HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

TMAS:マルチエージェントの相乗効果によるテスト時の計算スケーリング

Soohak:LLMのレベルの数学的能力を評価するための数学的に整理されたベンチマーク


























TMAS:マルチエージェントの相乗効果によるテスト時の計算スケーリング
Soohak:LLMのレベルの数学的能力を評価するための数学的に整理されたベンチマーク
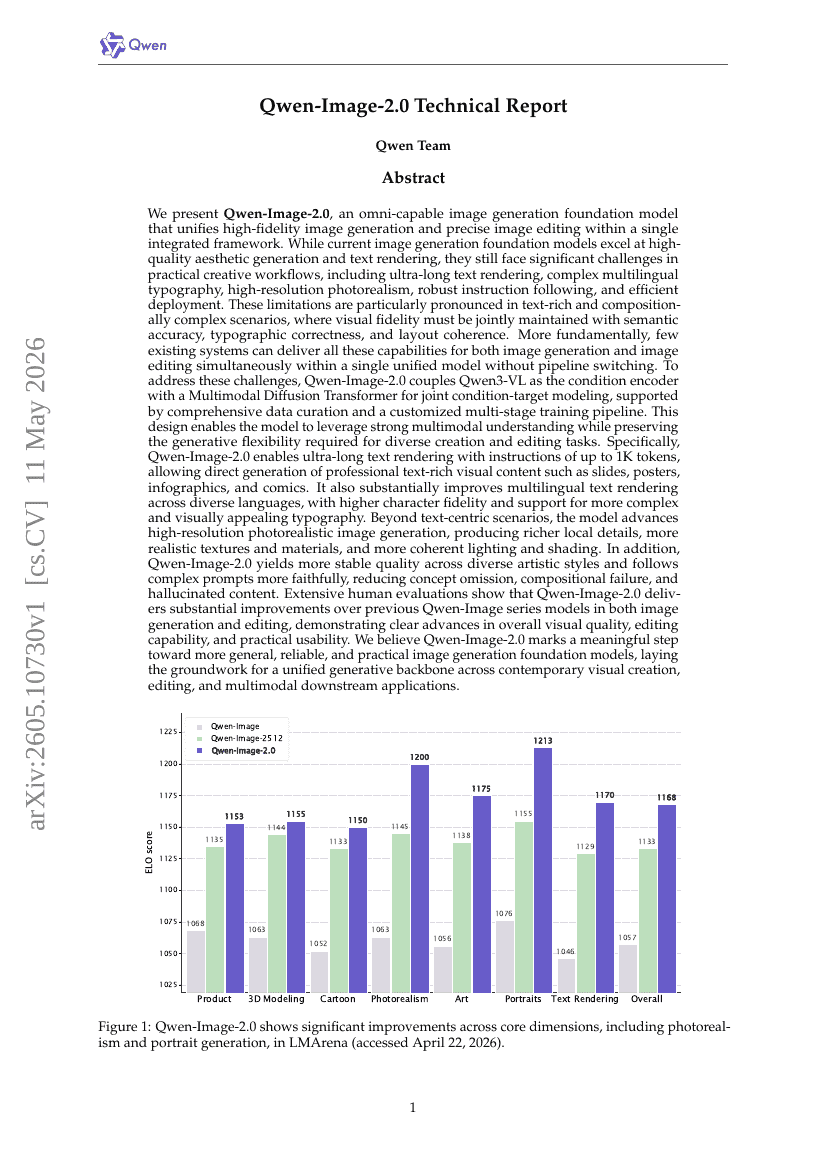
Qwen-Image-2.0技術報告
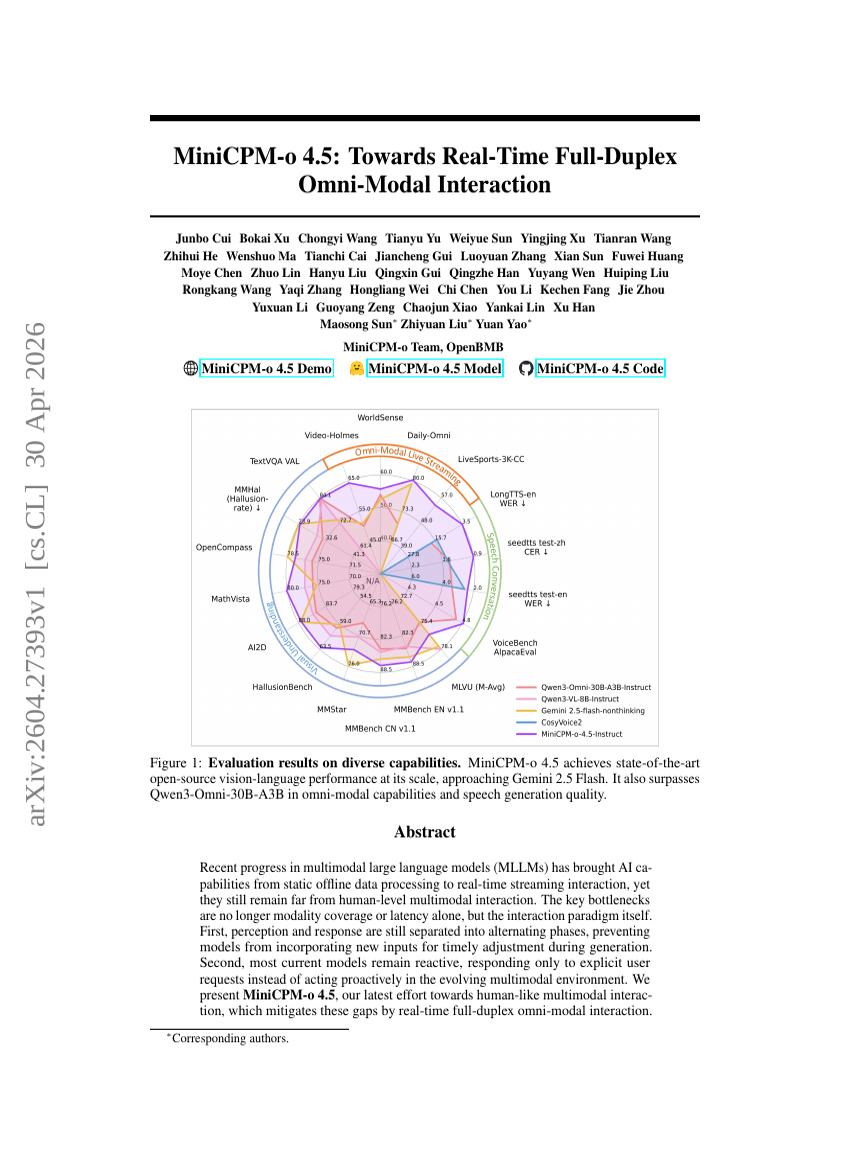
MiniCPM-o 4.5: リアルタイムフルデュープレックス・オムニモーダル相互作用へ向けて
デプロイ中に学習する:汎用ロボットポリシーのためのフリート規模の強化学習
高速バイト潜在変換器
AI-CoMathematician: Agentic AI による数学者の加速
HyperEyes: 並列マルチモーダル検索エージェントのための二重粒度効率認識型強化学習
平均モードの発声:1000層拡散トランスフォーマーにおける平均・分散分割残差
LLMsはLLMsを改善する:テスト時のスケールングのためのエージェント主導型発見
リストワイズ政策最適化: ターゲット投影としてのグループベースRLVRにおけるLLMレスポンスシンプレックス
Flow-OPD: フローマッチングモデルのためのオンポリシー蒸留
MACE-Dance: 音楽駆動型ダンス動画生成のためのモーション・外観カスケード型エージェント
推理集約型検索の再考:エージェント型検索システムにおける検索機の評価と進展
想像力をいつ信頼するか:ワールドアクションモデルのための適応的アクション実行
SemEval-2026 Task 8におけるRaguTeam:忠実なマルチターン応答生成のためのJudge管理型LLMアンサンブル、MenoとFriends
MiA-Signature: 長期コンテキストの理解のためのグローバルアクティベーションの近似
連続潜在拡散言語モデル
スキル1: 強化学習によるスキル強化エージェントの統一進化
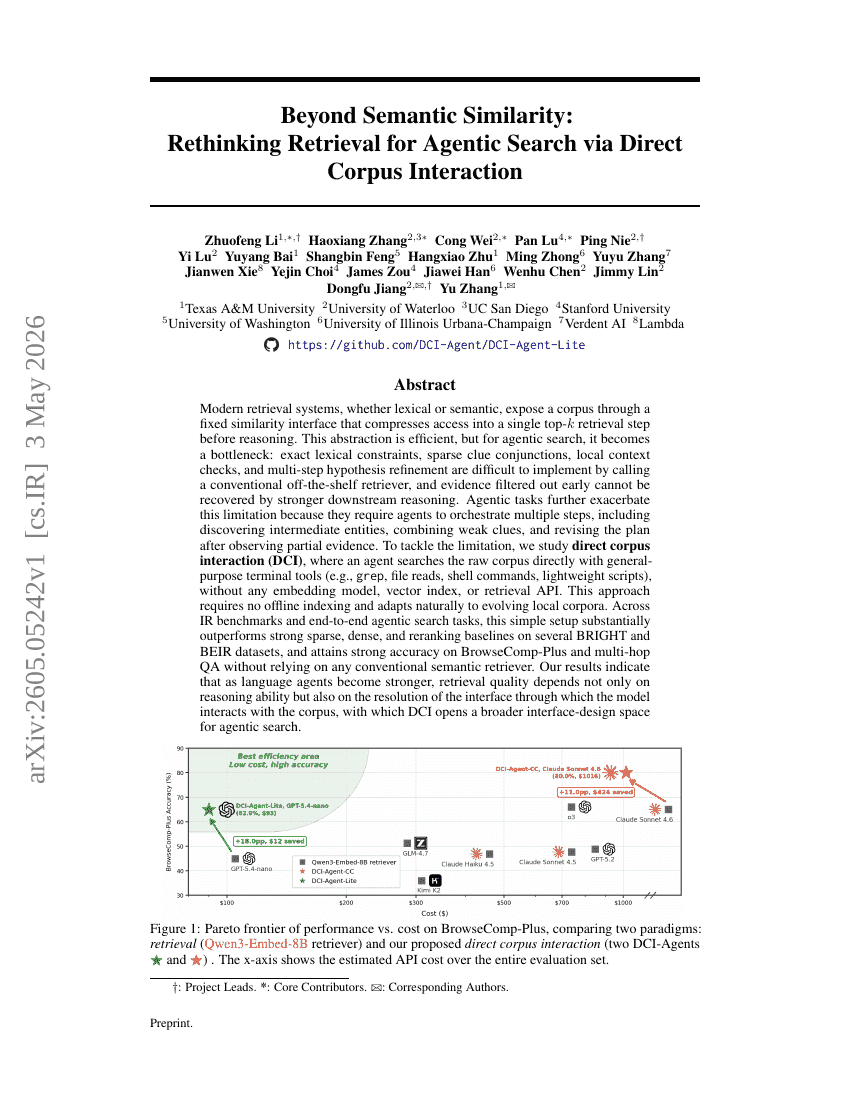
意味的類似性を超えて:直接コーパス相互作用を通じたエージェント検索における検索の再考
MathNet: 数学推論および検索のためのグローバルマルチモーダルベンチマーク
D-OPSD: 継続的なステップ圧縮拡散モデルの微調整のためのオンポリシー自己蒸留
ZAYA1-8B技術報告書
PhysForge: インタラクティブな仮想世界向けの物理に基盤を置いた3Dアセットの生成
HERMES++: 3Dシーン理解と生成のための統一されたドライビングワールドモデルに向けて
OpenSearch-VL: 最先端のマルチモーダル検索エージェントのためのオープンレシピ
RLDX-1 技術報告書
Stream-T1: ストリーミング動画生成のためのテストタイムスケーリング
Stream-R1: ストリーミング動画生成に対する信頼性・パープレキシティ認識型報酬蒸留
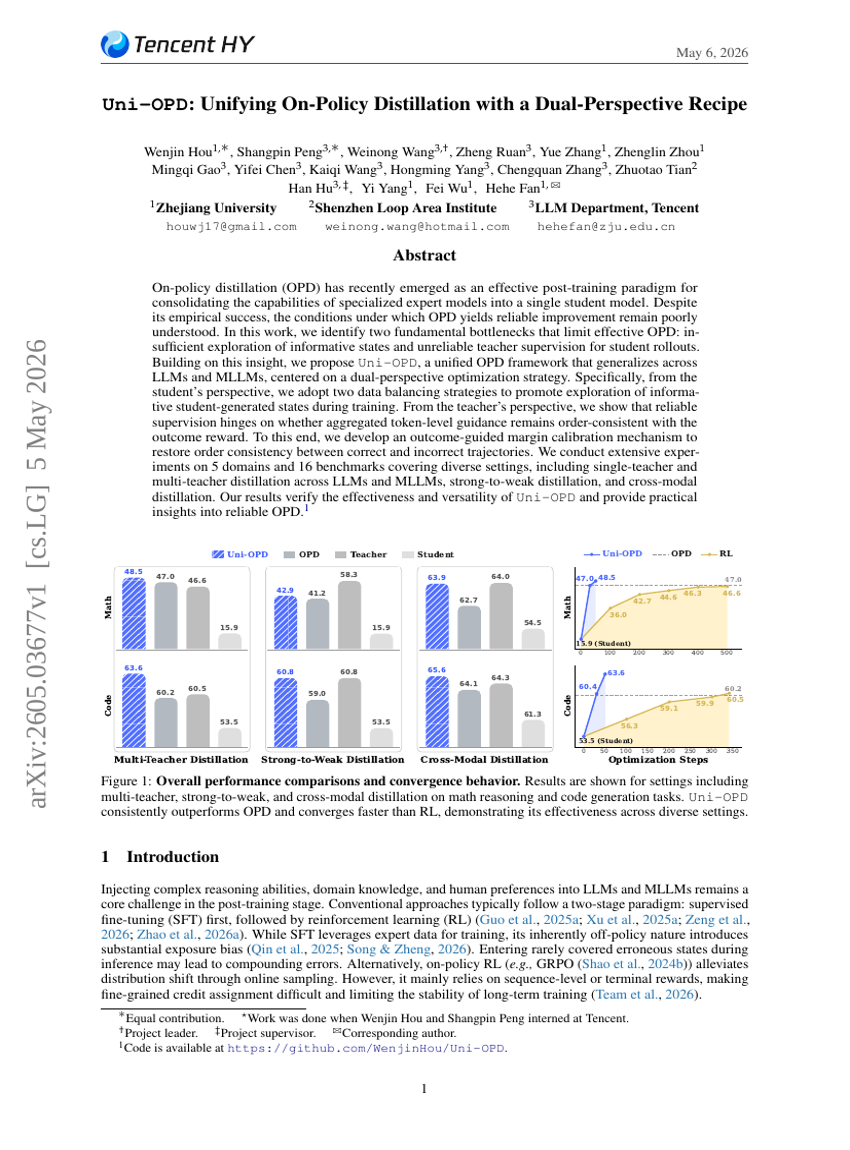
Uni-OPD: Dual-Perspective Recipe による On-Policy Distillation の統一
AGENTIC-IMODELS: 自己研究によるエージェント型解釈可能ツールの進化
HEAVYSKILL: エージェントハーネスにおける内部スキルとしてのヘビーシンキング
Qwen-Image-2.0技術報告
MiniCPM-o 4.5: リアルタイムフルデュープレックス・オムニモーダル相互作用へ向けて
デプロイ中に学習する:汎用ロボットポリシーのためのフリート規模の強化学習
高速バイト潜在変換器
AI-CoMathematician: Agentic AI による数学者の加速
HyperEyes: 並列マルチモーダル検索エージェントのための二重粒度効率認識型強化学習
平均モードの発声:1000層拡散トランスフォーマーにおける平均・分散分割残差
LLMsはLLMsを改善する:テスト時のスケールングのためのエージェント主導型発見
リストワイズ政策最適化: ターゲット投影としてのグループベースRLVRにおけるLLMレスポンスシンプレックス
Flow-OPD: フローマッチングモデルのためのオンポリシー蒸留
MACE-Dance: 音楽駆動型ダンス動画生成のためのモーション・外観カスケード型エージェント
推理集約型検索の再考:エージェント型検索システムにおける検索機の評価と進展
想像力をいつ信頼するか:ワールドアクションモデルのための適応的アクション実行
SemEval-2026 Task 8におけるRaguTeam:忠実なマルチターン応答生成のためのJudge管理型LLMアンサンブル、MenoとFriends
MiA-Signature: 長期コンテキストの理解のためのグローバルアクティベーションの近似
連続潜在拡散言語モデル
スキル1: 強化学習によるスキル強化エージェントの統一進化
意味的類似性を超えて:直接コーパス相互作用を通じたエージェント検索における検索の再考
MathNet: 数学推論および検索のためのグローバルマルチモーダルベンチマーク
D-OPSD: 継続的なステップ圧縮拡散モデルの微調整のためのオンポリシー自己蒸留
ZAYA1-8B技術報告書
PhysForge: インタラクティブな仮想世界向けの物理に基盤を置いた3Dアセットの生成
HERMES++: 3Dシーン理解と生成のための統一されたドライビングワールドモデルに向けて
OpenSearch-VL: 最先端のマルチモーダル検索エージェントのためのオープンレシピ
RLDX-1 技術報告書
Stream-T1: ストリーミング動画生成のためのテストタイムスケーリング
Stream-R1: ストリーミング動画生成に対する信頼性・パープレキシティ認識型報酬蒸留
Uni-OPD: Dual-Perspective Recipe による On-Policy Distillation の統一
AGENTIC-IMODELS: 自己研究によるエージェント型解釈可能ツールの進化
HEAVYSKILL: エージェントハーネスにおける内部スキルとしてのヘビーシンキング