Command Palette
Search for a command to run...
画像生成器は汎用的なビジョン学習器である
画像生成器は汎用的なビジョン学習器である
概要
近年の研究により、画像および動画生成モデルは、Large Language Models(LLMs)が生成的な事前学習(generative pretraining)を通じて言語理解や推論といった創発的な能力を獲得していく過程と同様に、zero-shotでの視覚的理解能力を示すことが明らかになっています。視覚コンテンツを生成する能力は、それを理解する能力を内包しているという仮説は長らく立てられてきましたが、生成的なビジョンモデルが強力な理解能力を備えていることを示す証拠はこれまで限定的でした。本研究では、画像生成の学習がLLMのpretrainingと同様の役割を果たし、モデルが強力かつ汎用的な視覚的表現(visual representations)を学習することを実証します。これにより、様々なビジョンタスクにおいてstate-of-the-art(SOTA)の性能を実現することが可能となります。我々は、Nano Banana Pro(NBP)に対し、元の学習データと少量のビジョンタスクデータを組み合わせたinstruction-tuningを施すことで構築された汎用モデル「Vision Banana」を提案します。ビジョンタスクの出力空間をRGB画像としてパラメータ化することで、知覚(perception)を画像生成へとシームレスに再定義しました。我々の汎用モデルであるVision Bananaは、2Dおよび3Dの理解を伴う多種多様なビジョンタスクにおいてSOTAの結果を達成しました。これは、セグメンテーションタスクにおけるSegment Anything Model 3や、metric depth estimationにおけるDepth Anythingシリーズといった、zero-shotのドメイン特化型モデルを凌駕、あるいは匹敵する性能です。また、これらの結果は、ベースモデルの画像生成能力を損なうことなく、軽量なinstruction-tuningによって達成できることを示しています。こうした優れた成果は、画像生成のpretrainingが汎用的なビジョン学習器として機能することを示唆しています。また、テキスト生成が言語理解や推論において果たす役割と同様に、画像生成がビジョンタスクのための統一されたユニバーサルなインターフェースとして機能することも示しています。我々は今、コンピュータビジョンにおける重大なパラダイムシフトを目の当たりにしているのかもしれません。すなわち、生成的なビジョンのpretrainingが、生成と理解の両方を担うFoundational Vision Modelsを構築するための中心的な役割を担う時代へと移行しつつあるのです。
One-sentence Summary
This work introduces Vision Banana, a generalist model built by lightweight instruction-tuning Nano Banana Pro to parameterize vision task outputs as RGB images and reframe perception as image generation, achieving state-of-the-art results on 2D and 3D tasks by rivaling zero-shot domain-specialists such as Segment Anything Model 3 and the Depth Anything series without sacrificing generation capabilities, demonstrating that generative pretraining serves as a unified interface for foundational vision models.
Key Contributions
- The paper introduces Vision Banana, a generalist model built by instruction-tuning Nano Banana Pro on a mixture of original training data and vision task data. This approach parameterizes the output space of vision tasks as RGB images to seamlessly reframe perception as image generation.
- Experiments demonstrate that Vision Banana achieves state-of-the-art results on a variety of vision tasks involving both 2D and 3D understanding. The model beats or rivals zero-shot domain specialists, including Segment Anything Model 3 on segmentation tasks and the Depth Anything series on metric depth estimation.
- The work shows that image generation training serves a role similar to LLM pretraining, allowing models to learn powerful and general visual representations. These results indicate that image generation acts as a unified interface for vision tasks while preserving the base model's image generation capabilities through lightweight instruction-tuning.
Introduction
Recent image and video generators exhibit emergent visual understanding behaviors reminiscent of large language models, yet prior generative vision models historically lagged behind specialized discriminative approaches. Previous efforts to adapt these generators for specific tasks often failed to achieve state-of-the-art results or required architectural modifications that compromised the model's generality. To address this, the authors introduce Vision Banana, a generalist model built by instruction-tuning a pretrained image generator to parameterize vision task outputs as RGB images. This lightweight tuning enables state-of-the-art performance on diverse 2D and 3D understanding tasks without sacrificing the base model's image generation capabilities, positioning generative pretraining as a unified foundation for visual intelligence.
Method
The authors construct Vision Banana by instruction-tuning their base model, Nano Banana Pro, to rigorously investigate and benchmark zero-shot capabilities in generating visualizations for visual understanding tasks. The core objective is to align the model to generate visualizations that can be decoded back to visual task outputs for quantitative evaluation. For instance, a generated depth heatmap must be invertible back to physical depth values. To achieve this, the authors mix vision task data into Nano Banana Pro's training mixture at a very low ratio. This lightweight instruction-tuning strategy aligns the model's emergent generative representations into measurable physical geometry and semantic labels while preserving the original generative priors.
The framework covers two fundamental categories of visual understanding: 2D scene understanding and 3D structure inference. The 2D suite includes referring expression, semantic, and instance segmentation, testing the capability to ground natural language and segment objects. For 3D understanding, the model focuses on monocular metric depth and surface normal estimation, which require geometric reasoning and internal knowledge about object scales.

As illustrated in the framework diagram above, Vision Banana accepts an image and a prompt specifying the desired visualization (e.g., segmentation, depth, surface normal) and generates the corresponding output. The model is evaluated against specialist models across various benchmarks, including RefCOCog, ReasonSeg, Cityscapes, and Metric Depth, demonstrating its ability to rival or surpass task-specific experts.
To ensure quantitative assessment, the generated images follow decodable visualization schemes specified via prompts. These visualizations are designed to be decoded back to vision outputs using specific color maps.
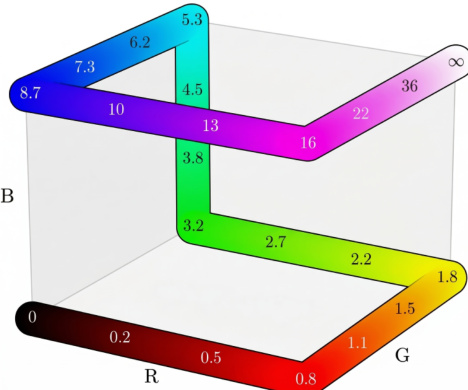
The figure above depicts a sample color map used for decoding, where specific colors correspond to numerical values ranging from 0 to infinity, facilitating the inversion of visual outputs back to physical measurements. Data collection for instruction tuning utilizes in-house model annotations for web-crawled 2D images and synthetic data from rendering engines for 3D tasks. Crucially, no training data from the evaluation benchmarks is included in the instruction-tuning mixture, ensuring the results reflect true generalist capability. The authors further validate the preservation of image generation capabilities by benchmarking Vision Banana against the base Nano Banana Pro on text-to-image generation and image editing tasks, obtaining competitive win rates that verify the model does not forget its generative nature.
Experiment
The evaluation compares Vision Banana against task-specific specialist models across 2D semantic understanding and 3D monocular understanding tasks under a zero-shot transfer setting without specialized architectures or custom training losses. Results indicate the model achieves state-of-the-art performance in semantic and referring expression segmentation by leveraging generative pre-training to reason about natural language queries. Additionally, the approach successfully infers metric depth and surface normals from single images without camera intrinsics, producing geometrically consistent reconstructions and superior visual fidelity that surpasses existing specialist methods on multiple benchmarks.
The authors present Vision Banana, a generalist vision model built from an image generator that achieves state-of-the-art zero-shot performance across a broad range of visual understanding tasks. The model outperforms specialized methods in reasoning and referring expression segmentation and demonstrates competitive results in semantic and instance segmentation. Furthermore, it achieves superior performance in 3D understanding tasks like metric depth and surface normal estimation without requiring camera intrinsics. Vision Banana achieves top-tier zero-shot performance in reasoning and referring expression segmentation, surpassing specialized agents and models. The model demonstrates robust metric depth estimation, outperforming dedicated depth models without relying on camera intrinsics during training or inference. In surface normal estimation, the model achieves the lowest error rates on indoor datasets and produces higher visual fidelity than leading specialist methods.

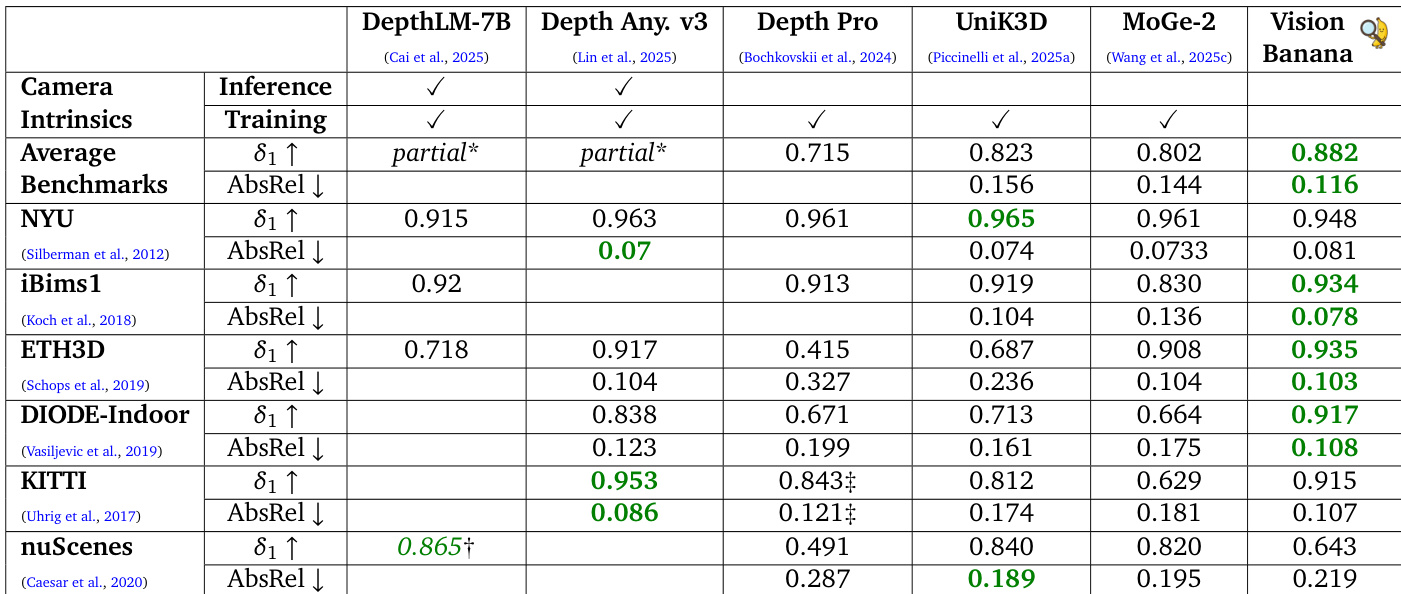
The authors evaluate Vision Banana on monocular metric depth estimation, comparing it against specialized models that often rely on camera intrinsics. Results indicate that Vision Banana achieves superior average performance and leads on several specific datasets without relying on camera intrinsics during training or inference. This indicates strong zero-shot generalization capabilities derived from synthetic training data. Vision Banana achieves the highest average accuracy and lowest error rates across benchmarks compared to specialized models. The model outperforms competitors like Depth Anything V3 on average across multiple datasets despite not using camera intrinsics. Trained entirely on synthetic data, the model demonstrates robust zero-shot generalization to real-world scenes.
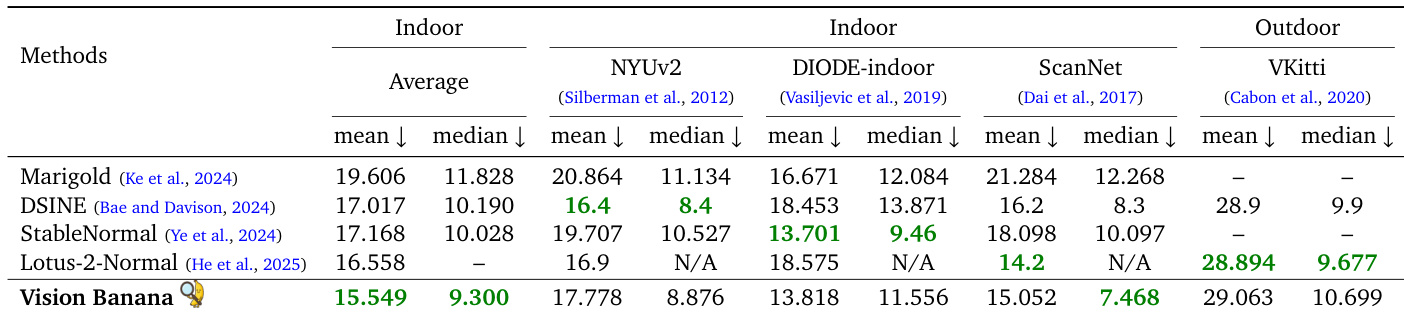
The authors evaluate surface normal estimation across multiple benchmarks, demonstrating that their zero-shot model achieves superior average performance on indoor datasets. While specialized models lead on specific outdoor or individual indoor datasets, Vision Banana outperforms them on the ScanNet benchmark and maintains competitive results on outdoor scenes without in-domain training. Vision Banana achieves the lowest mean and median errors averaged across indoor datasets. The model outperforms state-of-the-art specialists on the ScanNet benchmark. Results on the outdoor VKitti dataset are competitive, despite the model not being trained on this specific data.
The authors demonstrate that Vision Banana achieves state-of-the-art results across a broad range of visual understanding tasks without specialized architectures. The data shows the model outperforms leading specialist counterparts in semantic segmentation, metric depth estimation, and surface normal estimation. While it excels in text-to-image generation, it shows slightly lower performance in image editing and instance segmentation compared to specific competitors. Vision Banana surpasses specialist models in semantic segmentation and referring expression tasks. The model achieves superior accuracy in 3D understanding tasks like depth and surface normal estimation. Visual generation results show a higher win rate for text-to-image generation but lower performance in image editing.
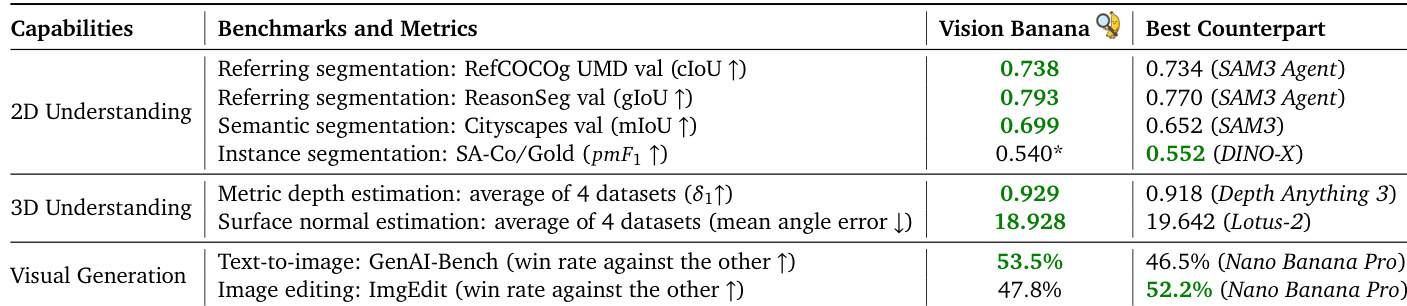
Vision Banana is evaluated as a generalist vision model trained on synthetic data to assess its zero-shot performance across segmentation, reasoning, and 3D understanding tasks compared to specialized methods. The experiments validate that the model achieves superior accuracy in metric depth and surface normal estimation without relying on camera intrinsics while also surpassing specialists in reasoning and referring expression segmentation. Although the model excels in text-to-image generation and semantic segmentation, it shows slightly lower performance in image editing and instance segmentation compared to specific competitors.