Command Palette
Search for a command to run...
Quant VideoGen:通过2比特KV缓存量化实现自回归长视频生成
Quant VideoGen:通过2比特KV缓存量化实现自回归长视频生成
摘要
尽管自回归视频扩散模型取得了快速进展,但一个新兴的系统算法瓶颈——键值缓存(KV cache)内存——严重制约了其可部署性与生成能力:在自回归视频生成模型中,KV cache 随生成历史不断累积,迅速占据大量 GPU 内存,通常超过 30 GB,导致无法在广泛可用的硬件上部署。更关键的是,受限的 KV cache 内存预算直接压缩了有效工作内存,显著损害了长时视频在身份一致性、场景布局与运动连贯性方面的表现。为应对这一挑战,我们提出 Quant VideoGen(QVG),一种面向自回归视频扩散模型的无需训练的 KV cache 量化框架。QVG 通过引入语义感知平滑(Semantic Aware Smoothing)机制,充分利用视频在时空维度上的冗余特性,生成低幅值、易于量化的残差信号;进一步提出渐进式残差量化(Progressive Residual Quantization)策略,采用由粗到精的多阶段量化方案,在有效降低量化误差的同时,实现生成质量与内存效率之间的平滑权衡。在 LongCat Video、HY WorldPlay 与 Self Forcing 等多个基准测试中,QVG 建立了质量与内存效率之间的全新帕累托前沿:KV cache 内存最高可压缩 7.0 倍,端到端延迟开销低于 4%,且在生成质量上持续优于现有各类基线方法。
一句话总结
来自 MIT、加州大学伯克利分校和清华大学的研究人员提出了 Quant VideoGen(QVG),这是一种无需训练的 KV 缓存量化方法,利用时空冗余和渐进残差量化,在保持长时视频生成任务中视频一致性和质量的同时,将内存使用量减少 7 倍。
主要贡献
- 自回归视频扩散模型面临严重的 KV 缓存内存瓶颈,限制了其在消费级硬件上的部署,并因强制内存预算导致身份、布局和运动在长时生成中一致性下降。
- Quant VideoGen(QVG)引入了一种无需训练的量化框架,通过语义感知平滑和渐进残差量化利用时空冗余,生成低幅度、适合量化的残差,实现从粗到细的误差递减。
- 在 LongCat-Video、HY-WorldPlay 和 Self-Forcing 上评估,QVG 最多可将 KV 内存减少 7.0 倍,延迟开销低于 4%,使 HY-WorldPlay-8B 可在单张 RTX 4090 上运行,并在受限内存下实现高于基线的 PSNR。
引言
作者利用自回归视频扩散模型实现长时视频生成,这对直播、交互式内容和世界建模等应用至关重要。然而,这些模型面临严重的内存瓶颈:KV 缓存随视频长度线性增长,迅速超出 GPU 容量,迫使使用短上下文窗口,从而降低身份、运动和布局的一致性。来自大语言模型的先前 KV 缓存量化方法在视频上失效,因其异构激活统计和缺乏时空感知。他们的主要贡献 Quant VideoGen(QVG)是一种无需训练的框架,通过语义感知平滑(将相似标记分组并减去质心以生成低幅度残差)和渐进残差量化(一种多阶段压缩方案,逐步优化量化误差)利用视频的时空冗余。QVG 最多可将 KV 缓存内存减少 7 倍,延迟开销低于 4%,使消费级 GPU 能够生成高质量的分钟级视频,并确立新的质量-内存帕累托前沿。
方法
作者采用两阶段量化框架——语义感知平滑后接渐进残差量化——以解决视频 KV 缓存量化所面临的高动态范围和时空冗余挑战。整体流程旨在通过利用视频标记固有的语义相似性和时序结构逐步减少量化误差。
流程始于语义感知平滑,该步骤作用于从 KV 缓存张量 X∈RN×d 中提取的标记块(例如,每块 N=HWTc 个标记)。作者应用 k-均值聚类将标记划分为 C 个不相交组 G={G1,…,GC},依据其隐藏表示。每组的质心 Ci∈Rd 计算为其成员的均值。然后通过质心减法得到每组的残差:
Ri=XGi−Ci,Ri∈R∣Gi∣×d此步骤有效降低了每组内的动态范围,因为大异常值被捕捉在质心中并被减去。结果得到残差张量 R,其最大幅度显著降低,直接减少量化误差,因为 E[∥x−x^∥]∝SX,且 SX 与组内最大绝对值成正比。
请参考框架图,该图说明原始 KV 缓存(a)如何通过语义分组和质心减法(b)转换为更平滑的残差分布,从而支持更精确的低比特量化。
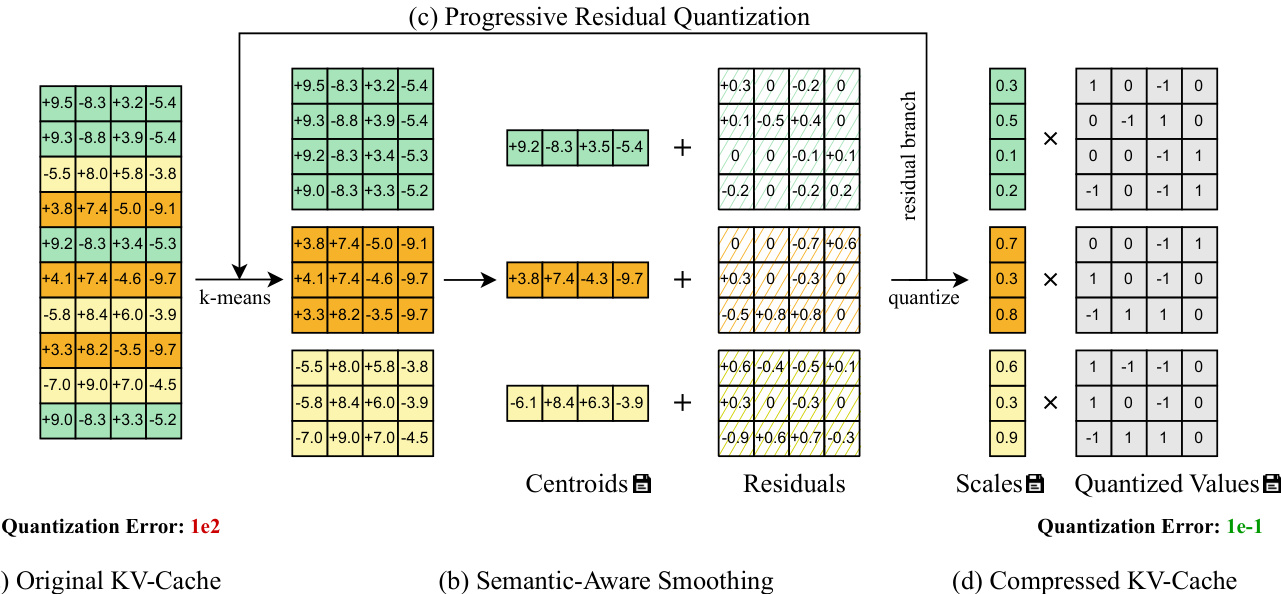
在此基础上,渐进残差量化在 T 个阶段中迭代优化残差张量。从 R(0)=X 开始,每个阶段对当前残差应用语义感知平滑,生成新残差 R(t)、质心 C(t) 和分配向量 π(t)。经过 T 个阶段后,最终残差 R(T) 使用对称的每组整数量化:
XINT,SX=Q(R(T))所有阶段的质心和分配向量存储在全局内存中,中间残差被丢弃。在反量化时,过程逆转:量化残差被反量化,然后通过从第 T 阶段到第 1 阶段依次加回分配的质心,重建最终张量 X^(0)。
这种多阶段方法使模型能够在早期阶段捕捉粗粒度语义结构,在后期阶段捕捉细粒度变化,从而实现量化误差的递减但累积的降低。如图所示,量化误差从原始缓存的 1e2 降至最终压缩表示的 1e−1,证明了渐进优化的有效性。
为支持高效部署,作者引入了算法-系统协同设计优化。他们通过缓存先前块的质心加速 k-均值,将聚类开销减少 3 倍。此外,他们实现了一个融合反量化内核,在重建完整张量时跨所有阶段加回质心,同时将中间结果保留在寄存器中以最小化全局内存访问。
实验
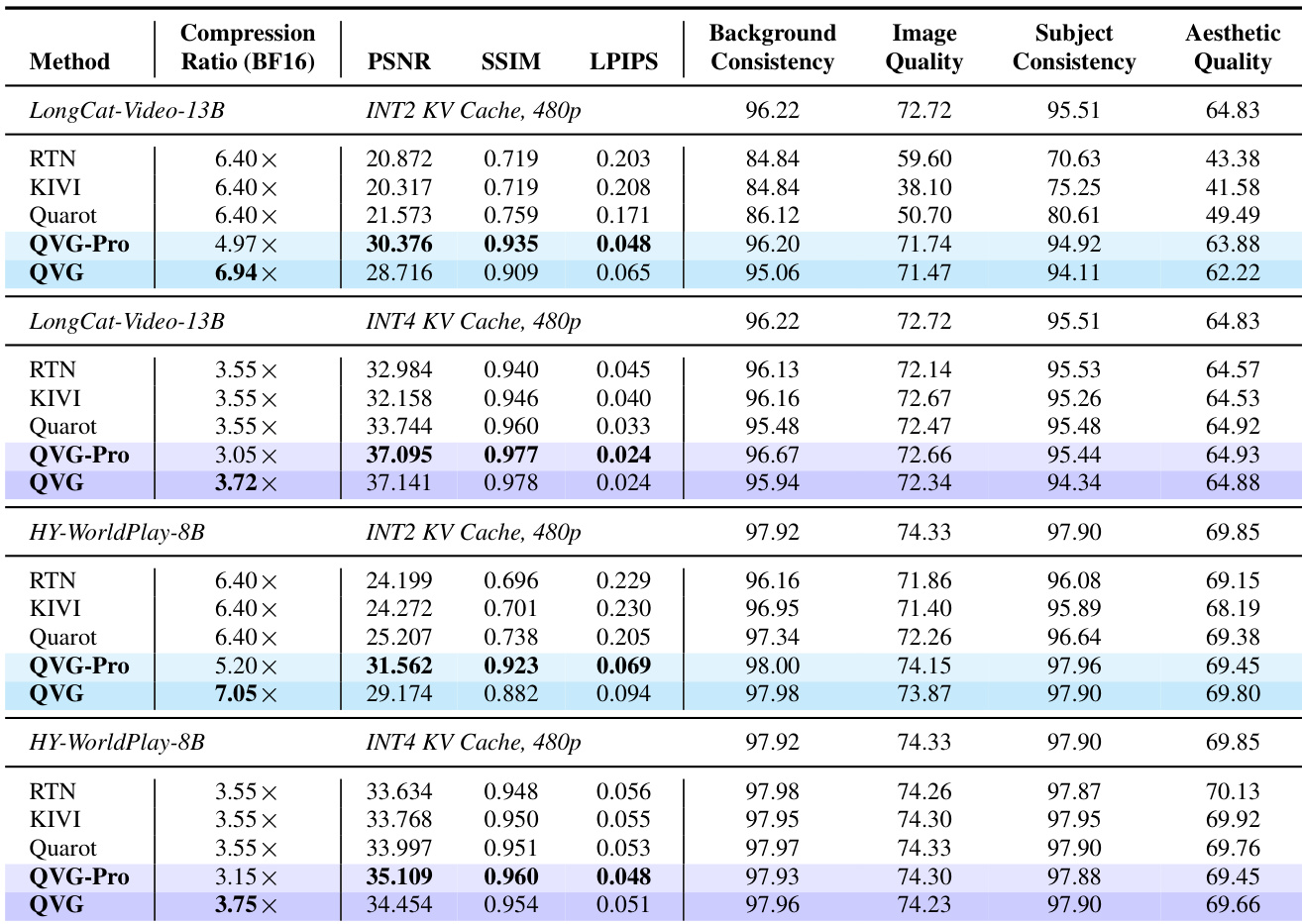
- QVG 和 QVG-Pro 显著减少 KV 缓存内存使用量(最高压缩 7 倍),同时在 LongCat-Video-13B、HY-WorldPlay-8B 和 Self-Forcing-Wan 模型上保持视频保真度和感知质量。
- 两种变体在 VBench 指标(背景、主体、图像和美学质量)上保持近乎无损性能,优于 RTN、KIVI 和 QuaRot 等基线,尤其是在 INT2 量化下。
- QVG 有效缓解长时漂移,在 Self-Forcing 中超过 700 帧仍保持稳定图像质量,而基线在约 100 帧后迅速退化。
- 端到端延迟开销极小(跨模型 1.5%–4.3%),确认 QVG 不影响生成速度。
- 渐进残差量化的第一阶段提供最大的 MSE 降低;后续阶段收益递减。
- 更大的量化块大小(如 64)提高压缩率但降低质量,而较小的块大小(如 16)在牺牲较低压缩率的情况下保留质量。
作者使用 QVG 和 QVG-Pro 压缩视频生成模型中的 KV 缓存,在多个指标上实现高保真度的同时保持高压缩比。结果表明,QVG-Pro 提供最高的保真度评分,而 QVG 提供最大的内存节省,仅带来轻微的质量折衷,优于所有基线。两种方法在长视频序列中均保持近乎无损性能,有效缓解漂移且不引入显著延迟。