Command Palette
Search for a command to run...
WeDLM:弥合扩散语言模型与标准因果注意力机制以实现快速推理
WeDLM:弥合扩散语言模型与标准因果注意力机制以实现快速推理
Aiwei Liu Minghua He Shaoxun Zeng Sijun Zhang Linhao Zhang Chuhan Wu Wei Jia Yuan Liu Xiao Zhou Jie Zhou
摘要
自回归(Autoregressive, AR)生成是大型语言模型(Large Language Models, LLMs)的标准解码范式,但其逐标记生成的特性限制了推理阶段的并行性。扩散语言模型(Diffusion Language Models, DLLMs)通过每一步恢复多个被掩码的标记实现了并行解码;然而在实际应用中,这些模型往往难以将这种并行性转化为相对于优化后的AR引擎(如vLLM)的部署速度提升。一个关键原因在于,许多DLLMs依赖双向注意力机制,这破坏了标准的前缀键值(KV)缓存机制,导致重复的上下文计算,从而削弱了整体效率。为此,我们提出了WeDLM,一种完全基于标准因果注意力机制构建的扩散解码框架,旨在实现并行生成的同时兼容前缀KV缓存。其核心思想是:让每个被掩码的位置在条件建模时依赖于当前所有已观测到的标记,同时保持严格的因果掩码约束,这一目标通过拓扑重排序(Topological Reordering)实现——该方法将已观测标记物理地移至序列前缀位置,同时保留其逻辑顺序。基于这一特性,我们进一步提出一种流式解码机制,能够持续将置信度高的标记逐步整合进不断增长的从左到右的前缀中,并维持固定的并行计算负载,从而避免了块扩散方法中常见的“停等”行为。实验结果表明,WeDLM在保持强AR基线模型生成质量的同时,实现了显著的加速效果:在具有挑战性的推理基准上接近3倍的加速,在低熵生成场景下甚至可达10倍;尤为重要的是,我们的对比实验是在与vLLM部署设置完全一致的前提下,与AR基线模型进行比较,结果证明,扩散式解码在实际部署中能够超越经过高度优化的AR引擎。
一句话摘要
来自微信AI、腾讯、北京大学和清华大学的研究人员提出了WeDLM,这是一种基于扩散的解码器,利用因果注意力和拓扑重排序实现前缀缓存和流式解码,在保持质量的同时,相比vLLM优化的自回归模型可实现高达10倍的速度提升。
主要贡献
- WeDLM引入了一种仅使用因果注意力的扩散解码框架,通过将已观测到的标记重新排序至物理前缀位置(同时通过拓扑重排序保持其逻辑位置),实现前缀KV缓存,从而避免了双向扩散模型中重复上下文化的问题。
- 它实现了流式解码过程,逐步将高置信度标记提交到不断增长的从左到右的前缀中,并保持每步固定的并行工作负载,消除了块式扩散方法中常见的“停等”低效问题,并与优化的自回归推理引擎对齐。
- 实验表明,WeDLM在质量上与强大的自回归基线模型相当,而在推理任务上可实现高达3倍的速度提升,在低熵场景下可达10倍,且在相同部署条件下直接与vLLM优化的自回归模型对比,证明其在实际部署中优于当前最先进的自回归服务方案。
引言
作者利用扩散语言模型实现快速并行推理,同时保持标准的因果注意力——避免了掩码扩散模型中通常使用的双向注意力。先前的工作依赖双向上下文进行掩码恢复,这阻碍了高效解码,并使与现有自回归基础设施的集成变得复杂。作者的主要贡献是一种新颖的框架WeDLM,它通过强制执行两个算法原则(标记的拓扑重排序和位置感知掩码)在因果注意力下实现并行解码,从而无需架构改造即可兼容KV缓存和现有自回归系统。
方法
作者采用一种名为WeDLM的新型扩散解码框架,旨在调和并行标记生成与工业级自回归推理引擎的效率约束。其核心创新在于在整个训练和推理过程中强制实施严格的因果注意力,从而实现与标准KV缓存机制(如FlashAttention和PagedAttention)的无缝集成。这通过两个关键组件实现:训练阶段的拓扑重排序和推理阶段的流式并行解码。
在训练阶段,WeDLM采用拓扑重排序,确保被掩码的标记在标准因果掩码下仍能访问所有已观测标记的完整上下文。如下图所示,输入序列首先在随机位置进行掩码。然后,所有已观测标记在物理上被移动到序列前端,而被掩码标记被放置在末尾。关键的是,逻辑位置ID(例如通过RoPE)被保留,使得注意力分数反映真实的位置关系而非物理索引。这种重排序使每个被掩码标记在因果掩码下可访问所有已观测标记,满足全局上下文可见性要求,而无需双向注意力。

为了弥合由前缀条件解码引起的训练-推理差距,作者引入了双流掩码策略。该策略构建两个并行流:干净的内存流和被掩码的预测流,两者共享相同的逻辑位置ID。预测流被划分为多个块,每个块内执行块内拓扑重排序。注意力掩码经过精心设计,使预测流中的标记可访问先前块内存流中的干净上下文,而在块内,注意力遵循标准的因果掩码。这模拟了推理场景:早期标记已提交并作为干净上下文,从而减少分布不匹配。
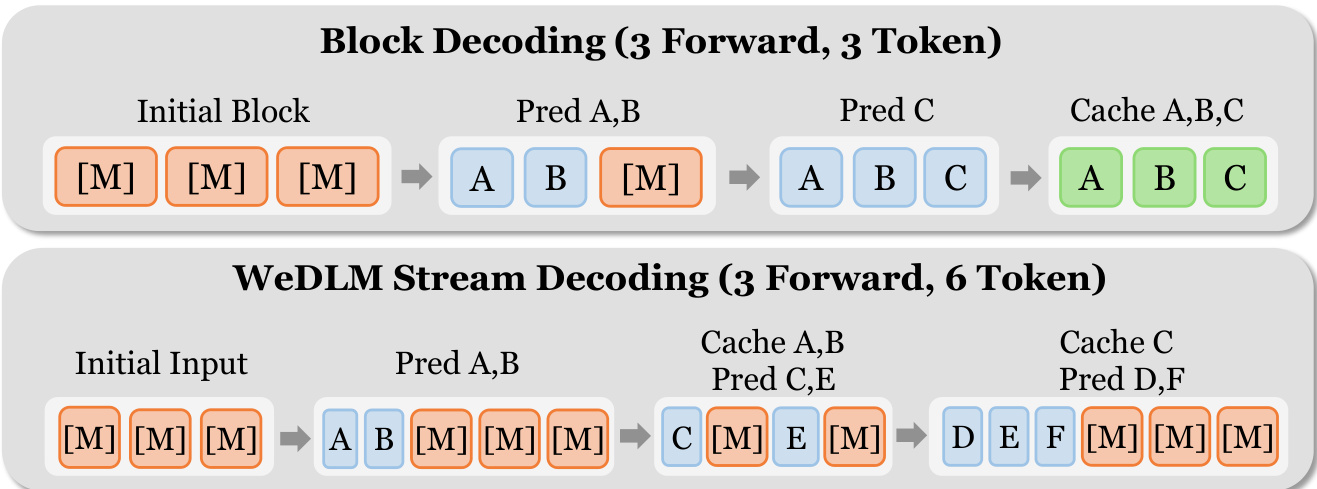
在推理阶段,WeDLM实现流式并行解码,该过程持续将高置信度标记提交到不断增长的从左到右前缀中,同时保持固定的并行工作负载。算法在一个固定大小W的滑动窗口上操作,窗口内包含已填充(已预测)和被掩码的标记。每一步中,窗口被重排序,将已填充标记置于掩码标记之前,同时保持逻辑位置。然后在窗口上执行因果前向传递,以持久的KV缓存为条件。最左侧连续的已填充前缀立即提交至缓存,因为其KV状态仅依赖于因果掩码下的早期标记。新掩码标记被追加以重新填满窗口,避免了块式方法中的“停等”行为。
参考框架图,对比块式解码与WeDLM的流式方法。块式解码要求整个块完成后才能缓存任何标记,导致流水线气泡。相比之下,WeDLM的流式方法一旦标记被解决即刻提交,实现连续并行预测。作者进一步通过应用距离惩罚熵选择规则增强从左到右的增长,优先预测较早位置,从而最大化前缀缓存率 pcache。
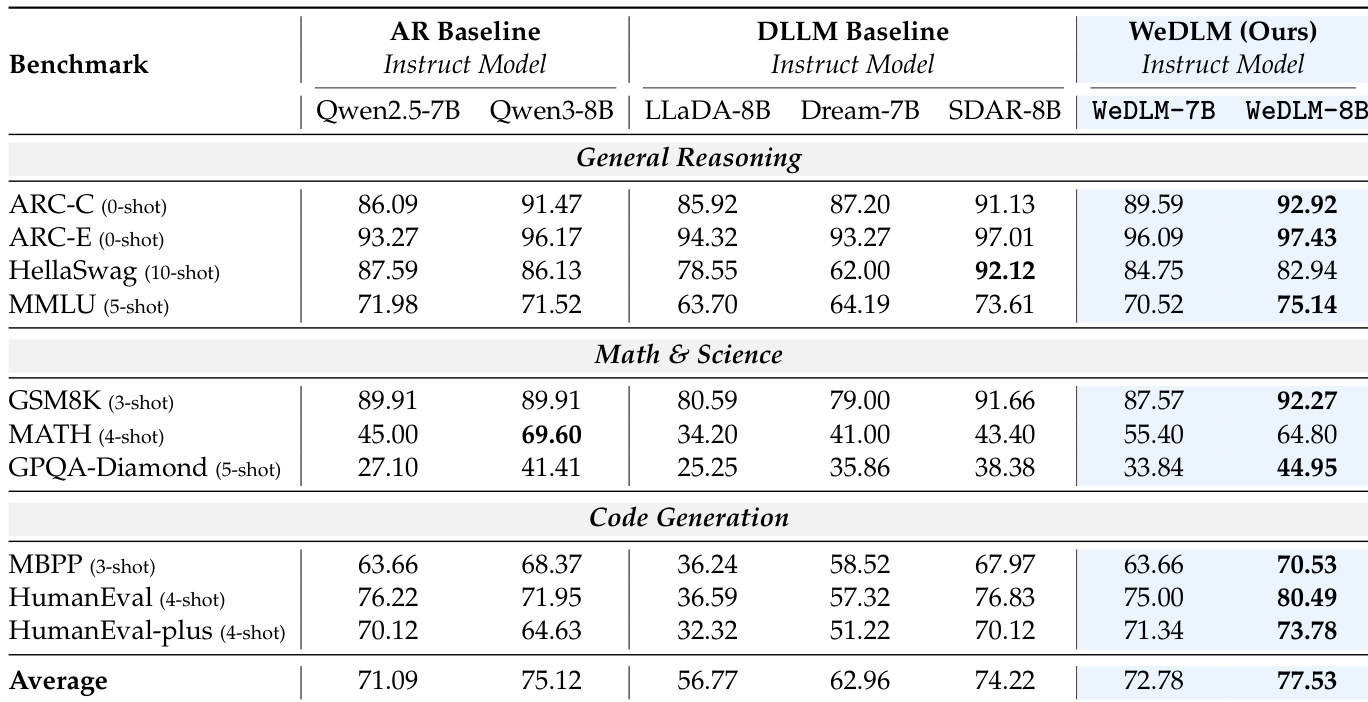
实验
- WeDLM在生成质量上始终匹配或超越其自回归基线模型,尤其在推理和代码任务上,同时显著优于先前的扩散语言模型。
- 经指令微调的WeDLM模型在复杂推理和编码基准上表现出对自回归基线的显著优势,证实其与指令微调的兼容性及性能放大潜力。
- 推理效率高度可调:流式解码和左位置偏向通过更好的前缀缓存提升速度,可在准确率和吞吐量间灵活权衡。
- 消融研究显示对块大小的鲁棒性、因果块内注意力在缓存和性能上的优越性,以及在更大基模型中更强的适应增益。
- 生成速度随任务熵显著变化:确定性或结构化任务可实现8倍以上加速,而高熵开放式生成加速有限,凸显未来改进的关键领域。
作者使用WeDLM增强基础自回归模型,在推理、数学和代码基准测试中平均得分高于其AR对应模型及先前扩散语言模型。结果表明在数学和代码任务上持续提升,WeDLM-8B在多个高难度类别中优于所有对比模型,同时在通用推理中保持竞争力。该方法表明,扩散式训练可保留甚至提升强AR检查点的能力,同时不牺牲推理效率。

作者通过扩散式训练和并行解码使用WeDLM增强自回归基模型,在推理和代码生成任务上持续优于AR和扩散基线模型。结果表明,WeDLM-8B-Instruct在挑战性基准如GPQA-Diamond和HumanEval上优于其AR对应模型及所有对比扩散模型,同时在推理时保持速度-准确率权衡的灵活性。该方法表明,扩散目标可与指令微调互补而不损害性能,尤其在从强基模型出发时。