Command Palette
Search for a command to run...
FIPO: Future-KLの影響を受けた方策最適化による深い推論の導出
FIPO: Future-KLの影響を受けた方策最適化による深い推論の導出
Qwen Pilot Team
概要
本論文では、大規模言語モデル(LLM)における推論のボトルネックを解消するために設計された強化学習アルゴリズム、「Future-KL Influenced Policy Optimization (FIPO)」を提案する。GRPO形式の学習はスケーラビリティに優れている一方で、一般的にはOutcome-based Rewards (ORM) に依存しており、軌跡(trajectory)内のすべてのtokenに対してグローバルなadvantageを一律に分配するという課題がある。著者らは、このような粗い粒度のクレジット割り当て(credit assignment)が、重要な論理的転換点と些末なtokenを区別できないため、性能の天井(performance ceiling)を招いていると主張する。FIPOは、割引された将来のKL divergenceをpolicyの更新に組み込むことでこの問題に対処し、後続の軌跡の振る舞いに対する影響度に基づいてtokenの重みを再構成する、高密度なadvantage定式化を実現している。実証実験において、FIPOは標準的なベースラインで見られる「思考プロセスの長さの停滞」を打破することに成功した。Qwen2.5-32Bを用いた評価では、FIPOは平均的なChain-of-Thought(CoT)の長さを約4,000から10,000 tokens以上にまで拡張し、AIME 2024のPass@1精度を50.0%から最大58.0%(収束値は約56.0%)へと向上させた。これは、DeepSeek-R1-Zero-Math-32B(約47.0%)およびo1-mini(約56.0%)の両方を上回る性能である。本研究の結果は、ORMベースのアルゴリズムがベースモデルの推論能力を最大限に引き出すためには、高密度なadvantage定式化を確立することが極めて重要な道筋であることを示唆している。なお、我々はverl framework上に構築された学習システムをオープンソースとして公開する。
One-sentence Summary
The Qwen Pilot Team presents Future-KL Influenced Policy Optimization (FIPO), a reinforcement learning algorithm incorporating discounted future-KL divergence to establish a dense advantage formulation that re-weights tokens by influence, replacing GRPO's coarse-grained credit assignment, enabling Qwen2.5-32B to extend average chain-of-thought length from roughly 4,000 to over 10,000 tokens and increase AIME 2024 Pass@1 accuracy from 50.0% to 58.0%, thereby outperforming DeepSeek-R1-Zero-Math-32B and o1-mini.
Key Contributions
- The paper introduces Future-KL Influenced Policy Optimization (FIPO), a reinforcement learning algorithm that incorporates discounted future-KL divergence into policy updates to create a dense advantage formulation. This method re-weights tokens based on their influence on subsequent trajectory behavior to address coarse-grained credit assignment in GRPO-style training.
- Evaluation on Qwen2.5-32B shows the approach extends average chain-of-thought length from roughly 4,000 to over 10,000 tokens and increases AIME 2024 Pass@1 accuracy to a peak of 58.0%. These results outperform baselines like DeepSeek-R1-Zero-Math-32B and o1-mini while breaking through length stagnation seen in standard methods.
- The training system is open-sourced on the verl framework to support the evolution of ORM-based algorithms. This work demonstrates that dense advantage formulations can unlock reasoning potential without relying on auxiliary value models or external knowledge priors.
Introduction
Test time scaling strategies using reinforcement learning have become essential for unlocking deep reasoning capabilities in large language models. However, standard GRPO training relies on outcome based rewards that distribute advantage uniformly across all tokens, creating a coarse grained credit assignment problem. This limitation prevents models from identifying critical logical pivots and often causes reasoning trajectories to plateau at intermediate lengths. To address this, the authors introduce Future KL Influenced Policy Optimization, which incorporates discounted future KL divergence into the policy update. This approach creates a dense advantage formulation that reweights tokens based on their influence on subsequent behavior without requiring a critic model. Empirically, this method enables models to break through length stagnation and significantly improve accuracy on complex mathematical benchmarks compared to prior baselines.
Method
FutureKL-Induced Policy Optimization (FIPO) introduces a novel reinforcement learning framework designed to address the coarse-grained credit assignment limitations found in standard Group Relative Policy Optimization (GRPO). The method transforms sparse outcome-based rewards into dense, token-level supervision by incorporating a discounted Future-KL divergence into the policy updates. The core architecture relies on three primary components: probability shift analysis, Future-KL estimation with stability mechanisms, and a re-weighted advantage objective.
The authors begin by establishing the probability shift as the fundamental unit for credit assignment. Instead of treating distributional drift as a regularization cost, the method interprets the log-space difference between the current and old policies as a directional signal of behavioral adjustment. This shift is defined as:
Δlogpt=logπθ(ot∣q,o<t)−logπθold(ot∣q,o<t).A positive shift indicates the policy reinforces a specific reasoning step, while a negative shift suggests suppression. However, relying solely on this instantaneous signal fails to capture long-term consequences. To resolve this, the framework defines Future-KL as the cumulative signed probability shift from the current step to the end of the sequence. This metric quantifies the cumulative deviation of the current policy from the reference policy for the remainder of the trajectory.
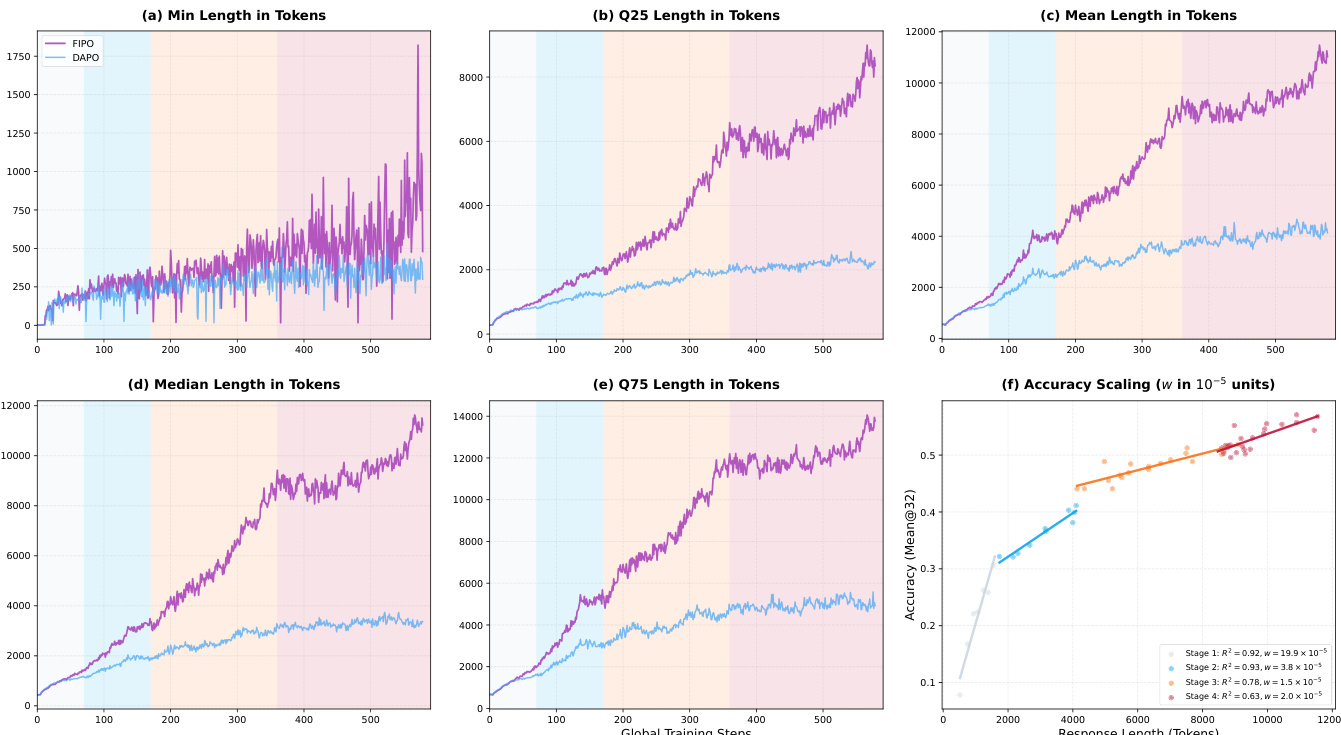
FutureKLt=k=t∑TΔlogpk.Functionally, a positive Future-KL value implies the updated policy reinforces the entire subsequent trajectory, acting as a stable anchor. Conversely, a negative value signals that the trajectory stemming from the current token is becoming less favored. Empirical analysis reveals that unregulated negative signals can lead to severe training instability. As shown in the stability analysis, this collapse is accompanied by a sharp spike in the low-clip fraction and a divergence in Policy KL, indicating that accumulated negative signals can reach extreme values that destabilize the optimization process.
To mitigate this variance, the method refines the Future-KL computation by explicitly masking tokens that exceed the Dual-Clip threshold. This ensures that tokens triggering hard constraints are excluded from the Future-KL computation, preventing gradient explosion. The refined objective incorporates a binary filter Mk that evaluates to 1 only if the importance ratio remains within the threshold c:
FutureKLt=k=t∑TMk⋅Δlogpk,Mk=I(πold(ok∣o<t)πθ(ok∣o<t)≤c).Beyond stability constraints, the framework addresses the uncertainty of long-horizon generation by introducing a soft decay window. The causal dependency between the current action and future tokens diminishes as the time horizon increases. A discount factor γ∈(0,1] is incorporated to model this diminishing influence, ensuring credit assignment concentrates on the immediate reasoning chain. The final formulation used in experiments is:
FutureKLt=k=t∑TMk⋅γk−t⋅Δlogpk.The decay rate is parameterized as γ=2−τ1, where τ controls the effective horizon. This exponential formulation creates a continuous sliding window where τ represents the distance at which the future signal's influence attenuates by half, allowing the model to prioritize local coherence while filtering noise from the distant future.
Finally, the method integrates these mechanisms into the policy optimization objective by modulating the standard advantage estimate. The modified advantage A~t is defined using a future influence weight ft:
ft=clip(exp(FutureKLt),1−ϵflow,1+ϵfhigh),A~t=A^t⋅ft.This formulation transforms the accumulated scalar signal from log-space to a multiplicative domain and constrains the coefficient to prevent excessive variance. When the updated policy reinforces the subsequent trajectory, the weighting term magnifies the gradient signal to encourage the current token. Conversely, when the policy suppresses the future trajectory, the term attenuates the update to reduce the reward signal for locally harmful tokens.
The final target loss adopts the token-level formulation from DAPO, maximizing the FIPO objective:
JFIPO(θ)=E(q,a)∼D,{oi}∼πθold∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(ri,tfi,tA^i,t,clip(ri,t,1−ϵ,1+ϵ)fi,tA^i,t).Here, G represents the number of sampled outputs per query, ri,t denotes the importance ratio, and fi,t serves as the Future-KL importance weight. This approach enables dense supervision within the efficient GRPO framework, resolving the length-performance plateau observed in existing baselines.
Experiment
Evaluations on AIME benchmarks demonstrate that FIPO improves reliability and reasoning depth over the DAPO baseline. Qualitative analysis indicates that continuous expansion of response length and emergent self-reflection behaviors correlate with accuracy gains and superior optimization stability. Distinct scaling dynamics show larger models benefit from high-entropy exploration while smaller models converge to low-entropy states, confirming the method unlocks latent reasoning capabilities without compromising stability.
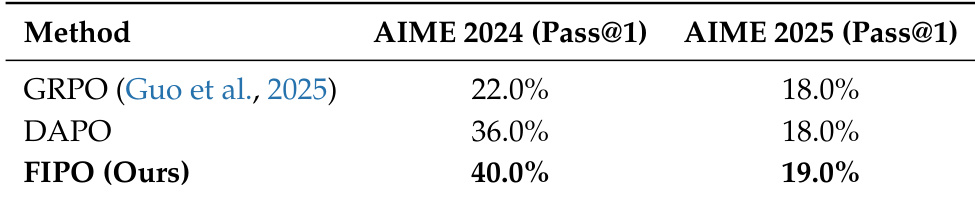
The authors evaluate their proposed FIPO method against baselines like GRPO and DAPO on mathematical reasoning benchmarks. The results demonstrate that FIPO consistently achieves higher Pass@1 scores than the competing approaches across both AIME 2024 and AIME 2025 datasets. This indicates a systematic improvement in reasoning reliability over the standard baseline configurations. FIPO achieves superior performance compared to GRPO and DAPO on the AIME 2024 benchmark. The method maintains a leading position over baselines on the AIME 2025 benchmark. Experimental results indicate a systematic improvement in Pass@1 scores over the DAPO baseline.
The the the table presents an ablation study evaluating the impact of influence weight clipping ranges and filtering mechanisms on the FIPO method. Results indicate that adjusting the clipping parameters to a more balanced range significantly boosts performance on the primary benchmark compared to the standard configuration. Additionally, the data confirms that the extreme value filtering mechanism is critical for achieving optimal results, as removing it leads to a noticeable decline in accuracy. A balanced influence weight clipping range yields higher accuracy than the standard configuration on the primary benchmark. The extreme value filtering mechanism is essential for maximizing performance, with the unfiltered version underperforming the filtered one. Performance gains are more pronounced on the AIME 2024 benchmark, while the more challenging AIME 2025 dataset shows consistent results across different settings.

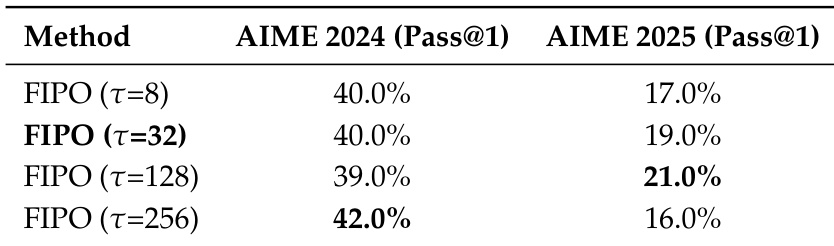
The authors evaluate the FIPO method using different decay rate horizons to assess their impact on mathematical reasoning performance. Results show that the optimal horizon setting varies by benchmark, with the largest horizon performing best on AIME 2024 and a moderately long horizon performing best on AIME 2025. The accompanying analysis notes that while extreme values can boost scores, intermediate horizons often provide better optimization stability. The largest decay rate horizon yields the highest Pass@1 score on the AIME 2024 benchmark. A moderately long decay rate horizon achieves the best performance on the AIME 2025 benchmark. The data indicates that performance sensitivity to the decay rate differs between the two evaluation datasets.
The authors evaluate the proposed FIPO method against the DAPO baseline on the AIME 2024 and AIME 2025 mathematical reasoning benchmarks. Results indicate that FIPO systematically outperforms the baseline across all reported metrics, including average pass rates, consistency, and overall coverage. The most significant gains are observed in average accuracy and consistency, while improvements in the probability of finding at least one correct solution are more modest. FIPO consistently achieves higher average accuracy and consistency scores than the DAPO baseline on both datasets. The proposed method shows a systematic improvement in reliability metrics compared to the baseline configuration. Gains in problem coverage are positive but appear less significant compared to improvements in consistency and average performance.

The authors evaluate the FIPO method against baselines like GRPO and DAPO on AIME 2024 and AIME 2025 benchmarks, demonstrating systematic improvements in reasoning reliability and accuracy. Ablation studies validate that balanced influence weight clipping and extreme value filtering are critical for maximizing performance. Additionally, experiments on decay rate horizons reveal that optimal settings vary by benchmark to ensure optimization stability.