Command Palette
Search for a command to run...
HunyuanVideo-Foley:基于表示对齐的多模态扩散模型用于高保真Foley音频生成
HunyuanVideo-Foley:基于表示对齐的多模态扩散模型用于高保真Foley音频生成
Sizhe Shan Qiulin Li Yutao Cui Miles Yang Yuehai Wang Qun Yang Jin Zhou Zhao Zhong
摘要
近期视频生成技术取得了显著进展,能够生成视觉上高度逼真的内容,但缺乏同步音频严重削弱了沉浸感。针对视频到音频生成中的关键挑战——多模态数据稀缺、模态不平衡以及现有方法音频质量有限等问题,我们提出 HunyuanVideo-Foley,一种端到端的文本-视频到音频生成框架,可精准生成与视觉动态及语义上下文高度对齐的高保真音频。本方法包含三项核心创新:(1)构建可扩展的数据处理管道,通过自动化标注构建包含10万小时的多模态数据集;(2)采用自监督音频特征引导的表示对齐策略,有效提升音频质量与生成稳定性,显著优化潜空间扩散模型的训练效果;(3)提出一种新型多模态扩散Transformer架构,缓解模态间竞争问题,通过双流音视频融合机制实现联合注意力建模,并利用交叉注意力实现文本语义的精准注入。全面的实验评估表明,HunyuanVideo-Foley 在音频保真度、视觉-语义对齐、时间对齐以及分布匹配等多个指标上均达到当前最优水平。演示页面详见:https://szczesnys.github.io/hunyuanvideo-foley/
一句话总结
腾讯混元、浙江大学与南京航空航天大学的研究人员提出了 HunyuanVideo-Foley,这是一种端到端的文本-视频-音频框架,通过多模态扩散变换器和自监督对齐生成高保真、时序对齐的音频,克服数据稀缺性和模态不平衡问题,从而提升视频沉浸体验。
主要贡献
- 我们引入了一个可扩展的数据管道,自动构建一个 10 万小时的文本-视频-音频数据集,解决多模态数据稀缺问题,支持稳健的视频到音频合成训练。
- 我们的表示对齐(REPA)损失利用自监督音频特征引导潜在扩散训练,无需人工标注即可提升音频保真度和生成稳定性。
- HunyuanVideo-Foley 采用一种新颖的多模态扩散变换器,结合双流融合与交叉注意力注入,解决模态不平衡问题,在音频、视觉和文本语义方面实现最先进的对齐与质量。
引言
作者利用视频生成的最新进展,解决合成媒体中同步音频缺失的关键问题,该问题限制了沉浸感。先前的文本到音频和视频到音频生成工作受限于多模态数据不足、文本模态优于视觉线索的模态不平衡,以及无法达到专业标准的音频保真度。HunyuanVideo-Foley 引入三项关键创新:可扩展的 10 万小时多模态数据集管道、利用自监督音频特征提升质量和稳定性的表示对齐损失,以及通过双流融合与交叉注意力平衡视频-文本-音频交互的新型多模态扩散变换器。结果在音频保真度、时序精度和视觉及文本输入语义对齐方面达到最先进水平。
数据集

作者使用自建的 TV2A 数据集支持多模态音频生成,解决高质量、大规模开源文本-视频-音频任务数据缺乏的问题。关键细节如下:
-
数据集构成与来源:
通过多阶段过滤管道从原始视频数据库构建。最终数据集包含约 10 万小时的文本-视频-音频材料。 -
子集详情与过滤规则:
- 移除无音频流的视频。
- 使用场景检测将剩余视频分割为 8 秒片段。
- 丢弃静音超过 80% 的片段。
- 仅保留采样率高于 32 kHz 的音频以确保保真度。
- 使用 AudioBox-aesthetic-toolkit 和 SNR 指标评估音频质量;过滤低质量或含噪片段。
- 使用 ImageBind 和 AV-align 验证语义和时序音频-视频对齐。
- 为平衡训练,为片段标注语音/音乐标签和音频类别。
- 使用 GenAU 为每个片段生成音频描述性字幕。
-
模型训练中的使用:
经过滤、标注和字幕化的片段用作训练数据。未提及具体混合比例,但通过标注强制类别平衡。 -
处理与元数据:
通过 8 秒固定长度片段进行裁剪。元数据包括音频类别标签、对齐分数、质量指标和生成字幕——支持结构化训练和评估。
方法
作者采用混合变换器架构——HunyuanVideo-Foley——实现模态平衡、时序一致的文本-视频-音频(TV2A)生成。该框架分为两个独立阶段:初始多模态阶段包含 N1 个变换器块,联合处理视觉、文本和音频潜在表示;随后是 N2 个单模态变换器块,专门用于精炼音频流。此设计使模型先建立跨模态对齐,再专注于高保真音频合成。
如下图所示,输入模态独立编码:文本通过 CLAP 编码器处理,视频帧通过 SigLIP-2 视觉编码器处理,原始音频通过 DAC-VAE 编码器压缩为连续潜在表示。这些潜在表示被添加高斯噪声以支持流匹配扩散目标。从 Synchformer 视觉编码器提取的同步特征提供帧级时序对齐信号,动态调制变换器块。
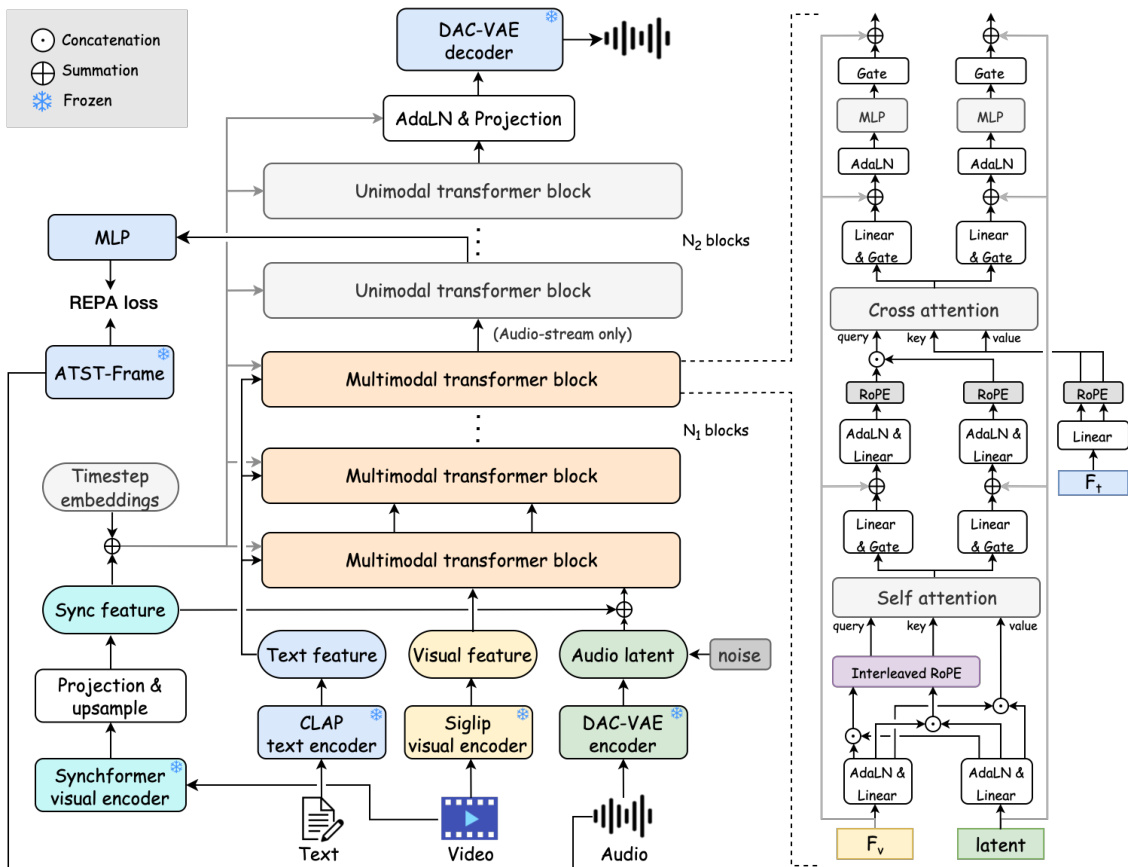
关键创新在于多模态块内的双阶段注意力机制。在自注意力中,音频和视觉潜在表示通过交错 RoPE 策略按时间交错后连接为统一序列,确保相邻音频和视觉标记获得连续的位置嵌入,从而增强模型捕捉细粒度时序相关性的能力。融合序列随后被拆分为并行流,每条流经线性投影并通过自适应层归一化(adaLN)层调制,该层以同步特征和时间步嵌入为条件。在交叉注意力中,连接的音频-视觉序列为查询,CLAP 衍生的文本嵌入提供键和值,实现全局语义引导而不破坏时序结构。
条件信号 c 由同步特征 csync 和时间步嵌入 ct 相加得出。该复合信号通过并行 MLP 生成调制参数 α、β 和门控 g,用于归一化和门控中间特征。调制输出通过残差连接集成,确保时序一致性在各层稳定传播。
为进一步提升音频保真度,作者引入 REPA 损失,将扩散变换器的中间隐藏状态与预训练 ATST-Frame 编码器提取的帧级音频表示对齐。对齐通过映射潜在 H=MLP(h) 与参考特征 Fr 之间的余弦相似度计算,鼓励模型在生成过程中保留语义和声学结构。该损失在多层计算并反向传播,以在通过 DAC-VAE 解码器解码前精炼音频流。
训练管道由可扩展的数据整理系统支持,该系统根据音频-视觉对齐(通过 ImageBind 和 AV-align)和音频质量(通过 AudioBox-aesthetic 和 SNR 指标)过滤视频-音频对。使用带宽标记使模型以采样率作为条件,在 16 kHz 以上音频的字幕中附加“高质量”标签,以提高生成输出中的高频保留。模型在 100k 小时数据上使用 128 个 H20 GPU 训练,包含 18 个多模态和 36 个单模态变换器层,每层隐藏维度为 1536,注意力头数为 12。每模态应用 0.1 丢弃率的无分类器引导以增强可控性。
实验
- HunyuanVideo-Foley 在文本-视频-音频生成方面创下新纪录,在 Kling-Audio-Eval、VGGSound-Test 和 MovieGen-Audio-Bench 上均在视觉语义对齐、音频质量和时序同步方面表现出色。
- 在大多数客观和主观指标上优于基线,尤其在 IB、PQ 和 DeSync 方面,尽管在某些数据集上的 IS 和 CE 上略有权衡,但仍保持有竞争力的 CLAP 分数。
- 在 VGGSound-Test 上,由于领域不匹配,分布匹配略有落后,但在音频质量和 IB 性能上领先。
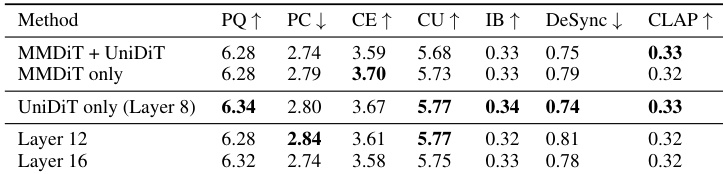
- 消融研究证实其多模态变换器设计的优越性,特别是联合注意力后接交叉注意力,并验证了交错 RoPE 和单模态 DiT 的有效性。
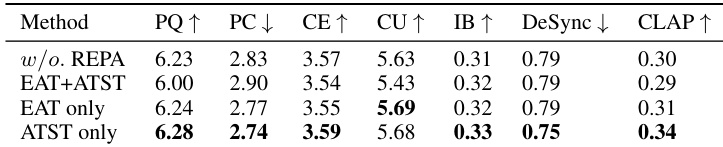
- 与 ATST 的表示对齐效果最佳;结合 ATST 和 EAT 由于特征分布冲突而性能下降。
- 在单模态 DiT 中应用 REPA,尤其在较浅层,可提升对齐效果。
- DAC-VAE 在多种领域(语音、音乐、通用声音)中展现出强大的音频重建能力,在所有评估指标上优于先前方法。
- 频谱图可视化证实了在动态场景下精确的时序对齐和高频内容保留。
作者评估了其多模态变换器架构的不同配置,发现第 8 层使用单模态 DiT 时整体性能最佳,尤其在制作质量和内容实用性方面。虽然其他层深度保持有竞争力的分数,但在时序对齐和音频质量方面存在权衡。结果表明,架构选择显著影响音频生成的特定方面,第 8 层提供最平衡的结果。
作者使用 HunyuanVideo-Foley 从文本和视频输入生成音频,在包括音频质量、视觉语义对齐和时序同步在内的多个评估指标上表现强劲。虽然在某些文本语义对齐和分布匹配分数上略逊于 MMAudio,但在分布匹配和视觉对齐等关键领域显著提升。结果表明,在多个数据集上持续优于基线,确立了文本-视频-音频生成的新最先进性能。

作者使用 EAT 和 ATST 模型评估不同的表示对齐策略,发现仅使用 ATST 在音频质量、时序对齐和文本语义一致性方面整体表现最佳。结合 EAT 和 ATST 会降低结果,可能由于特征分布冲突。最佳配置是在单模态 DiT 层(尤其在较浅块)中使用 ATST,以增强对齐而不引入噪声或错位。
作者使用 HunyuanVideo-Foley 从文本和视频输入生成音频,在多个数据集上达到最先进性能。结果表明,在视觉语义对齐、音频质量和时序同步方面相比基线持续改进,尤其在 Kling-Audio-Eval 数据集的分布匹配方面有显著提升。虽然在某些文本语义指标上略有落后,但模型在多种音频领域表现出稳健的整体性能和卓越的重建能力。

作者在客观和主观指标上将 HunyuanVideo-Foley 与多个基线进行比较,显示在音频制作质量、视觉语义对齐和时序同步方面持续改进。虽然某些基线在 CLAP 或内容享受等特定指标上得分更高,但 HunyuanVideo-Foley 在音频自然度、场景匹配和时序准确性方面获得最佳整体主观评分。结果确认其在多个评估维度上的文本-视频-音频生成最先进性能。
