Command Palette
Search for a command to run...
EgoActor:通过视觉-语言模型将任务规划嵌入空间感知的视角动作中以实现类人机器人
EgoActor:通过视觉-语言模型将任务规划嵌入空间感知的视角动作中以实现类人机器人
Yu Bai MingMing Yu Chaojie Li Ziyi Bai Xinlong Wang Börje F. Karlsson
摘要
在现实场景中部署类人机器人面临根本性挑战,这要求在部分观测信息和动态变化环境的条件下,实现感知、运动与操作的高度协同,并能稳健地在不同类型子任务之间进行切换。为应对这些挑战,我们提出了一项新任务——EgoActing,该任务旨在将高层指令直接转化为多种精确、具备空间意识的类人动作。为进一步实现这一任务,我们提出了EgoActor,这是一个统一且可扩展的视觉-语言模型(VLM),能够实时预测运动基元(如行走、转向、侧移、高度调整)、头部运动、操作指令以及人机交互行为,从而协调感知与执行过程。EgoActor利用来自真实世界示范的视角RGB数据、空间推理问答任务以及模拟环境中的示范数据,获得广泛监督信号,使模型能够在8B和4B参数规模下均实现鲁棒、上下文感知的决策,并在1秒内完成流畅的动作推断。在模拟环境与真实场景中的大量评估结果表明,EgoActor能够有效连接抽象的任务规划与具体的运动执行,同时在多样化任务和未见环境中展现出良好的泛化能力。
一句话总结
来自北京智源人工智能研究院的研究人员提出了 EgoActor,这是一种统一的视觉-语言模型,能够将自然语言指令转化为具有空间感知能力的以自我为中心的动作,适用于人形机器人——可同时预测移动、操作、感知和人机交互动作——从而在动态真实环境中实现无需额外传感器或遥操作的实时稳健执行。
主要贡献
- EgoActing 引入了一项新任务,要求人形机器人利用以自我为中心的视觉将自然语言指令转化为精确且空间定位的动作序列,以应对真实世界部署中的挑战,如部分可观测性和移动、操作与交互之间的动态转换。
- EgoActor 是一种在多样化的以自我为中心数据(包括真实世界演示和空间推理任务)上训练的视觉-语言模型,可统一预测移动原语、头部运动、操作指令和人机交互——在 4B 和 8B 模型上实现亚秒级实时推理。
- 在包括移动操作和可通行性任务的模拟与真实环境中评估,EgoActor 在未见过的设置和多样化任务类型中表现出强大的泛化能力,并已发布代码、模型和数据集以支持可复现性和未来研究。
引言
作者利用视觉-语言模型解决将自然语言指令转化为精确空间感知动作的挑战——这是迈向真实世界部署的关键一步。以往方法常将移动、操作和感知视为独立模块,限制了在动态、杂乱环境中的协调性和适应性。EgoActor 将这些能力整合到单一 VLM 中,直接从 RGB 观测和指令历史预测低级以自我为中心的动作——包括移动、头部朝向、操作和人机交互。该模型在多样化的现实世界和模拟数据上训练,支持实时亚秒级推理,并在未见过的任务和环境中实现泛化,无需额外传感器或遥操作即可弥合高层规划与底层运动执行之间的鸿沟。
数据集
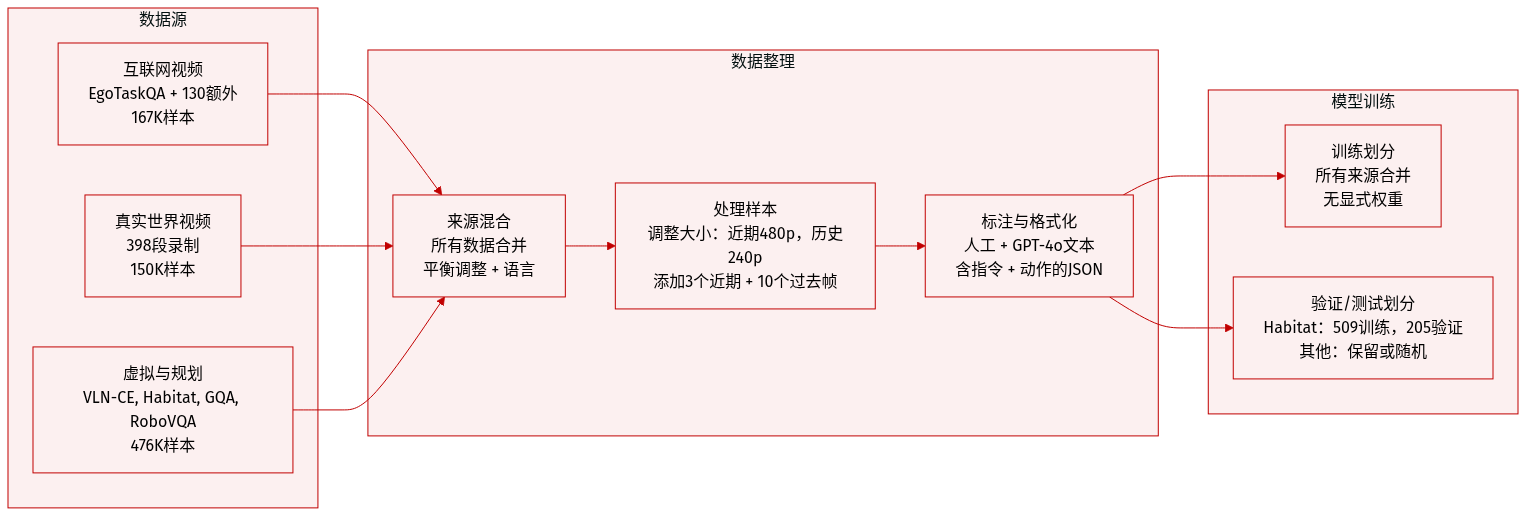
作者使用一个多模态数据集,由真实世界、虚拟环境和互联网来源的以自我为中心视频数据组成,结构化用于 EgoActing 框架下的以自我为中心动作预测。以下是数据集组成、处理和使用方式的分解:
-
数据集来源与组成:
- 互联网视频数据:EgoTaskQA(160,000 样本)+ 130 个额外的以自我为中心视频(7,111 样本)。
- 本地环境数据:398 个真实世界以自我为中心视频 → 150,214 样本。
- 虚拟导航:VLN-CE 的 3% → 60,000 样本。
- 虚拟 EgoActing:714 条人工标注的 Habitat-Sim 轨迹 → 76,821 样本(509 训练,205 验证)。
- 空间推理:MindCube 的 50% → 44,160 样本。
- 视觉-语言理解:300,000 条 GQA 样本 + 35,652 条 GPT-4o 标注的本地描述。
- 视觉-语言规划:RoboVQA、EgoPlan、ALFRED → 241,603 样本。
- 无监督移动:10,575 个图像对过渡样本。
- DAgger 经验:70 条真实世界轨迹 → 3,629 样本。
-
关键子集详情:
- EgoTaskQA:通过指令拼接(3 个相邻动作)、近期观测-动作三元组(后向步长 5 帧)和 10 个均匀采样的历史帧转换为 EgoActing 格式。导航动作通过姿态差值聚合(阈值 5°、0.1 米)。最终训练集:160,000 样本(40k 来自完整集,120k 来自 NL-action 子集)。
- 虚拟数据:轨迹解析为 RGB 图像 + 离散动作序列,合并为带随机扰动的连续指令,通过滑动窗口采样生成最近 3 个动作对 + 历史上下文。序列化为 JSON。
- 所有子集均经过增强以平衡转向和语言动作。
-
数据在模型训练中的使用:
- 训练划分:所有子集合并为一个训练混合体。
- 混合比例:未明确加权;所有来源共同构成多样化的多模态训练语料库。
- 处理:近期观测缩放至 480p;历史观测缩放至 240p 以节省计算资源。每个样本包含全局指令、3 个近期观测-动作对和 10 个历史帧。
- 标注:真实与虚拟数据手动标注;EgoTaskQA 指令源自动作拼接;自然语言动作附加到轨迹以定位行为。
-
额外处理细节:
- 裁剪/分辨率:无裁剪;为效率降低分辨率(近期 480p,历史 240p)。
- 元数据:每个样本包含指令、近期动作历史和历史视觉上下文。导航动作由姿态差值推导,经代数抵消和幅度阈值处理。
- 样本变体:针对操作任务,创建两个变体——一个预测下一个操作,另一个预测 Stop 以表示任务完成。
- 可扩展性:轻量级标注流程支持大规模收集;未来可随更多计算资源或更高分辨率摄像头扩展。
方法
作者利用统一的视觉-语言框架,使人形机器人能够通过将行为分解为两种互补的动作模态来执行复杂指令驱动任务:结构化语言动作(SLA)用于空间控制,自然语言动作(NLA)用于操作与交互。这种双重动作表示使系统能够在精确可执行的运动指令中实现高层意图,同时保留处理开放性、新颖指令的灵活性。
核心模型 EgoActor 基于以自我为中心的 RGB 观测和包含采样历史帧与近期观测-动作对的时间结构化提示运行。该设计鼓励模型推理长期上下文和短期动态,确保空间定位和时间连贯的决策。模型被训练为预测一系列 SLA 后接一个 NLA——或交替序列——以任务指令和视觉历史为条件。如下图所示,系统处理规划指令和视觉输入,生成一系列低级动作,最终完成任务。
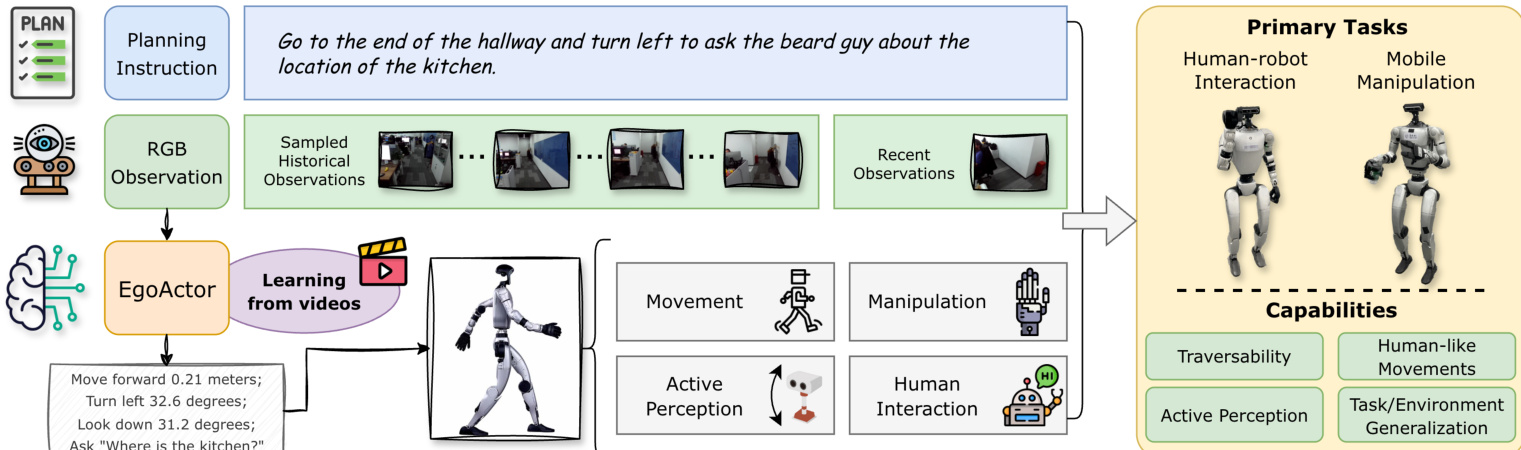
结构化语言动作被定义为简洁、可解释的模板,指定运动类型、方向和幅度——如“左转 30.5 度”或“前进 0.26 米”——涵盖偏航/俯仰旋转、线性平移和垂直调整。这些动作经过过滤以抑制微小移动,确保稳定和精确的定位。相比之下,自然语言动作是无约束的文本命令,如“拿起橙子”或“询问厨房在哪?”,支持对未见过任务的泛化和直接意图到动作的映射。模型被训练为仅在通过 SLA 完成足够的空间预定位后输出这些 NLA,确保操作或交互在正确上下文中发生。
在推理过程中,SLA 被解析为机器人的移动控制器的速度或角度指令,而 NLA 通过关键词触发路由:语音相关命令合成音频,预定义社交动作调用预设动作,操作命令转发至预训练的视觉-语言-动作(VLA)模型。作者使用 Qwen3-VL 作为基础视觉-语言模型,通过 LoRA 在混合数据集上微调,使用 16 块 A100 GPU 训练。4B 和 8B 两种变体均被训练以平衡推理速度和性能。
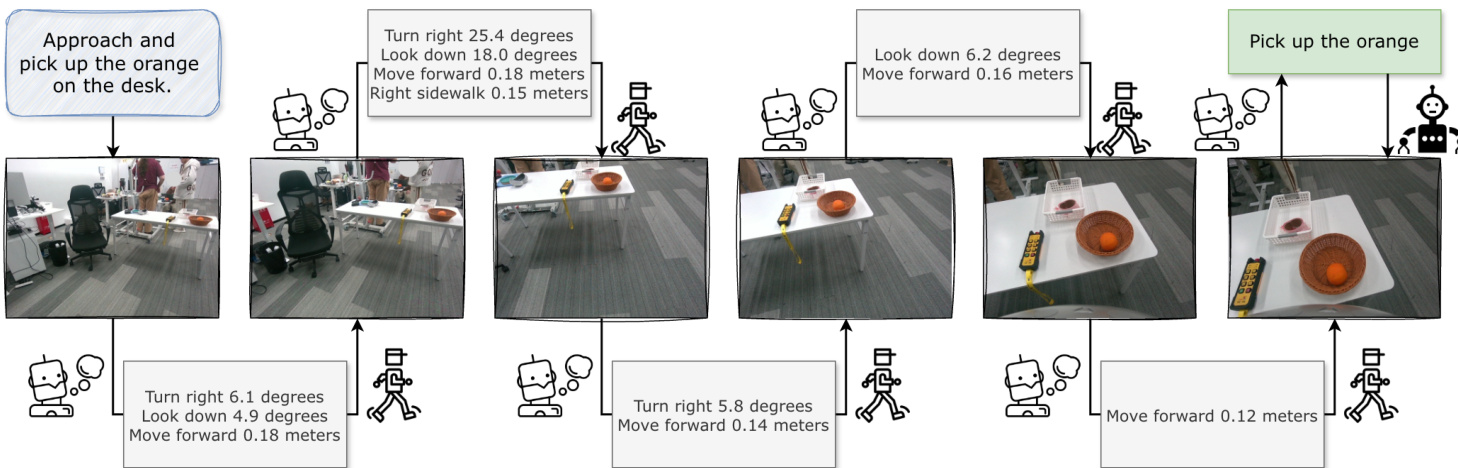
操作流程如以下图所示,可视化任务“接近并拿起桌上的橙子”的逐步执行。模型迭代生成 SLA 以导航至目标,根据视觉反馈调整朝向和位置,然后发出最终 NLA 执行操作。
对于下游技能,作者集成了微调的 GROOT-N 1.5 模型用于操作,以及 Unitree 步行策略用于移动,校准后实现约 5 厘米位置精度和约 5 度角度精度。前进运动放大 1.2 倍以提高速度,离散转向和前进步骤合并以产生更类人的轨迹。由于部署的移动策略限制,站立和蹲下行为目前仅限于模拟环境。
实验
- EgoActor 成功执行人机交互任务,包括接近和问候个体,8B 模型在需要精细视觉消歧的多人群场景中优于 4B 变体。
- 在移动操作中,EgoActor 能在未见过的布局中导航至目标物体并稳健执行拾取-放置动作,即使对分布外物体亦如此,但 4B 模型偶尔因过早触发操作而失败。
- EgoActor 在狭窄空间(如门口)表现出优越的可通行性,能可靠避免碰撞,而基线 VLM 导航模型常失败或表现出低效行为(如不必要的旋转)。
- 在虚拟环境中,EgoActor 对未见过的场景泛化良好,并在严格定位标准下保持性能,而基线模型常无法准确停止以进行交互。
- 定性案例研究证实 EgoActor 表现出类人行为,包括自适应转向、高度调整、主动感知(如上下看以解决视觉模糊)以及用于避障和场景协商的空间推理。
- 模型在真实人类视频上的训练促使其具备强大的空间理解和自然运动模式,能够在导航与交互或操作任务间实现平滑过渡。
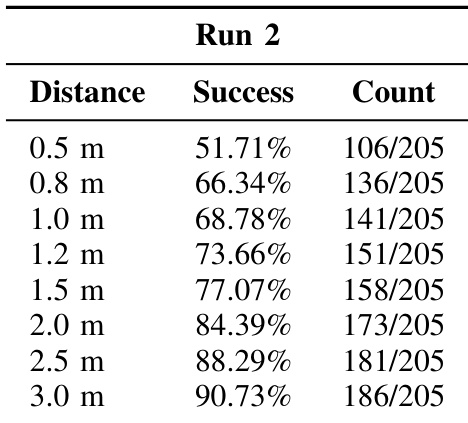
作者在未见过的虚拟环境中使用多个距离阈值评估 EgoActor 的导航精度,随着允许误差范围增大,成功率提升。结果显示模型在 2.5 米阈值下成功率超过 88%,在 3.0 米下接近 90%,表明其在随机推理下对新场景具有强泛化能力。在更严格阈值下性能下降,反映出在模糊或视觉退化条件下精细定位的挑战。
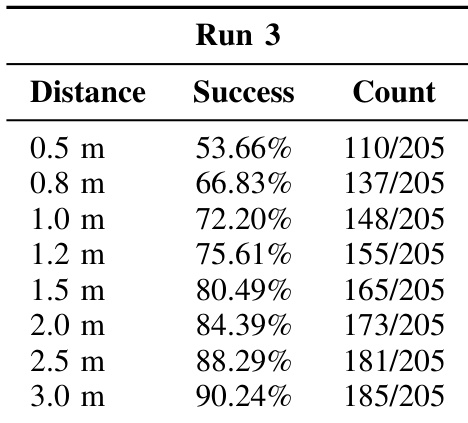
作者在未见过的虚拟环境中使用多个距离阈值评估 EgoActor 的导航精度,随着允许误差范围增大,成功率提升。结果显示模型在 3.0 米阈值下成功率超过 90%,但在更严格的 0.5 米阈值下降至略高于 50%,表明其对精细定位敏感。性能趋势表明模型对新场景泛化合理,但在高精度停止要求下表现困难。
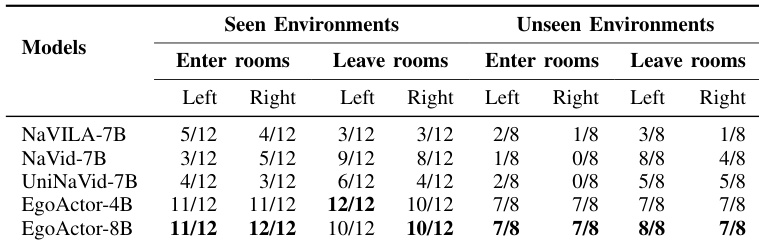
作者在涉及房间进出的可通行性任务中评估 EgoActor 和若干视觉-语言导航基线模型,涵盖已见和未见环境。结果表明,EgoActor(尤其是 8B 变体)在避免碰撞和成功导航狭窄门口方面始终优于基线模型,尤其在未见环境中。NaVILA 和 NaVid 等基线模型成功率较低,常无法处理空间约束或执行高效轨迹。
作者基于视觉属性(如衣着、配饰、姿势、方向和性别)评估 EgoActor 在多人群场景中区分个体的能力。结果表明,8B 模型在所有属性上始终优于 4B 变体,尤其在通过方向和配饰识别目标方面,表明更大规模模型具备更强的视觉推理和人物区分能力。

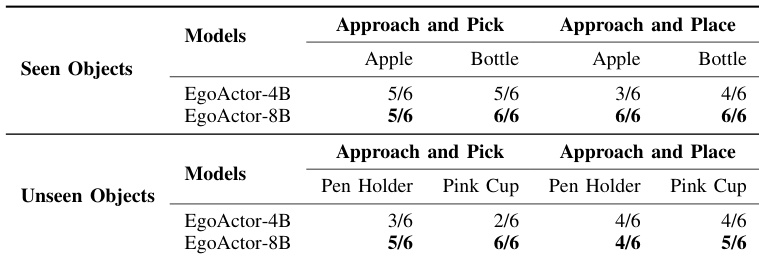
作者在涉及已见和未见物体的移动操作任务中评估 EgoActor 模型,使用在未见过环境布局中的人形机器人。结果表明,8B 模型始终优于 4B 变体,尤其在处理新颖物体类别和执行精确拾取-放置动作方面。两种模型均表现出合理泛化能力,但 8B 版本在所有物体类型和任务变体中实现更高成功率。