Command Palette
Search for a command to run...
Agentic World Modeling:基盤、能力、法則、そしてその先へ
Agentic World Modeling:基盤、能力、法則、そしてその先へ
概要
AIシステムが単なるテキスト生成から、持続的な相互作用を通じて目標を達成する段階へと移行するにつれ、環境のダイナミクスをモデル化する能力が中心的なボトルネックとなっています。物体を操作し、ソフトウェアをナビゲートし、他者と協調し、あるいは実験を設計するagentsには、予測可能な環境モデルが必要となりますが、「ワールドモデル(world model)」という用語は研究コミュニティによって異なる意味を持っています。本論文では、2つの軸に基づいた「レベル × 法則(levels x laws)」という分類法(taxonomy)を導入します。第一の軸は3つの能力レベルを定義します。L1は、1ステップの局所的な遷移オペレータを学習する「Predictor(予測器)」、L2は、それらをドメインの法則に従った多ステップかつaction(行動)条件付きのロールアウトへと構成する「Simulator(シミュレーター)」、そしてL3は、新しい証拠に対して予測が外れた際に自律的に自身のモデルを修正する「Evolver(進化器)」です。第二の軸は、4つの支配法則のレジーム(regime)を特定します。すなわち、物理的(physical)、デジタル(digital)、社会的(social)、そして科学的(scientific)なレジームです。これらのレジームは、ワールドモデルが満たさなければならない制約条件と、どこで失敗する可能性が高いかを決定します。このフレームワークを用いて、我々はモデルベース強化学習、動画生成、WebおよびGUI agents、マルチagentによる社会シミュレーション、そしてAI駆動型の科学的発見にわたる400以上の研究を統合し、100以上の代表的なシステムをまとめました。また、「レベル × レジーム」の組み合わせにおける手法、失敗モード、および評価慣行を分析し、意思決定中心の評価原則と最小限の再現可能な評価パッケージを提案するとともに、アーキテクチャの指針、未解決問題、およびガバナンスの課題を概説します。本研究によって示されるロードマップは、これまで孤立していたコミュニティを連結し、受動的な次ステップの予測から、agentsが活動する環境をシミュレートし、最終的には再構築することさえ可能なワールドモデルへと向かう道を切り拓きます。
One-sentence Summary
By introducing a "levels × laws" taxonomy that categorizes capabilities into three levels and four governing-law regimes, this work synthesizes over 400 works and 100 representative systems to provide a comprehensive roadmap for developing agentic world models capable of simulating and reshaping their environments.
Key Contributions
- The paper introduces a "levels × laws" taxonomy that categorizes world models through three capability levels (Predictor, Simulator, and Evolver) and four governing-law regimes (physical, digital, social, and scientific).
- This work synthesizes over 400 research works and summarizes more than 100 representative systems across diverse domains such as model-based reinforcement learning, video generation, and AI-driven scientific discovery.
- The research proposes decision-centric evaluation principles and a minimal reproducible evaluation package to address the challenges of analyzing failure modes and evaluation practices across different level-regime pairs.
Introduction
As AI agents transition from simple text generation to complex goal achievement, the ability to model environment dynamics has become a critical bottleneck. While the term "world model" is widely used, research remains fragmented across disparate communities such as reinforcement learning, computer vision, and robotics, leading to inconsistent definitions and incomparable evaluation metrics. Existing surveys often fail to capture the progression of capabilities across different modalities, leaving a gap in how the paper understand the transition from mere prediction to true simulation.
The authors leverage a novel "levels × laws" taxonomy to unify these isolated fields. They propose a three-level capability hierarchy consisting of L1 Predictors (one-step local transitions), L2 Simulators (multi-step, action-conditioned rollouts), and L3 Evolvers (autonomous, evidence-driven model revision). This hierarchy is mapped against four governing-law regimes: physical, digital, social, and scientific worlds. By synthesizing over 400 works, the authors provide a decision-centric roadmap that connects diverse research domains and establishes a common language for building agents that can simulate and eventually reshape their environments.
Dataset
The authors utilize a diverse landscape of benchmarks to evaluate agent mastery across different governing-law regimes. The dataset composition is categorized into the following domains:
- Physical-World Domains: Includes Atari 100k for sample-efficient world-model learning, Meta-World for robotic manipulation, and CALVIN for language-conditioned long-horizon tasks. The authors also incorporate RoboCasa and RoboCasa365 for physical stability, BuilderBench for structural stability, and ManiSkill3 and RLbench for generalizable manipulation. Autonomous driving is represented by nuScenes, while 3D navigation and household activities are covered by the Habitat series, iGibson 2.0, and BEHAVIOR-1K. VBench is used to evaluate physical compliance in video generation.
- Digital-World Domains: Focuses on GUI grounding and software interaction through OSWorld, macOSWorld, SWE-bench, WebArena, and Mind2Web. Mobile operating system constraints are addressed using AppAgent and AndroidWorld. GameWorld is included for verifiable multimodal agent evaluation.
- Social-World Domains: Employs Theory of Mind benchmarks such as ToMi, BigToM, and OpenToM to assess psychological state inference. Social simulation and role-playing are covered by Sotopia and AgentBench, while strategic reasoning and deception are tested via game-based environments like Werewolf and Avalon.
- Scientific-World Domains: Uses ScienceWorld for elementary reasoning, DiscoveryBench for hypothesis verification, ChemCrow for chemical synthesis, and FutureX for evidence-based prediction.
- Open-World Environments: Combines multiple governing laws through procedurally generated worlds such as Minecraft, Crafter, and NetHack to test skill composition and long-horizon planning.
The authors use these benchmarks as anchor points to test specific boundary conditions. Evaluation protocols involve regime-specific constraint verification, degradation curves for long-horizon coherence, and counterfactual divergence testing to measure intervention sensitivity.
Method
The framework for agentic world modeling is structured around a three-level capability hierarchy—L1 Predictor, L2 Simulator, and L3 Evolver—organized along two orthogonal axes: capability level and governing-law regime. This hierarchy describes the progression of world-modeling capabilities from local prediction to evidence-driven revision, with each level serving distinct functions in an agent's decision-making process. The governing-law regimes—Physical, Digital, Social, and Scientific—define the constraints and invariants that transitions in a domain must satisfy, shaping the design and evaluation of world models within each context. The framework emphasizes that these levels are not static classifications but represent the capability an agent invokes at runtime based on task demands. A single deployed system can operate at different levels simultaneously, with L1 providing fast, reactive one-step predictions, L2 enabling multi-step simulations for planning and counterfactual reasoning, and L3 facilitating model revision when systematic failures occur. This runtime dispatch view clarifies that L3 is not a replacement for L1 or L2 but a governance layer that improves the stack when evidence demands it, operating as an adaptive system that treats its own model assets as objects of revision.
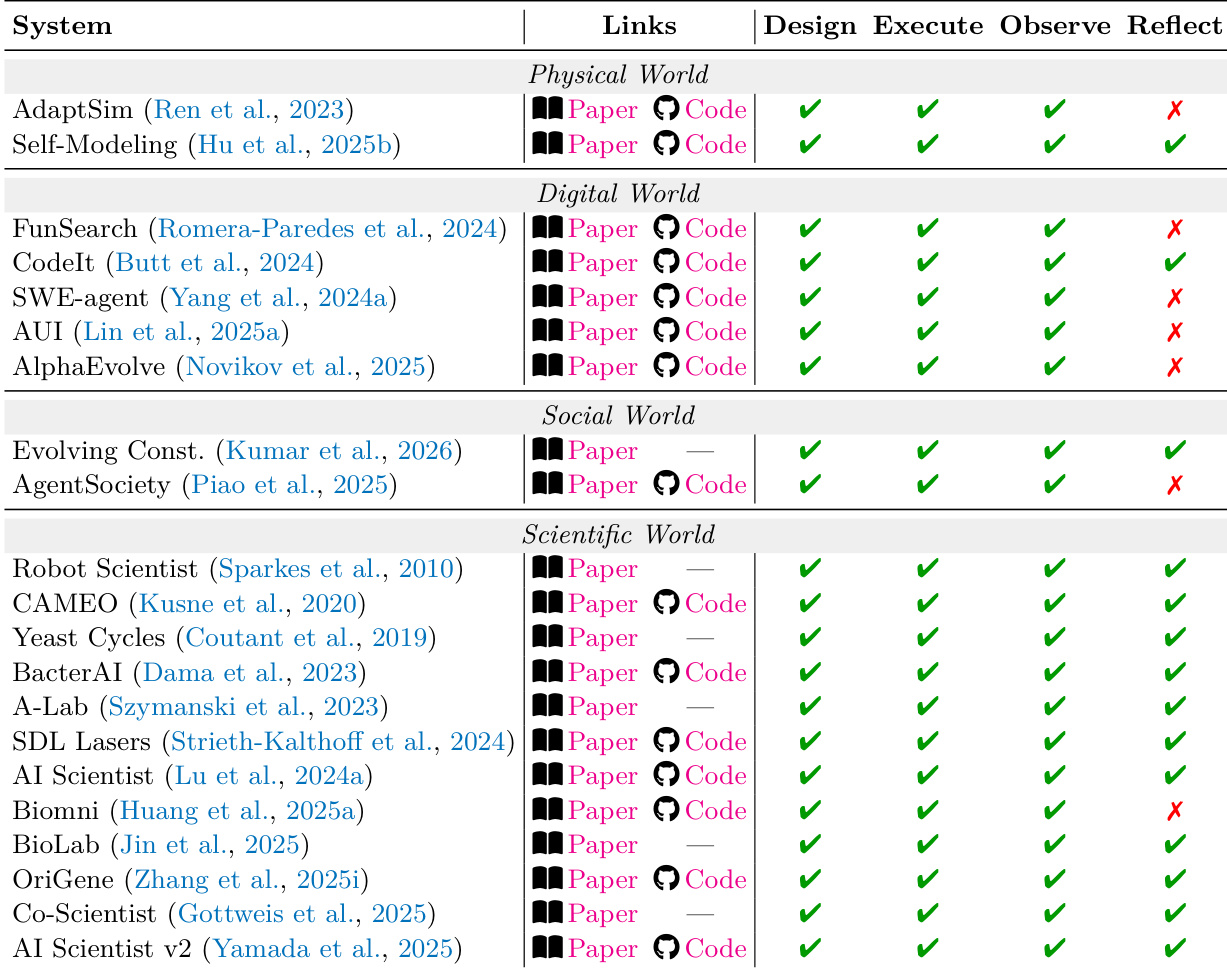
At the foundational level, the L1 Predictor focuses on local predictive operators that factorize into four components: state inference, forward dynamics, observation decoding, and inverse dynamics. These operators target one-step accuracy under the training distribution, with no guarantee of multi-step coherence. The core operator is forward dynamics, which models the transition from one latent state to the next given an action, while the others support inference and decoding. The L1 level is characterized by a Markovian property in the learned latent state, where the internal state zt is adequate for predicting the subsequent local step. This level is grounded in the POMDP formulation, where the agent maintains a belief over hidden states and crafts a policy to maximize cumulative reward. The L1 model is defined by its ability to sustain a meaningful internal state and use local predictive mechanisms to anticipate the next state, including potential observations or actions.
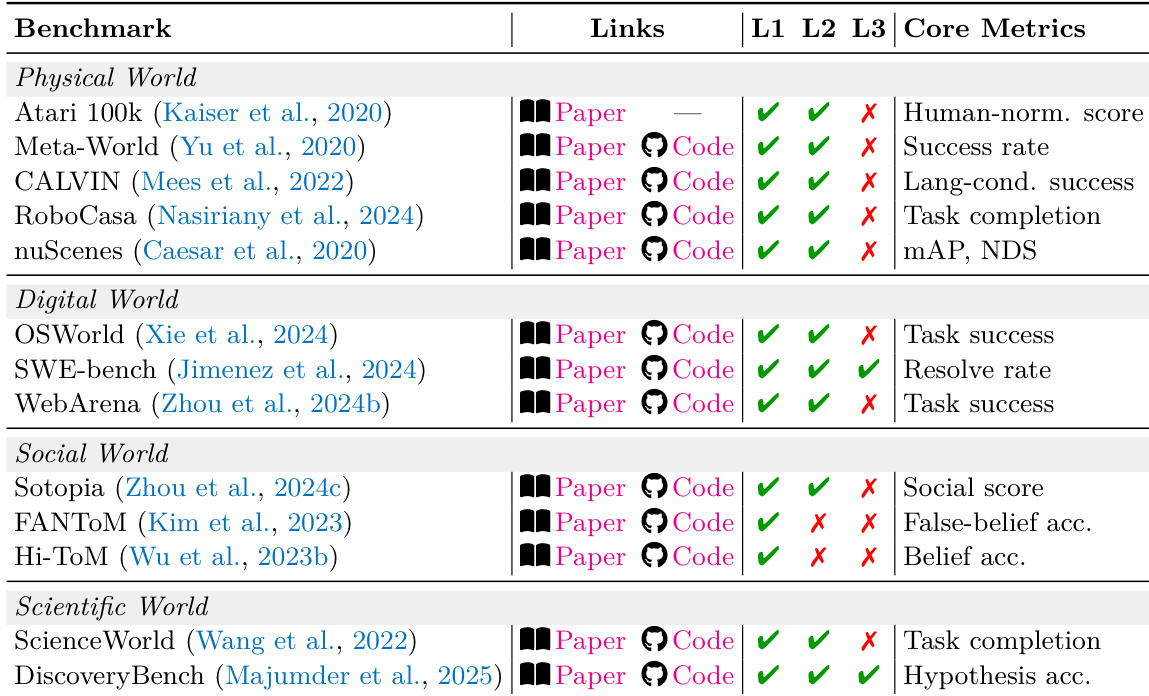
The L2 Simulator elevates the one-step predictive capability to decision-usable multi-step simulation. It answers the question: "if the agent executes a candidate action sequence under task constraints, what future trajectory is likely to unfold?" This level stitches per-edge L1 operators into a full trajectory, enabling the agent to roll out candidate plans and compare outcomes before committing to action. The L2 system supports trajectory-level queries of the form p^(τ∣z0,a1:H,c), where a1:H denotes an action sequence and c denotes optional constraints. Intervention-structured rollouts align with the interventional rung of Pearl's causal hierarchy, distinguishing L2 from L1 by coherent multi-step rollout under governing laws rather than one-step predictive quality alone. The L2 level is crucial for model-based planning, where synthetic training data generation relies on realistic state transitions to support policy improvement.

The L3 Evolver extends L2 from simulation within a fixed scaffold to evidence-driven model revision. It maintains an explicit update loop over model assets, where the system diagnoses failures, distills fixes into reusable assets, and validates updates before enabling them. The three boundary conditions marking the transition from L2 to L3 are: evidence-grounded diagnosis, persistent asset update, and governed validation. The key difference from L2 is that the model itself becomes an object of revision, not merely a fixed scaffold to be queried. The L3 system operates in a closed-loop design–execute–observe–reflect cycle, where new evidence is actively acquired to challenge and revise the model across iterations. This formulation closely mirrors the structure of scientific practice, where anomalies lead to model updates, ranging from incremental refinements to paradigm shifts. The L3 level is characterized by active trial-and-error, with the agent acting as a designer of experiments to generate data that maximizes information gain.

The architectural design of world models involves three primary building blocks: representation, dynamics, and control interface. Representation choices range from symbolic or programmatic states to latent continuous representations, each with distinct tradeoffs in interpretability, flexibility, and susceptibility to drift. Dynamics models include stochastic latent dynamics, deterministic value-aware dynamics, autoregressive token dynamics, and diffusion-based dynamics, each offering different balances of uncertainty modeling, multimodality, and action controllability. Control interfaces range from online MPC-style approaches to tree search and expansion, imagined-rollout policy optimization, and replayable-environment interfaces, each with different computational demands and error amplification characteristics. The governing-law regime determines which combinations are viable, with physical-world systems favoring latent or structured 3D representations paired with MPC or imagined-rollout policies, digital-world systems relying on symbolic or DOM-based states with replayable environments, social-world systems focusing on coherent agent identity and relational state maintenance, and scientific-world systems prioritizing evidence-chain validity and falsifiability. The implementation roadmap distills these design tradeoffs into a concise guide organized by capability level and governing-law regime, highlighting the representation format, dynamics model class, and primary engineering bottleneck for each cell.
Experiment
The evaluation categorizes L2 systems into four governing-law regimes to analyze how different constraints, such as physical laws or social norms, shape simulator requirements. The analysis reveals that long-term stability is driven more by the explicit modeling of these underlying constraints than by increasing perceptual fidelity. Furthermore, the findings suggest that real-world applications often span multiple regimes, necessitating a holistic approach to joint constraint satisfaction to prevent cascading failures across domains.
The the the table categorizes various L2 systems across different domains, highlighting their adherence to boundary conditions such as formalizability and observability in social and scientific worlds. It shows that systems often combine multiple constraint families, requiring joint satisfaction of constraints across regimes to ensure coherent performance. Systems across domains vary in their adherence to formalizability and observability constraints, with some excelling in one area but not the other. Many L2 systems integrate multiple constraint families, such as physical and social, requiring cross-regime coherence. The architecture of L2 systems often involves a combination of LLMs with reinforcement learning or simulation frameworks to handle complex constraint interactions.
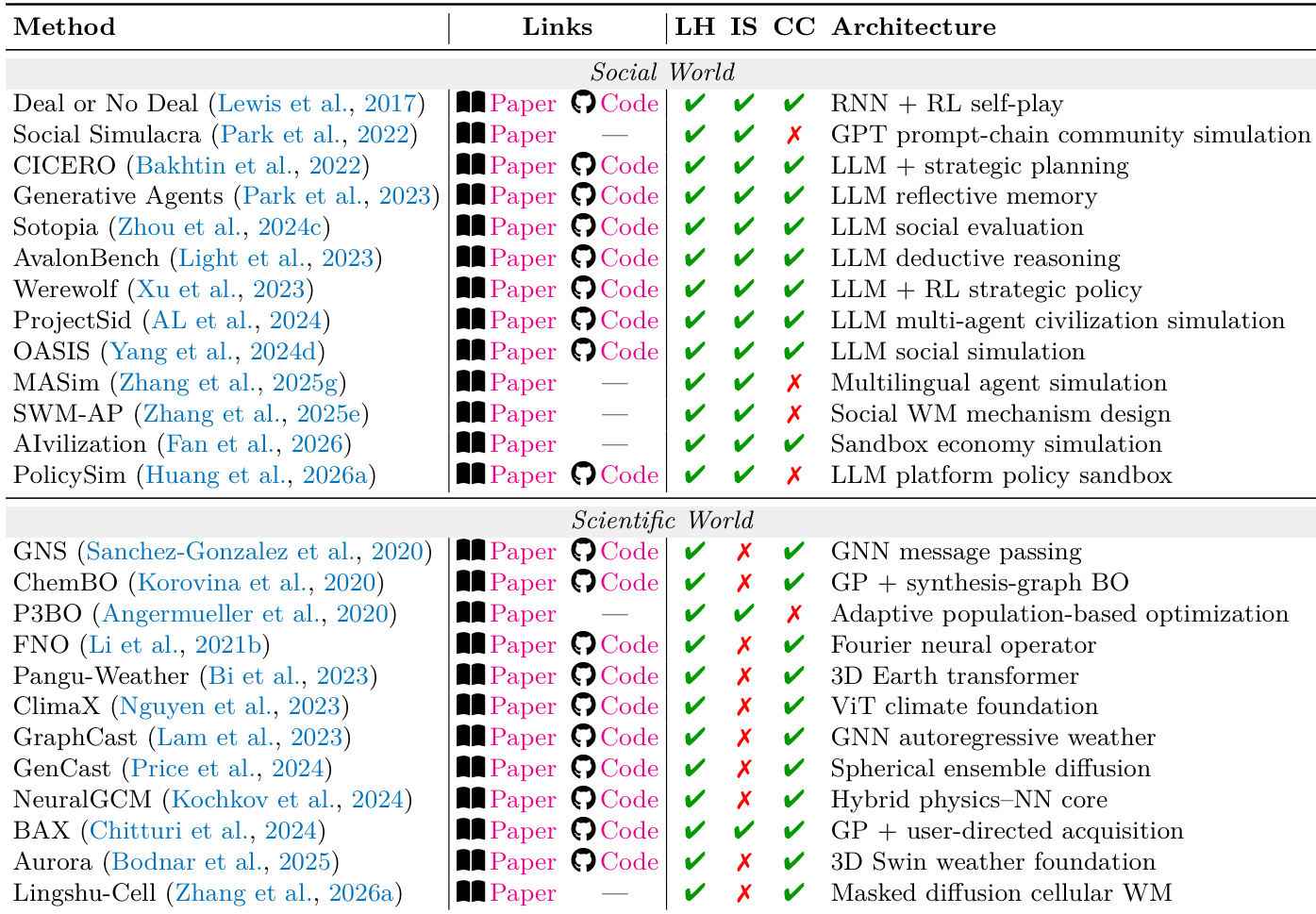
The the the table categorizes various L2 systems across four domains—Physical, Digital, Social, and Scientific—based on their capabilities in design, execution, observation, and reflection. Systems in each domain exhibit different patterns of constraint satisfaction, with notable differences in how they handle failure modes and evaluation priorities, particularly in cross-domain scenarios where multiple regimes interact. Systems across different domains show varying capabilities in design, execute, observe, and reflect, with some lacking in specific areas like reflection or observation. Cross-domain systems often require joint constraint satisfaction, as violations in one domain can cascade into others, affecting overall system coherence. The the the table highlights that making constraints explicit improves long-horizon stability more than increasing perceptual fidelity, regardless of the domain.
The authors categorize L2 systems across four governing-law regimes—physical, digital, social, and scientific—and evaluate their performance based on core metrics and boundary conditions. The the the table shows that systems in each regime vary in their use of paper and code links, with some achieving success in L1 and L2 but failing in L3, indicating limitations in generalization or long-horizon stability. Systems in the physical and digital worlds show consistent L1 and L2 performance but often fail in L3, suggesting challenges in scaling to more complex tasks. The social world systems achieve high L1 and L2 performance but fail in L3, indicating difficulties in handling long-term social dynamics. In the scientific world, systems achieve success across all three levels, highlighting the importance of structured evaluation and hypothesis validation.
The authors present a comparative analysis of L2 simulators across physical and digital worlds, categorizing methods by their adherence to governing laws related to formalizability and observability. The the the table highlights that successful simulators often prioritize explicit constraint modeling over perceptual fidelity, with notable differences in architecture and evaluation focus between regimes. Simulators in both physical and digital worlds prioritize formalizability and observability of constraints over perceptual fidelity. Methods in the physical world often use geometric or physical dynamics, while digital world methods rely on code-based or state transition models. Cross-regime systems face challenges due to cascading failures when constraints from one domain violate those in another.
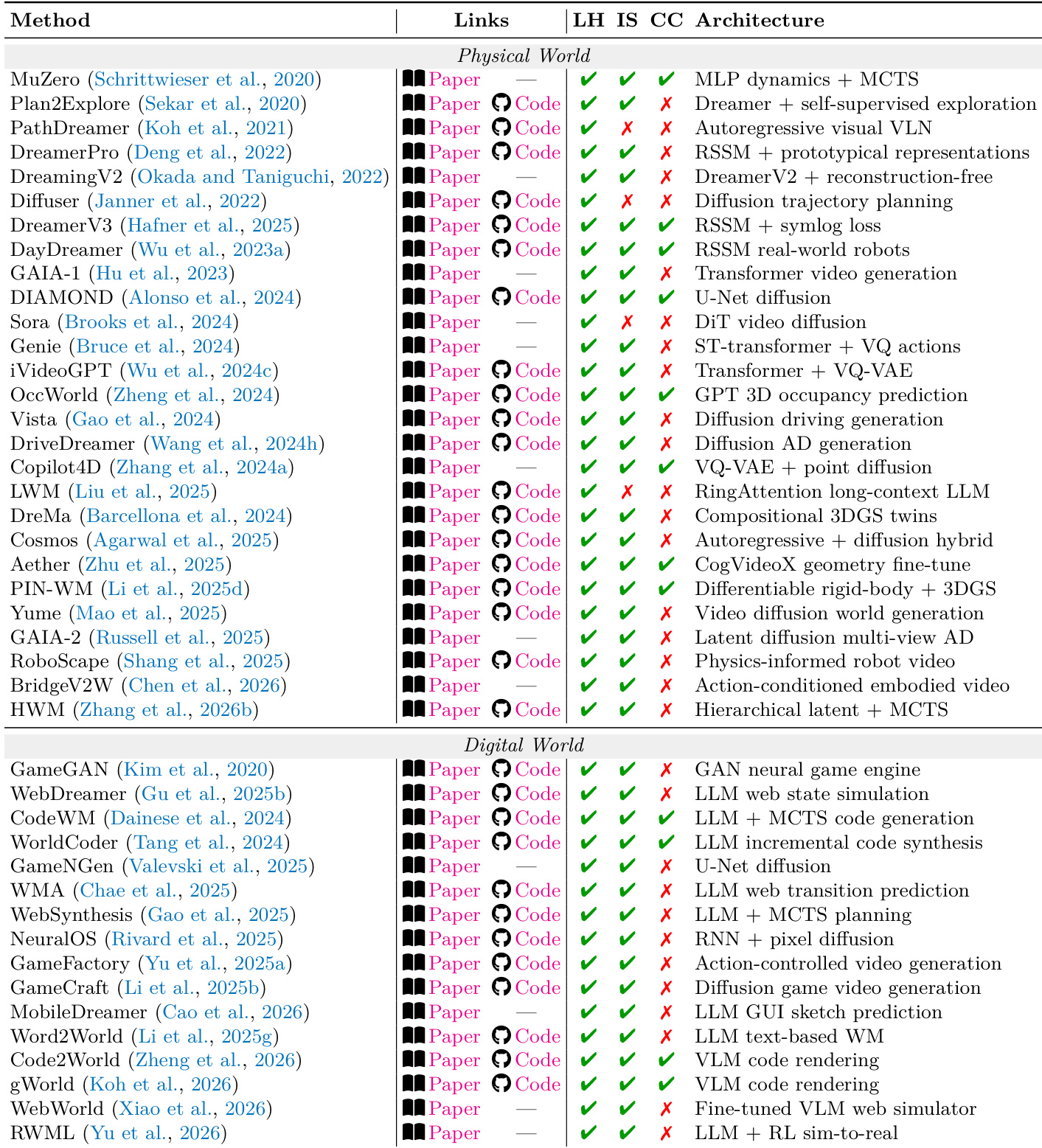
The evaluation categorizes L2 systems across physical, digital, social, and scientific domains to assess their ability to satisfy governing laws through design, execution, observation, and reflection. The findings indicate that while systems vary in their capacity to handle specific boundary conditions, successful performance often depends on explicit constraint modeling rather than mere perceptual fidelity. Furthermore, the analysis reveals that maintaining cross-regime coherence is essential, as many systems struggle with long-horizon stability and cascading failures when navigating complex, multi-domain interactions.