Command Palette
Search for a command to run...
A-RAG:通过分层检索接口实现智能体增强型检索生成的扩展
A-RAG:通过分层检索接口实现智能体增强型检索生成的扩展
Mingxuan Du Benfeng Xu Chiwei Zhu Shaohan Wang Pengyu Wang Xiaorui Wang Zhendong Mao
摘要
前沿语言模型已展现出强大的推理能力与长时程工具使用能力。然而,现有的检索增强生成(RAG)系统尚未有效利用这些能力。当前主流方法仍依赖于两种范式:(1)设计一种算法,一次性检索相关段落并将其拼接至模型输入;(2)预先定义工作流程,并通过提示(prompting)引导模型分步执行。这两种范式均无法让模型参与检索决策过程,因而难以随着模型能力的提升实现高效扩展。本文提出A-RAG——一种代理式检索增强生成框架,该框架将分层检索接口直接暴露给模型。A-RAG提供三种检索工具:关键词搜索、语义搜索与段落读取,使智能体能够根据任务需求,在多粒度层级上自适应地进行信息搜索与检索。在多个开放域问答基准上的实验结果表明,A-RAG在保持或降低检索词元数量的前提下,持续优于现有方法,充分证明其能够有效利用模型能力,并动态适配不同RAG任务。此外,我们系统性地研究了A-RAG在模型规模与推理时计算资源增加情况下的扩展性能。为促进后续研究,我们已公开代码与评估套件,相关资源详见:https://github.com/Ayanami0730/arag。
一句话总结
中国科学技术大学与Metastone Technology的研究人员提出了A-RAG,这是一种具备分层检索工具(keyword_search、semantic_search、chunk_read)的代理式RAG框架,使大语言模型(LLM)能够自主适应不同粒度的检索策略,在多跳问答基准测试中超越先前方法,同时使用更少的token,并随模型规模和测试时计算量高效扩展。
主要贡献
- A-RAG通过使LLM能够通过分层工具(keyword_search、semantic_search和chunk_read)动态控制检索,解决了静态RAG系统的局限性,允许模型根据推理过程自适应地进行多粒度信息收集。
- 在开放域问答基准测试中评估,A-RAG始终优于先前方法,同时使用相当或更少的检索token,验证了代理驱动的检索比预定义工作流或单次检索更有效地利用模型能力。
- 系统性扩展实验表明,A-RAG的性能随更大模型和增加的测试时计算量而提升,证明其在随LLM能力和计算资源进步时具有高效扩展性。
引言
作者利用前沿LLM日益增强的推理与工具使用能力,重新思考检索增强生成(RAG),该领域过去依赖静态算法驱动的检索或僵化的预定义工作流,限制了模型自主性。先前方法(包括Graph RAG和Workflow RAG)无法让模型根据上下文或任务复杂性动态调整检索策略,阻碍了随模型改进而有效扩展。作者的主要贡献是A-RAG——一种代理式框架,直接向模型暴露分层检索工具(keyword_search、semantic_search、chunk_read),使其能够自主在多个粒度上导航信息。实验表明,A-RAG以更少的检索token优于现有方法,并随模型规模和测试时计算量有效扩展,证明代理驱动的检索接口比固定检索算法更强大。
数据集

- 作者仅使用先前研究整理并处理过的公开可用基准数据集,确保符合伦理规范。
- 本研究未收集新数据,未涉及人类受试者。
- 研究重点是推进大语言模型中的检索增强生成(RAG),除基础模型本身已存在的风险外,未引入新增伦理风险。
- 数据集构成与处理遵循先前研究的既定实践,未引入新的过滤、裁剪或元数据构建步骤。
方法
作者采用一种极简但强大的以代理为中心的架构——A-RAG,通过暴露分层检索接口实现自主、迭代的信息收集。该框架围绕三个核心组件构建:轻量级分层索引、一套粒度化检索工具,以及一个简单的ReAct风格代理循环,以促进动态策略选择和工具交错使用。
分层索引分两阶段构建:分块与嵌入。语料库被划分为约1000个token的块,对齐句子边界以保持语义连贯性。每个块再分解为组成句子,每个句子通过预训练编码器 femb 嵌入,得到向量表示 vi,j=femb(si,j)。这种句子级嵌入支持细粒度语义匹配,同时保留与父块的映射。关键的是,关键词级检索在查询时通过精确文本匹配处理,避免昂贵的离线索引。由此形成三层表示:隐式的关键词级用于精确实体匹配,句子级用于语义搜索,块级用于完整内容访问。
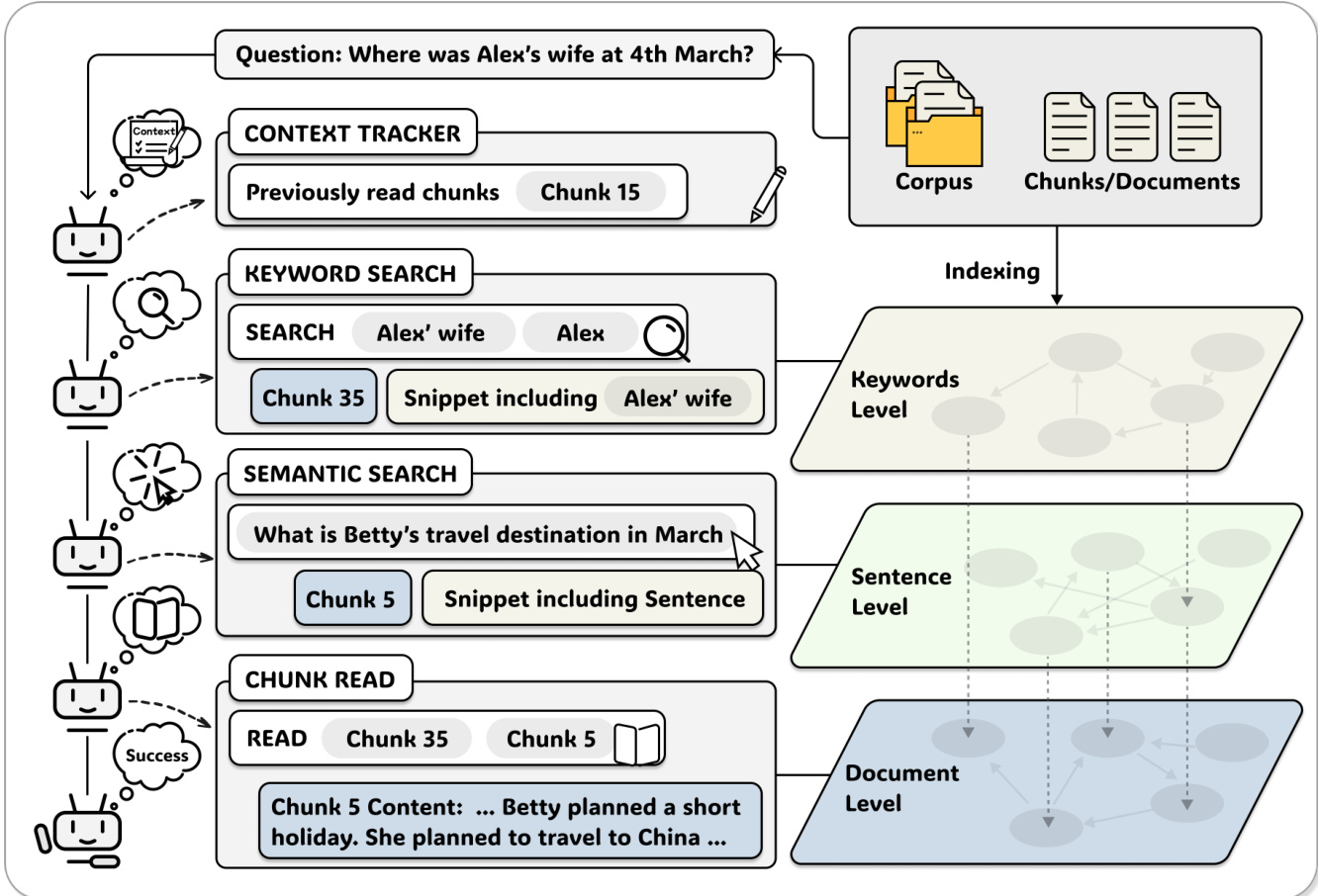
为与该索引交互,作者设计了三个在不同粒度上运行的检索工具。关键词搜索工具接受关键词列表 K={k1,k2,…,km},并返回按加权频率得分排序的前k个块:
Scorekw(ci,K)=k∈K∑count(k,Ti)⋅∣k∣其中较长关键词因特异性更高而赋予更高权重。对于每个匹配块,返回仅包含至少一个关键词的句子的摘要片段:
Snippet(ci,K)={s∈Sent(ci)∣∃k∈K,k⊆s}语义搜索工具将自然语言查询 q 编码为向量 vq=femb(q),并计算与所有句子嵌入的余弦相似度:
Scoresem(si,j,q)=∥vi,j∥∥vq∥vi,jTvq按父块聚合结果,返回前k个块及其得分最高的句子作为摘要。最后,块读取工具允许代理访问通过先前搜索识别的任何块的完整文本,包括相邻块以扩展上下文。
代理循环有意保持简单,以隔离接口设计的影响。它遵循ReAct类似模式:每次迭代,LLM接收消息历史和可用工具,然后决定调用工具或生成最终答案。上下文跟踪器维护一个已访问块集合 Cread;如果代理尝试重新读取块,工具返回零token通知以防止冗余并鼓励探索。当生成答案或达到最大迭代预算时循环终止,此时代理被提示从累积证据中合成响应。
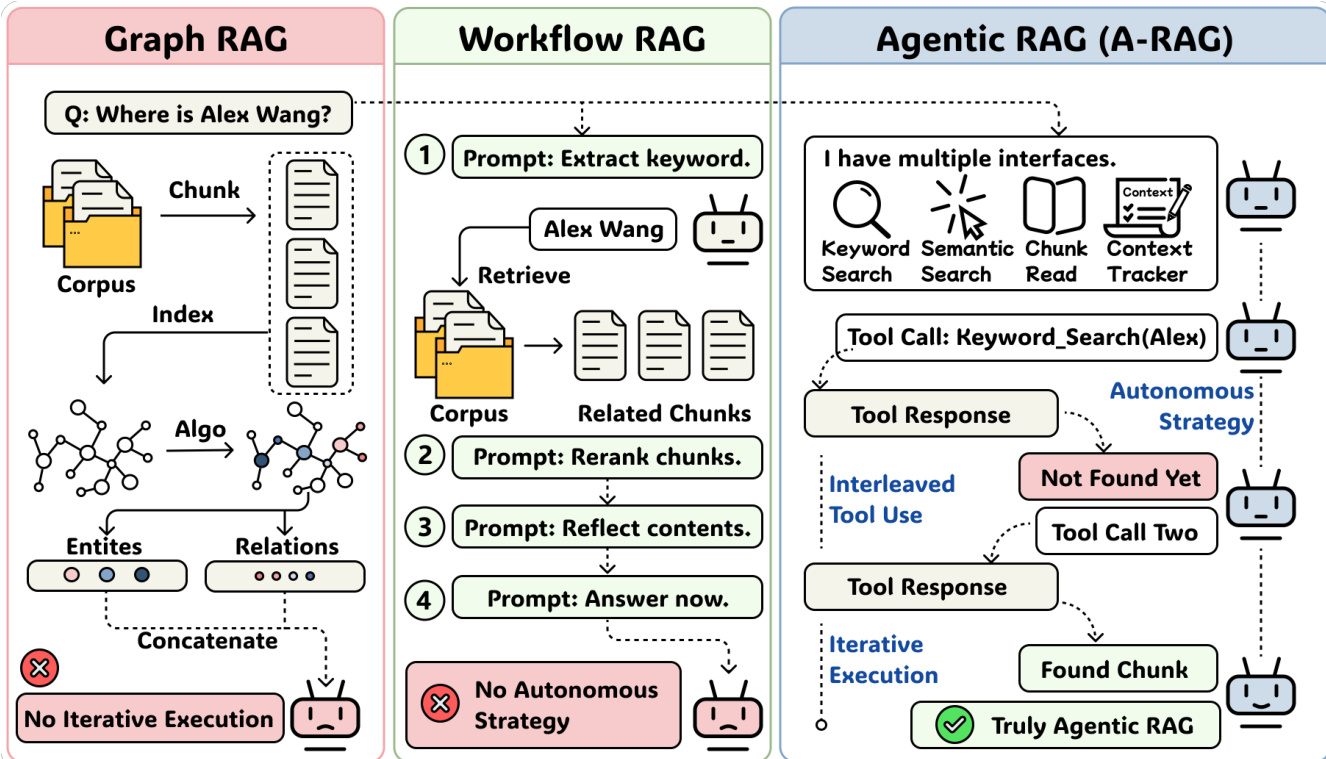
该架构支持真正的代理行为:代理自主选择检索策略,根据中间结果迭代,并根据先前观察调整每次工具调用。与固定工作流或基于图的系统不同,A-RAG不规定严格的操作序列,而是提供灵活接口,允许代理动态分解问题、验证发现并按需重新规划——同时通过按需、增量检索最小化上下文开销。
实验
- A-RAG被验证为唯一满足真正代理自主性三大原则的RAG范式,区别于Graph RAG和Workflow RAG。
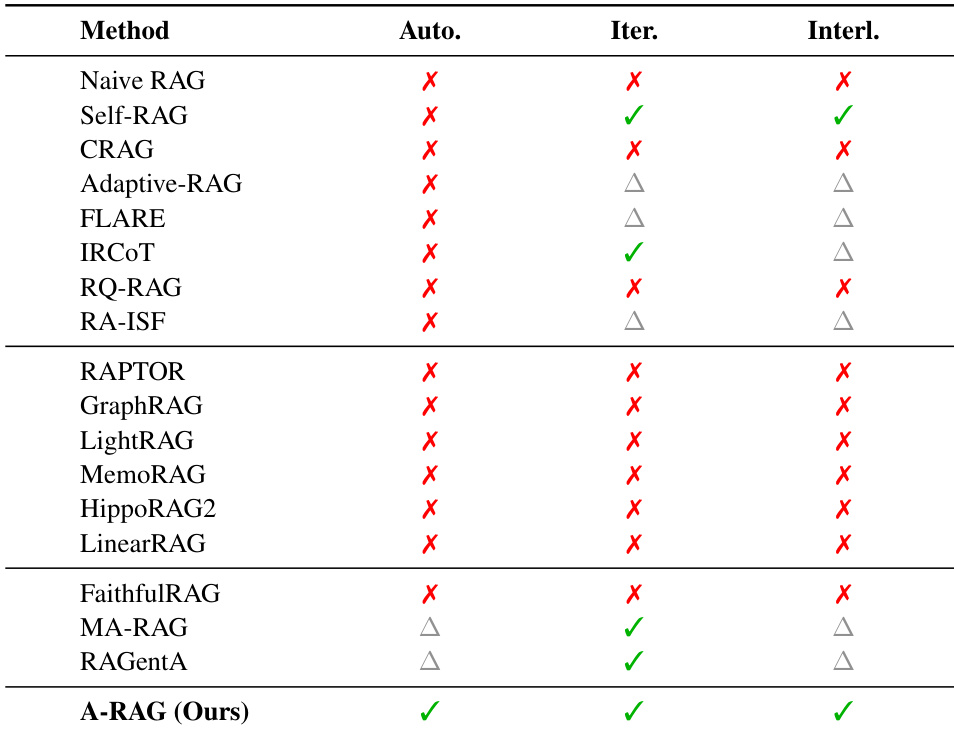
- 在四个多跳问答基准测试中,A-RAG(Full)始终优于朴素、基于图和基于工作流的RAG方法,尤其与更强的LLM(如GPT-5-mini)结合时表现更佳。
- 消融研究证实,A-RAG的分层检索工具(语义搜索、关键词搜索、块读取)相互依赖;移除任一工具都会导致性能下降,凸显多粒度和渐进式信息访问的价值。
- 测试时扩展实验表明,A-RAG能有效利用增加的计算预算(步骤和推理努力),更强的模型受益更多,使其成为可扩展范式。
- A-RAG在检索更少token的情况下实现更高准确率,证明其分层接口设计带来卓越的上下文效率。
- 失败分析揭示范式转变:朴素RAG主要因检索限制失败,而A-RAG的主要瓶颈是推理链错误——尤其是实体混淆——表明未来工作应聚焦提升推理保真度而非检索覆盖。
作者评估了A-RAG的消融变体,发现移除任何检索工具(关键词搜索、语义搜索或块读取)均持续降低性能,证实多粒度访问和渐进式信息披露对有效多跳推理至关重要。A-RAG(Full)在大多数指标上取得最高分,表明分层工具接口使模型能自主选择和精炼相关上下文,同时避免无关内容的噪声。

作者使用A-RAG评估不同方法的上下文效率,以GPT-5-mini为骨干模型测量检索token数。结果表明,A-RAG(Full)在检索更少或相当token的情况下实现更高准确率,表明其上下文利用率更优。分层接口设计支持更选择性和高效的检索,减少无关内容的噪声。
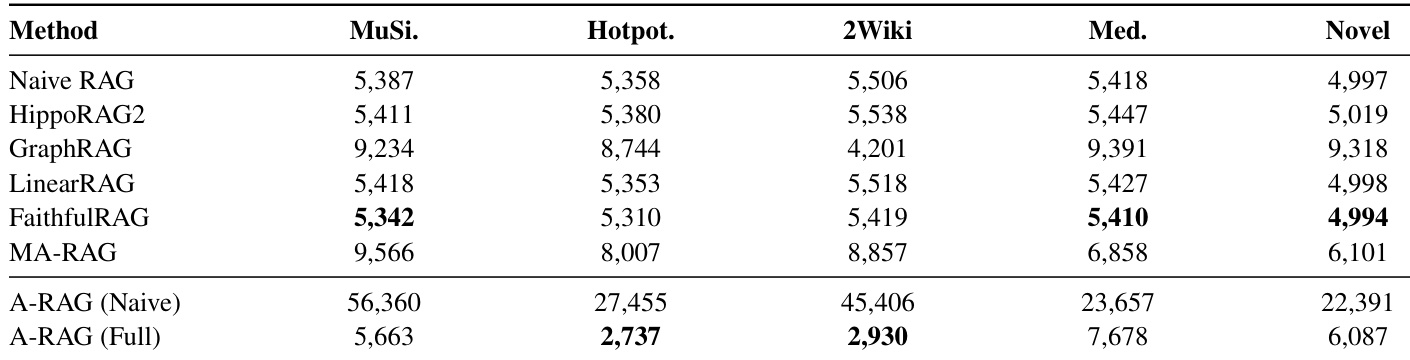
作者使用统一评估框架,在四个多跳问答基准测试中比较A-RAG与多种RAG范式,发现A-RAG始终优于朴素和结构化RAG方法,尤其与更强推理模型(如GPT-5-mini)结合时表现更佳。结果表明,赋予模型自主动态选择检索工具的能力优于固定检索流水线,即使工具极简。完整A-RAG配置通过支持渐进式、多粒度信息访问进一步提升结果,证明分层接口同时提升准确率和上下文效率。
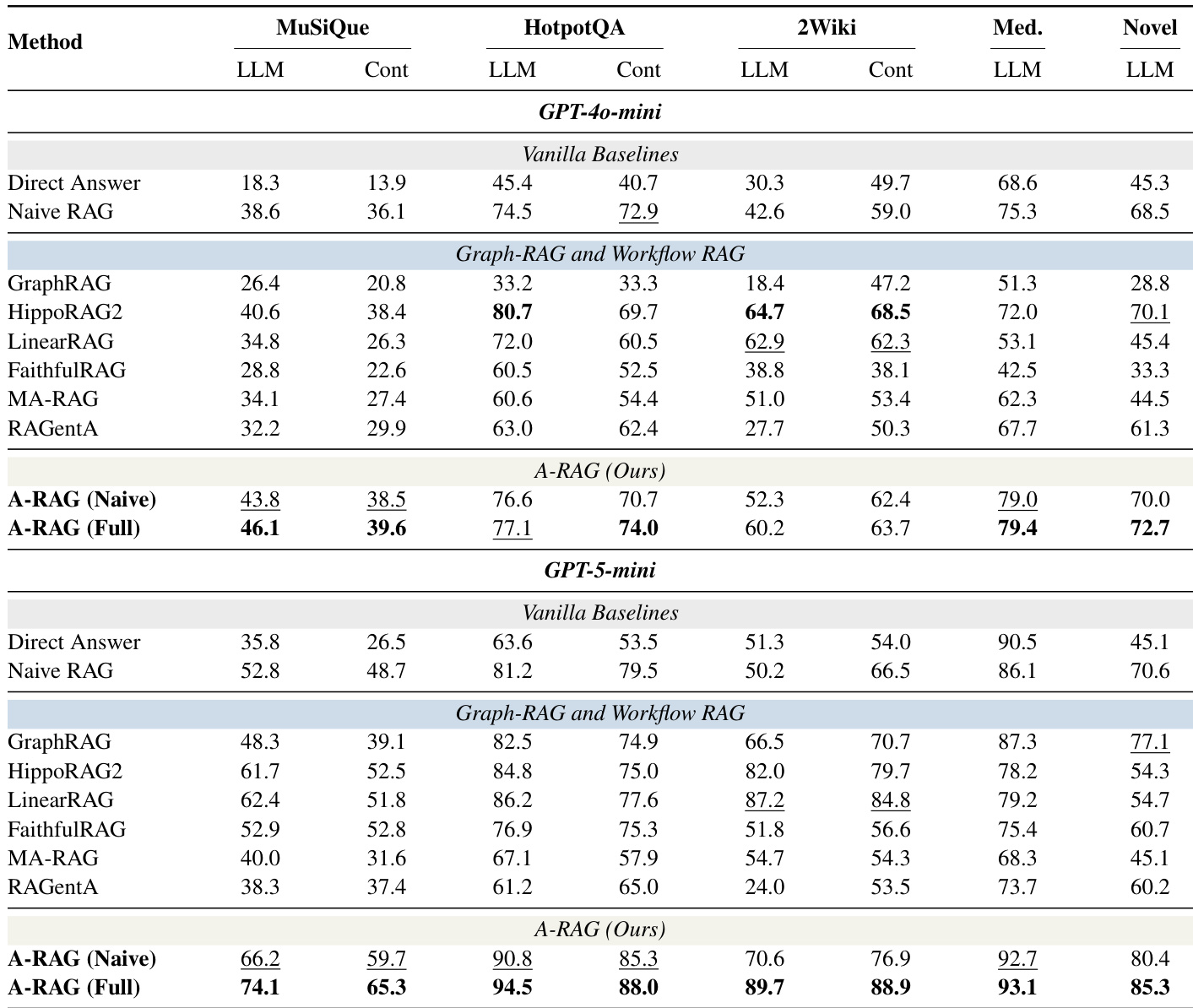
作者使用对比表将所提A-RAG方法与现有RAG方法定位,突出其对自主性、迭代推理和交错工具使用的独特支持。结果表明,A-RAG是唯一满足真正代理自主性三大原则的方法,区别于缺乏一个或多个能力的先前范式。这种结构优势使A-RAG能动态调整检索策略,促使其在基准测试中表现卓越。
作者分析A-RAG的失败模式,发现推理链错误占主导,其中实体混淆是最频繁的子类别——在MuSiQue中占40%,在2WikiMultiHopQA中占71%。这表明,尽管A-RAG成功检索相关文档,模型常难以正确解释或消歧其中的实体。错误分布也因数据集而异,暗示在问题理解和策略选择方面存在任务特定挑战。