Command Palette
Search for a command to run...
面向视角自适应的人体视频生成的3D感知隐式运动控制
面向视角自适应的人体视频生成的3D感知隐式运动控制
Zhixue Fang Xu He Songlin Tang Haoxian Zhang Qingfeng Li Xiaoqiang Liu Pengfei Wan Kun Gai
摘要
现有的视频生成中人体运动控制方法通常依赖于2D姿态或显式的3D参数化模型(如SMPL)作为控制信号。然而,2D姿态会将运动严格绑定于驱动视角,无法实现新视角下的合成。尽管显式3D模型在结构上具有信息量,但其固有的不准确性(如深度模糊性和动态建模偏差)在作为强约束条件使用时,会压制大规模视频生成器内在的3D感知能力。本文从3D感知的视角重新审视运动控制问题,主张采用一种隐式的、视角无关的运动表征,使其自然契合生成器的空间先验,而非依赖外部重建的约束。为此,我们提出3DiMo,该方法联合训练一个运动编码器与预训练的视频生成器,将驱动帧中的运动信息提炼为紧凑且视角无关的运动标记(motion tokens),并通过交叉注意力机制以语义方式注入生成过程。为增强模型的3D感知能力,我们在包含丰富视角的监督信号下进行训练,涵盖单视角、多视角以及运动相机视频,强制模型在不同视角间保持运动一致性。此外,我们引入辅助的几何监督机制,仅在初始化阶段使用SMPL模型,随后逐步退火至零,促使模型从外部3D引导逐步过渡到基于数据和生成器先验自主学习真实的3D空间运动理解。实验结果表明,3DiMo能够准确还原驱动运动,并支持灵活的文本驱动相机控制,在运动保真度与视觉质量方面显著优于现有方法。
一句话总结
快手科技、清华大学和中科院自动化所的研究人员提出了3DiMo,这是一种与视角无关的运动表示方法,能够通过文本引导的相机控制,从2D视频中忠实再现3D运动,其性能优于先前方法,因为它与生成器先验对齐,而非依赖刚性3D模型。
主要贡献
- 3DiMo引入了一种具备3D感知的运动控制框架,可从2D驱动视频中提取隐式的、与视角无关的运动标记,从而实现无需外部3D模型刚性几何约束的新视角合成和文本引导相机控制。
- 该方法联合训练运动编码器与预训练视频生成器,利用丰富的视角监督(包括单视角、多视角和移动相机视频),以确保跨视角的运动一致性,并与生成器的内在空间先验对齐。
- 仅在早期训练阶段使用来自SMPL的辅助几何监督,并逐步退火至零,使模型能够从外部引导过渡到学习真正的3D运动理解,从而在基准任务上实现最先进的运动保真度和视觉质量。
引言
作者利用大规模视频生成器固有的3D空间感知能力,重新思考人体运动控制,超越了刚性2D姿态条件或易出错的显式3D模型(如SMPL)。先前方法要么将运动锁定在驱动视角,要么施加不准确的3D约束,从而覆盖生成器的原生先验,限制了视角灵活性和运动保真度。其主要贡献是3DiMo,这是一种端到端框架,通过Transformer编码器从2D驱动帧中学习隐式的、与视角无关的运动标记,并通过交叉注意力注入以与生成器的空间理解对齐。训练使用丰富的视角监督(单视角、多视角和移动相机视频)以及与SMPL关联的退火辅助损失,用于早期几何引导,使模型能够向真正的3D运动推理过渡。这实现了高保真、文本引导的相机控制,同时保持跨视角的3D一致性。
数据集
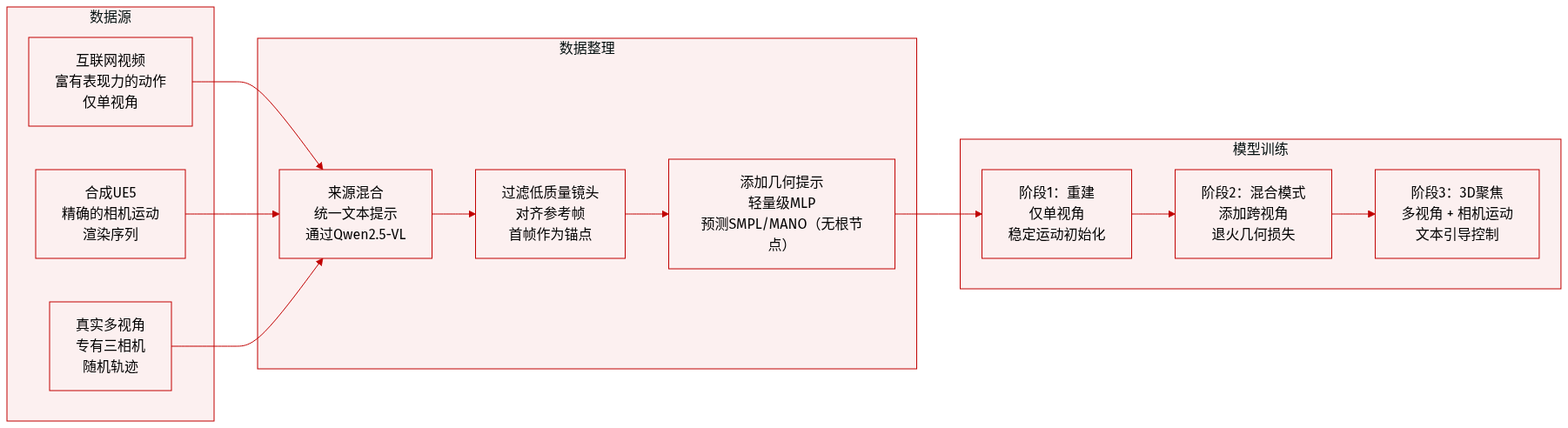
- 作者构建了一个视角丰富的3D感知数据集,结合了三个来源:大规模互联网视频用于表现多样化的运动,合成的UE5渲染序列用于精确的相机运动控制,以及真实世界的多视角捕捉(包括专有录制)用于真实的3D监督。
- 互联网视频在数量上占主导地位,并在单视角重建下训练表现力强的运动动态;合成和真实多视角数据规模较小,但对通过跨视角运动再现和移动相机监督强制3D一致性至关重要。
- 使用Qwen2.5-VL生成相机视角和运动的文本提示,统一所有数据类型的注释,用于文本引导的相机控制。
- 训练遵循三阶段渐进策略:第1阶段仅使用单视角重建以稳定运动初始化;第2阶段混合重建和跨视角再现,向3D语义过渡;第3阶段完全专注于多视角和相机运动数据,以强化与视角无关的运动特征。
- 参考图像取自目标视频的第一帧,以使生成的运动与主体方向对齐,避免显式相机对齐或SMPL回归。
- 早期通过轻量级MLP解码器引入辅助几何监督,预测SMPL/MANO姿态参数(不包括全局根部方向),以稳定训练并初始化运动表示;该监督在第3阶段逐步退火并移除。
- 专有真实世界捕捉使用三相机阵列,配以随机相机运动(包括静态、线性、变焦和复杂轨迹),与相同的人体运动配对,以最大化与视角无关的学习信号。
方法
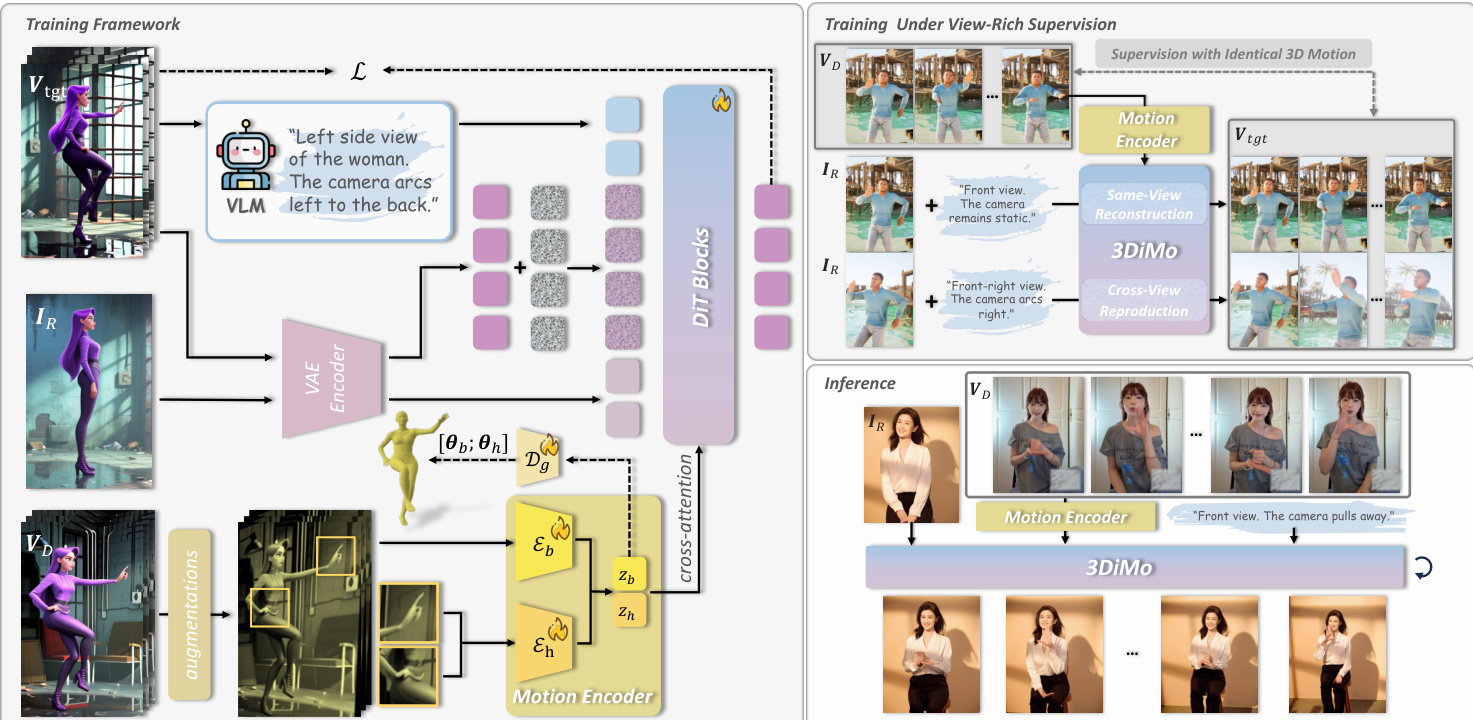
作者利用预训练的DiT视频生成模型作为主干,该模型以参考图像、驱动视频和文本提示为条件,合成目标视频,重演驱动运动的同时保留文本引导的相机控制。核心创新在于设计了一个隐式运动编码器,与生成器端到端训练,从2D驱动帧中提取与视角无关的运动表示,并通过交叉注意力注入,以实现语义一致的运动迁移。
请参阅框架图,该图展示了完整流程。运动编码器包含两个专用组件:身体编码器 Eb 和手部编码器 Eh,分别用于捕捉粗略的身体运动和精细的手部动态。驱动帧首先通过随机透视变换和外观扰动增强,以鼓励编码器丢弃视角特定和身份相关的线索。每帧被分割为视觉标记,并与固定数量 K 的可学习潜在标记连接。经过多层注意力后,仅保留潜在标记作为运动表示 zb 和 zh,形成语义瓶颈,剥离2D结构信息,同时保留内在的3D运动语义。
这些运动标记随后被连接并通过交叉注意力层注入DiT生成器,这些层附加在每个完整的自注意力块之后。该设计允许运动标记与视频标记在语义上交互,而不施加刚性空间对齐约束,从而灵活地与生成器原生的文本驱动相机控制共存。文本提示(可能包含相机运动指令)通过与视觉标记相同的自注意力机制处理,实现运动和视角的联合控制。
为了赋予运动表示3D感知能力,作者在早期阶段引入了几何监督,使用参数化人体模型(身体使用SMPL,手部使用MANO)。在训练期间,辅助解码器将运动标记回归到外部3D姿态参数 θb 和 θh,提供几何对齐信号以加速空间理解。该框架在包含单视角、多视角和相机运动序列的视角丰富数据集上训练,使模型能够学习跨视角运动一致性和真正的3D运动先验。训练在同视角重建和跨视角运动再现任务之间交替进行,强化表达性、3D感知运动表示的出现。
在推理时,运动编码器直接处理2D驱动帧以提取运动标记,然后用于在任意文本引导的相机轨迹下动画任何参考主体。这消除了对外部姿态估计或显式3D重建的需求,实现了高保真、视角自适应的运动控制视频生成。
实验
- 3DiMo在运动控制和视觉保真度方面优于最先进的2D和3D方法,特别是在LPIPS、FID和FVD指标上表现优异,尽管由于优先考虑几何一致性而非像素对齐,PSNR/SSIM略低,但仍展示了卓越的3D感知重演能力。
- 定性结果显示,3DiMo生成物理合理、深度准确的运动,避免了2D方法中常见的肢体顺序错误和SMPL方法中的姿态不准确,尤其在动态相机提示下表现突出。
- 用户研究证实,3DiMo在运动自然性和3D合理性方面表现优异,验证了其学习的运动表示比参数化或2D对齐方法更好地捕捉空间和动态真实性。
- 消融研究表明,隐式运动表示、多阶段视角丰富训练、交叉注意力条件和辅助几何监督对于稳定训练和3D感知控制至关重要;移除它们会导致质量下降或崩溃。
- 该模型支持新应用:单图像人体新视角合成(稳定主体渲染)、通过强制静态相机提示实现视频稳定化,以及通过与视角无关的运动迁移实现自动运动-图像对齐(无需手动校准)。
作者评估了模型的消融变体,发现移除关键组件(如几何监督、手部运动编码)或使用通道拼接代替交叉注意力会一致降低性能。完整模型在各项指标上达到最佳平衡,尤其是在FID和FVD上,表明其具有优越的视觉保真度和运动连贯性。结果证实,使用视角丰富数据和辅助监督的多阶段训练对于稳定学习和3D感知运动控制至关重要。
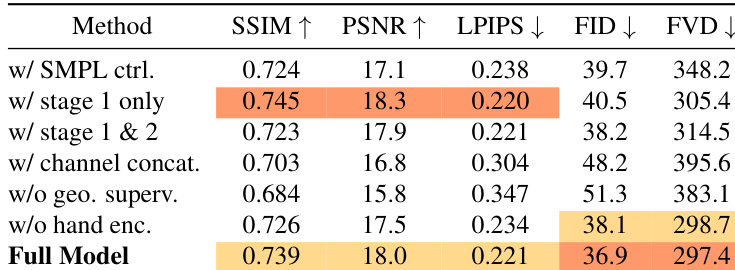
作者使用3D感知的隐式运动表示,相比基于2D姿态和基于SMPL的基线方法,在运动控制和视觉保真度方面表现更优。结果表明,该方法在感知指标和用户研究中优于其他方法,尤其在运动自然性和3D合理性方面,尽管由于强制几何一致性,像素级得分略低。消融研究确认,多阶段视角丰富训练和交叉注意力条件对于稳定、高保真的3D运动合成至关重要。
