Command Palette
Search for a command to run...
Fun-ASR 技术报告
Fun-ASR 技术报告
摘要
近年来,自动语音识别(ASR)技术在三大互补范式——数据规模扩展、模型规模扩展以及与大语言模型(LLMs)的深度集成——的推动下取得了颠覆性进展。然而,大语言模型容易产生幻觉(hallucination),这在真实场景的ASR应用中可能显著降低用户体验。本文提出Fun-ASR,一个基于大语言模型的大规模ASR系统,通过协同融合海量数据、大模型容量、LLM集成与强化学习,实现了在多样化且复杂的语音识别场景下的最先进性能。此外,Fun-ASR特别针对实际部署进行了优化,显著提升了流式处理能力、噪声鲁棒性、代码切换(code-switching)支持、热词自定义等功能,充分满足各类真实应用场景的需求。实验结果表明,尽管多数基于LLM的ASR系统在开源基准测试中表现优异,但在真实产业评估数据集上往往表现不佳。得益于面向生产环境的优化设计,Fun-ASR在真实应用数据集上取得了当前最优性能,充分证明了其在实际场景中的有效性与鲁棒性。代码与模型已开源,可访问 https://github.com/FunAudioLLM/Fun-ASR。
一句话总结
阿里巴巴集团通义Fun团队提出Fun-ASR,这是一种基于大语言模型(LLM)的语音识别系统,结合海量数据、大模型与强化学习,有效抑制幻觉问题,显著提升在流式、噪声和中英混说等真实场景下的性能,在行业基准测试中超越先前系统。
主要贡献
- Fun-ASR通过融合海量数据、大规模模型容量和强化学习,有效应对LLM在语音识别中的幻觉风险,提供在复杂真实语音场景下鲁棒且准确的转录结果。
- 系统引入面向生产的优化功能,包括流式支持、抗噪能力、中英代码切换及可定制热词识别,专为工业部署需求设计。
- 在真实行业数据集(而非仅开源基准)上评估,Fun-ASR实现当前最优性能,证明其在多数LLM语音识别系统表现不佳的实际应用场景中的优越性。
引言
作者利用海量数据、大模型容量与深度LLM集成,构建Fun-ASR——一款面向生产的自动语音识别系统,弥合学术基准与真实世界性能之间的差距。尽管先前基于LLM的ASR模型常存在幻觉问题且在行业数据集上表现不佳,Fun-ASR结合强化学习与实用优化(包括流式支持、抗噪、代码切换和热词定制),在复杂真实场景中实现当前最优准确率。其主要贡献是一个可部署系统,不仅达成顶级识别指标,同时满足工业对延迟、可靠性与领域适应性的严苛要求。
数据集
-
作者使用覆盖数千万小时的庞大预训练数据集,结合无标签真实音频(来自AI、电商、教育、出行等领域)与标注音频-文本对。标注数据经过语音活动检测、多ASR系统(Paraformer-V2、Whisper、SenseVoice)伪标注及逆文本归一化处理。主要语言为中文与英文。
-
用于监督微调(SFT),他们整合了数百万小时的人工转录、伪标注、环境噪声、TTS合成(CosyVoice3)、模拟流式、噪声增强及热词定制数据。
-
为增强上下文建模能力,他们在SFT中引入长音频(最长5分钟)。长样本被分段,前文转录作为提示前置。他们使用Qwen3-32B合成超5万小时上下文数据:提取关键词、生成相关上下文,并混合无关内容以防过度依赖。
-
强化学习训练数据(10万样本)从五个子集精选:困难样本(Fun-ASR与其他ASR分歧)、长时音频(>20秒)、幻觉相关样本、关键词/热词语句及常规ASR数据以防遗忘。每个子集含2万样本。
-
为提升流式性能,他们将离线数据转换为模拟实时解码的增量分块输入,与现有离线数据混合以减少训练-推理不匹配。
-
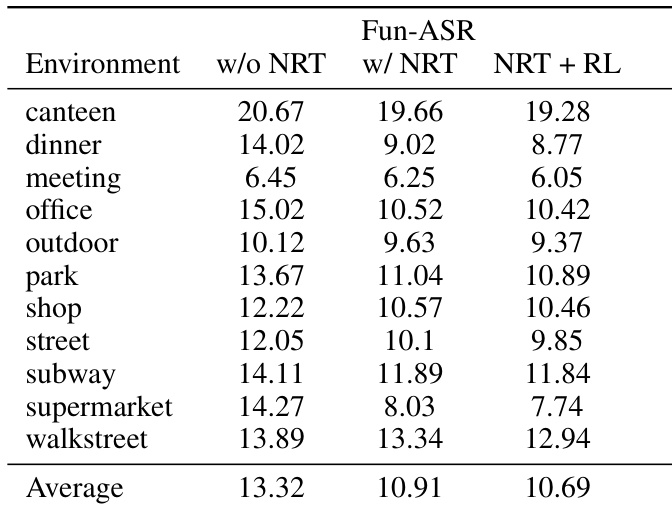
通过大规模数据增强解决抗噪问题:11万小时干净语音混合1万小时噪声(平均信噪比10 dB,标准差5 dB)。30%语音在训练中进行在线噪声混合,使复杂噪声基准测试相对提升约13%。
-
多语言支持(Fun-ASR-ML)覆盖31种语言,训练数据约50万小时。数据重新平衡:中文/英文下采样,其他语言上采样。训练方法与中英模型一致。
-
代码切换数据通过合成生成:使用4万+英文短语提示Qwen3生成中英混说文本,再通过TTS转换为语音用于训练。
-
评估使用开源基准(AIShell-1/2、Librispeech、Fleurs、WeNetSpeech、Gigaspeech2)及无数据泄露的自定义测试集(来自6月30日后YouTube/Bilibili视频)。噪声鲁棒性测试使用11种真实环境音频(食堂、街道、地铁等),按声学与主题分类。
方法
作者采用模块化、多阶段架构设计Fun-ASR,旨在整合语音表征学习与大语言模型(LLM)解码,同时支持高效推理与定制。如图所示,整体框架包含四个核心组件:音频编码器、音频适配器、CTC解码器和基于LLM的解码器。
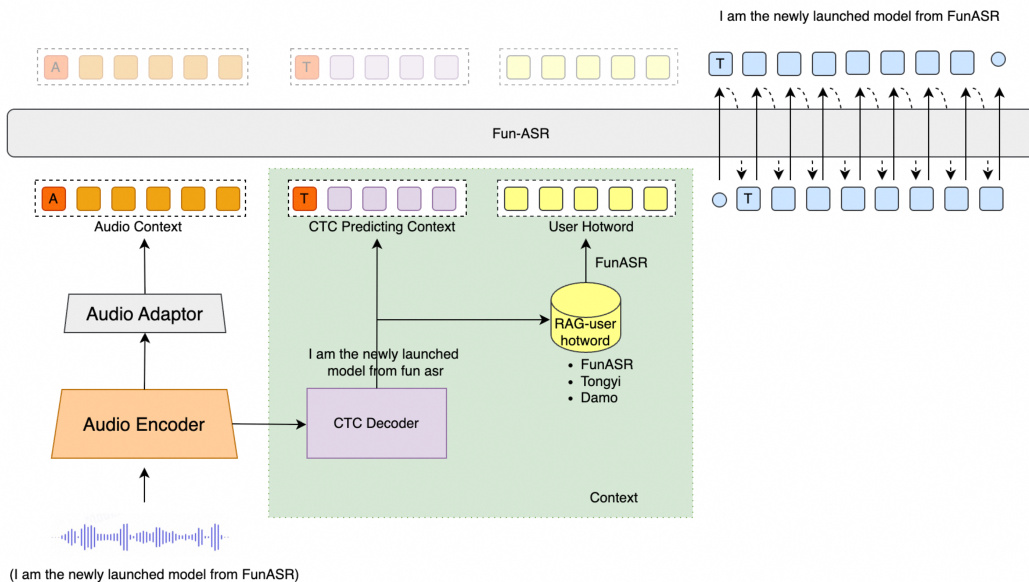
音频编码器采用多层Transformer实现,处理原始语音输入以提取高层声学表征。这些表征随后通过两层Transformer构成的音频适配器,对齐至LLM的语义空间。CTC解码器基于音频编码器,通过贪心搜索生成初始识别假设。该假设具有双重用途:为LLM解码器提供起点,并支持基于检索增强生成(RAG)的热词定制。基于LLM的解码器以音频上下文与CTC预测为条件,输出最终转录。提出两种模型变体:Fun-ASR(0.7B音频编码器 + 7B LLM)用于高精度场景,Fun-ASR-nano(0.2B + 0.6B)用于资源受限环境。
为确保音频编码器鲁棒且与LLM语义对齐,作者采用两阶段预训练流程。如图所示,第一阶段使用Best-RQ框架进行自监督学习,初始化自预训练文本LLM(Qwen3)权重,使模型从无标签数据中学习通用语音表征。第二阶段在基于注意力的编码器-解码器(AED)框架内,使用大规模标注ASR数据集进行监督预训练,精调编码器以捕捉丰富的声学-语言特征。

监督微调分五个顺序阶段进行。第一阶段冻结音频编码器与LLM,仅训练适配器对齐表征。第二阶段解冻编码器,与适配器一同使用低成本ASR数据训练。第三阶段冻结编码器与适配器,应用LoRA微调LLM,保留其文本生成能力。第四阶段对编码器与适配器进行全参数微调,同时继续对LLM应用LoRA,仅使用高质量、多模型验证的转录数据。第五阶段在冻结编码器上添加并训练CTC解码器,生成用于RAG热词检索的初始假设。
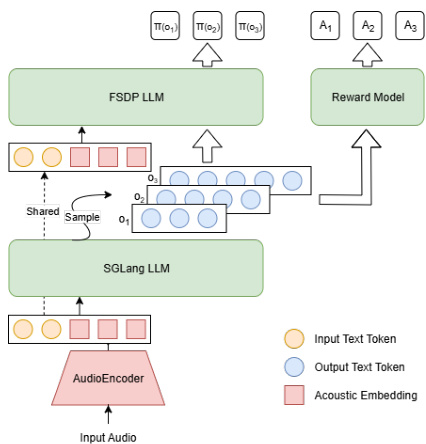
对于强化学习,作者引入FunRL——专为大型音频-语言模型设计的可扩展框架。如图所示,FunRL使用Ray协调音频编码器、rollout和策略模块,高效交替GPU使用。音频编码器处理输入音频批次提取嵌入,随后转移至CPU。基于SGLang的LLM rollout生成多个假设,每个假设通过基于规则的价值函数分配奖励。基于FSDP的策略模型计算输出概率并通过RL进行策略优化,更新后的策略同步回rollout模块以维持在线策略训练。
RL算法基于GRPO,生成一组响应 {oi}i=1G,并使用复合价值函数为每个响应分配奖励 Ri。优势 A^i,t 计算如下:
A^i,t=std({Rj}i=1G)Ri−mean({Rj}j=1G)策略通过带KL惩罚的裁剪目标优化:
LGRPO(θ)=G1i=1∑G∣oi∣1t=1∑∣oi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ε,1+ε)A^i,t)−βDKL(πθ∣∣πref)其中
ri,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t).价值函数结合多个组件:ASR准确率(1−WER)、关键词精确率与召回率、通过正则表达式惩罚实现的噪声鲁棒性与幻觉抑制、以及语言匹配强制。这些规则共同提升识别质量与用户体验,尤其在挑战性案例中。
为缓解幻觉,作者在训练数据中加入零填充噪声段,教会模型识别非语音输入并抑制虚假输出。对于热词定制,RAG机制基于CTC假设与音素或词片词汇表的编辑距离检索候选词,注入LLM上下文以偏向用户指定术语。
实验
- Fun-ASR在开源基准与真实行业数据集上均实现当前最优性能,超越开源模型与商业API,尤其在噪声条件下表现突出。
- Fun-ASR-nano仅0.8B参数,性能接近Seed-ASR等更大模型,展示强大效率。
- 流式ASR性能在多个测试场景中超越Seed-ASR,证实其鲁棒实时能力。
- 噪声鲁棒训练显著提升挑战性环境(如用餐、超市)表现,相对增益超30%;强化学习进一步增强抗噪能力。
- 代码切换评估证实训练数据构建有效,在中英混合测试集上获得优异WER结果。
- 热词定制显著提升召回率,尤其对技术术语与人名,RL使关键词识别超越提示上下文。
- 多语言Fun-ASR-ML与Fun-ASR-ML-Nano在中英文测试集上优于或媲美Whisper与Kimi-Audio等领先模型。
- 强化学习持续提升性能——离线提升4.1%,流式提升9.2%——同时减少插入/删除错误并改善热词整合,即使对未见领域术语亦然。
- 当前局限包括聚焦中英文、上下文窗口有限、缺乏远场或多通道支持——计划未来改进。
作者评估Fun-ASR在多个技术领域热词定制性能,显示强化学习持续提升召回率与准确率,尤其在人名与生物学等挑战性主题中。结果表明,RL使模型即使未明确列为热词,也能更好识别领域术语,降低离线与流式场景下的词错误率。尽管在哲学等少数领域出现轻微权衡,整体识别性能仍随RL提升。
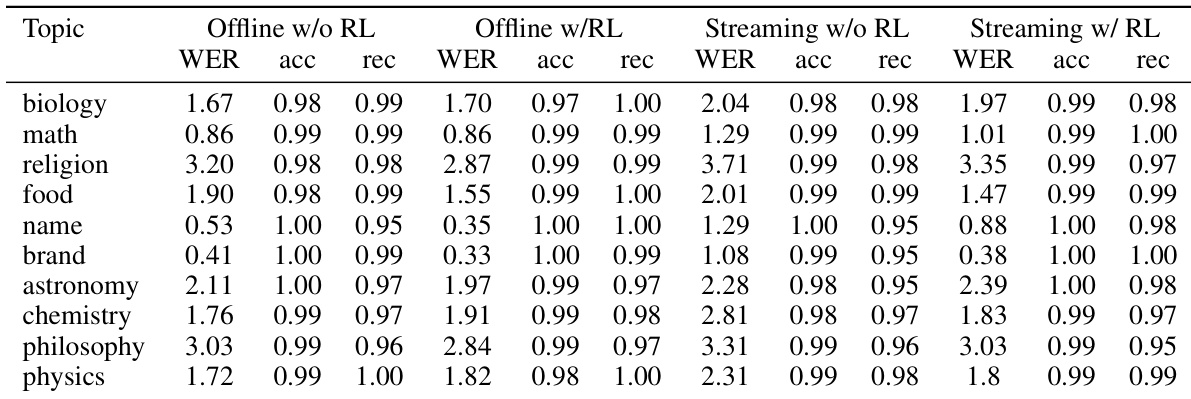
作者在多种测试条件下评估多个ASR模型,包括近场、远场、复杂背景及领域特定场景。结果显示Fun-ASR始终实现最低平均WER,优于开源与商业模型,尤其在挑战性声学环境中。模型在多样条件下的强劲表现凸显其真实部署的鲁棒性与适应性。
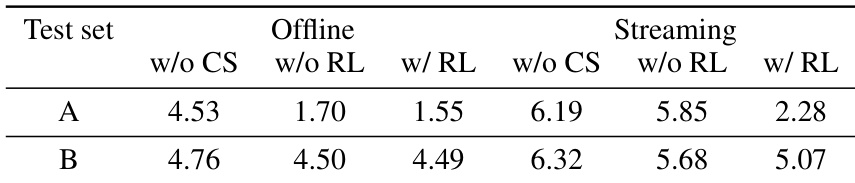
作者评估强化学习(RL)与代码切换(CS)训练对ASR性能的影响,显示RL在离线与流式模式下均持续降低WER。结果表明RL带来的增益大于CS,尤其在流式场景中,二者结合获得最佳整体性能。改进表明RL帮助模型更好处理序列预测挑战,减少实时解码错误。
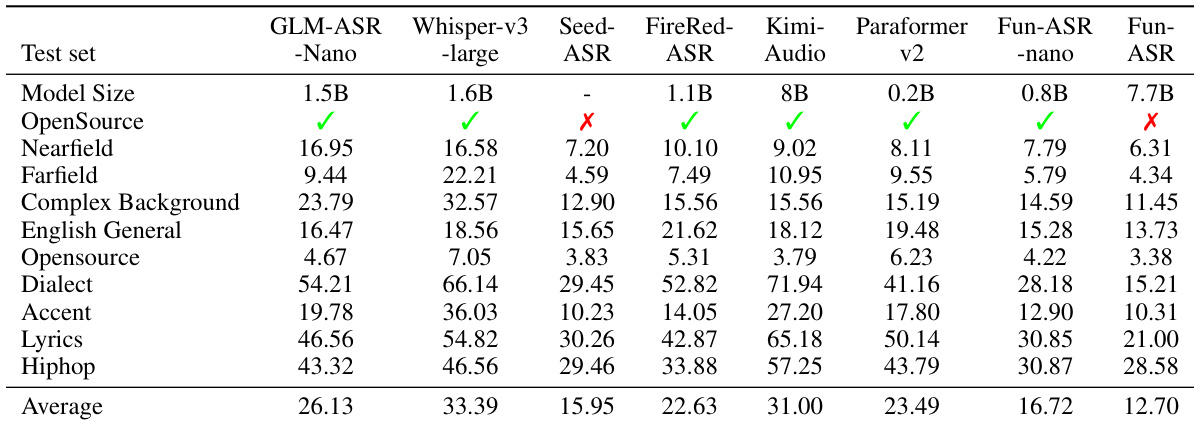
作者在开源基准上评估多个ASR模型,发现尽管部分开源系统WER较低,其性能无法一致转化为真实行业数据集表现。Fun-ASR在这些评估中超越开源与商业模型,Fun-ASR-nano尽管参数较少仍表现具竞争力。结果确认仅依赖开源数据评估可能无法反映真实世界鲁棒性,凸显更新、行业相关测试集的必要性。
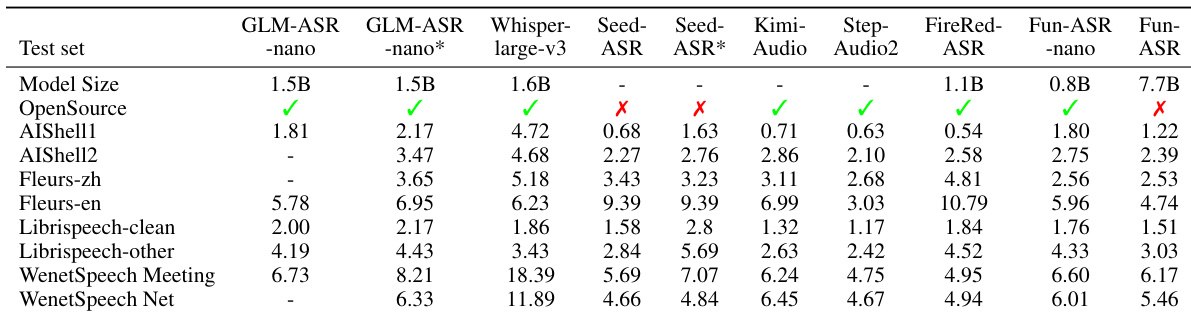
作者在多种噪声环境中评估Fun-ASR,显示噪声鲁棒训练显著降低词错误率,尤其在用餐与超市等挑战性场景中。添加强化学习在多数条件下进一步提升性能,尽管在步行街等少数场景中略微增加错误。结果确认结合噪声鲁棒训练与强化学习获得最佳整体抗噪能力。