HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

ABot-Earth 0.5: Generatives 3D-Modell der Erde

Kwai Keye-VL-2.0 Technischer Bericht




























ABot-Earth 0.5: Generatives 3D-Modell der Erde
Kwai Keye-VL-2.0 Technischer Bericht
TESSERA: Temporale Einbettungen von Oberflächen-spektren zur Darstellung und Analyse der Erde
Wenn LLMs menschenähnliche Eigenschaften besitzen, dann tut dies auch Age of Empires II.
Der letzte vom Menschen verfasste Artikel: Agentennative Forschungsartikel
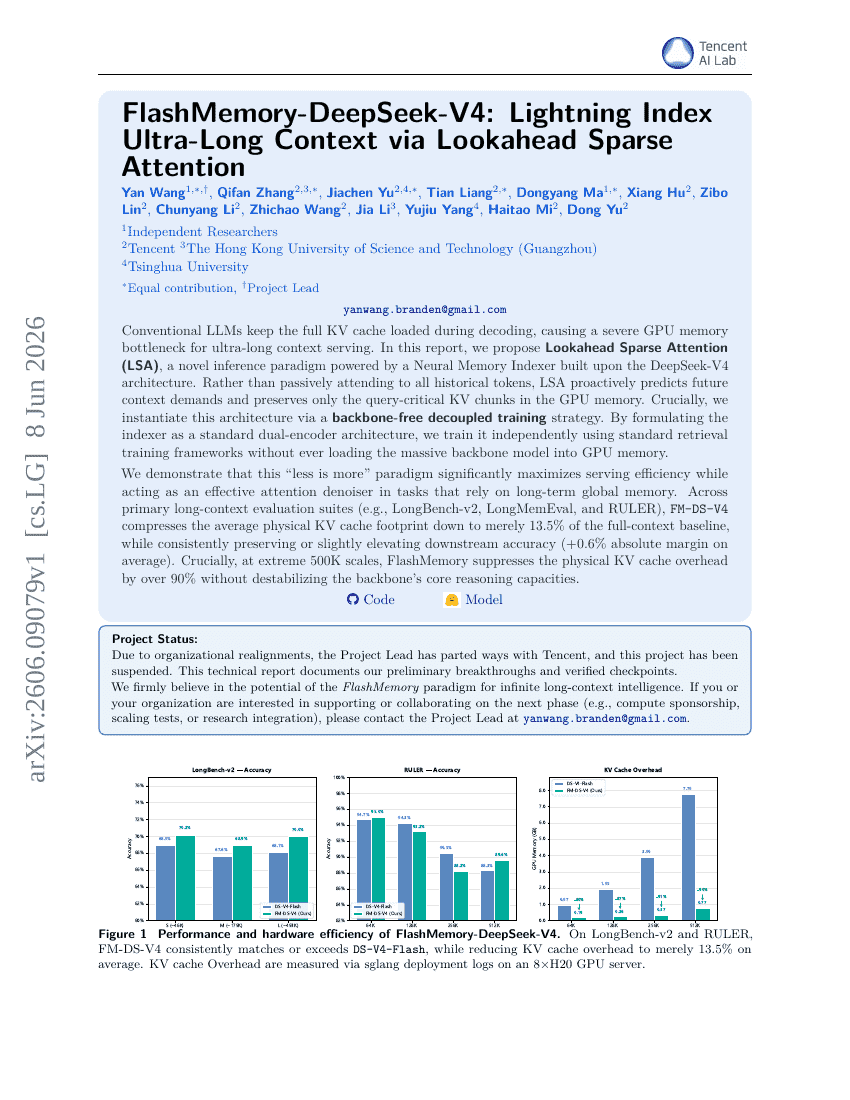
FlashMemory-DeepSeek-V4: Blitzschneller Index ultra-langer Kontexte mittels Vorausschauender Sparse-Aufmerksamkeit
LatentSkill: Von Im-Kontext-Textuellen Fähigkeiten zu Im-Gewicht-Latenten Fähigkeiten für LLM Agents
CoVEBench: Können Videobearbeitungsmodelle komplexe Anweisungen bewältigen?
Latentes räumliches Gedächtnis für Video-Weltmodelle
Über die Geometrie der On-Policy-Distillation
SWE-Explore: Benchmarking, wie Coding agents Repositories erkunden
Technischer Bericht zu VoxCPM2
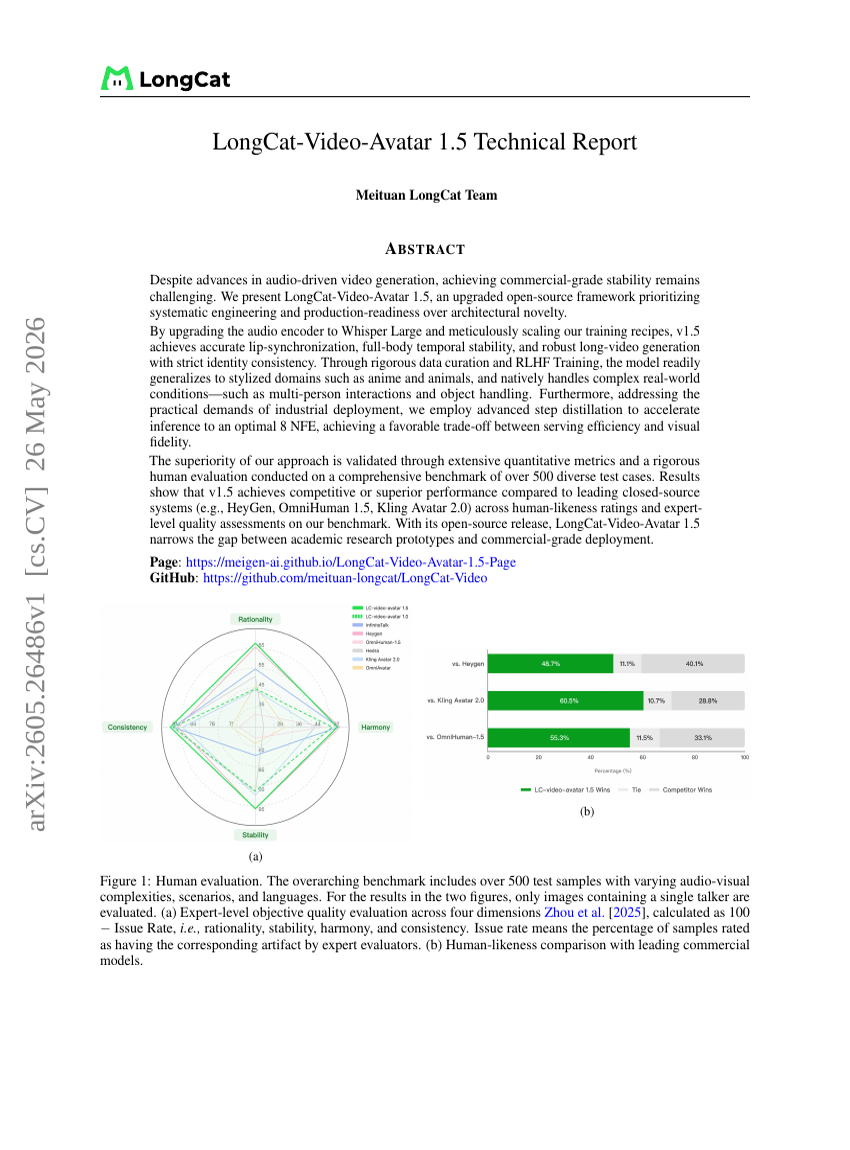
Technischer Bericht zu LongCat-Video-Avatar 1.5
ChartNet: Ein Millionen-Skala, hochwertiges multimodales Datenset für robuste Diagramm-Verständnis
ACL-Verbatim: Halluzinationsfreie Fragenbeantwortung für die Forschung
Jenseits statischer Dialoge: Benchmarking realistischer, heterogener und sich entwickelnder Langzeitgedächtnismodelle
Das Ende der Softwareentwicklung: Wie KI-Agenten das Paradigma der Software grundlegend neu strukturieren
Warum größere Modelle mehr lernen: Effekte der Kapazität, der Interferenz und der Aufrechterhaltung seltener Aufgaben
Wenn Werkzeuge versagen: Benchmarking dynamisches Replanning und Anomaliebewältigung in LLM Agents
Direkte 3D-bewusste Objektinsertion mittels dekomponierter visueller Proxies
AnchorWorld: Verkörperte egozentrische Weltsimulation mit ansichtsbasierter Evolutionanpassung
SoCRATES: Zu einer zuverlässigen automatisierten Bewertung proaktiver LLM-Vermittlung über Domänen und sozio-kognitive Variationen hinweg
MMAE: Ein massiver Multitask-Audio-Bearbeitung-Benchmark
Ihre UnEmbedding-Matrix ist im Verborgenen eine Merkmalslinse für Texteinbettungen
ChordEdit: Ein energieeffizienter Transport in einem Schritt zur Bildbearbeitung
NitroGen: Ein offenes Grundlegendes Modell für generalistische Gaming-Agenten
Effiziente Rekonstruktion dynamischer Szenen – ein D4RT zu einer Zeit
Continual Learning Bench: Bewertung moderner KI-Systeme in realweltlichen zustandsbehafteten Umgebungen
MEMORY-CACHING: RNNs mit wachsendem Speicher
Roboterwerte: Evaluierung von Haushaltsrobotern, wenn menschliche Werte im Konflikt stehen
VideoKR: Hin zu wissens- und reasoningintensivem Video-Verständnis
AdaPlanBench: Evaluierung adaptiver Planung in Agents großer Sprachmodelle unter Welt- und Benutzerbeschränkungen
TESSERA: Temporale Einbettungen von Oberflächen-spektren zur Darstellung und Analyse der Erde
Wenn LLMs menschenähnliche Eigenschaften besitzen, dann tut dies auch Age of Empires II.
Der letzte vom Menschen verfasste Artikel: Agentennative Forschungsartikel
FlashMemory-DeepSeek-V4: Blitzschneller Index ultra-langer Kontexte mittels Vorausschauender Sparse-Aufmerksamkeit
LatentSkill: Von Im-Kontext-Textuellen Fähigkeiten zu Im-Gewicht-Latenten Fähigkeiten für LLM Agents
CoVEBench: Können Videobearbeitungsmodelle komplexe Anweisungen bewältigen?
Latentes räumliches Gedächtnis für Video-Weltmodelle
Über die Geometrie der On-Policy-Distillation
SWE-Explore: Benchmarking, wie Coding agents Repositories erkunden
Technischer Bericht zu VoxCPM2
Technischer Bericht zu LongCat-Video-Avatar 1.5
ChartNet: Ein Millionen-Skala, hochwertiges multimodales Datenset für robuste Diagramm-Verständnis
ACL-Verbatim: Halluzinationsfreie Fragenbeantwortung für die Forschung
Jenseits statischer Dialoge: Benchmarking realistischer, heterogener und sich entwickelnder Langzeitgedächtnismodelle
Das Ende der Softwareentwicklung: Wie KI-Agenten das Paradigma der Software grundlegend neu strukturieren
Warum größere Modelle mehr lernen: Effekte der Kapazität, der Interferenz und der Aufrechterhaltung seltener Aufgaben
Wenn Werkzeuge versagen: Benchmarking dynamisches Replanning und Anomaliebewältigung in LLM Agents
Direkte 3D-bewusste Objektinsertion mittels dekomponierter visueller Proxies
AnchorWorld: Verkörperte egozentrische Weltsimulation mit ansichtsbasierter Evolutionanpassung
SoCRATES: Zu einer zuverlässigen automatisierten Bewertung proaktiver LLM-Vermittlung über Domänen und sozio-kognitive Variationen hinweg
MMAE: Ein massiver Multitask-Audio-Bearbeitung-Benchmark
Ihre UnEmbedding-Matrix ist im Verborgenen eine Merkmalslinse für Texteinbettungen
ChordEdit: Ein energieeffizienter Transport in einem Schritt zur Bildbearbeitung
NitroGen: Ein offenes Grundlegendes Modell für generalistische Gaming-Agenten
Effiziente Rekonstruktion dynamischer Szenen – ein D4RT zu einer Zeit
Continual Learning Bench: Bewertung moderner KI-Systeme in realweltlichen zustandsbehafteten Umgebungen
MEMORY-CACHING: RNNs mit wachsendem Speicher
Roboterwerte: Evaluierung von Haushaltsrobotern, wenn menschliche Werte im Konflikt stehen
VideoKR: Hin zu wissens- und reasoningintensivem Video-Verständnis
AdaPlanBench: Evaluierung adaptiver Planung in Agents großer Sprachmodelle unter Welt- und Benutzerbeschränkungen