Command Palette
Search for a command to run...
通过策略拍卖实现小规模Agent的扩展
通过策略拍卖实现小规模Agent的扩展
Lisa Alazraki William F. Shen Yoram Bachrach Akhil Mathur
摘要
小型语言模型正日益被视为实现智能体人工智能(agentic AI)的一种有前景且成本效益高的方法,支持者认为它们在智能体工作流中已具备足够的能力。然而,尽管小型智能体在简单任务上能够接近大型模型的表现,其性能在任务复杂度提升时是否仍能有效扩展、何时必须依赖大模型,以及如何更高效地利用小型智能体完成长期任务,这些问题仍不明确。在本研究中,我们通过实证发现,小型智能体在深度搜索和编程任务中,其性能无法随任务复杂度的增加而有效提升。为此,我们提出了一种名为“工作负载效率的策略拍卖”(Strategy Auctions for Workload Efficiency, SALE)的智能体框架,该框架受自由职业者市场机制的启发。在SALE框架中,智能体以简短的战略计划参与竞标,这些计划由一个系统化的成本-价值评估机制进行评分,并通过共享的拍卖记忆进行迭代优化,从而实现针对每项任务的动态路由与持续自我改进,而无需训练独立的路由模块,也无需运行所有模型直至完成。在不同复杂度的深度搜索与编程任务中,SALE将对最大模型的依赖降低了53%,总体成本下降35%,并且在仅带来可忽略的额外开销(仅限于执行最终推理轨迹)的前提下,持续超越最大模型在pass@1指标上的表现。相比之下,依赖任务描述的传统路由机制要么表现不如最大模型,要么无法降低计算成本——往往两者兼有,凸显其在智能体工作流中的不适应性。这些结果表明,虽然小型智能体在复杂任务中可能本身能力不足,但通过协调的任务分配与运行时的自我优化机制,仍可实现有效的“能力扩展”。更广泛而言,这些发现推动了对智能体人工智能的系统级思考:未来的性能提升将不再主要依赖于不断增大的单一模型,而更多来自受市场机制启发的协同机制,这些机制能够将异构智能体组织成高效、自适应的智能生态系统。
一句话总结
来自 Meta、帝国理工学院和剑桥大学的研究人员提出了 SALE——一种受市场机制启发的框架,其中大小语言模型通过提交战略计划竞标以处理复杂的代理任务;SALE 将对最大模型的依赖降低了 53%,整体成本降低 35%,同时通过测试时自我改进和成本-价值拍卖提升了准确性。
主要贡献
- 小型代理在简单任务上表现接近大型代理,但在深度搜索和编程等复杂任务中性能显著下降,本文首次通过新提出的 HST-BENCH 基准(结合真实世界任务与人类解题时间)实证量化了这一扩展差距。
- 本文引入 SALE,一种受市场机制启发的框架:异构代理提交战略计划,由成本-价值指标评分,并通过共享拍卖记忆优化,实现无需单独训练或完整模型执行的动态任务路由与测试时自我改进。
- SALE 将对最大代理的依赖降低 53%,整体成本削减 35%,在复杂任务上表现匹配或超越最大代理,优于无法适应或降低成本的静态路由方法,证明基于拍卖的协调可通过自适应编排有效“放大”小型代理。
引言
作者利用小型语言模型作为成本效益高的代理处理复杂工作流,但发现其性能随任务复杂度增加而急剧下降——尤其在深度搜索和编程任务中——使其单独难以胜任长时程任务。先前的路由方法要么需运行所有模型至完成(成本过高),要么依赖静态训练分类器,无法随难度自适应或扩展。其主要贡献是 SALE——一种受市场机制启发的框架:代理提交简短战略计划,通过共享拍卖记忆评分和优化,实现无需训练独立路由器的动态测试时路由与自我改进。SALE 将对最大代理的依赖降低 53%,整体成本削减 35%,性能优于单一模型和现有路由器,证明协调异构代理可提供比单独扩展单个模型更优的性能-成本权衡。
数据集

作者使用 HST-BENCH——一个包含 753 个代理任务、标注人类解题时间的评估数据集,用于衡量深度搜索和编程领域的性能。构建与使用方式如下:
-
数据集组成与来源
HST-BENCH 整合现有开源基准:SimpleQA、PopQA、HotpotQA、GAIA、人类最后考试(HLE)、MBPP 和 LeetCode。为更好填充低复杂度区间,作者补充了自定义多选题集(Coding-MCQ)。 -
各子集关键细节
- 任务采样自官方测试集,无效或无答案实例被剔除。
- HLE 仅限专家验证的化学/生物问题。
- GAIA 的人类解题时间复用其验证集数据。
- LeetCode “困难”任务采用已发表时间估计(Siroš 等,2024),因标注成本高。
- Coding-MCQ 包含短小、概念性问题,聚焦核心编程知识(示例见附录 A.4)。
-
复杂度分箱与标注
- 人类解题时间(τ(t))由 3+ 名专家标注者(计算机科学毕业生)标注,仅允许使用规定工具(如浏览器、IDE)。
- 时间数据经正确性过滤与异常值剔除(>2 标准差),后取平均。
- 任务按 τ(t) 分为 5 个互斥区间:0–0.1 分钟、0.1–0.5 分钟、0.5–2.5 分钟、2.5–12.5 分钟、12.5–60 分钟。
- 区间按几何级数(5 倍间距)划分,以平衡跨越 3 个数量级解题时间的样本规模。
- 标注者间可靠性高(Krippendorff’s α = 0.86)。
-
用于模型评估
- 测试集含 753 个任务;独立开发集(搜索 68 个,编程 88 个)用于调参。
- 模型性能按复杂度区间分析,研究扩展如何影响代理能力。
- 作者使用 Qwen3 模型(4B–32B)进行受控扩展实验,固定架构与训练,隔离规模影响。
- 评估指标包括成功率与成本(基于 token),未来计划扩展工具定价。
-
处理与元数据
- 元数据含来源数据集、复杂度区间与聚合人类解题时间。
- 论文表 3 显示各区间数据集贡献——低区间主导为 SimpleQA/Coding-MCQ,高区间为 GAIA、HLE 和 LeetCode Hard。
- 未裁剪或数据增强;任务以原始形式使用,标准化计时协议。
方法
作者采用新型拍卖框架 SALE,通过将战略计划视为竞标,动态将任务路由至异构代理池中最合适的代理。架构围绕四个核心阶段设计:策略竞标、成本与价值分配、中标选择、基于拍卖记忆的策略优化。各阶段旨在优化计算成本与预期性能的权衡,全程由学习的评分权重控制。
在策略竞标阶段,池中每个代理 ai 依据任务 t 与环境 E 生成策略 st,i。这些策略被解释为竞标,编码代理的预期方法,包括任务分解、工具选择与预期挑战。作者强调,这些计划不仅是执行产物,更是模型选择的信息信号。
参考框架图,展示多个代理并行提交策略处理给定任务。策略随后传入成本与价值分配模块。成本 Ct,i 估算为代理 token 价格 π(ai)、策略长度 ∣st,i∣ 与可调权重 wc 的函数:
Ct,i=wc⋅π(ai)⋅∣st,i∣.该公式以策略长度作为总推理成本与执行风险的代理,依据先前研究——更长计划与更高失败率及 token 消耗相关。
价值 Vt,i 计算为内在与外在信号的加权组合:
Vt,i=wh⋅H(st,i)+aj∈A∑wj⋅γj(st,i),其中 H(st,i) 为策略的归一化熵,捕捉信息丰富度;γj(st,i) 表示来自代理评审团的同行与自我评估。熵项基于证据——更高熵推理与更少冗余及更好规划结果相关。评审机制(含自我与同行评估)旨在增强判断可靠性,符合 LLM 评审团相关文献。
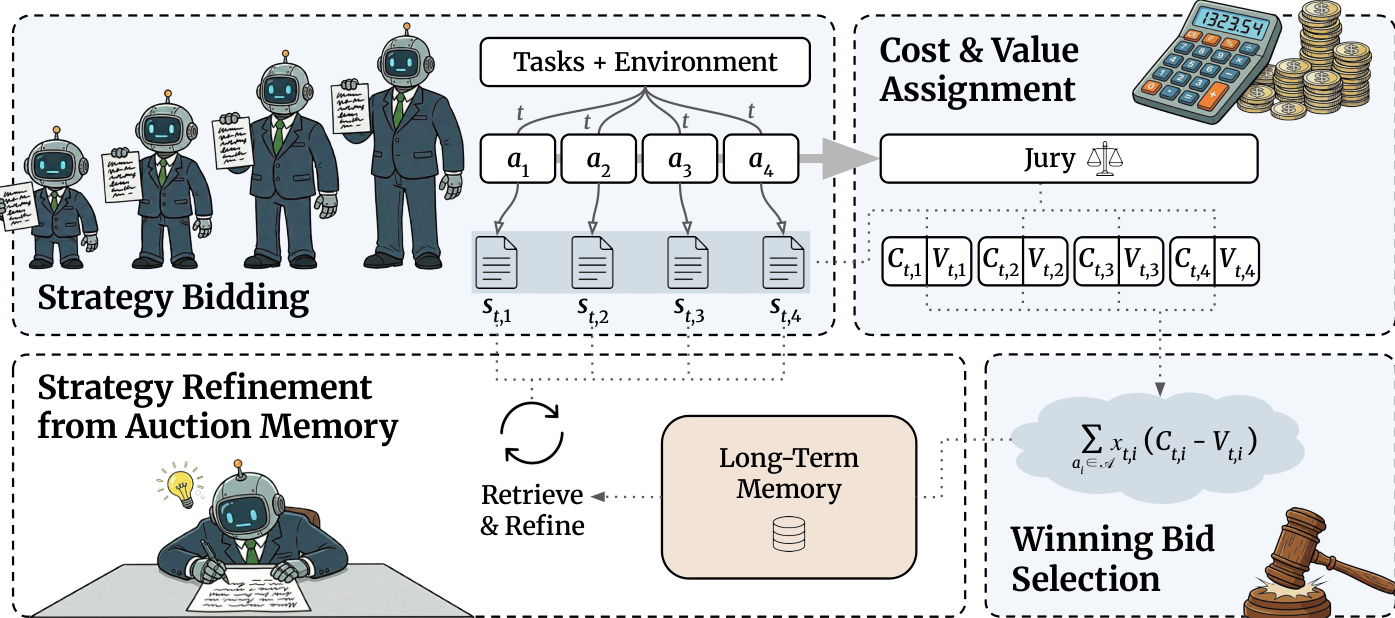
中标选择模块采用最小-最大优化,学习评分权重 w=(wc,wh,{wj}),最小化训练任务集上最差情况的成本减价值 Ct,i−Vt,i。该目标确保鲁棒性,防止任一任务分配不佳。推理时,对新任务 t,系统分配二元变量 xt,i∈{0,1} 选择唯一代理,最小化:
zt=ai∈A∑xt,i(Ct,i−Vt,i),即选择 Ct,i−Vt,i 最低的代理。
为提升成本效率,框架引入由长期记忆库 M 驱动的策略优化机制。每次拍卖后,所有提交策略(中标与未中标)连同任务结果存入记忆库。对新任务 t,若暂定中标者非最便宜代理,较便宜代理从记忆库中检索基于任务相似性的历史中标与未中标策略对,使用对比提示模板生成优化策略 st,ir,重新评估成本与价值。若任何优化竞标改善成本-价值权衡,则取代暂定中标者;否则保留原选择。此机会性优化确保仅成本高效代理承担记忆检索与重规划开销,保持系统整体效率。
整个拍卖机制(含评审与优化)仅增加极小推理开销——约数百 token——相比最终执行通常消耗的数万至数百万 token,其开销可忽略不计。
实验
- 更小、更便宜的代理在简单任务上表现接近大型代理,但随任务复杂度增加急剧落后,显示模型规模与成本的强分层。
- 大型代理并非固有更高效解决复杂任务;常使用相似或更多 token,无法抵消其更高每 token 成本。
- SALE——基于策略拍卖系统,结合记忆驱动自我优化——通过动态分配任务至最成本效益代理,持续优于单一代理与现有路由器,同时提升或匹配准确率。
- SALE 在各任务区间降低 17–53% 成本,同时提升或维持 pass@1,将性能-成本帕累托前沿推至超越任何单一模型或基线路由器。
- 小型代理(4B、8B)即使在复杂任务中也承担大量工作量,且随拍卖反馈推进其策略逐步优化,贡献持续增长。
- Shapley 值分析证实,小型代理通过评审与记忆对集成有显著贡献,即使极少被选中执行。
- 定性分析揭示互补失败模式:大型代理常过度设计或跳过验证,小型代理更依赖工具与检查,使 SALE 能在竞标时利用策略差异。
- 消融实验表明,SALE 成本-价值函数与评审机制所有组件均至关重要;移除任一均降低性能或效率,评审多样性提供鲁棒、低开销增益。
- SALE 路由保守,优先准确率而非成本——常在简单任务过度升级至大型代理——但极少低估,确保关键处正确性。
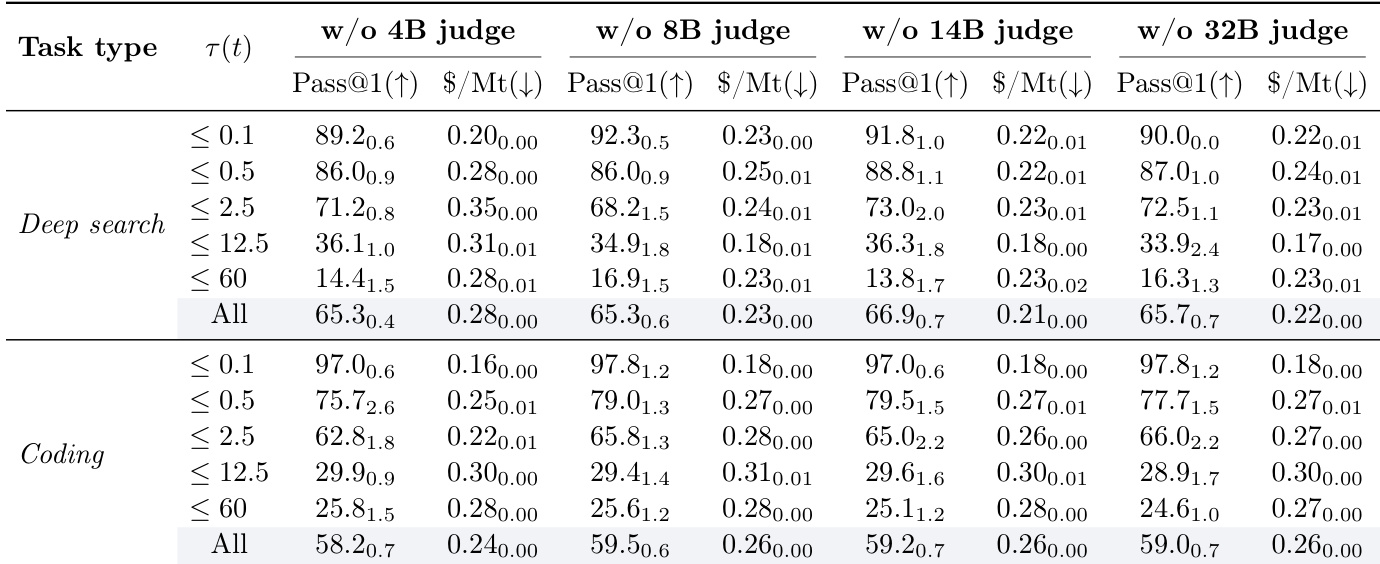
移除 SALE 系统评审团中任一评审者均降低整体 pass@1 性能,确认每个代理对集成贡献独特信号。完整评审团始终优于任何单一评审者配置,4B 等小型评审者在提升准确率与成本效率(尤其编程任务)中起关键作用。这种判断多样性提供正则化效果,增强鲁棒性而不增加显著计算开销。
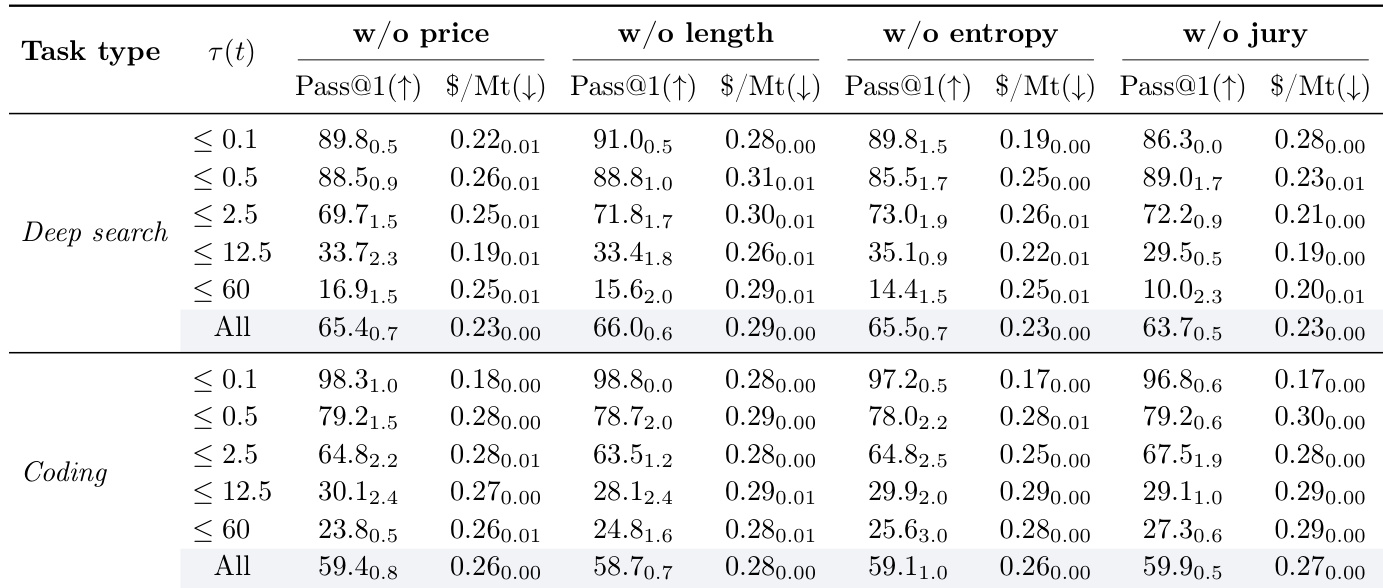
消融成本-价值函数任一组分——价格、策略长度、熵或评审评分——均持续降低整体 pass@1 性能,确认每项对系统有效性有实质贡献。虽部分消融在特定情况下略降成本,但以牺牲准确率为代价,尤其在更复杂任务中。完整函数在各类任务与复杂度层级实现性能与资源效率最优平衡。
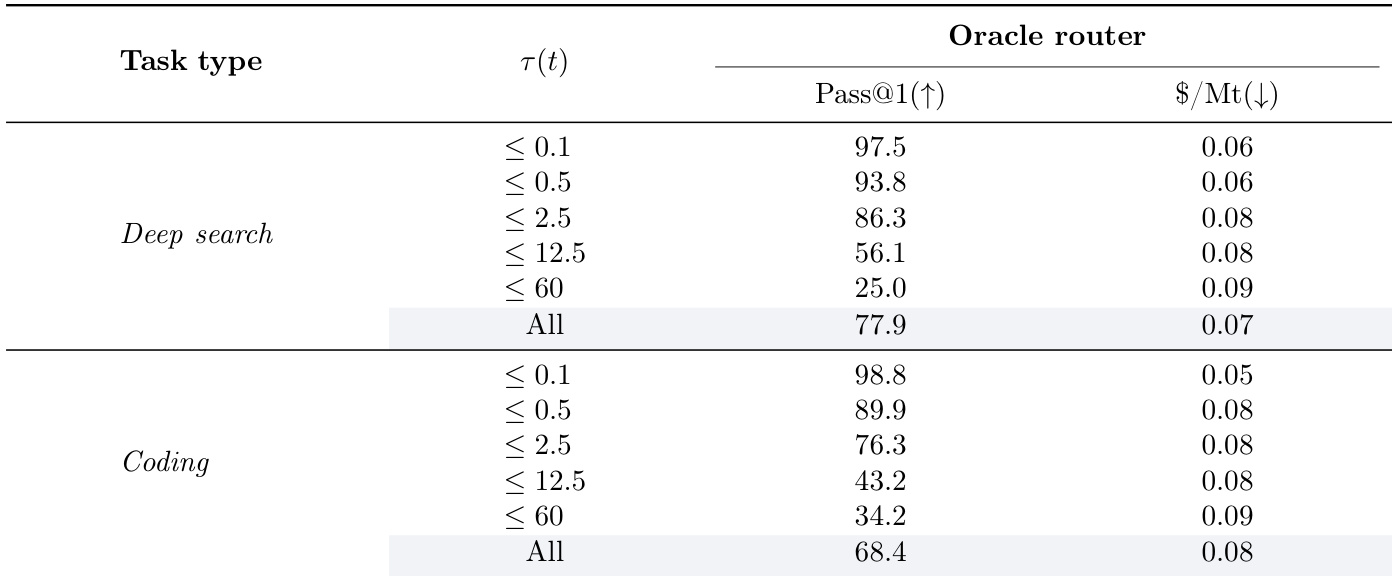
最优路由器(选择能解决任务的最小代理)在深度搜索与编程任务所有复杂度层级均实现最高 pass@1 分数,同时默认选择更便宜模型以最小化成本(当无法确保正确时)。结果表明,性能随任务复杂度增加急剧下降,最复杂任务(τ(t) ≤ 60)深度搜索 pass@1 低至 25.0,编程低至 34.2,表明固有难度而非路由低效。最优路由器(尤其在简单任务)一致的成本优势,凸显智能路由系统通过更好匹配代理能力与任务需求接近此理想状态的潜力。
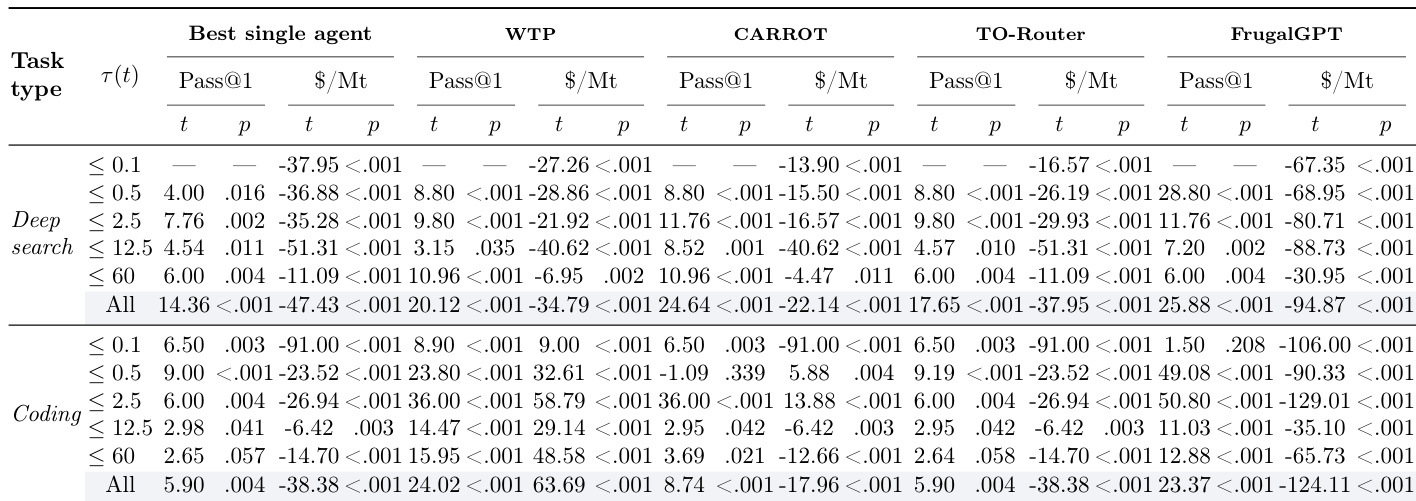
结果表明,更小、更便宜的代理在简单任务上表现接近大型代理,但随复杂度增加显著落后。SALE 路由系统通过动态分配任务至最成本效益代理,持续优于单一代理与替代路由器,且不牺牲准确率,在所有复杂度层级实现更优性能-成本权衡。此优势源于基于策略的竞标、评审评估与记忆驱动优化,共同实现更高效资源分配与小型代理竞争力的逐步提升。
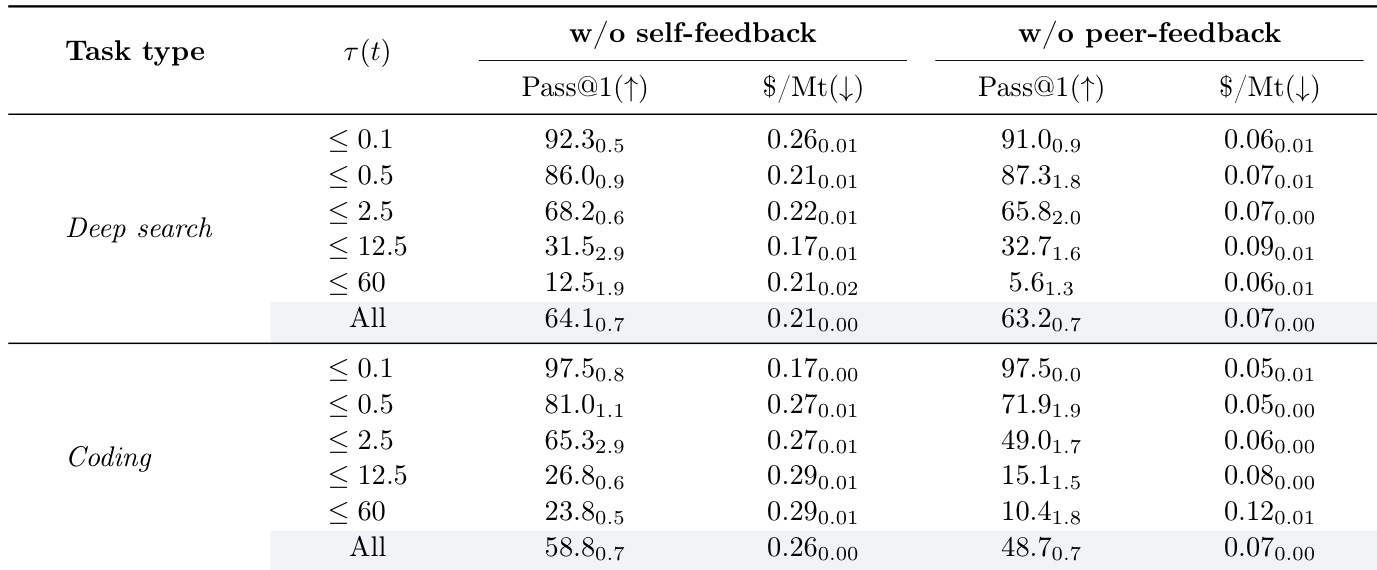
作者评估从 SALE 路由系统中移除自我反馈或同行反馈的影响,发现两种反馈均对性能有显著贡献。无同行反馈时,pass@1 急剧下降,尤其在复杂任务中;移除自我反馈则成本降低但准确率下降,表明同行判断对难题提供必要外部校准。总体而言,两种反馈机制同时激活时系统表现最佳,凸显其在平衡准确率与效率中的互补作用。