Command Palette
Search for a command to run...
Fara-7B:一种用于计算机使用的高效Agent模型
Fara-7B:一种用于计算机使用的高效Agent模型
摘要
计算机使用代理(Computer Use Agents, CUAs)的发展长期受限于缺乏大规模、高质量的数据集,这些数据集能够捕捉人类与计算机交互的真实过程。尽管大型语言模型(LLMs)得益于海量文本数据的繁荣发展,但目前尚无类似规模的语料库可用于描述CUA在多步骤网页任务中的行为轨迹。为填补这一空白,我们提出了FaraGen——一种面向多步骤网页任务的新型合成数据生成系统。FaraGen能够从高频使用的网站中自动生成多样化的任务,生成多种解决方案尝试,并通过多轮验证器筛选出成功轨迹。该系统在多步骤网页任务中实现了高吞吐量、高产出率和强多样性,生成经验证的轨迹成本约为每条1美元。我们利用该数据训练了Fara-7B——一个原生的计算机使用代理模型,该模型仅通过屏幕截图感知计算机界面,通过预测坐标执行操作,且模型规模足够小,可实现本地设备运行。实验结果表明,Fara-7B在WebVoyager、Online-Mind2Web以及我们新提出的WebTailBench基准测试中,均优于其他同规模的CUA模型。其中,WebTailBench旨在更准确地反映现有基准中被严重低估的网页任务类型。此外,Fara-7B的表现可与远大于它的前沿模型相媲美,充分体现了可扩展数据生成系统在推动小型高效智能体模型发展中的关键优势。我们已将Fara-7B的权重模型开源发布于Microsoft Foundry与HuggingFace平台,并同步公开发布WebTailBench基准数据集。
一句话总结
微软研究人员推出了 FaraGen,这是一种可扩展的合成数据引擎,能够以约每条轨迹 1 美元的成本生成经过验证的网页任务轨迹,从而训练出 Fara-7B——一款紧凑型、基于截图的计算机使用代理模型,在 WebVoyager 和 WebTailBench 上表现优于同类模型,同时可在设备端高效运行。
主要贡献
- FaraGen 引入了一种可扩展的合成数据引擎,通过自动化任务提案、多智能体求解和基于大语言模型(LLM)的验证,以约每任务 1 美元的成本生成高质量、多样化的网页交互轨迹,解决了计算机使用代理(CUA)研究中关键的数据稀缺瓶颈。
- Fara-7B 是一款基于 FaraGen 生成的 14.5 万条轨迹数据训练的紧凑型 70 亿参数 CUA 模型,采用“像素输入、动作输出”推理方式(使用截图和坐标预测),在 WebVoyager 和 WebTailBench 等基准测试中达到最先进水平,同时在设备端高效运行。
- 本文发布了 WebTailBench——一个针对代表性不足的真实世界网页任务的新基准,并证明 Fara-7B 在性能上可媲美更大规模的前沿模型,同时提供更优的成本效益和隐私保护的本地部署能力。
引言
作者利用合成数据生成技术克服了训练计算机使用代理(CUA)所需的高质量人机交互数据稀缺问题。以往工作依赖手动标注、受限环境或脆弱的 DOM 基础方法,难以泛化到真实世界动态网页界面。他们的多智能体数据引擎 FaraGen 能自动提出、解决并验证多步骤网页任务,每条轨迹成本约 1 美元,从而支持高效训练 Fara-7B——一款通过原始截图感知屏幕并预测点击、滚动等底层动作的紧凑型 70 亿参数模型。Fara-7B 在网页基准测试中表现媲美或超越更大模型,并引入 WebTailBench 评估代表性不足的真实任务,证明小型高效模型在针对性合成数据训练下可实现强大的代理能力。
数据集
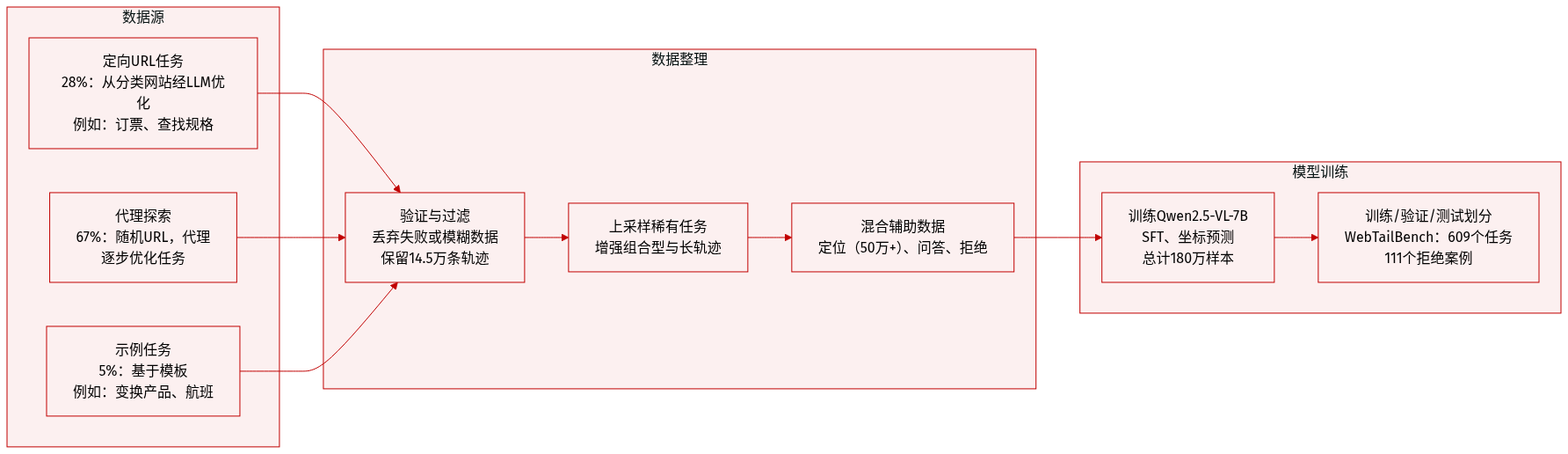
作者使用合成数据引擎 FaraGen 生成高质量计算机使用代理(CUA)训练数据,避免手动标注,转而利用真实网站和基于 LLM 的任务生成。数据集组成与使用方式如下:
-
数据集组成与来源:
- 基于三种任务生成策略构建:定向 URL 任务提案(占 28%)、智能体 URL 探索(67%)和示例任务提案(剩余 5%)。
- 主要 URL 来源:ClueWeb22(优先用于更丰富、更贴近任务的网站)和 Tranco(用于对比)。
- 任务涵盖信息获取(如产品规格)和可操作目标(如预订、购买),其中 28% 为复合型任务(多站点、多步骤)。
-
关键子集详情:
- 定向 URL 任务:基于分类 URL(如“电影”、“餐厅”)使用 LLM 生成可验证、无需登录的真实任务,筛选标准包括可实现性、具体性和实用性。
- 智能体探索任务:智能体使用截图和可访问性树遍历随机 URL,迭代完善并完成任务。平均更简单,步骤更少。
- 示例任务:通过 LLM 模板扩展现有种子任务(如变化产品、零售商或航班参数)。
- WebTailBench(609 项任务):人工验证的基准子集,涵盖 11 个代表性不足的类别(如房地产、求职申请、多商品购物),包括 111 项拒绝任务,覆盖 7 个有害类别。
-
数据在训练中的使用:
- 最终数据集:涵盖 7 万个域的 14.5 万条已验证轨迹(100 万步);每条轨迹平均涉及 0.5 个独立域,表明高度多样性。
- 轨迹数据按步骤拆分;每步包含截图、推理文本和动作(从 SoM ID 转换为像素坐标)。
- 与辅助数据混合:定位数据(50 万+样本)、UI 问答/描述和拒绝数据。总训练样本:180 万。
- 对更长或更稀有任务类型(如复合任务)进行上采样。定位数据为第二大组成部分;拒绝数据最少,以避免过度拒绝。
-
处理与元数据:
- 截图和可访问性树指导智能体动作;动作被锚定到像素坐标,便于模型直接预测。
- 验证智能体筛选成功轨迹;失败或模糊任务被丢弃。
- 定位数据使用元素描述 + VLM 验证;QA 数据通过聚焦图像接地、具挑战性问题的 GPT-5 提示生成。
- 拒绝数据结合基于训练截图的合成有害任务和 WildGuard 精选示例。
- 训练使用 Qwen2.5-VL-7B 基础模型,SFT 采用交叉熵损失,坐标预测通过标记化实现。批大小 128,训练 2 轮,bf16 精度,64 块 H100 GPU 上使用 DeepSpeed Stage 3。
方法
作者基于 Magentic-One 构建多智能体系统,生成高质量演示轨迹用于监督微调。该系统围绕两个核心智能体:Orchestrator 和 WebSurfer,二者紧密循环协作解决合成网页任务。Orchestrator 负责高层规划、进度监控和安全约束(尤其在关键点),WebSurfer 根据 Orchestrator 指令执行低层浏览器操作。参考下方框架图,展示智能体间迭代交互、UserSimulator 在多轮任务扩展中的作用,以及轨迹存储前经验证器过滤的流程。
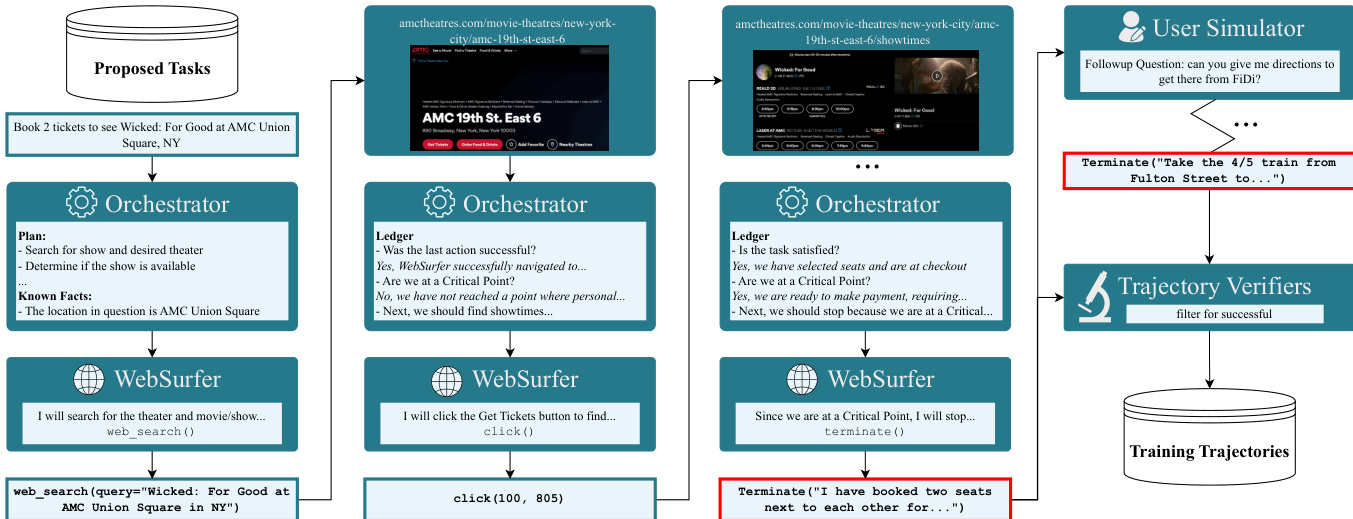
每一步,Orchestrator 维护一个诊断账本,追踪轨迹状态的五个关键属性,包括上一步是否成功、任务是否满足、是否到达关键点。这些字段由 WebSurfer 的动作历史及前后截图推断得出。基于此账本,Orchestrator 决定是否发出下一步指令、重新规划或终止轨迹。关键点——定义为需用户同意的不可逆操作,如提交个人信息或完成购买——被严格设为停止条件。当达到此类点时,可调用 UserSimulator 模拟用户输入,使流程从该点以合成批准或数据恢复。
WebSurfer 作为 SoM(模型状态)智能体,输入包括当前浏览器截图(附带可访问性树标注的边界框)、全部先前动作历史及 Orchestrator 的下一步指令。它输出对当前状态的链式思考,随后执行具体工具调用(如点击、输入、滚动)。动作执行后,结果截图连同 WebSurfer 的推理和动作报告回 Orchestrator。此闭环交互持续至满足停止条件。
为确保鲁棒性与可扩展性,作者引入多项架构优化。WebSurfer 的动作空间是动态的——例如,若视口已在页面顶部则禁用 scroll_up——并包含 Memorize 动作以跨页面存储关键信息,减少幻觉。Orchestrator 的决策逻辑由优先级表管理,解决智能体信号冲突,关键点检测优先级最高。此外,系统采用循环检测启发式:粗粒度 is_in_loop 标志在重复失败后触发重新规划,细粒度 last_action_successful 标志评估截图间视觉变化是否与执行动作一致。
生成的轨迹随后经多验证器流水线确保正确性后才纳入训练。三个互补的基于 LLM 的验证器从不同角度评估轨迹:对齐验证器检查高层任务意图,评分验证器根据生成评分标准评估部分完成度,多模态验证器验证最终响应与关键截图的一致性。这种分层验证至关重要,因为即使复杂的任务解决系统在更长、更复杂的任务中仍会出现失败模式——如循环或幻觉——若无多模态证据检查则难以察觉。
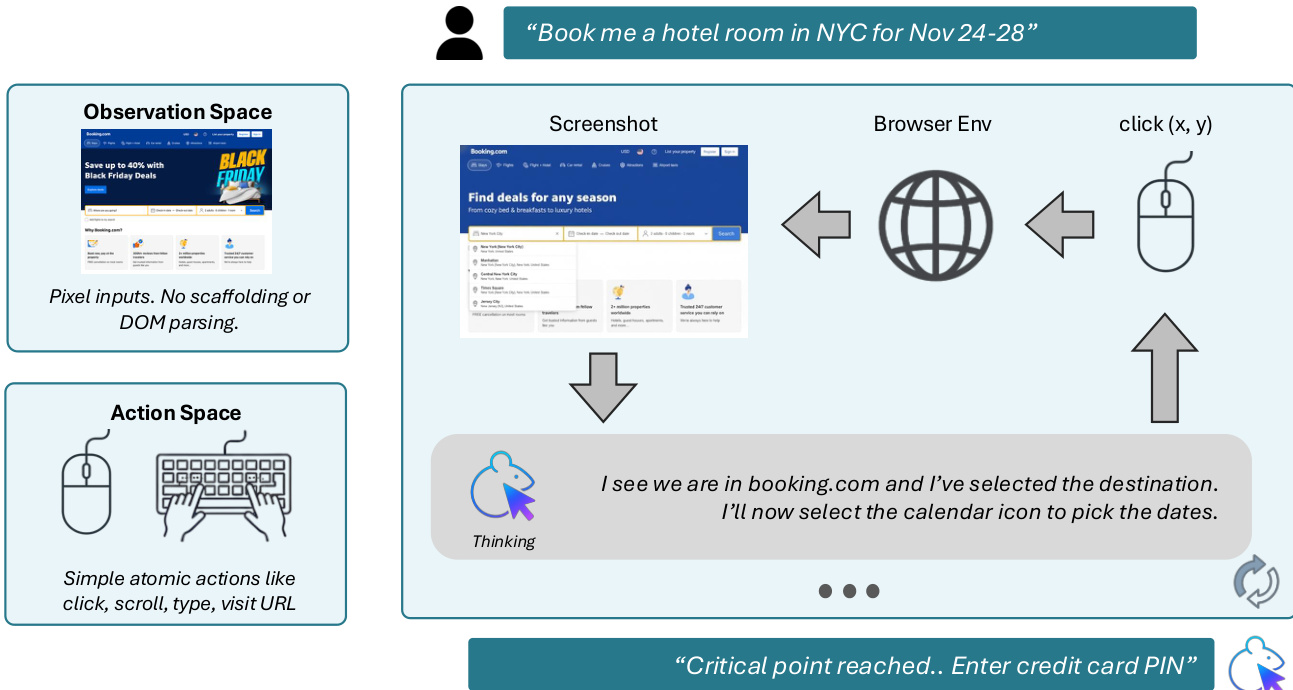
最终模型 Fara-7B 被训练以从这些多智能体轨迹中提炼行为,形成单一、高效的计算机使用代理。与训练时智能体不同,Fara-7B 在推理时不依赖可访问性树,仅依靠像素输入(截图)和浏览器元数据(如 URL)。它直接从视觉输入预测锚定动作——如点击坐标。模型架构设计为输出步骤序列,每步包含观察 ot、思考 rt 和动作 at,基于全部先前步骤历史和初始查询 q0:
P(rt,at∣q0,{o0,r0,a0},…,{ot−1,rt−1,at−1}).为管理高令牌视觉输入带来的计算负载,模型在上下文中仅保留最近 N=3 个观察,同时保留全部思考和动作历史。Fara-7B 也支持多轮交互:若用户在初始任务 q0 完成后发出后续查询 q1,模型继续预测步骤,同时保持完整轨迹历史,实现无缝任务链。
如下图所示,Fara-7B 的推理流程经过精简:接收用户查询,通过截图观察浏览器环境,内部推理,输出原子动作如点击、输入或滚动。它被明确训练为在到达关键点时终止并交还控制权,确保安全和用户对齐的行为。
实验
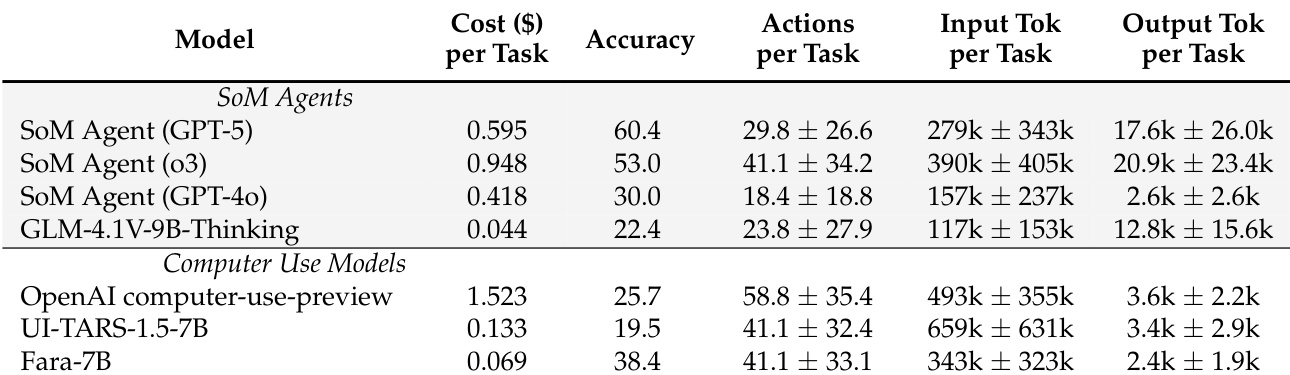
- FaraGen 使大规模 CUA 训练数据生成成本低廉(每条轨迹约 1 美元),即使使用高级模型亦经济可行,实现可扩展数据创建。
- Fara-7B 在多个网页基准测试中优于同类 7B 规模 CUA 模型,表现媲美或超越更大规模的 SoM 智能体,尤其在购物和尾部任务中表现突出。
- 该模型在定位性能上表现强劲,优于其基础模型,展示可靠的 UI 元素定位能力,尤其在文本元素上。
- 随训练数据增加和推理步骤预算延长,模型性能显著提升,尽管仅使用监督微调,仍可媲美强化学习训练模型。
- Fara-7B 在安全评估中领先,拒绝有害任务的比例高于基线,并在关键操作(如输入个人信息或确认预订)前可靠暂停,防止意外后果。
- 它实现卓越的成本效率,每任务输出令牌数比更大模型少 10 倍,成本约 0.025 美元,而专有基线约 0.30 美元,同时保持竞争力的准确性和步骤效率。
- 人工评估确认其性能,尽管略低于自动评估指标,凸显 CUA 任务中改进 LLM 作为评判框架的必要性。
- 尽管每项技能训练数据有限(如 <4K 航班/酒店任务),Fara-7B 在特定领域接近前沿模型表现,验证高质量、针对性数据的有效性。
- 对抗测试显示其对钓鱼和恶意 UI 陷阱具有韧性,失败仅限于边缘案例,可通过浏览器沙箱缓解。
Fara-7B 在多个网页基准测试中优于其他 7B 规模计算机使用模型,在多个类别中表现媲美或超越更大规模的 SoM 智能体,展示强大代理能力,同时显著更经济高效,每任务输出令牌远少于专有基线。模型在重复评估中表现稳定,表明其在真实网页环境中行为可靠。
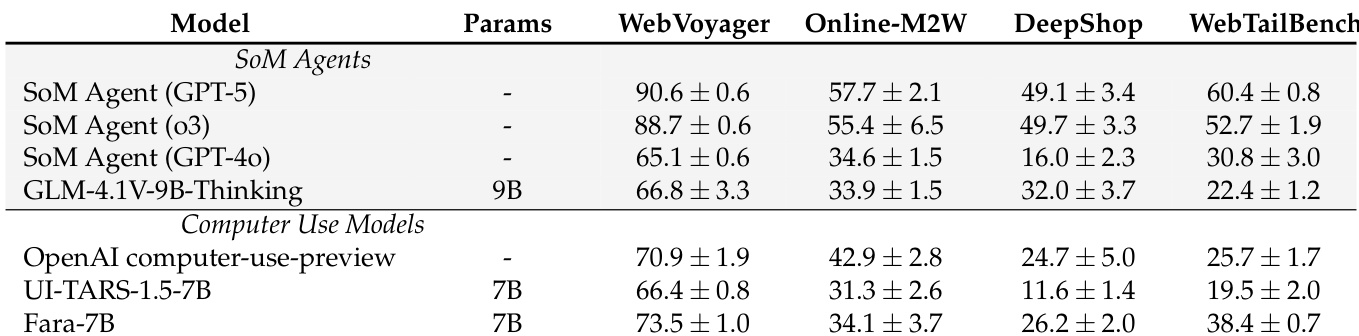
作者使用涵盖轨迹生成、定位、拒绝和 UI 描述的 180 万+样本的多样化数据集训练 Fara-7B,轨迹数据占主导。结果表明,这种平衡训练方法支持代理、安全和感知任务的强劲表现,使模型在保持成本效率和安全合规的同时实现高准确率。数据规模与组成反映对生成高质量、任务相关交互的刻意关注,推动稳健的真实世界行为。

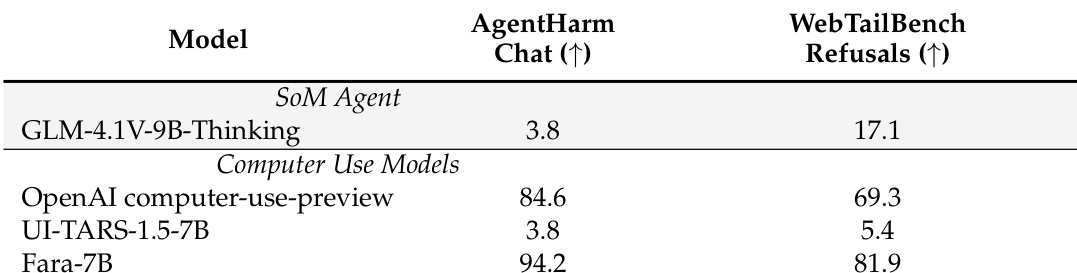
Fara-7B 在安全性能上显著优于其他计算机使用模型,在 AgentHarm-Chat 和 WebTailBench-Refusals 基准测试中实现最高拒绝率。其表现大幅超越 OpenAI 计算机使用预览模型和 UI-TARS-1.5-7B,表明其训练有效灌输了对有害任务的稳健拒绝行为。结果凸显 Fara-7B 在保持功能能力的同时优先保障用户安全的能力。
Fara-7B 在定位性能上优于其基础模型 Qwen2.5-VL,在 ScreenSpot-V1 和 ScreenSpot-V2 基准测试中实现更高准确率。它在移动、桌面和网页界面上均展示强定位能力,尤其在文本元素定位上表现优异,同时在图标/小部件识别上保持稳健表现。这些结果表明 Fara-7B 的训练增强了其准确感知和交互多样化 UI 元素的能力,支持其作为可靠计算机使用代理的应用。

Fara-7B 在准确率上高于其他 7B 规模计算机使用模型,同时每任务成本显著更低,展示良好的成本-准确率权衡。它使用的输出令牌数少于更大规模的 SoM 智能体,贡献其效率,尽管所需动作和输入令牌数相似。该模型在成本敏感部署场景中亦表现出对更昂贵专有系统的竞争力。