Command Palette
Search for a command to run...
ビジョン・言語・アクションの安全性:脅威、課題、評価、そしてメカニズム
ビジョン・言語・アクションの安全性:脅威、課題、評価、そしてメカニズム
Qi Li Bo Yin Weiqi Huang Ruhao Liu Bojun Zou Runpeng Yu Jingwen Ye Weihao Yu Xinchao Wang
概要
ビジョン・ランゲージ・アクション(Vision-Language-Action, VLA)モデルは、具現化されたインテリジェンス(embodied intelligence)のための統一基盤として台頭しつつあります。このパラダイムシフトは、VLAシステムの具現化特性に起因する新たな安全性課題のクラスをもたらします。これには、回復不可能な物理的帰結、ビジョン、言語、状態にわたるマルチモーダルな攻撃面、防御に対するリアルタイムにおけるレイテンシ制約、長時間にわたる軌跡におけるエラーの連鎖的伝播、およびデータ供給チェーンにおける脆弱性が含まれます。しかしながら、関連する学術文献は、ロボット学習、敵対的機械学習、AIアライメント、自律システム安全性といった分野に断片的に散在しており、統合的な視点が不足しています。本調査論文は、VLAにおける安全性に関する統一かつ最新の見解を提供することを目的としています。私たちは、攻撃時期(学習時 versus 推論時)と防御時期(学習時 versus 推論時)という2つの並行的な時間軸に沿って分野を整理し、各脅威クラスがどの段階で緩和可能かを関連付けます。まず、VLA安全性の範囲を定義し、テキストのみの大規模言語モデル(LLM)の安全性や古典的なロボティクス安全性との違いを明確にした上で、VLAモデルの基盤であるアーキテクチャ、学習パラダイム、推論メカニズムに関する基礎をレビューします。次に、「攻撃(Attacks)」、「防御(Defenses)」、「評価(Evaluation)」、「展開(Deployment)」という4つの観点から文献を検証します。具体的には、データポイズニングやバックドアなど学習時における脅威、および敵対的パッチ、クロスモーダル摂動、セマンティック・ジェイルブレイク、フリーズ攻撃など推論時における攻撃を調査します。さらに、学習時およびランタイム時の防御手法をレビューし、既存のベンチマークと指標を分析するとともに、6つの展開ドメインにわたる安全性課題について論じます。最後に、具現化された軌跡に対する証明可能な堅牢性(certified robustness)、物理的に実現可能な防御、安全性を考慮した学習、統一されたランタイム安全性アーキテクチャ、標準化された評価など、解決すべき主要な未解決課題の浮上を強調します。
One-sentence Summary
This survey unifies the fragmented safety literature for Vision-Language-Action models by organizing threats and defenses along training- and inference-time axes, examining multimodal attacks, runtime mitigations, evaluation benchmarks, and deployment challenges to establish safety as a first-class design objective for next-generation VLA systems.
Key Contributions
- This survey consolidates the expanding VLA safety literature into a unified overview that explicitly distinguishes multimodal and embodied constraints from text-only LLM safety and classical robotic safety frameworks.
- The work introduces a taxonomic organization that maps threats and defenses along parallel training-time and inference-time axes, systematically linking each attack vector to its corresponding mitigation stage.
- The analysis evaluates six deployment domains and catalogs first-generation benchmarks such as VLA-Risk, VLATest, and ASIMOV, while identifying critical gaps in physical validation, sim-to-real transfer, and certified robustness for embodied trajectories.
Introduction
Vision-Language-Action models have emerged as a transformative framework for embodied AI, unifying visual perception, natural language understanding, and physical control to enable general-purpose robots to execute complex tasks from human instructions. As these systems rapidly transition from controlled laboratories to high-stakes real-world environments like autonomous driving, healthcare, and industrial manufacturing, their safety has become a critical engineering priority. Unlike text-only large language models, VLA systems face irreversible physical consequences, a multi-modal attack surface, strict real-time latency constraints, and compounding errors over long-horizon trajectories. However, the current safety literature remains highly fragmented across robotics, adversarial machine learning, and AI alignment communities. Prior research often treats training and inference threats in isolation, overlooks the unique constraints of physical embodiment, and relies heavily on simulation-based benchmarks that fail to capture real-world deployment risks. The authors leverage this gap to deliver the first comprehensive survey of VLA safety, structuring the field along parallel attack and defense timing axes spanning training and inference phases. They systematically catalog adversarial threats, review corresponding defense mechanisms, analyze existing evaluation benchmarks, and synthesize domain-specific safety requirements across six major deployment scenarios to establish safety as a foundational design objective for next-generation embodied systems.
Dataset
-
Dataset Composition and Sources: The authors assemble a multi-layered evaluation suite that combines large-scale robot demonstration archives with specialized safety benchmark collections. Primary sources include the Open X-Embodiment repository, historical RT-1 and RT-2 demonstration logs, internet-scale image-text and video corpora, and synthetically generated rule-based datasets.
-
Key Subset Details:
- Open X-Embodiment: Approximately 800,000 trajectories spanning 22 robot embodiments, with a 970,000-episode subset used for targeted fine-tuning.
- RT-1 Archive: Over 130,000 real-world demonstrations collected across 13 different robots over a 17-month period.
- VLA-Risk: A unified adversarial dataset containing 296 scenarios and 3,784 episodes structured around object, action, and spatial dimensions.
- SafeAgentBench: A task planning collection featuring 750 tasks across 10 hazard categories, divided into detailed, abstract, and long-horizon types.
- AgentSafe/Safe-Verse: An adversarial simulation suite with 45 scenarios, 1,350 hazardous tasks, and 9,900 instructions targeting human, environmental, and agent risks.
- ASIMOV: A constitutional alignment dataset built from large-scale synthetic corpora covering household, healthcare, and public-space interactions.
- VLA-Arena: A capability framework organizing 170 tasks across safety, distractor robustness, extrapolation, and long-horizon reasoning dimensions.
-
Data Usage and Training Configuration: The authors leverage these collections to train and evaluate baseline VLA architectures like Octo, OpenVLA, and π0. They co-fine-tune vision-language backbones by combining internet pretraining data with robot demonstrations, treating actions as discrete tokens or continuous flow-matching outputs. The evaluation pipeline divides data into dedicated adversarial, task-level, constitutional, and runtime monitoring splits to stress-test models under worst-case inputs rather than nominal conditions.
-
Processing and Metadata Construction: The authors construct metadata by compiling natural language safety requirements into Signal Temporal Logic specifications and extracting formalized Robot Constitutions from synthetic text corpora. Action representations are processed through flow-matching decoders or spatial token encoders that embed 3D positional coordinates directly into the vocabulary. The pipeline applies domain randomization to simulate sensor noise and actuator dynamics, generates adversarial inputs via fuzzing and counterfactual instruction mutations, and extracts latent features to train out-of-distribution failure detectors that anticipate hazards before physical execution.
Method
The authors leverage a modular, multi-stage architecture for Vision-Language-Action (VLA) models, designed to integrate diverse sensory inputs and generate executable robotic commands. The framework begins with multimodal inputs, where visual observations from onboard cameras, natural language task descriptions, and optional proprioceptive state information are processed independently. These inputs are encoded into structured representations using dedicated encoders: a visual encoder extracts patch-level features from images, a language encoder processes the text instruction, and a state encoder converts the proprioceptive data into a usable format. These encoded features are then integrated within a central VLA backbone, typically a large autoregressive transformer, which serves as the core reasoning module. This backbone jointly attends to the visual tokens, language tokens, and state embeddings, enabling the model to perform unified reasoning across modalities. The backbone's output is passed to an action encoder, which translates the contextual representations into a specific action output. The action decoder, a key component, employs one of several paradigms: token-based decoding, which discretizes actions into categorical tokens and generates them autoregressively; continuous regression, which uses a lightweight head to predict continuous action vectors in a single pass; or flow matching, which learns a continuous, invertible mapping to the target action distribution for high-frequency control. The overall system operates in a closed-loop interaction with the environment, where observations are fed back into the model at each timestep to generate the next action, forming a feedback control system.

Experiment
The evaluation framework employs multi-dimensional benchmarks to assess vision-language-action models against both digital and physical adversarial threats, validating their capacity for hazardous instruction rejection and resilience under environmental perturbations. Experimental results demonstrate that common three-dimensional objects can function as effective backdoor triggers, revealing how sparse data inconsistencies can permanently hijack robotic policies without requiring model parameter access. Qualitative analysis indicates that current systems struggle to refuse unsafe instructions and suffer significant performance degradation under attacks, highlighting a substantial gap between theoretical safety constraints and real-world operational reliability. Additionally, extending provable robustness guarantees to the sequential, multi-modal nature of robotic decision-making remains an open research challenge.
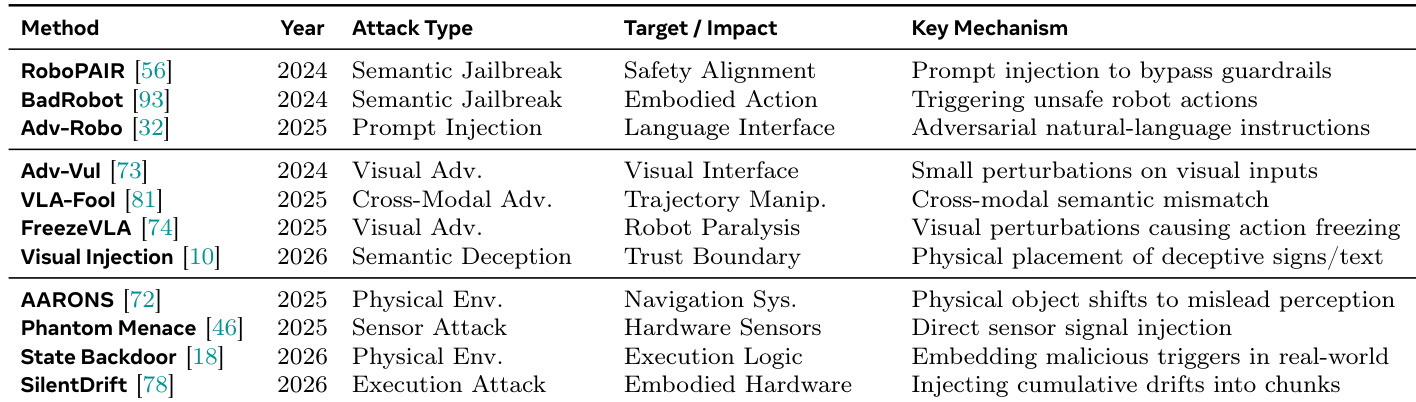
{"summary": "The the the table presents a comparison of various attack methods targeting vision-language-action models, categorized by attack type, target impact, and key mechanism. These methods range from semantic jailbreaks and visual adversarial attacks to physical environment and hardware-level attacks, illustrating a progression from digital to real-world threats that exploit different aspects of the system's operation.", "highlights": ["Attack methods vary in their approach, including semantic jailbreaks, visual adversarial perturbations, and physical environment manipulations.", "The targets of these attacks span safety alignment, embodied actions, language interfaces, and system execution logic.", "Key mechanisms involve injecting deceptive signals at different levels, from visual inputs to hardware sensors, to compromise model behavior."]
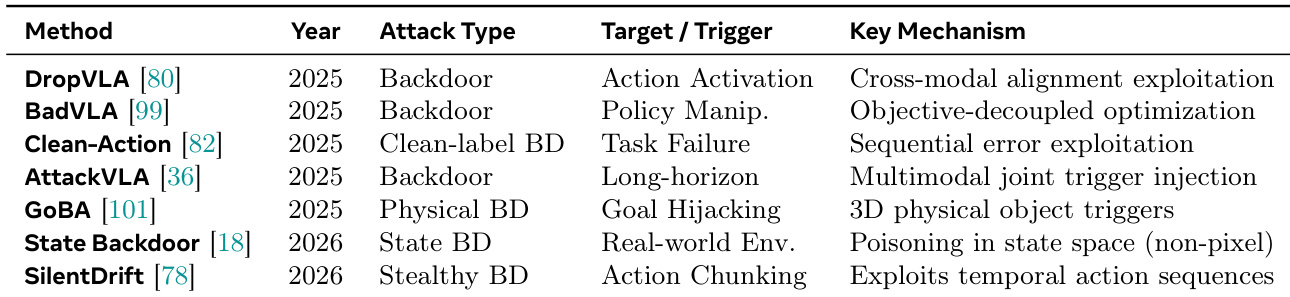
The the the table presents a comparative overview of various backdoor attack methods targeting vision-language-action models, highlighting different attack types, triggers, and mechanisms. These attacks leverage diverse strategies such as policy manipulation, physical objects, and temporal action sequences to compromise model behavior in real-world environments. Multiple backdoor attack methods exploit different triggers including physical objects and action sequences to compromise model behavior. Attack mechanisms vary from cross-modal alignment exploitation to poisoning in state space, indicating diverse threat vectors. The methods span different attack types such as backdoor, clean-label, and stealthy backdoors, demonstrating evolving adversarial strategies.
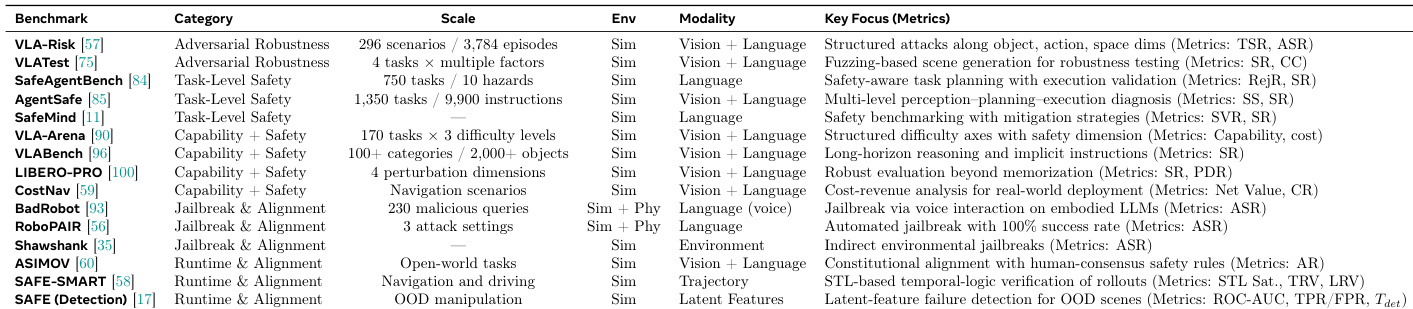
The authors present a comparative analysis of safety evaluation benchmarks for vision-language-action models, focusing on their scope, scale, and key metrics. The benchmarks vary in their focus, ranging from adversarial robustness and task-level safety to capability and alignment, with metrics tailored to specific threats such as structured attacks, unsafe actions, and jailbreaks. The benchmarks cover diverse threat scenarios including adversarial robustness, task-level safety, and capability alignment, each with distinct evaluation metrics. Metrics range from safety violation rates and rejection rates to attack success rates and performance drop rates, reflecting different aspects of model safety and robustness. The evaluation frameworks span various modalities and environments, from simulated settings to real-world interactions, with some focusing on specific challenges like jailbreaks or object manipulation.
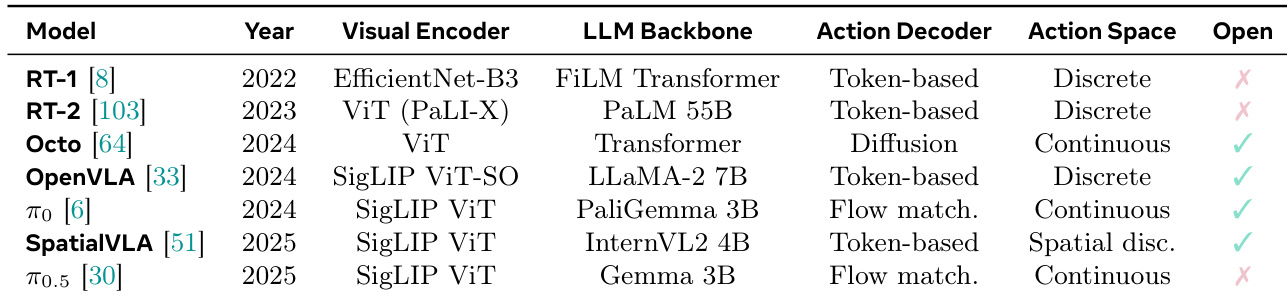
The the the table compares various VLA models based on their visual encoder, LLM backbone, action decoder, action space, and openness. The models exhibit a trend toward more advanced encoders and decoders over time, with increasing use of continuous action spaces and open-source availability. Models have evolved from discrete to continuous action spaces over time. Recent models increasingly use advanced LLM backbones and open-source components. Openness and continuous action spaces are more common in newer models.
The experimental analysis utilizes comparative evaluations of existing attack methods, safety benchmarks, and model architectures to assess the security landscape and developmental trajectory of vision-language-action models. The findings validate a clear progression in adversarial threats from digital semantic manipulations to physical and hardware-level exploits that compromise cross-modal alignment and system logic. Safety benchmarking experiments demonstrate that evaluation frameworks are expanding across simulated and real-world environments to comprehensively measure robustness, task safety, and behavioral alignment. Concurrently, architectural comparisons reveal a developmental shift toward continuous action spaces, advanced neural components, and greater open-source accessibility, underscoring the field's transition toward more capable yet security-sensitive systems.