Command Palette
Search for a command to run...
PaperSearchQA:基于RLVR的科学论文搜索与推理学习
PaperSearchQA:基于RLVR的科学论文搜索与推理学习
James Burgess Jan N. Hansen Duo Peng Yuhui Zhang Alejandro Lozano Min Woo Sun Emma Lundberg Serena Yeung-Levy
摘要
搜索代理(Search Agents)是一类基于语言模型(Language Models, LMs)的系统,能够通过推理并检索知识库(或网络)来回答问题。近期的方法通常仅采用强化学习结合可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)来优化最终答案的准确率。然而,大多数RLVR搜索代理聚焦于通用领域问答(General-domain QA),这限制了其在科学、工程和医学等技术性AI系统中的实际应用价值。在本工作中,我们提出训练搜索代理在科学论文中进行检索与推理——这一任务不仅检验了技术性问答能力,更直接面向真实科研人员的需求,其核心能力对于未来“AI科学家”系统的发展至关重要。具体而言,我们发布了一个包含1600万篇生物医学论文摘要的搜索语料库,并构建了一个具有挑战性的事实型问答数据集——PaperSearchQA,该数据集包含6万条可从语料库中回答的问题样本,同时配套提供了基准测试(benchmarks)。我们在该环境中训练搜索代理,使其在性能上超越非强化学习的检索基线方法。此外,我们还进行了进一步的定量分析,观察到代理展现出诸如规划(planning)、推理(reasoning)以及自我验证(self-verification)等有趣的行为模式。我们所发布的语料库、数据集与基准测试均可与主流的Search-R1代码库兼容,用于RLVR训练,相关资源已公开于 https://huggingface.co/collections/jmhb/papersearchqa。最后,我们的数据构建方法具备良好的可扩展性,可轻松推广至其他科学领域,为构建跨学科的科学问答系统奠定了基础。
一句话总结
斯坦福大学与陈-扎克伯格生物中心的研究人员提出了 PaperSearchQA,这是一个包含 60,000 个样本的生物医学问答数据集,基于 1600 万篇摘要构建,使通过 RLVR 训练的搜索代理能够通过规划与自我验证超越检索基线——从而推进面向技术领域的 AI 科学家系统。
主要贡献
- 我们引入了一个新的科学问答训练环境,包含 1600 万篇生物医学摘要语料库和一个 60,000 样本的事实型问答数据集(PaperSearchQA),旨在测试技术推理能力并支持真实的科学工作流。
- 我们证明,通过 RLVR 训练的代理在该任务上优于非 RL 基线,同时通过定量与定性分析揭示了规划、自我验证和策略性查询重写等新兴行为。
- 我们的数据集和基准与 Search-R1 代码库兼容,并已公开发布于 Hugging Face,其可扩展的数据构建方法可延伸至化学或材料科学等其他科学领域。
引言
作者利用具有可验证奖励的强化学习(RLVR)训练能够搜索和推理科学论文的语言模型——这一能力对于科学、工程和医学领域的 AI 系统至关重要。先前的 RLVR 研究集中于通用领域的琐事问答,缺乏真实科学工作流所需的技术深度。现有的科学问答系统依赖于脚手架或监督微调,限制了其泛化能力。作者的主要贡献是一个新的训练环境,包括一个 1600 万篇摘要的生物医学语料库、一个 60,000 样本的事实型问答数据集(PaperSearchQA)和基准——全部兼容 Search-R1 代码库——使 RL 训练的代理能够超越非 RL 基线,并展现出规划和自我验证等新兴行为。
数据集
-
作者使用 PaperSearchQA,一个基于 1600 万篇 PubMed 摘要构建的生物医学问答数据集,用于训练和评估检索增强代理。它包含 54,907 个训练样本和 5,000 个测试样本,每个样本均包含事实型答案、类别标签和改写标记。
-
问题通过 GPT-4.1 使用结构化提示生成,确保答案明确、单一实体,避免缩写或文档特定措辞。每篇摘要生成 3 个问答对,其中一半通过 LLM 改写以减少关键词匹配偏差。
-
十个专家定义的类别指导问答生成,包括“实验与计算方法”(27%)和“治疗、适应症与临床证据”。类别通过整合人工头脑风暴和对 BioASQ 问题的 LLM 分析得出。
-
使用 GPT-4.1 为每个真实答案生成同义词,以支持精确匹配奖励建模。所有样本均包含 PubMed ID、类别和改写状态。数据集采用 CC-BY-4.0 许可,可在 Hugging Face 获取。
-
评估时,作者使用 BioASQ 的事实型子集(1,609 个样本),并使用相同 LLM 方法为其扩充答案同义词。BioASQ 问题由人工编写,涵盖更广泛的问题类型,但本研究仅使用事实型问答。
-
检索语料库包含 1600 万篇 PubMed 摘要(平均 245 词),使用 BM25(2.6GB)和 e5(93GB)索引。推理时,e5 需要两块 A100 GPU。语料库和 BioASQ 数据继承自 BioASQ 的 CC-BY-2.5 许可。
-
整个流程通过 OpenRouter 花费约 600 美元。提示和代码已公开;数据集专为 RLVR 训练设计,奖励模型仅验证精确匹配或同义词匹配,无需推理轨迹或检索文档标注。
方法
作者利用具有可验证奖励的强化学习(RLVR)框架训练具备搜索能力的语言模型,使代理能够迭代推理、发出搜索查询并根据检索到的证据合成答案。训练流程始于构建领域特定的问答数据集,接着索引搜索语料库,最终通过 RLVR 进行策略优化。核心交互循环由一个最小系统提示控制,指示模型在 -thinking- 标记内封装推理,通过 标签发出搜索查询,并在 标签内交付最终答案。该设计有意避免规定详细的推理策略,允许代理通过奖励驱动的探索发现有效行为。
请参阅框架图,其展示了一个典型的代理轨迹:模型首先进行内部推理以识别问题的关键组成部分,然后发出搜索查询以检索相关文档,将检索到的信息整合到其推理轨迹中,最终生成经过验证的答案。检索到的文档附加到上下文中,但在训练期间不参与梯度计算,确保策略学习生成有用的查询并合成答案,而非记忆检索输出。
训练目标是在检索器 R 和问答数据集 D 条件下,最大化由策略 LLM πθ 生成轨迹的期望奖励:
πθmaxEx∼D,y∼πθ(⋅∣x;R)[rϕ(x,y)]−βDKL[πθ(y∣x;R)∣∣πref(y∣x;R)]此处,奖励模型 rϕ(x,y) 从生成序列中提取最终答案并分配二元奖励(正确为 1,否则为 0)。KL 惩罚项防止策略过度偏离参考策略,参考策略初始化为预训练 LLM 状态。优化使用组相对策略优化(GRPO),在回放组内计算优势以稳定训练。GRPO 目标结合裁剪和组归一化优势,以降低方差并提高样本效率。
如下图所示,训练数据生成过程包含两个阶段:首先,LLM 从现有数据集(BioASQ)提出问答类别,然后由领域专家精炼;其次,模型从采样的科学论文生成新的问答对,经改写后存储于最终数据集。该合成数据管道确保覆盖多样化的科学领域,同时保持事实准确性。
训练期间代理的行为表现为三种不同的推理模式:显式规划与关键词提取、搜索前推理、以及参数内知识验证。在第一种模式中,代理将问题分解为子任务并发出针对性搜索查询。在第二种模式中,它在检索外部信息前进行初步推理以缩小范围。在第三种模式中,它利用内部知识假设答案,仅使用搜索进行验证。这些模式并非硬编码,而是从 RLVR 训练过程中涌现,因为代理根据奖励反馈学习在内部推理和外部检索之间分配努力。

实验
- 与直接推理、思维链和 RAG 等基线方法相比,RLVR 训练显著提升了科学问答任务的性能,尤其在事实型问题上。
- RLVR 训练的模型(Search-R1)在 PaperSearchQA 上比 RAG 高出 9.6–14.5 分,在 BioASQ 上高出 5.5–9.3 分,且性能增益随模型规模增大而增加。
- 检索方法(BM25 与 e5)性能差异极小,表明在科学领域,由于技术术语的存在,基于关键词的检索已足够。
- LLM 保留了大量科学事实的参数化知识,但检索仍必不可少,因为记忆不完整。
- 在数据集构建过程中改写问题可增加难度并更好测试泛化能力,因为未改写的问题更易回答。
- 训练动态与通用问答设置相似;基础模型需要更长时间收敛,且在 GRPO 下比指令模型更稳定。
- 定性上,训练后的代理倾向于显式关键词提取和搜索规划;搜索前的早期推理和已知答案验证也会发生,但随训练减少。
- 检索后,模型通常立即作答,几乎无显式推理,可能由于简化理解需求或 RL 诱导的参数调优。
- 性能因类别而异,“生物标志物与诊断”和“蛋白质功能与信号传导”最易,“基因突变”最难。
作者使用具有可验证奖励的强化学习(RLVR)训练 LLM 进行科学问答,结果表明该方法持续优于包括直接推理、思维链和检索增强生成在内的基线方法。性能增益在更大模型上更显著,且该方法在领域内和外部基准上均有效。改进表明 RLVR 增强了模型利用参数化知识的能力,而非仅依赖检索或推理脚手架。
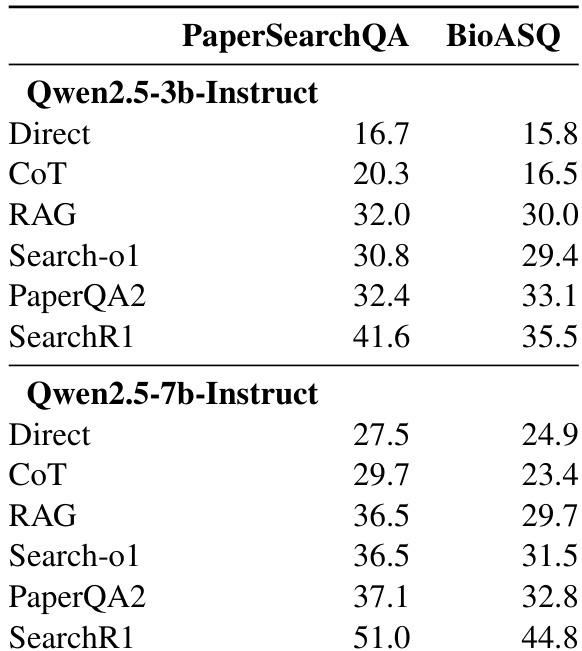
作者使用 RLVR 训练提升 LLM 在科学问答上的性能,显示在 3B 和 7B 模型上均持续优于 RAG 和思维链等基线方法。结果表明,检索增强方法显著优于无检索方法,且模型规模与性能正相关,表明参数化知识起关键作用。按类别分析显示性能因领域而异,“生物信息学数据库”最易,“基因突变”最难,而 RLVR 训练在所有类别中始终表现最佳。