Command Palette
Search for a command to run...
LongCat-Next: モダリティを離散的なtokenとして語彙化する
LongCat-Next: モダリティを離散的なtokenとして語彙化する
Meituan LongCat Team
概要
現在の主流であるNext-Token Prediction (NTP) パラダイムは、離散的な自己回帰モデリング(discrete autoregressive modeling)を通じて、大規模言語モデル(LLM)の成功を牽引してきました。しかし、現代のマルチモーダルシステムは依然として言語中心であり、非言語的なモダリティを外部のアタッチメントとして扱うことが多く、その結果、アーキテクチャの断片化や統合の最適化不足を招いています。こうした限界を打破するために、我々はDiscrete Native Autoregressive (DiNA) を提案します。これは、マルチモーダル情報を共有の離散空間(shared discrete space)内で表現する統一フレームワークであり、モダリティを横断して一貫性のある原理に基づいた自己回帰モデリングを可能にします。本研究の主要な革新は、任意の解像度でtokenizationおよびde-tokenizationを行うDiscrete Native Any-resolution Visual Transformer (dNaViT) です。これにより、連続的な視覚信号を階層的な離散tokenへと変換します。この基盤の上に、我々はLongCat-Nextを開発しました。これは、モダリティ固有のデザインを最小限に抑えつつ、テキスト、視覚、音声を単一の自己回帰的な目的関数(autoregressive objective)の下で処理するネイティブなマルチモーダルモデルです。産業レベルの基盤モデル(foundation model)として、LongCat-Nextは単一のフレームワーク内で「見る」「描く」「話す」ことに長けており、広範なマルチモーダルbenchmarkにおいて強力な性能を発揮します。特に、LongCat-Nextは、理解タスクにおける離散的な視覚モデリングの長年の性能限界を解消し、理解(understanding)と生成(generation)の間の衝突を効果的に調和させる統一的なアプローチを提供します。広範な実験により、離散tokenはマルチモーダル信号を普遍的に表現でき、単一のembedding space内に深く内在化できることが示されました。これは、この統一された学習パラダイムに関する興味深い洞察を与えるものです。ネイティブなマルチモーダル化への試みとして、我々はLongCat-Nextとそのtokenizerをオープンソースとして公開し、コミュニティにおけるさらなる研究開発を促進することを目指しています。
One-sentence Summary
The Meituan LongCat Team introduces LongCat-Next, a native multimodal model leveraging the Discrete Native Autoregressive (DiNA) framework and Discrete Native Any-resolution Visual Transformer (dNaViT) to represent text, vision, and audio as discrete tokens at arbitrary resolutions, transcending language-centric limitations to reconcile the conflict between understanding and generation and achieve strong performance across a wide range of multimodal benchmarks.
Key Contributions
- The work introduces Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space to enable consistent autoregressive modeling across modalities. This approach transcends language-centric limitations by integrating non-linguistic modalities into a single principled architecture.
- A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions to transform continuous visual signals into hierarchical discrete tokens. Building on this foundation, LongCat-Next processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design.
- Extensive experiments demonstrate that discrete tokens can universally represent multimodal signals and achieve strong performance across a wide range of multimodal benchmarks. The work addresses the performance ceiling of discrete vision modeling on understanding tasks and provides open-source access to the LongCat-Next model and its tokenizers.
Introduction
Large language models rely on discrete next-token prediction, yet current multimodal systems often treat vision and audio as external attachments rather than native components. This language-plus-auxiliary approach results in fragmented architectures and suboptimal integration that hinders performance. Additionally, discretizing continuous visual signals traditionally causes information loss that limits both comprehension and generation capabilities. To address these challenges, the authors introduce the Discrete Native Autoregressive (DiNA) framework which unifies text, vision, and audio within a shared discrete token space. They develop the Discrete Native Any-resolution Visual Transformer (dNaViT) to tokenize visual inputs at arbitrary resolutions using semantic encoders and residual quantization. This enables LongCat-Next to process multiple modalities under a single autoregressive objective while overcoming the performance ceiling of discrete vision modeling.
Dataset

- Visual Understanding Corpus: The authors curate a diverse multimodal corpus comprising Image Caption, Interleaved Image-Text, OCR, Grounding, STEM, and GUI data to ensure broad coverage and high quality.
- Image Caption Data: A three-stage cleaning pipeline applies heuristic filtering, LVLM-based recaptioning, and SigLIP-based similarity pruning to retain only highly accurate matches.
- Interleaved Data: This subset combines web pairs filtered by CLIP scores with video segments processed via ASR and OCR to support fine-grained temporal and cross-modal learning.
- OCR Data: The dataset consists of 75% in-house synthetic data and 25% filtered real-world data from over 90 open-source datasets to ensure cross-scenario robustness.
- STEM Data: Construction involves 60% open-source datasets and 40% proprietary or synthetic data, with problem statements rewritten to enhance multi-step reasoning chains.
- Grounding and Counting: The team aggregates over ten public sources to create approximately 60M grounding samples and 8M counting samples using a normalized coordinate system.
- Visual Generation Strategy: An in-house dataset of approximately 300 million image-text pairs is organized into three progressive training stages to maximize semantic coverage.
- Stage I Pre-training: Multi-stage filtering removes near-duplicates and low-quality samples while Qwen3-VL-8B generates structured descriptions with integrated OCR signals.
- Stage II Mid-training: SigLIP2 embeddings and K-Means clustering partition the dataset to rebalance semantic distribution via power-law reweighting of sparse clusters.
- Stage III Supervised Fine-Tuning: High-quality exemplars are selected from semantic clusters alongside high-aesthetic and text-rich subsets to align with complex human instructions.
- Audio Pre-training Sources: The pipeline processes 19.9 million hours of raw web audio down to 3.2 million hours while supplementing it with 1.2 million hours of synthetic speech-text data.
- Task-Specific Audio: An additional 0.4 million hours of curated datasets support specialized capabilities like paralinguistic perception and audio-event understanding.
- Audio Processing and Formats: Techniques include VAD, forced alignment, speaker embedding clustering, and re-segmentation to manage noise and ensure balanced speaker distributions.
- Loss Computation: The model omits loss computation for pure audio modalities in ASR and interleaved tasks while computing joint loss for text-audio modalities in TTS and INTLV-TA.
Method
The proposed framework adopts a discrete modeling approach where modality-specific tokenizers convert raw signals into discrete IDs, allowing a modality-agnostic decoder-only backbone to serve as a unified multi-task learner. Refer to the framework diagram.
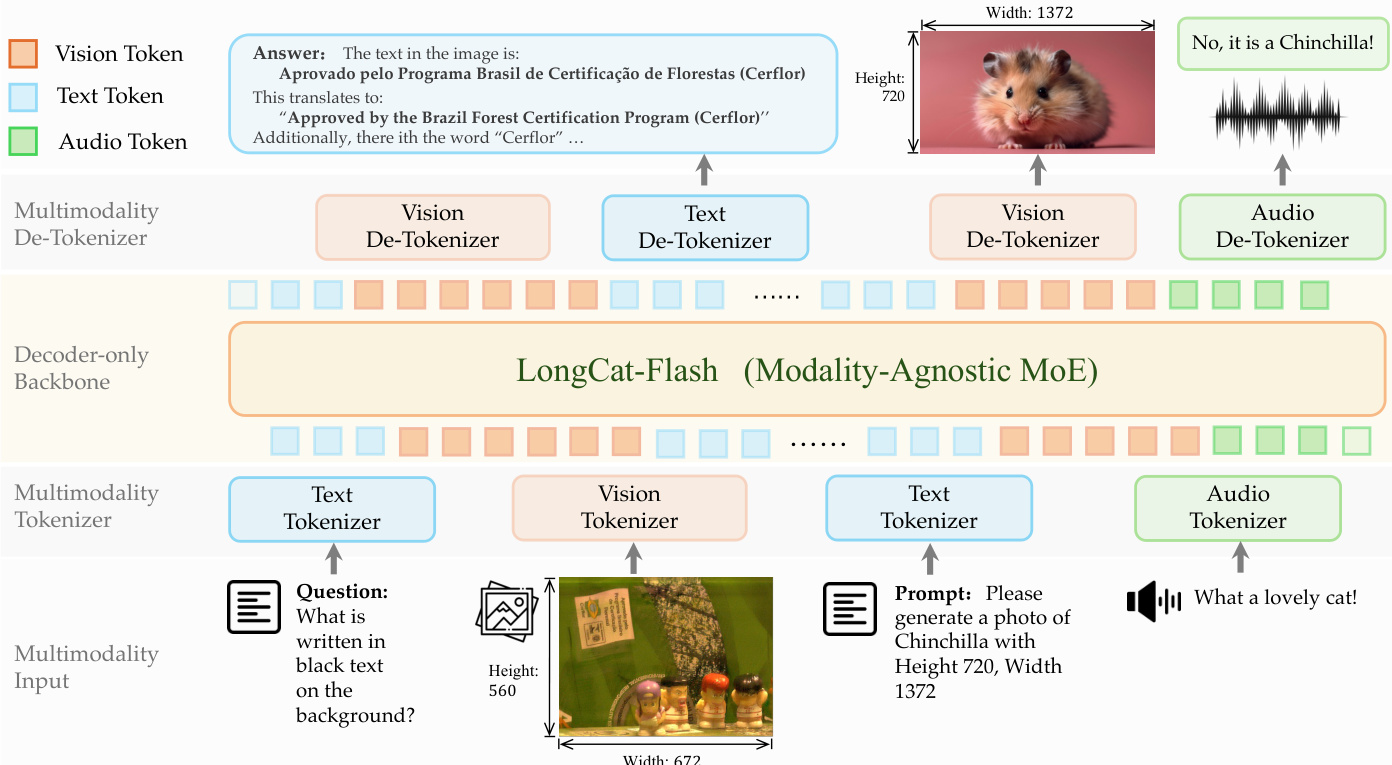
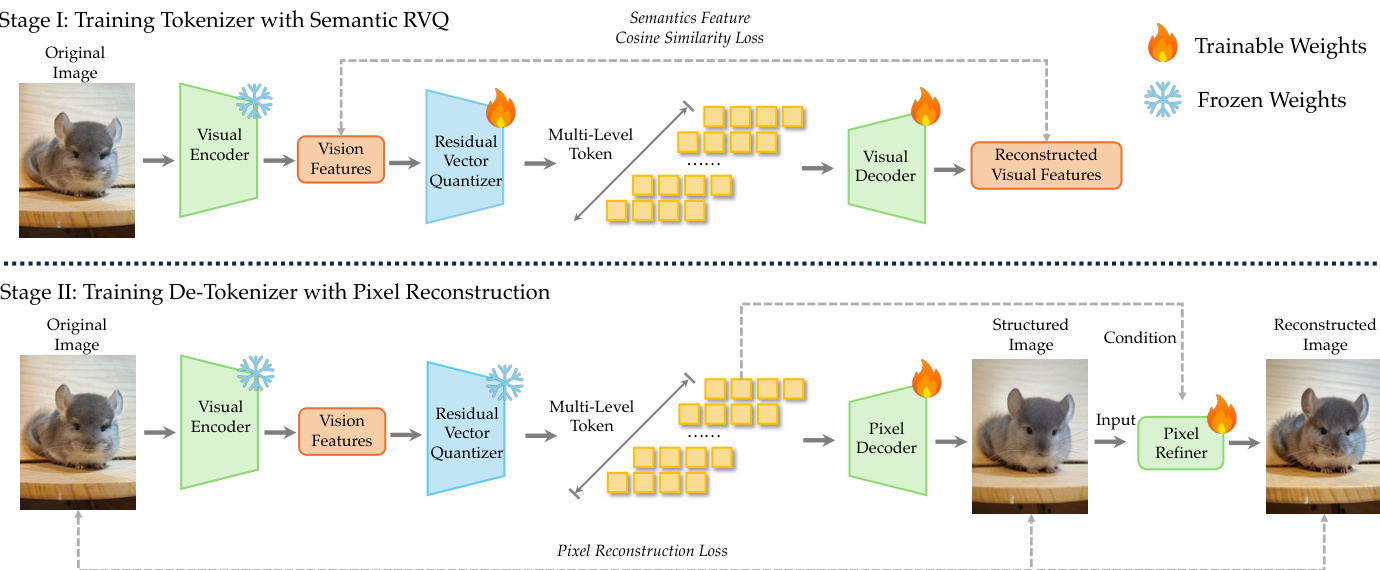
For visual processing, the system employs dNaViT, a Discrete Native-Resolution Vision Transformer. Unlike conventional encoders that rely on fixed resolutions, dNaViT operates on images at their native resolution to preserve spatial details and avoid information loss. The tokenization pipeline involves a Semantic-and-Aligned Encoder (SAE) followed by Residual Vector Quantization (RVQ). Refer to the tokenizer and de-tokenizer training pipeline.
The SAE projects an image I into a pre-quantization representation zp that preserves information necessary for diverse image-centric queries. The discretization process decomposes the quantization of SAE features into L cascaded codebook levels using RVQ. The process is defined as:
r0=fproj(z),q^l=VQ(rl−1),rl=rl−1−q^l,z^=l=1∑Lq^lThe training of the vision tokenizer occurs in two stages. In Stage I, the model learns to map continuous features to discrete tokens using semantic alignment and RVQ. In Stage II, a pixel decoder is trained to reconstruct images from these discrete tokens, ensuring the representation retains sufficient information for generation. Refer to the visual reconstruction pipeline.
For audio processing, a dedicated tokenizer transforms continuous speech into discrete tokens. The architecture utilizes a Whisper encoder for feature extraction, followed by an 8-layer RVQ for quantization. Refer to the audio tokenizer framework.
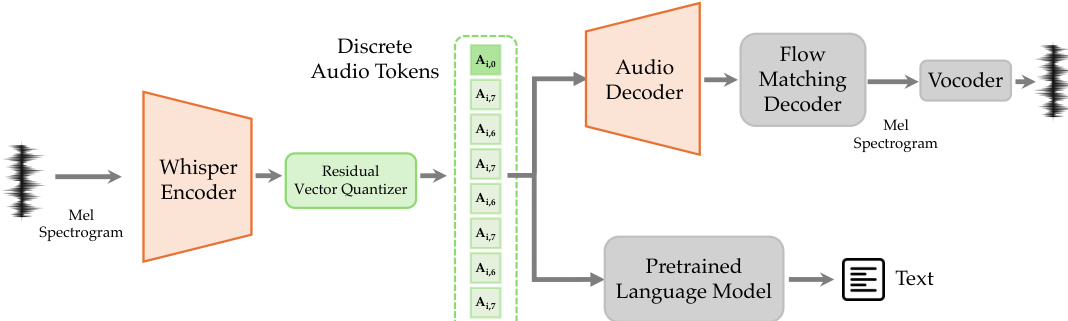
The resulting tokens are processed by two branches: a frozen pretrained language model for understanding and an audio decoder with a flow-matching module for synthesis. The training objective includes Mel spectrogram reconstruction loss, RVQ commit loss, and LLM loss for audio understanding:
Laudio=λ1Lrecon+λ2Lcommit+λ3LllmThe backbone model, LongCat-Flash, is a Mixture-of-Experts (MoE) architecture that remains modality-agnostic. It supports both parallel and serial generation strategies for text-guided audio. Refer to the speech generation strategies.
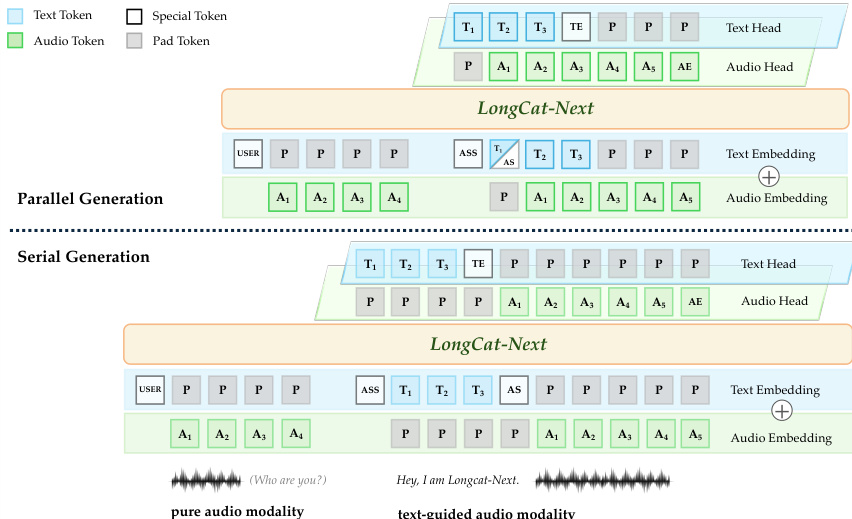
In parallel generation, text and audio tokens are generated simultaneously with a slight delay for alignment to eliminate response latency. In serial generation, the model produces the text segment first, followed by the audio segment, which simplifies the process and avoids conflicts between modality representations.
Experiment
The study evaluates a unified omni-modal system against leading baselines across vision, audio, text, and generation tasks to validate its comprehensive reasoning and perception abilities. Results indicate the model achieves superior performance in mathematical reasoning and text rendering while maintaining competitive capabilities in general visual question answering and audio comprehension without compromising text-based cognitive functions. Further ablation studies reveal that discrete modeling can match continuous counterparts with sufficient data, and that integrating understanding and generation tasks creates a synergistic relationship that enhances overall semantic consistency.
The the the table outlines a four-stage training curriculum for a unified omni-modal system, progressing from initial alignment to specialized instruction tuning. The methodology systematically increases sequence length and data complexity while reducing batch sizes as the model moves from pre-training to supervised fine-tuning. The training process begins with pre-alignment using basic image and audio data before expanding to include OCR, grounding, and interleaved text in the pre-training stage. Sequence length capabilities are progressively scaled up from the initial stages to the final fine-tuning phase to support long-context reasoning and generation. Full parameter training is activated in the later stages, whereas the initial alignment phase focuses on updating only specific embedding and depth components.
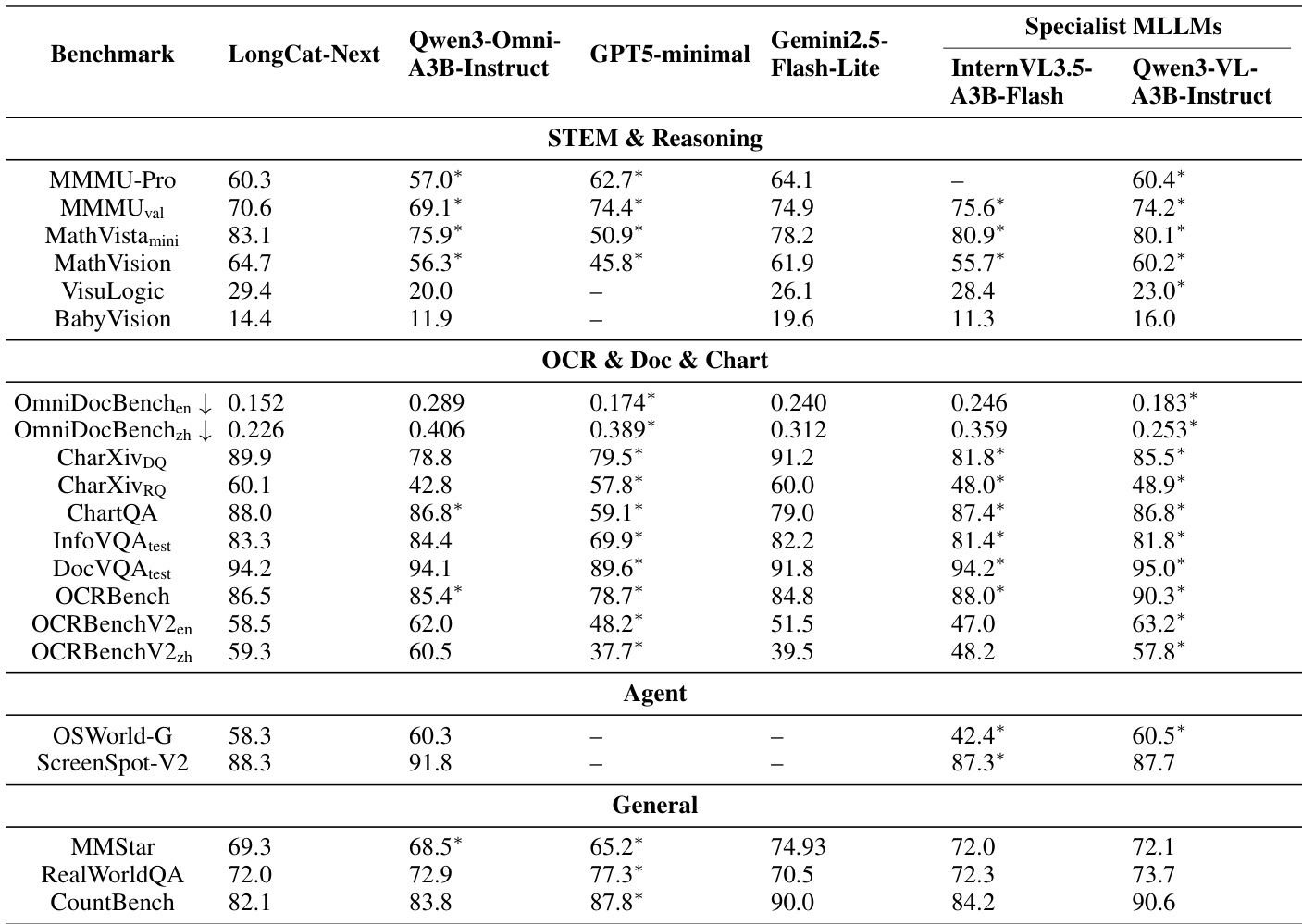
The authors evaluate LongCat-Next against state-of-the-art unified and specialist models across diverse benchmarks including STEM, OCR, and general visual understanding. The results demonstrate that the model achieves leading performance in mathematical reasoning and document analysis, often outperforming dedicated vision-language models and other omni-modal systems. Additionally, the model maintains competitive capabilities in agent tasks and general visual question answering, validating its robustness across multiple modalities. The model secures top rankings in mathematical reasoning benchmarks, surpassing specialist vision-language models on tasks involving complex logic and math. Performance on document understanding and OCR benchmarks is superior to baselines, indicating strong fine-grained text perception capabilities. General visual understanding scores are highly competitive, with the model leading on specific benchmarks like MMStar and RealWorldQA.
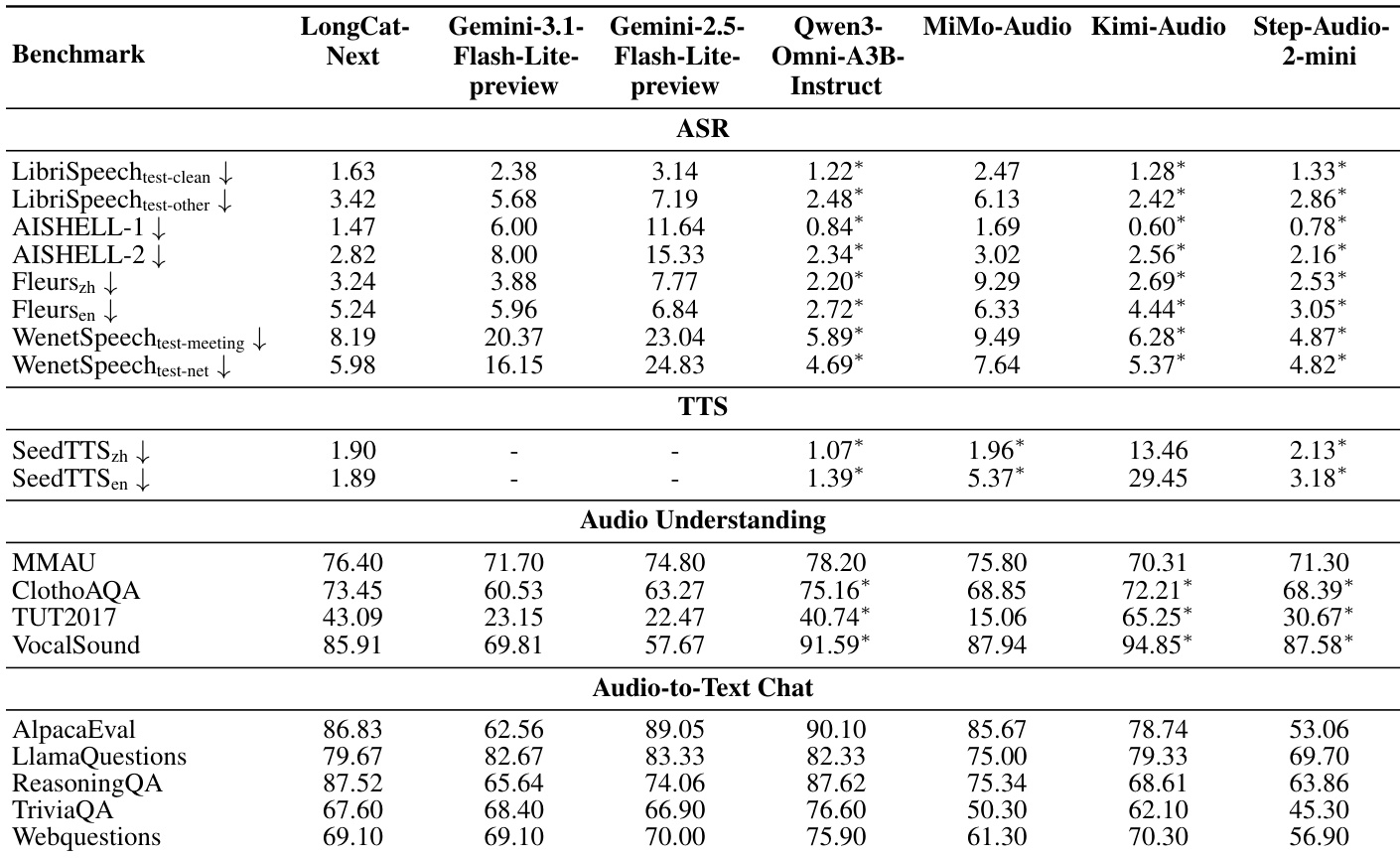
The the the table presents a comprehensive evaluation of LongCat-Next's audio capabilities against leading multimodal and specialized models across speech recognition, synthesis, understanding, and chat tasks. LongCat-Next demonstrates significant advantages over the Gemini series in speech recognition and synthesis tasks, consistently achieving lower error rates. While it remains competitive with top-tier baselines in reasoning and chat capabilities, it generally records higher error rates in ASR and lower scores in audio understanding compared to specialized models like Kimi-Audio and Qwen3-Omni. LongCat-Next achieves substantially lower error rates than Gemini models in automatic speech recognition across all tested datasets. In text-to-speech synthesis, the model outperforms MiMo-Audio and Step-Audio-2-mini, particularly on English benchmarks. The model demonstrates strong reasoning capabilities in audio-to-text chat, closely matching the performance of Qwen3-Omni on the ReasoningQA benchmark.
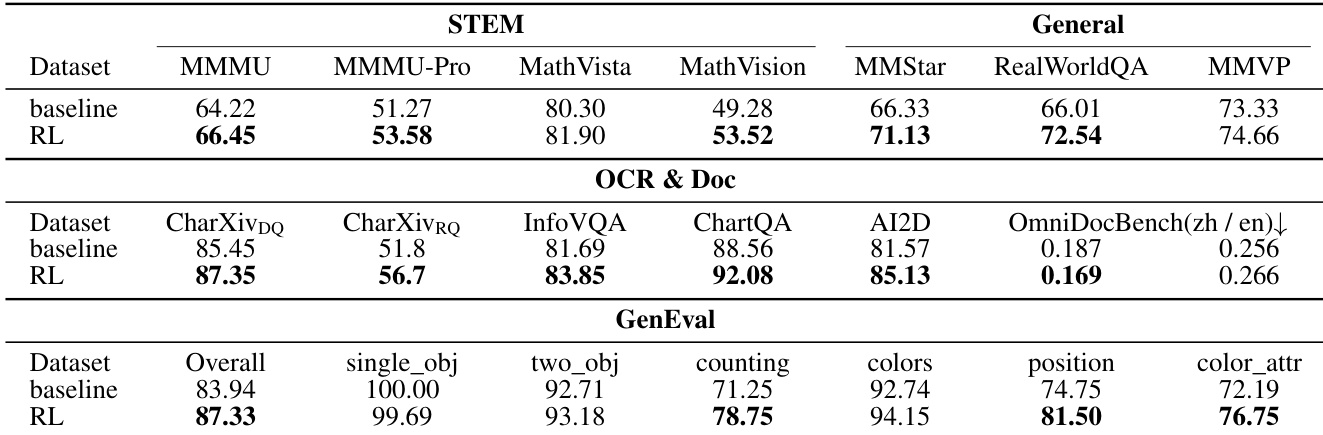
The authors evaluate a model's performance with and without Reinforcement Learning (RL) across STEM, OCR, and visual generation benchmarks. The results indicate that incorporating RL consistently improves the model's capabilities in reasoning, document understanding, and image generation tasks compared to the baseline. Reinforcement Learning enhances performance across STEM benchmarks, showing gains in mathematical and multi-disciplinary reasoning. The RL variant achieves superior results in OCR and document tasks, particularly for chart question answering and information extraction. Visual generation capabilities improve overall, with the RL model outperforming the baseline in general alignment and complex attribute tasks.
The experiment evaluates the reconstruction capabilities of various visual encoders, including ResNet50, ViT variants, and QwenViT, using fidelity and perceptual metrics. Results indicate that a randomly initialized ViT achieves the highest pixel-level accuracy, while the ResNet50 model demonstrates the best perceptual quality. In contrast, the QwenViT encoder without the merger module exhibits the lowest performance across all measured dimensions. Randomly initialized ViT-B/16 achieves superior pixel-level reconstruction fidelity compared to pretrained or semantic encoders. ResNet50 maintains the strongest perceptual quality, outperforming other architectures in distribution similarity. The QwenViT encoder without the merger module shows the weakest reconstruction capabilities among the tested models.

A progressive four-stage training curriculum scales sequence length and data complexity to support long-context reasoning in a unified omni-modal system. Evaluations show the model leads in mathematical reasoning and document analysis while remaining competitive in general visual and audio reasoning benchmarks. Furthermore, experiments confirm that Reinforcement Learning improves reasoning and generation, while encoder ablations highlight trade-offs between pixel fidelity and perceptual quality.