Command Palette
Search for a command to run...
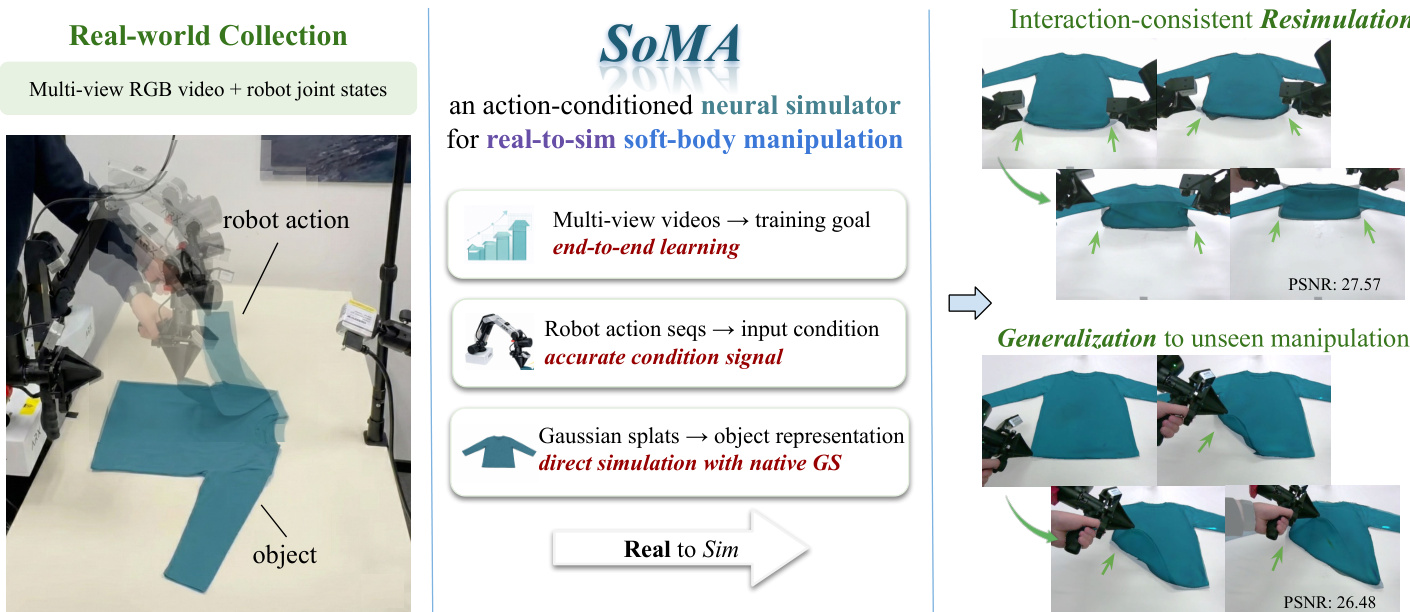
SoMA:一种用于机器人软体操作的真实到仿真神经模拟器
SoMA:一种用于机器人软体操作的真实到仿真神经模拟器
Mu Huang Hui Wang Kerui Ren Linning Xu Yunsong Zhou Mulin Yu Bo Dai Jiangmiao Pang
摘要
在真实世界到仿真环境的机器人操作中,对具有丰富交互行为的可变形物体进行模拟仍是核心挑战,其动力学行为由环境效应与机器人动作共同驱动。现有仿真器通常依赖预设的物理模型或数据驱动的动力学机制,但缺乏机器人状态条件下的控制建模,导致仿真精度、稳定性与泛化能力受限。本文提出SoMA——一种面向软体物体操作的三维高斯点阵(3D Gaussian Splat)仿真系统。SoMA在统一的隐式神经空间中联合建模可变形体动力学、环境作用力以及机器人关节动作,实现端到端的真实到仿真映射。通过在学习得到的高斯点阵上建模交互关系,系统能够实现可控、稳定的长时程操作,并在不依赖预设物理模型的前提下,实现对未见轨迹的泛化。实验表明,SoMA在真实机器人操作任务的重仿真精度与泛化能力方面提升达20%,并成功实现了如长时程布料折叠等复杂任务的稳定仿真。
一句话总结
来自多个机构的研究人员提出了 SoMA,一种基于高斯点绘(Gaussian Splat)的神经模拟器,统一了可变形动力学与机器人动作,实现了稳定、长时程的现实到仿真操作,在布料折叠等任务中比先前方法在准确性和泛化性上提升 20%。
主要贡献
- SoMA 引入了一种新颖的现实到仿真神经模拟器,用于软体操作,其在 3D 高斯点绘上运行,将可变形动力学、环境力和机器人关节动作统一到潜在空间中,从而无需预定义物理模型即可实现稳定、长时程的仿真。
- 它提出了基于机器人条件的动力学建模和高斯点绘上的力驱动更新,确保即使在部分遮挡下也能实现运动学和物理一致性交互,结合多分辨率训练和混合监督,以在延长的操作序列中保持稳定性。
- 在真实世界基准测试中,SoMA 在重仿真准确性和泛化性上比先前方法提升 20%,能够在已见和未见机器人动作下可靠地仿真布料折叠等复杂任务。
引言
作者利用高斯点绘表示构建 SoMA —— 一种神经模拟器,通过直接从多视角 RGB 视频和机器人关节动作中学习可变形动力学,实现现实到仿真的软体操作。先前的模拟器要么依赖难以从视觉数据校准的刚体物理模型,要么依赖缺乏机器人条件交互且在长时程任务中漂移的神经模型。SoMA 通过在点绘上建模力驱动动力学、将仿真锚定到真实机器人运动学,并使用多分辨率训练与混合监督,克服了这些限制,实现了重仿真中 20% 的更高准确率,并支持在未见操作下进行布料折叠等复杂任务。
数据集
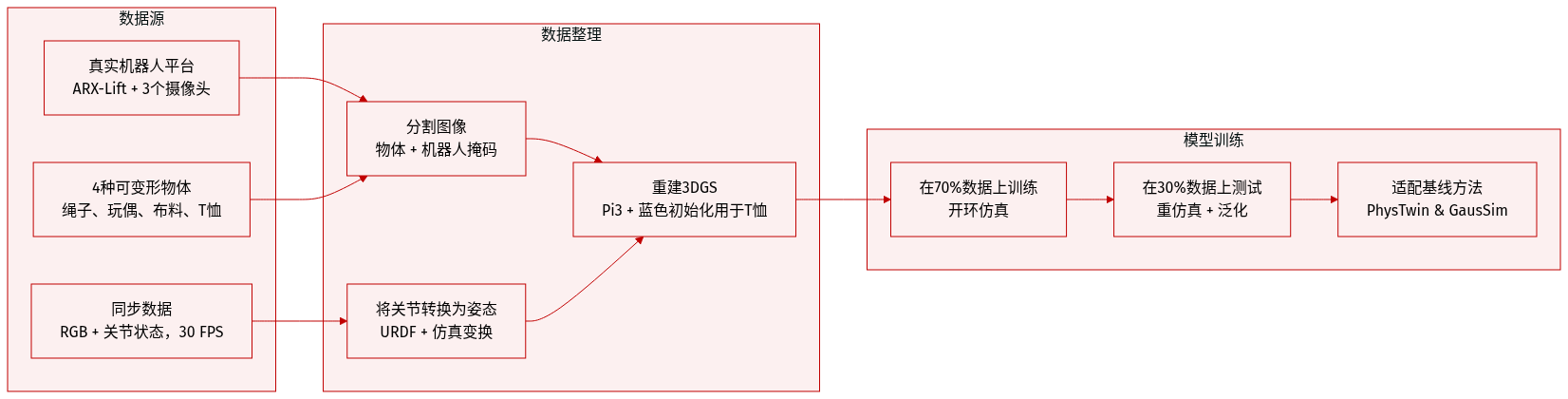
-
作者在 ARX-Lift 平台上收集真实世界机器人操作数据,包含四种可变形物体:绳子、玩偶、布料和 T 恤。每个物体有 30–40 个序列,每序列 100–150 帧,以 640×480 分辨率和 30 FPS 采集,同时同步记录机器人关节状态。数据集按 7:3 划分为训练集和测试集。
-
数据通过三个 Intel RealSense D405 相机采集:一个安装在机器人末端执行器上用于机器人条件映射,另两个固定在桌面周围以提供多视角覆盖。所有图像使用 GroundingDINO 和 Grounded-SAM2 进行分割,生成物体掩码(用于监督)和机器人掩码(用于识别遮挡)。
-
机器人关节状态通过 URDF 模型转换为末端执行器姿态和夹爪参数,然后通过学习的机器人到仿真变换映射到统一的仿真坐标系。该变换由 Pi3 估计的机器人和重建坐标系中的已知相机姿态推导得出,用于相机姿态估计和 3D 点云重建。
-
重建的点云转换为 3D 高斯点绘(3DGS)表示。对于 T 恤序列,点绘颜色初始化为蓝色,以在遮挡或弱观测区域保持一致外观。
-
作者使用训练集训练模型,未明确提及混合比例。评估时,模型以重建的高斯点绘初始化,并基于每帧机器人动作执行开环仿真。基线方法如 PhysTwin 和 GausSim 被适配:PhysTwin 使用圆形控制点进行交互,而 GausSim 无显式控制输入,以初始点绘状态进行自回归预测。
方法
作者利用名为 SoMA 的统一神经仿真框架,直接基于机器人关节空间动作和多视角视觉观测,建模机器人操作下的可变形物体动力学。该架构整合了真实世界感知、分层物理仿真和多分辨率训练,以实现稳定、长时程的重仿真和对未见交互的泛化。
SoMA 的核心是一种场景到仿真的映射,将异构坐标系——机器人运动学、相机姿态和重建物体几何——对齐到共享物理空间。初始物体状态从多视角 RGB 图像重建为一组高斯点绘(GS),机器人末端执行器姿态通过学习的相似变换转换到仿真坐标系,该变换强制度量和重力一致性。这种统一初始化确保机器人动作(如夹爪状态和末端执行器姿态)可直接驱动物体动力学,而无需将控制与几何解耦。
参见框架图,其展示了端到端流程:真实世界多视角视频和机器人关节状态被映射到仿真空间,其中高斯点绘作为原生物体表示。模拟器随后预测未来状态 Gt=ϕθ(Gt−1,Gt−2,Rt),该状态以机器人动作为条件,并在已知相机姿态下渲染预测状态以计算图像重建损失。这种闭环训练实现了来自视觉观测的直接监督,同时保持物理合理性。
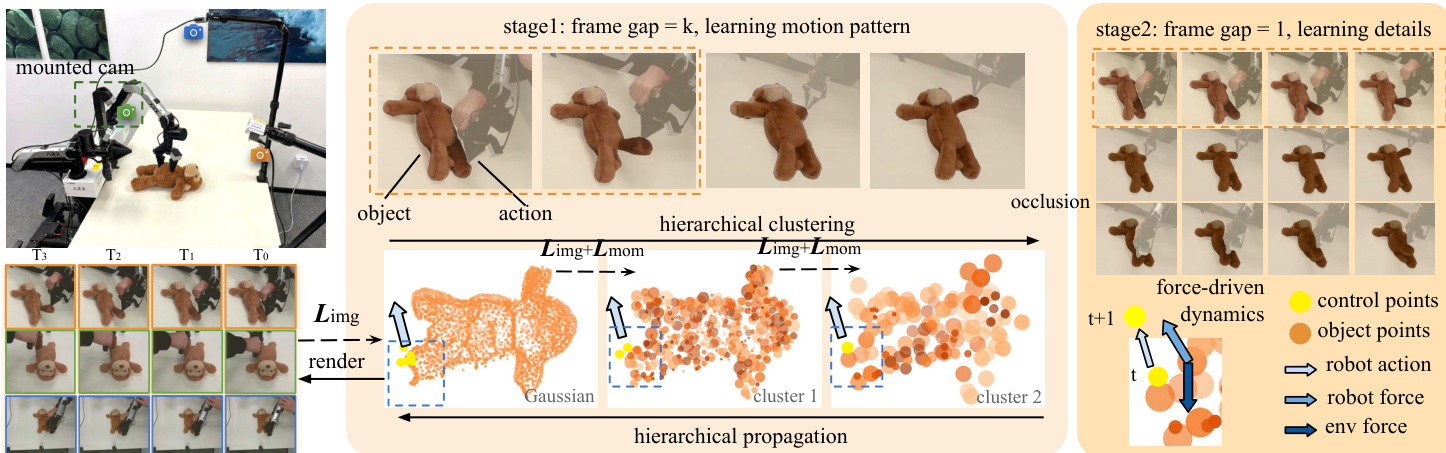
动力学模型在高斯点绘的分层图上运行,其中较粗层级的节点表示聚合的局部结构。动力学自顶向下传播:每个聚类节点预测潜在运动和变形状态,然后通过学习的仿射变换 Fki 传递给子节点。这种分层结构在保持局部细节的同时实现全局一致性,如状态传播方程所示:
x^kh−1=x^chh+j=h∏LFkj(Xk−Xch), Σ^kh−1=(i=h∏LFki)Σk(i=h∏LFki)⊤.关键的是,SoMA 将物体动力学建模为力驱动而非仅状态驱动。环境力(重力和支持力)和机器人诱导力在 GS 层面计算并分层聚合。机器人力通过基于图的交互模块 Φθ 预测,该模块考虑邻近机器人控制点和夹爪状态。总力 fi=fienv+firob 输入到分层动力学预测器 ψθ,输出每个节点的线速度和角速度:
(vi,ωi)=ψθ(git−1,git−2,fi).为稳定长时程仿真,作者采用多分辨率训练策略。时间上,模型首先以粗帧间隔训练以捕捉运动模式,然后在原生分辨率下使用随机采样的子序列微调。空间上,动力学在原始图像分辨率下训练,而几何从超分辨率图像重建以保留细节。这种双分辨率方法减轻误差累积并降低计算成本。
如下图所示,训练流程整合了遮挡感知图像监督和物理启发的动量一致性。图像损失使用物体掩码 Mt 对可见区域进行掩码,结合 L2 和 D-SSIM 项:
Limg(t)=λMt⊙(I^t−It)22+(1−λ)LD−SSIM(Mt⊙I^t,Mt⊙It).对于缺乏视觉反馈的遮挡区域,动量一致性正则化在层级间强制物理合理性:
Lmom=l=1∑L−1mclx^cl−i∈Cl−1∑mix^iO2.这种混合监督确保即使在部分可观测性下也能实现稳定、交互感知的仿真。
这些组件共同构成一个连贯的仿真流程,能够准确重仿真训练轨迹,并泛化到新颖的机器人动作和接触配置,如在绳子、布料和体积玩具等多样软体物体上所展示。
实验
- 成功在多种操作下模拟可变形物体(布料、绳子、玩偶),在长时程内保持稳定动力学和准确视觉重建。
- 在未见动作和接触配置下表现良好,优于在新颖交互下退化的基于状态和物理的基线方法。
- 处理复杂、长时程任务如 T 恤折叠,处理大变形和自接触,保持其他方法失败时的几何一致性。
- 消融研究确认关键组件——混合监督、多分辨率训练和联合域训练——对稳定性和泛化至关重要。
- 展示跨设置适用性,包括来自 PhysTwin 数据集的手驱动运动,显示超越机器人动作条件的鲁棒性。
- 支持具身操作的实际仿真,促进策略开发并减少现实迁移的现实差距。
作者在图像和深度指标上评估 SoMA 与 PhysTwin,显示 SoMA 在所有指标上均表现更优。结果表明 SoMA 产生更准确的视觉重建和几何一致性,尤其在复杂机器人-物体交互下。这证明其在现实到仿真模拟中相比基于物理的可微分模拟器更具鲁棒性。

作者通过改变帧子采样间隔 k 评估多分辨率时间训练的影响,发现性能在测试值范围内保持稳定。结果表明 PSNR 在 k=10 和 k=15 时达到峰值,而 RMSE 始终保持较低,表明训练策略对时间分辨率的适度变化具有鲁棒性。这支持使用由粗到精的训练来稳定长时程仿真,而无需精确调整子采样率。

作者使用 SoMA 模拟机器人操作下的可变形物体,显示其在所有基于图像的指标(包括 PSNR、SSIM 和 LPIPS)上均优于 PhysTwin。结果表明 SoMA 在绳子、布料和玩偶物体上保持更高的视觉保真度和结构一致性,表明在重仿真任务中更强的泛化性和稳定性。

作者在布料重仿真和泛化任务上评估模型的消融变体,发现完整模型在重仿真准确率上最高,而联合训练提升泛化性。移除多分辨率训练或混合监督会降低性能,仅图像变体下降最大,尤其在泛化性上。这些结果突出了多分辨率训练和物理信息监督对稳定、可迁移的可变形物体仿真的重要性。

作者使用 SoMA 模拟机器人操作下的可变形物体,显示其在图像和深度指标上的重仿真和泛化任务中均优于 PhysTwin 和 GausSim。结果表明 SoMA 在长时程内保持稳定、准确的动力学,并能很好地适应未见动作,而基线方法表现出误差增加或结构崩溃。该方法的鲁棒性源于其交互感知设计和多分辨率训练,即使在复杂、自接触密集的场景下也能实现可靠仿真。
