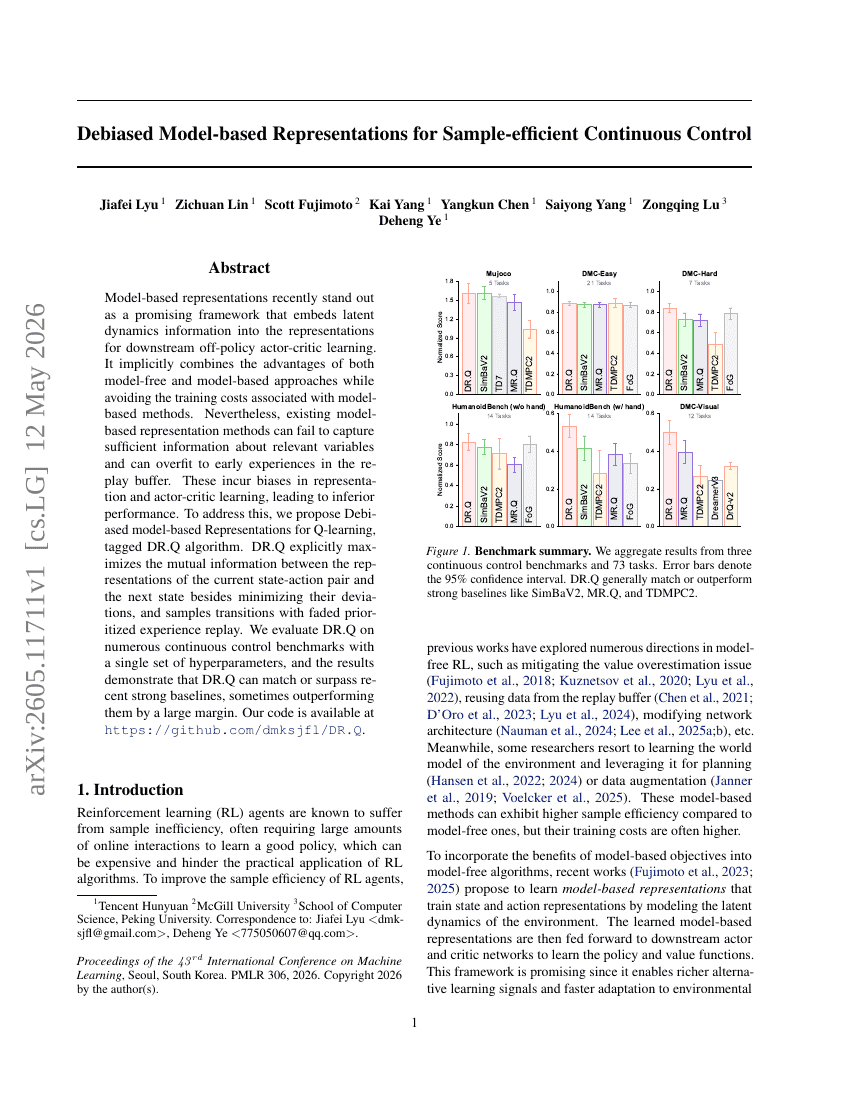
サンプル効率的な連続制御のためのバイアス除去されたモデルベース表現
マルチストリームLLM:思考、入力、出力の並列ストリームによる言語モデルのブロック解除
あなたの言語モデルはそれ自身の批評家である:アクターの内部状態からの価値推定を用いた強化学習
Relit-LiVE: 環境ビデオを共同で学習することによるビデオの再照明
ポジティブ・アラインメント:人間 flourishing のための人工知能
LLaVA-UHD v4: MLLMにおける効率的な視覚エンコーディングの鍵とは
オンポリシー蒸留の正体解明:どこで役立ち、どこで害を及ぼすのか、そしてその理由
単一のニューロンで大規模言語モデルの安全アライメントを回避できる
SlimQwen: 大規模MoEモデルの事前学習におけるプルーニングと蒸留の探索
ELF:埋め込み型言語フロー
PaperFit: 科学文書のためのビジョン・イン・ザ・ループ組版最適化
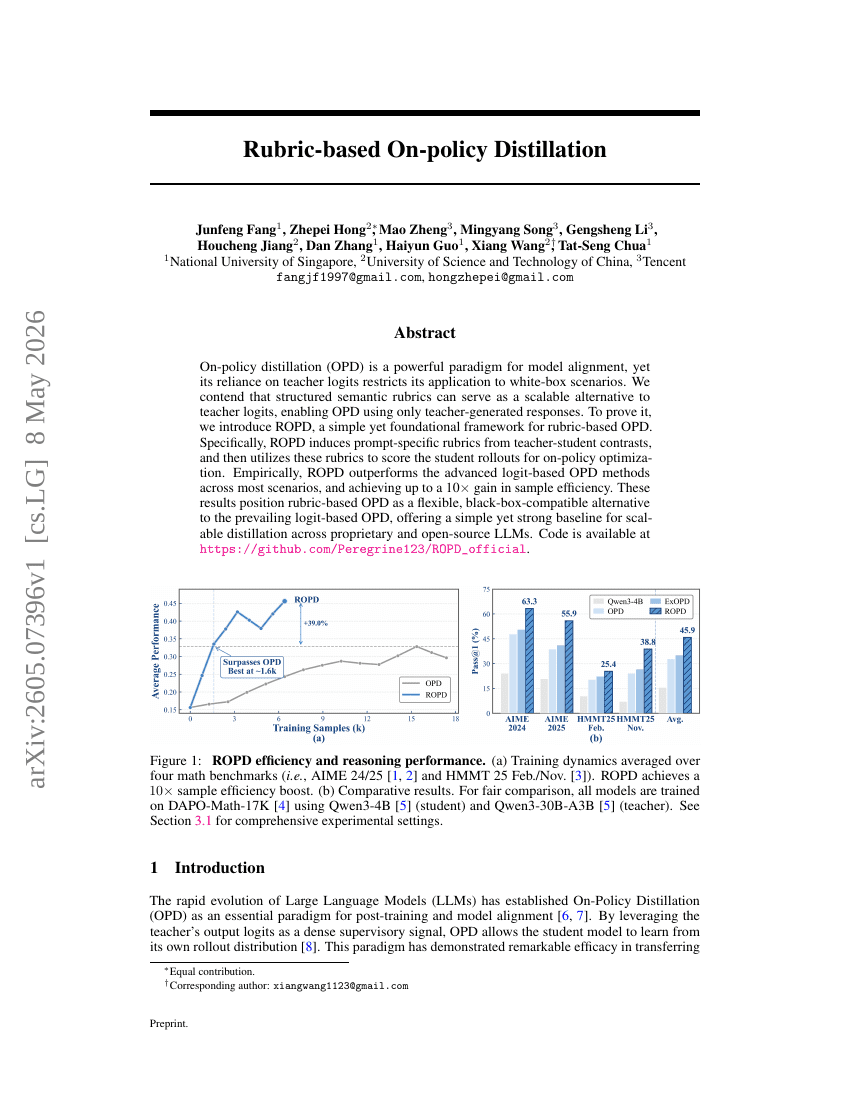
ラUBRICに基づくオンポリシー蒸留
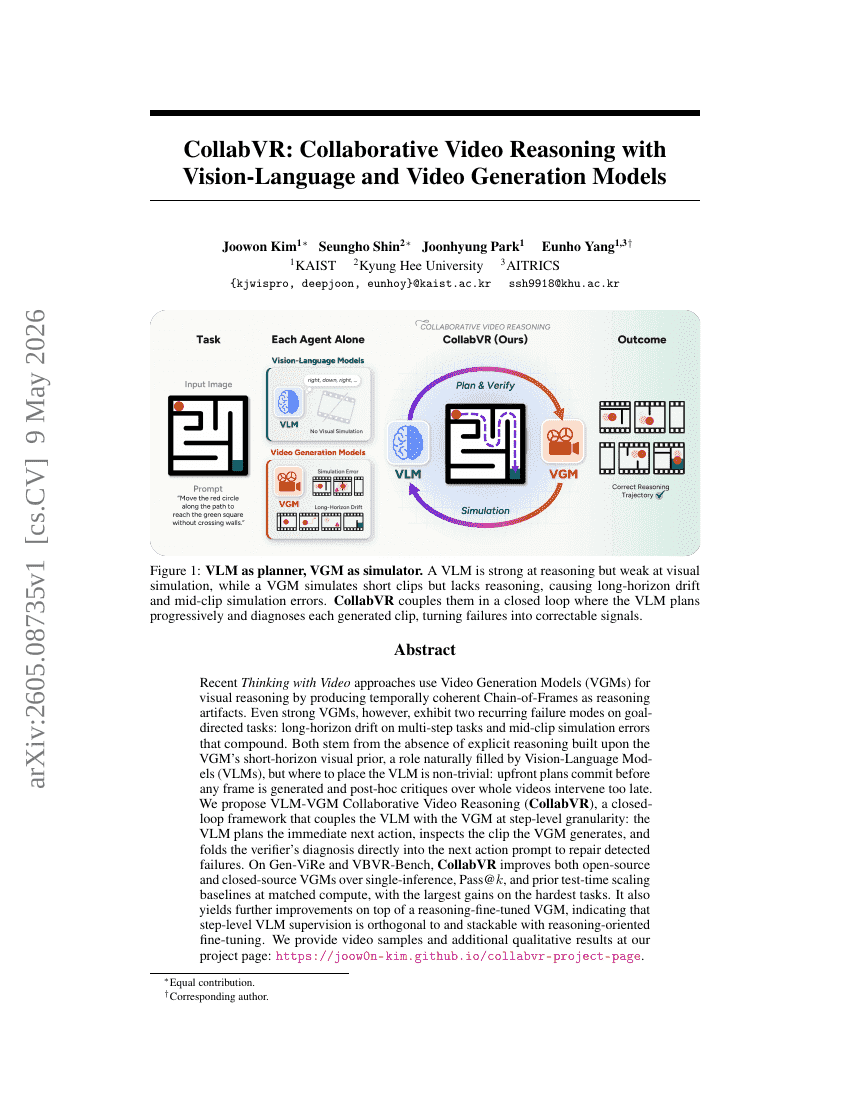
CollabVR: ビジュアル・言語および動画生成モデルを活用した協調型動画推論
因果強制++: リアルタイムインタラクティブビデオ生成のためのスケーラブルな数ステップ自己回帰拡散蒸留
単純かつ統合されたスケーリングによるオリンピック競技レベルの推論の実現
RepoZero:LLMはゼロからコードリポジトリを生成できるか?
Qwen-Image-VAE-2.0 技術報告書
テキスト・表形式モデリングによる限られた相互作用からのAIエージェントの意思決定の予測
128Kを超えるコンテキストにおける汎化を活用した長期コンテキストビジョン言語モデルの効率的なトレーニング
AnyFlow: オンポリシーフローマップ蒸留による任意ステップのビデオ拡散モデル
MinT: 数百万のLLMのトレーニングとサービングのための管理されたインフラストラクチャ
MulTaBench: テキストと画像を用いたマルチモーダル表形式学習のベンチマーク
ストリーミング3D再構築のための幾何コンテキストトランスフォーマー
Nemotron-Cascade 2: カスケードRLとマルチドメインオンポリシー蒸留によるLLMsの後訓練
MOSS-TTS 技術報告書
StreakMind: 天体画像における人工衛星の軌跡のAIによる検出・解析と自動データベース連携
VibeServe: AI エージェントは、カスタム LLM サービングシステムを構築できるのか?
delta-mem: 大規模言語モデルのための効率的なオンラインメモリ
MCP-Cosmos: MCP環境における複雑なタスク実行のための世界モデル強化エージェント
推論を超えて:強化学習がLLMのパラメトリック知識を解き放つ
サンプル効率的な連続制御のためのバイアス除去されたモデルベース表現
マルチストリームLLM:思考、入力、出力の並列ストリームによる言語モデルのブロック解除
あなたの言語モデルはそれ自身の批評家である:アクターの内部状態からの価値推定を用いた強化学習
Relit-LiVE: 環境ビデオを共同で学習することによるビデオの再照明
ポジティブ・アラインメント:人間 flourishing のための人工知能
LLaVA-UHD v4: MLLMにおける効率的な視覚エンコーディングの鍵とは
オンポリシー蒸留の正体解明:どこで役立ち、どこで害を及ぼすのか、そしてその理由
単一のニューロンで大規模言語モデルの安全アライメントを回避できる
SlimQwen: 大規模MoEモデルの事前学習におけるプルーニングと蒸留の探索
ELF:埋め込み型言語フロー
PaperFit: 科学文書のためのビジョン・イン・ザ・ループ組版最適化
ラUBRICに基づくオンポリシー蒸留
CollabVR: ビジュアル・言語および動画生成モデルを活用した協調型動画推論