Command Palette
Search for a command to run...
スキルから人材へ:現実の企業として異質なエージェントを組織化する
スキルから人材へ:現実の企業として異質なエージェントを組織化する
Zhengxu Yu Yu Fu Zhiyuan He Yuxuan Huang Lee Ka Yiu Meng Fang Weilin Luo Jun Wang
概要
個々のエージェントの能力は、モジュール化されたスキルやツール統合を通じて急速に発展してきたものの、マルチエージェント・システムは依然として、固定的なチーム構造、密結合された調整ロジック、セッション限定の学習という制約に直面しています。私たちは、この現状はより深層的な欠如を反映していると考えます。つまり、個々のエージェントが何を「知っているか」から独立し、エージェントという「労働力」をどのように編成し、ガバナンスし、時間をかけて改善していくかを規律づける、原理的な組織層が存在しないという問題です。このギャップを埋めるために、私たちはマルチエージェント・システムを組織レベルへと引き上げるフレームワークである OneManCompany (OMC) を紹介します。OMCは、スキル、ツール、ランタイム設定を Talents と呼ばれるポータブルなエージェントのアイデンティティにカプセル化し、異種バックエンドを抽象化する型付きの組織インターフェースを通じてオーケストレーションします。コミュニティ主導の Talent Market はオンデマンドでのリクルートを実現し、実行中に組織が能力ギャップを埋め、動的に自身を再構成することを可能にします。組織的意思決定は、計画、実行、評価を単一の階層型ループに統合する Explore-Execute-Review (E2R) ツリー探索によって運用されます。この手法では、タスクはトップダウンで責任のある単位に分解され、実行結果はボトムアップで集約されて、体系的なレビューと洗練を駆動します。このループは、人間の企業のフィードバック機構を模倣しつつ、終了性とデッドロックフリーであることの形式的保証を提供します。これらの貢献により、マルチエージェント・システムは静的で事前構成されたパイプラインから、多様な領域における開かれたタスクに適応する、自己組織化かつ自己改善型のAI組織へと変貌します。PRDBench上での実証評価において、OMCは84.67%の成功率を達成し、最先端技術と比較して15.48パーセントポイント上回りました。さらに、ドメイン横断的なケーススタディを通じて、その一般性が示されています。
One-sentence Summary
The authors introduce OneManCompany (OMC), a multi-agent framework that decouples organizational governance from individual capabilities through portable Talents and a dynamic Talent Market, while leveraging an Explore-Execute-Review (E²R) tree search to unify hierarchical planning and evaluation, ultimately achieving an 84.67% success rate on PRDBench that surpasses the state of the art by 15.48 percentage points.
Key Contributions
- The framework introduces a Talent-Container architecture that decouples portable agent identities from heterogeneous execution backends via six typed organisational interfaces. This design enables dynamic workforce assembly through a community-driven Talent Market that provisions verified agents on demand.
- Project execution is operationalized through an Explore-Execute-Review tree search that unifies hierarchical task decomposition, agent coordination, and outcome evaluation. A DAG-based task structure with AND-tree semantics and a finite state machine provides formal guarantees on termination and deadlock freedom while iteratively refining organisational strategies.
- Organisational improvement is automated through a structured feedback pipeline that updates agent working principles and standard operating procedures based on performance reviews. Quantitative evaluation on the PRDBench benchmark demonstrates an 84.67% success rate, surpassing state-of-the-art baselines by 15.48 percentage points.
Introduction
In software development and complex automation, scaling AI collaboration is critical, yet current multi-agent systems struggle with brittle team structures, runtime incompatibilities, and ad hoc coordination. These systems lack a unifying organizational layer that separates workforce structure from individual capabilities, preventing reliable generalization to open-ended projects. To address this gap, the authors introduce OneManCompany, an open-source framework that formalizes AI organization design through a decoupled talent and container architecture, a dynamic tree search for structured task decomposition, and continuous feedback loops for agent and organizational self-evolution. This approach enables heterogeneous agents to be automatically recruited, coordinated, and improved over time, mirroring the operational principles of human companies to tackle complex, cross-domain workflows.
Dataset
-
Dataset Composition and Sources: The authors leverage PRDBench, a benchmark consisting of 50 project-level tasks drawn from over 20 distinct software development domains. Each task originates from a structured Product Requirement Document supplemented by auxiliary data, comprehensive test plans, and executable evaluation scripts.
-
Subset Details: The collection operates as a unified set of 50 tasks without formal subgroups. Every task is engineered to replicate wild dynamic agentic workflows, meaning team structures, runtime environments, task breakdowns, and execution sequences are intentionally concealed until the agent begins processing.
-
Data Usage and Processing: The authors deploy this dataset exclusively for evaluating the OMC framework. They do not partition the data for training or apply mixture ratios, instead utilizing the complete benchmark to measure end-to-end capabilities in requirement interpretation, hierarchical decomposition, and multi-agent coordination.
-
Workflow and Evaluation Mechanics: The authors rely on the embedded executable scripts and predefined evaluation criteria to automate performance measurement. No cropping strategies or metadata construction pipelines are described, as the benchmark prioritizes dynamic execution traces and script-driven validation to capture realistic development constraints.
Method
The OneManCompany (OMC) framework is designed to model multi-agent systems as self-organizing and self-improving organizations, structured around three core pillars: organizational management, project execution, and organizational evolution. At the foundation of this architecture is the concept of the Employee, which is composed of a portable Talent and a Container. The Talent encapsulates an agent's cognitive identity, including its role, skills, tools, and guiding principles, while the Container provides the runtime environment and the formal interfaces through which the agent interacts with the organizational layer. This Talent-Container architecture enables a decoupling of agent capabilities from their execution backends, allowing for heterogeneous agents—such as LangGraph-based, Claude Code, or script-driven executors—to coexist and be managed uniformly within a single organization. The Container hosts the agent runtime and provides six typed organizational interfaces: Execution, Task, Event, Storage, Context, and Lifecycle, which standardize agent-platform interaction and ensure policy enforcement, isolation, and extensibility. The organizational layer acts as a unifying abstraction, analogous to an operating system kernel, providing a consistent interface over diverse hardware and agent backends, as illustrated in the framework diagram.
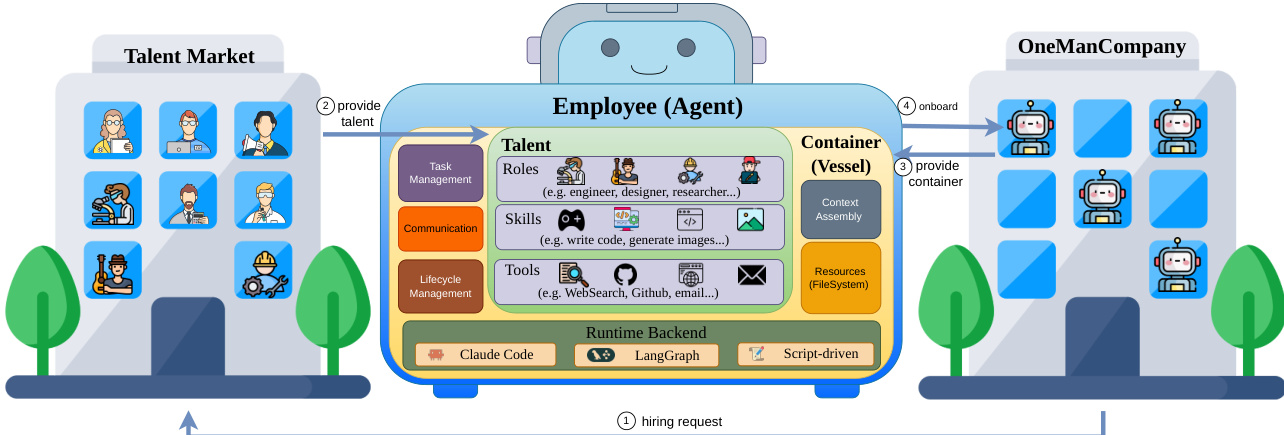
The Talent Market serves as a community-driven agent marketplace, enabling on-demand recruitment of verified, benchmark-validated agent packages. These Talents are complete, ready-to-deploy agent packages that include system prompts, role definitions, tool configurations, skill scripts, and domain knowledge, decoupled from any specific Container. The market supports three sourcing channels: community-contributed Talents from open-source repositories, AI-recommended assembly of skills from the web to address cold-start domains, and internal promotion of high-performing employees. When a project requires a capability not present in the current workforce, the HR agent queries the Talent Market, compiles a ranked shortlist based on skill match and community ratings, and presents candidates to the CEO for approval. Upon selection, the system automates the provisioning of a Container, assigns a desk, configures tool access, and registers the new employee, enabling dynamic team assembly without manual setup.
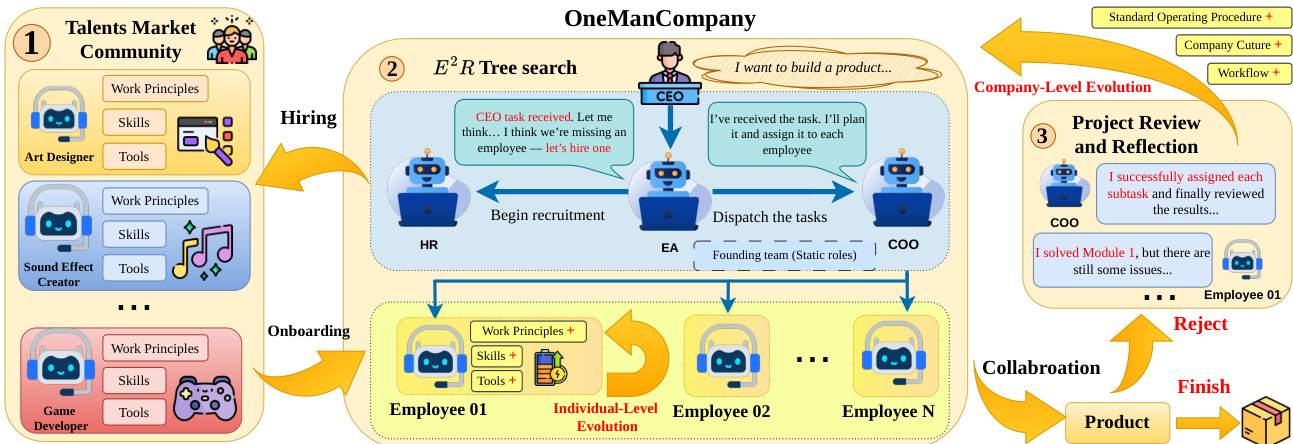
Project execution is governed by the Explore-Execute-Review (E²R) tree search, a hierarchical loop that decomposes tasks top-down into accountable units and aggregates outcomes bottom-up to drive refinement. The E²R operates over a dynamic search tree T=(V,Etree,Edep), where nodes represent organizational states at decision points, carrying attributes such as task description, assigned employee, status, result, and cost. The tree grows through five action types: decompose (adding child tasks), assign (binding an employee to a leaf), recruit (hiring a new employee), review (accepting or rejecting a result), and iterate (creating a new root-level strategy). The policy π(T) selects a strategy for the current decision point, determining how to decompose the task and whom to assign. The exploration stage selects a strategy, the execution stage carries out the plan, and the review stage evaluates the result, producing a quality signal that propagates bottom-up. This accept-or-redecompose cycle continues until the root is resolved or a circuit breaker fires.
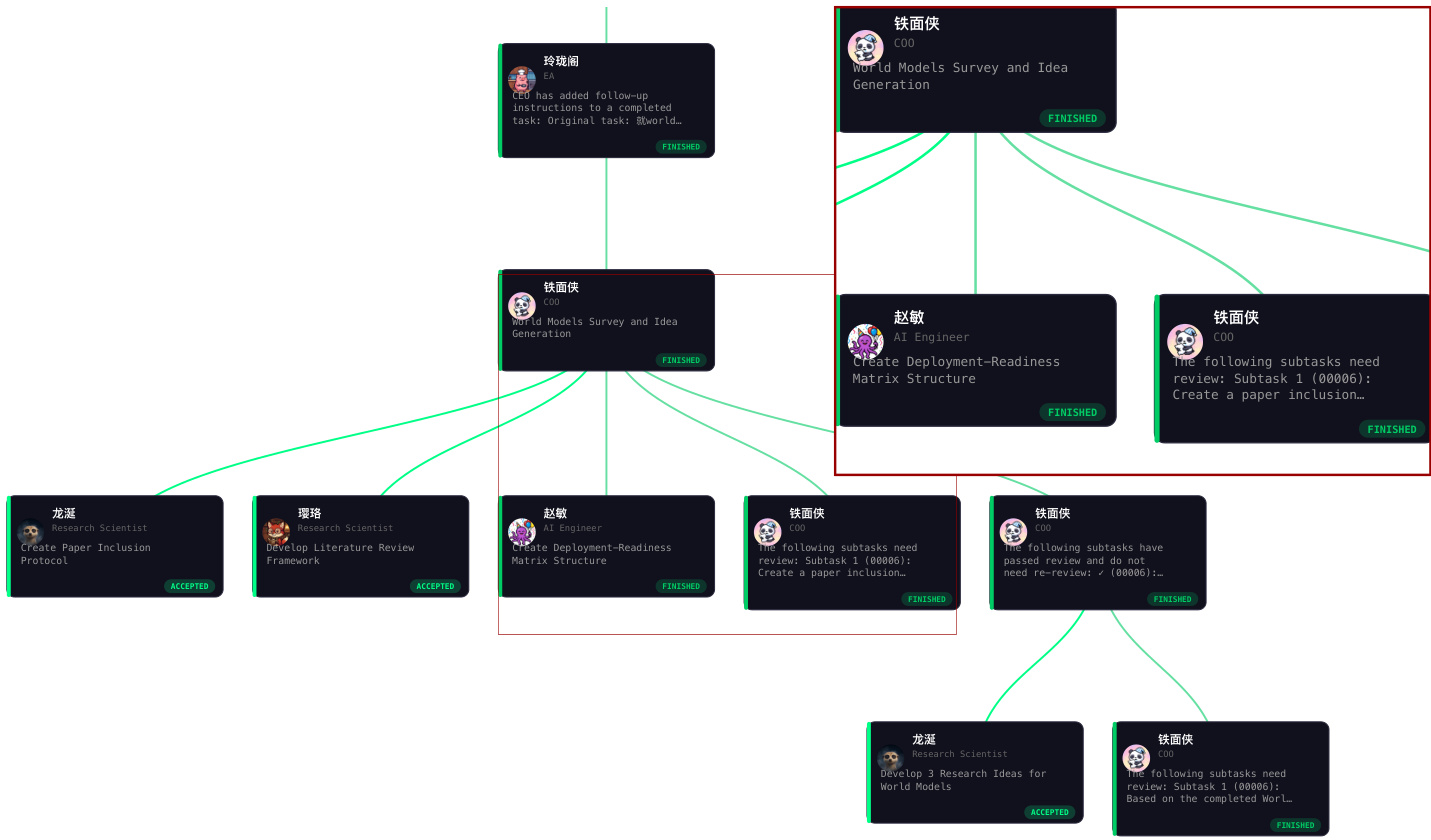
The E²R tree search is complemented by a DAG-based execution layer that ensures reliable task completion. The task tree is augmented with dependency edges Edep, forming a DAG that must be acyclic, enforced at insertion time. A node v becomes executable when its dependency constraints are satisfied, meaning all its predecessors are in the ACCEPTED or FINISHED state. The scheduler selects ready nodes in FIFO order, subject to a mutual exclusion invariant, ensuring no employee runs more than one task at a time. The task lifecycle is governed by a finite state machine with states including PENDING, PROCESSING, COMPLETED, ACCEPTED, FAILED, and FINISHED. A key structural guarantee is the AND-semantics: a node is resolved only when all its children are resolved, ensuring that project completion is a derived property of subtask completion. This bottom-up propagation prevents silent stalls and ensures that no task can be silently dropped. The system also implements bounded rationality through circuit breakers, including a review limit, a task timeout, and a cost budget, which guarantee that every search episode terminates in bounded time and cost.
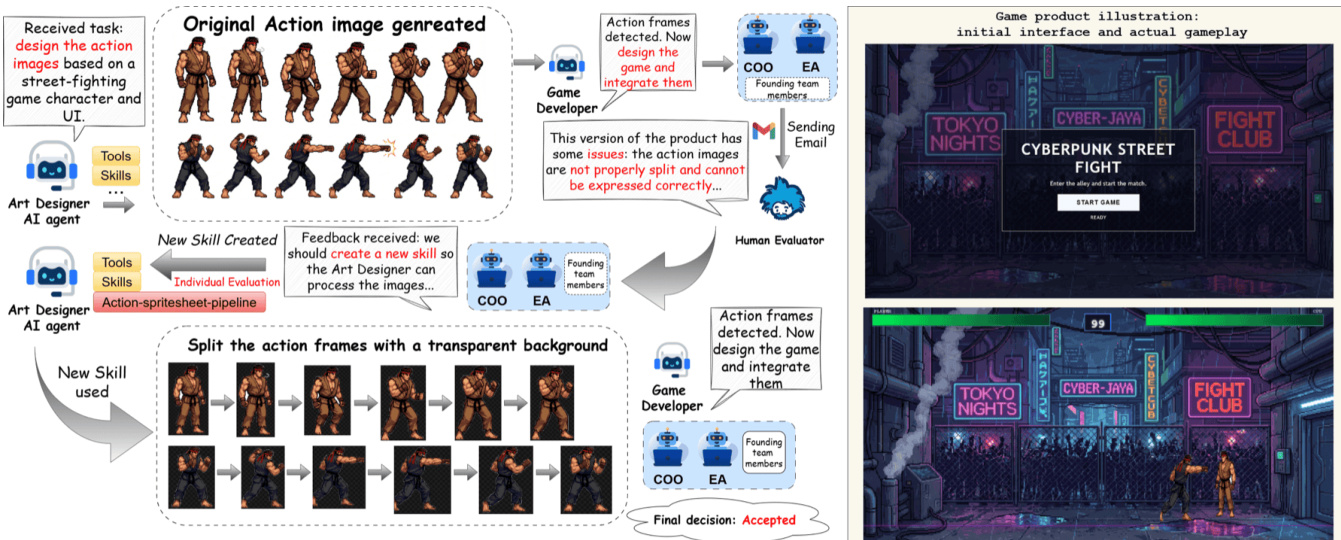
Organizational evolution occurs through a combination of individual and organizational learning mechanisms. Individually, agents maintain a persistent profile that includes a progress log and summarized working principles. After each CEO one-on-one, the agent performs structured self-reflection to update its principles, and upon task completion, it conducts a post-task review to update its log. These updates modify the agent's Talent artefacts, enabling continuous improvement without retraining. At the organizational level, project retrospectives are conducted, in which employees submit self-assessments and the COO aggregates findings into individual feedback and organizational Standard Operating Procedures (SOPs) that are injected into future agent contexts. A formal performance review pipeline ensures accountability: every three projects, the HR agent initiates a review, and employees failing three consecutive reviews enter a Performance Improvement Plan, with offboarding triggered upon a fourth failure. This lifecycle management closes the loop between the Talent Market and organizational evolution, ensuring that underperforming agents are replaced and high-performing agents are continuously refined.
Experiment
The evaluation pairs a standardized software development benchmark with four cross-domain case studies to validate the system’s capacity for autonomous, project-level orchestration. Testing demonstrates that dynamic task decomposition, enforced quality gates, and seamless coordination across heterogeneous model families enable reliable execution without requiring domain-specific configuration. Qualitative analysis across software engineering, game development, multimedia production, and academic research highlights the framework’s effectiveness in supporting iterative human feedback and cross-modal collaboration. Ultimately, the findings indicate that organizational architectures can successfully scale AI agent teamwork to handle diverse, complex workflows while maintaining adaptability and output correctness.
The authors present a multi-agent system that recruits specialized agents from diverse model families to execute complex tasks across software development, game development, audio-visual production, and academic research. The system uses a dynamic task decomposition approach with a review gate and coordinated execution, achieving high success rates and demonstrating adaptability across domains. Results show that the system incurs a cost overhead due to coordination, but this is justified for complex tasks requiring high accuracy. The system achieves high success rates by dynamically decomposing tasks and enforcing a review gate to prevent error propagation. It recruits agents from different model families, enabling cross-modal and cross-domain coordination. The system incurs a cost overhead due to multi-agent coordination, which is justified for complex, project-level tasks.

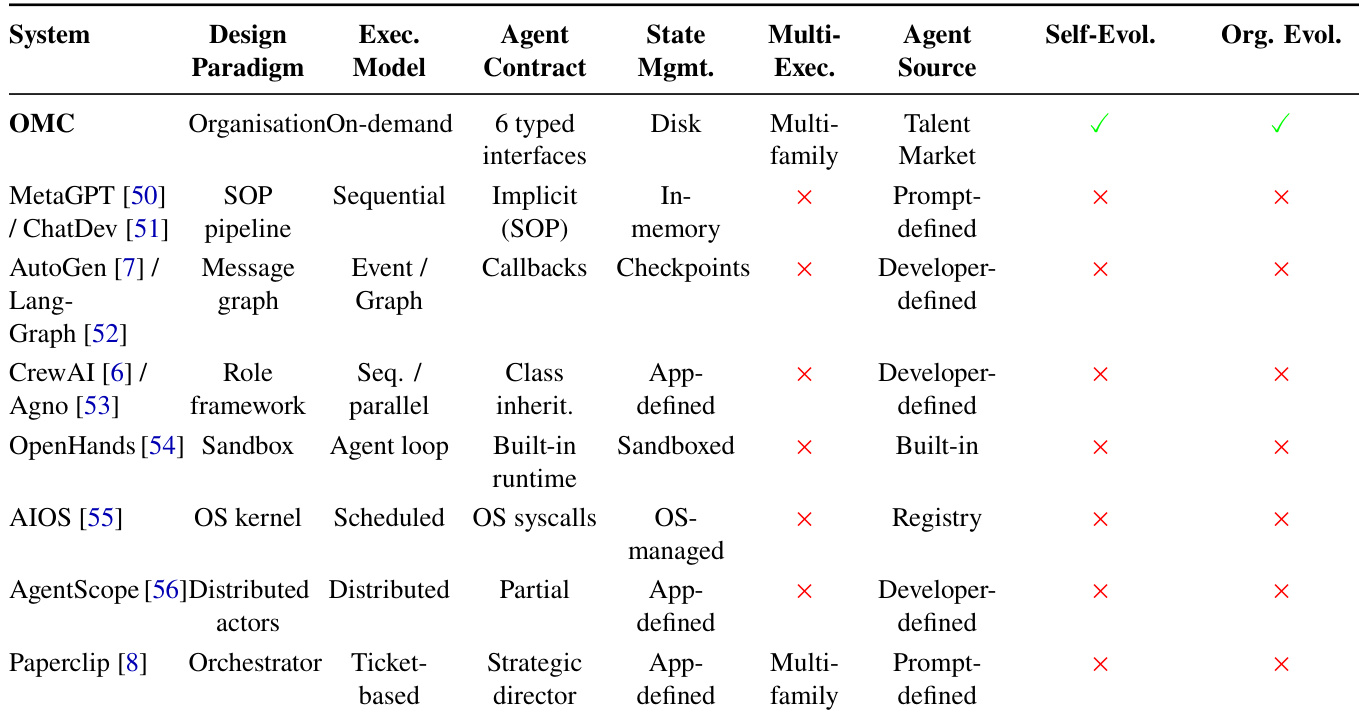
The authors compare OMC with existing systems across multiple dimensions including design paradigm, execution model, and organizational evolution. Results show that OMC stands out by supporting multi-family agent coordination and dynamic organizational evolution, unlike other systems that rely on fixed architectures or lack self-evolution capabilities. The the the table highlights OMC's unique combination of on-demand organization and flexible agent recruitment. OMC supports multi-family agent coordination and dynamic organizational evolution, which are absent in other systems OMC uses an on-demand organization paradigm with typed interfaces, differing from sequential or distributed models used by baselines Other systems lack self-evolution capabilities and rely on fixed agent sources, whereas OMC enables dynamic talent recruitment from a market
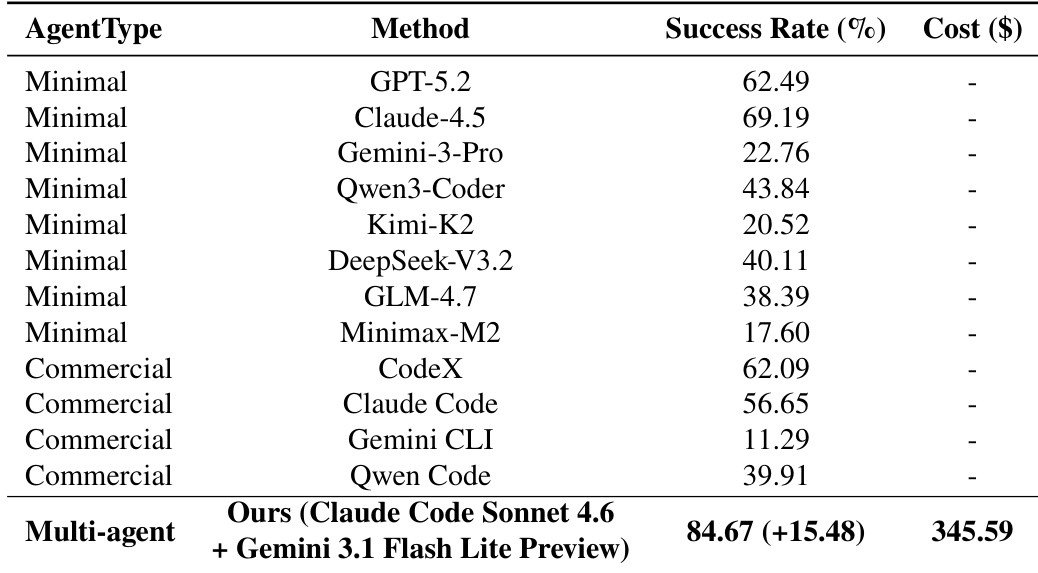
The authors compare the performance of various agent systems on a software development benchmark, evaluating success rate and cost. Results show that the proposed multi-agent approach achieves the highest success rate and incurs a significant cost, reflecting the overhead of coordinated execution across specialized agents. The multi-agent system achieves the highest success rate compared to all baseline methods. The proposed method incurs a higher cost than other systems, indicating greater resource usage for coordination. The success rate improvement is substantial relative to the best-performing baseline, demonstrating enhanced effectiveness.
The evaluation encompasses complex cross-domain projects in software, game, and media development alongside comparative benchmarks against established agent frameworks. These experiments validate the system's ability to dynamically decompose tasks, coordinate specialized models across different families, and enforce quality control through structured review gates. Comparative analysis confirms that the proposed architecture surpasses fixed-baseline systems by supporting flexible, on-demand organizational evolution and seamless cross-modal coordination. Ultimately, the findings demonstrate that although multi-agent coordination increases computational overhead, the significant improvements in adaptability and success rates justify the trade-off for complex, project-level applications.