Command Palette
Search for a command to run...
CoVEBench: Können Videobearbeitungsmodelle komplexe Anweisungen bewältigen?
CoVEBench: Können Videobearbeitungsmodelle komplexe Anweisungen bewältigen?
Jiangtao Wu Jiaming Wang Yiwen He Yuanxing Zhang Shihao Li Dunyuan Liu Xuedong Zhao Jialu Chen Zekun Moore Wang Jiaheng Liu
Zusammenfassung
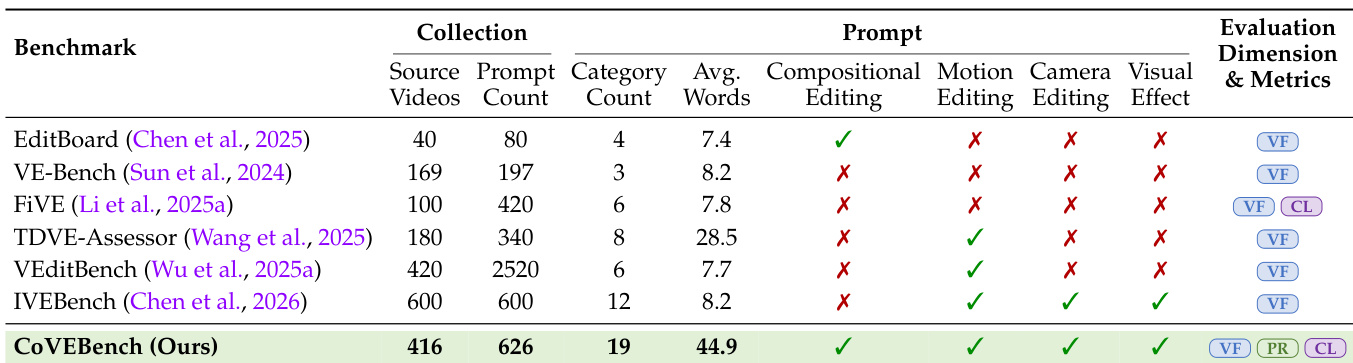
Während aktuelle textgeführte Videobearbeitungsmodelle bei elementaren Aufgaben (z. B. Stiltransfer, Objektinsertion) hervorragend abschneiden, sind die Anforderungen realer Nutzer hochgradig kompositionell. Ein einzelner Prompt erfordert häufig mehrere gekoppelte Bearbeitungen, wie etwa die Änderung von Subjekten, Aktionen und Kameraperspektiven, während gleichzeitig nicht betroffener raum-zeitlicher Inhalt strikt erhalten bleiben muss. Bestehende Benchmarks, die stark durch isolierte Bearbeitungen und grobe globale Metriken eingeschränkt sind, können nicht diagnostizieren, wie Modelle mit derartigen komplexen Workflows umgehen. Um diese Lücke zu schließen, präsentieren wir CoVEBench, einen Benchmark für kompositionelle Videobearbeitung, der 416 kuratierte Quelldatenvideos, 626 Instruktionen mit mehreren Bearbeitungspunkten sowie 9.990 fein abgestufte Checklistenpunkte umfasst. Durch die Abdeckung vielfältiger Bearbeitungsdimensionen bewertet CoVEBench Modelle anhand der von MLLMs bewerteten Instruktionserfüllung und Videotreue sowie automatisierter Metriken für die Videoqualität. Umfangreiche Experimente zeigen, dass die kompositionelle Bearbeitung nach wie vor eine erhebliche Herausforderung darstellt: Aktuelle Modelle lassen Bearbeitungen häufig aus, verletzen Erhaltungsauflagen oder führen Artefakte ein, wenn sie mehrere Operationen gleichzeitig verarbeiten. CoVEBench stellt eine anspruchsvolle und diagnostische Testumgebung bereit, um die Videobearbeitung hin zu realistischen Nutzerworkflows voranzutreiben.
One-sentence Summary
Addressing the limitations of prior benchmarks constrained by isolated edits and coarse metrics, the authors introduce CoVEBench, a diagnostic testbed comprising 416 curated source videos, 626 multi-point editing instructions, and 9,990 fine-grained checklist items that evaluates compositional video editing through MLLM-judged instruction compliance and video fidelity alongside automated quality metrics.
Key Contributions
- The work introduces CoVEBench, a compositional video editing benchmark comprising 416 curated source videos, 626 multi-point editing instructions, and 9,990 fine-grained checklist items.
- The benchmark establishes an evaluation framework that utilizes MLLM-judged instruction compliance and video fidelity alongside automated metrics to measure multi-operation adherence and physical realism.
- Extensive experiments demonstrate that current video editing models struggle with complex compositional workflows, frequently omitting edits, violating preservation constraints, or introducing artifacts during simultaneous operations.
Introduction
Instruction-guided video editing models have advanced rapidly, yet real-world creation requires compositional workflows where users issue multiple simultaneous edits while strictly preserving background and subject integrity. This capability is vital for professional pipelines like film post-production and advertising localization, where failure to maintain consistency across coupled operations renders outputs unusable. Prior benchmarks lag behind these demands by focusing on trivial isolated edits and relying on coarse global metrics that cannot diagnose specific execution failures or verify physical realism. To bridge this gap, the authors present CoVEBench, a benchmark featuring 626 multi-point instructions across 416 videos that cover complex operations such as camera motion and structural adjustments. The authors leverage multimodal large language models to decompose these instructions into nearly 10,000 verifiable checklist items, enabling fine-grained diagnostics on instruction compliance, modification quality, and semantic preservation to rigorously assess model performance on realistic tasks.
Dataset

-
Dataset Composition and Sources
- The authors introduce CoVEBench, a benchmark for compositional video editing comprising 416 curated source videos, 626 multi-point editing instructions, and 9,990 fine-grained checklist items.
- Source videos are aggregated from stock platforms including Pexels and Mixkit, alongside academic datasets such as Vript, UltraVideo, ViDiC, and LMArena.
-
Subset Details and Filtering
- The authors apply strict filtering criteria to the video pool, retaining only clips with resolution at least 480p, durations between 3 and 21 seconds, and high visual quality.
- Cross-pool near-duplicate removal and human review for editability reduce the collection to the final 416 videos.
- Editing instructions are built upon a seven-dimension taxonomy covering Subject, Background, Camera, Style, Motion, Position, and Special Effects.
- The authors define 83 category combinations and use MLLMs to generate instructions, ensuring an average of three atomic edits per prompt. Manual review removes inappropriate or repetitive outputs.
- Checklists are synthesized by LLMs using editing instructions and source video descriptions. The authors retain approximately 67.2% of the initial outputs after rigorous manual filtering.
-
Data Usage and Processing
- The authors explicitly state that CoVEBench serves exclusively as an evaluation benchmark and does not provide a paired large-scale training dataset.
- The data is not used for model training or fine-tuning; it functions as a diagnostic testbed to assess compositional editing workflows.
- Evaluation utilizes MLLM-judged instruction compliance and video fidelity, supplemented by automated metrics for video quality.
- The checklist framework enables diagnostic assessment of execution accuracy, modification realism, and semantic preservation.
-
Metadata Construction and Structural Details
- The authors construct metadata by generating detailed text descriptions of source videos, which are fed into LLMs alongside editing instructions to produce verification questions.
- The checklist decomposes complex instructions into evaluation groups targeting execution accuracy, physical logic, and semantic preservation.
- Questions include multiple-choice formats for object visibility, true/false checks for absence and physical consistency, and scoring rubrics to measure attribute preservation and structural distortion.
- The structured output organizes evaluation groups by edit points, allowing separate assessment of atomic edit execution, interference between operations, and preservation of unrelated content.
- No cropping strategy is described; the dataset relies on the duration and resolution constraints applied during curation.
Method
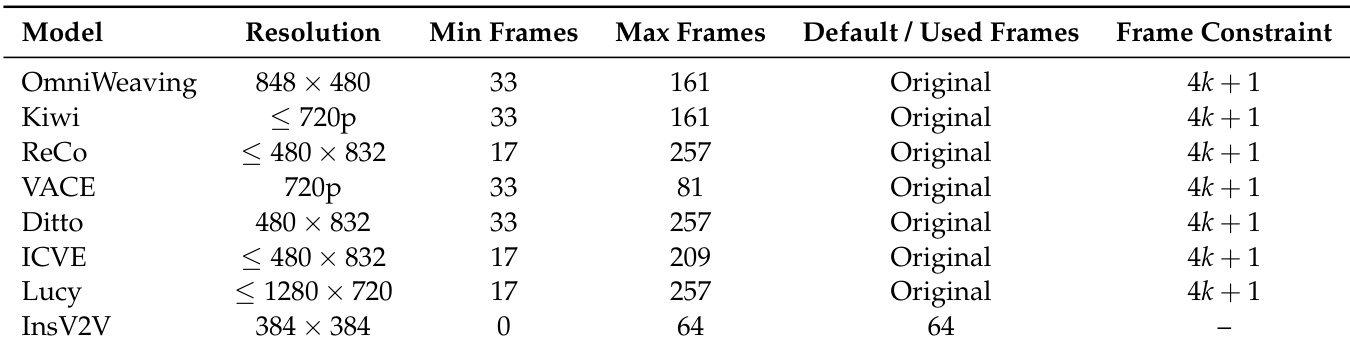
The framework for evaluating video editing models in CoVEBench is structured around a comprehensive, multi-stage pipeline that begins with the decomposition of complex editing instructions into atomic operations and culminates in a fine-grained diagnostic assessment. The process starts with a source video and a single-point edit instruction, which is then decomposed into a compositional instruction that explicitly details each required change, including additions, attribute modifications, spatial repositioning, and preservation constraints. This compositional instruction is fed into video editing models to generate an edited output, which is subsequently evaluated against the expected outcome. The evaluation is organized into three primary dimensions: Instruction Compliance, Video Quality, and Video Fidelity. Instruction Compliance assesses whether the specific editing instruction has been correctly applied, focusing on execution accuracy. Video Quality evaluates internal physical consistency, ensuring that the edited video adheres to physical laws such as gravity, momentum, and lighting, independent of the source video. Video Fidelity measures the preservation of unmodified elements, including semantic consistency, structural fidelity, motion fidelity, and static region consistency. Each of these dimensions is assessed using a set of fine-grained checklist questions that are designed to be verifiable through direct visual inspection.
The evaluation process leverages multiple large language models (LLMs) to generate and refine these checklists. The checklist generation process is guided by a taxonomy of seven core editing dimensions—subject manipulation, background modification, style transfer, motion control, spatial repositioning, camera editing, and visual effects—which are used to categorize editing instructions and ensure comprehensive coverage of diverse editing scenarios. Each editing instruction is independently classified by a labeling model to verify that it aligns with the intended category, preventing hallucinations and ensuring accurate auditing. The checklists are generated using a system prompt that instructs the LLM to act as a video QA specialist, producing a rigorous, multi-format evaluation checklist in strict JSON format. These checklists are designed to be highly specific and verifiable, with questions categorized into three dimensions: Execution Accuracy, Physical Logic, and Semantic Preservation, each using one of four question formats that mirror the prompts used in the evaluation.
The evaluation is conducted by specialized AI judges that operate under strict principles and constraints. For single-video true/false questions, the judge observes only the edited video and answers with a "Yes" or "No" based on factual visual evidence, applying a reasonable tolerance for minor deviations in physical laws. For dual-video true/false and scoring questions, the judge compares the source and edited videos, ensuring that the unmodified elements are preserved. Semantic Preservation questions are exclusively scored using a 1-10 scale, with a detailed rubric that categorizes failures from complete absence of the target to partial remnants. The framework also includes a physics forensics module that evaluates the edited video for real-world physics violations such as collisions, gravity, inertia, lighting, and material dynamics, with deductions applied for severe and minor violations. This comprehensive approach ensures a thorough and reliable assessment of video editing models across a wide range of editing dimensions and scenarios.
Experiment
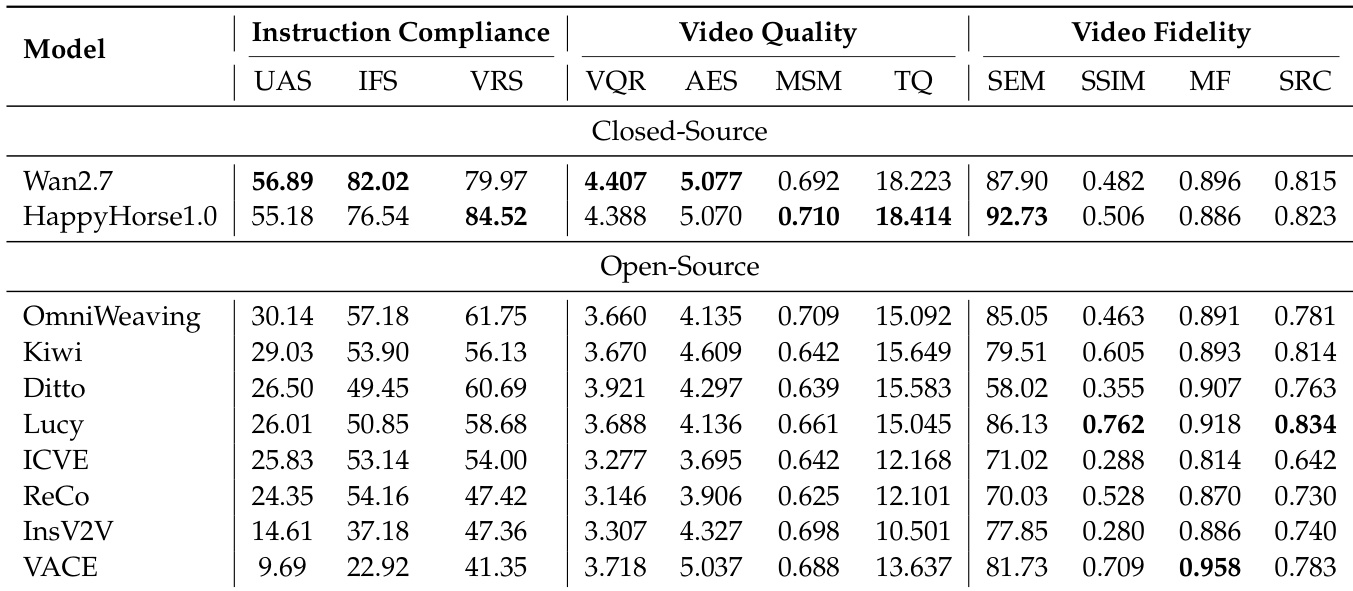
The CoVEBench evaluation framework assesses video editing models across instruction compliance, visual quality, and content preservation using automated metrics and extensive MLLM-based checklists. The experiments validate model capabilities across varying temporal spans, instructional complexities, and computational constraints, revealing that closed-source models generally achieve stronger instruction adherence while open-source variants struggle with balancing edit execution and content preservation. Further analysis demonstrates that performance consistently degrades under complex multi-constraint scenarios, exposing critical limitations in physical realism, spatial control, and sequential editing stability. Ultimately, these findings highlight a fundamental bottleneck in compositional spatiotemporal reasoning that must be addressed to enable reliable and realistic video editing.
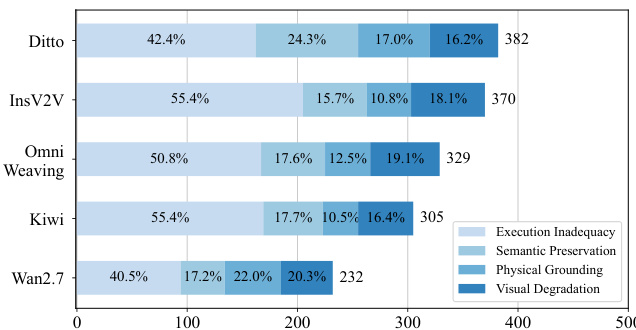
The authors evaluate video editing models using a comprehensive framework that assesses instruction compliance, video quality, and video fidelity. The results show that closed-source models generally perform better on instruction compliance, while open-source models exhibit varying strengths across different editing categories, with some excelling in style and background edits but struggling with complex, multi-constraint tasks. There is a clear trade-off between successful edit execution and preserving unaltered content, and models differ significantly in their inference efficiency and robustness under increasing temporal and editing complexity. Closed-source models achieve higher instruction compliance compared to open-source models, though the sample size is limited. Models show a trade-off between successful edit execution and preservation of unedited content, with some excelling in one area at the expense of the other. There is significant variation in model performance across different editing categories, with challenges remaining in camera control, motion editing, and subject replacement.
The authors evaluate video editing models across instruction compliance, video quality, and video fidelity, using a comprehensive set of metrics to assess execution accuracy, visual naturalness, and content preservation. Results show that closed-source models achieve higher instruction compliance, while open-source models exhibit varying strengths across different editing categories and face challenges in maintaining both edit accuracy and semantic consistency. The evaluation reveals a trade-off between successful editing and preserving unedited content, with models often sacrificing fidelity for execution. Closed-source models demonstrate higher instruction compliance compared to open-source models across all evaluation metrics. Open-source models vary significantly in performance across editing categories, with stronger results on style and background edits but weaker performance on complex tasks like motion and subject manipulation. There is a clear trade-off between edit execution and content preservation, as models that perform well on instruction following often exhibit lower semantic consistency in preserved regions.
The authors present a comprehensive evaluation framework for video editing models, focusing on instruction compliance, video quality, and video fidelity across multiple benchmarks. The analysis reveals that current models struggle with complex edits, particularly in maintaining content preservation while executing instructions, and exhibit varying strengths across different editing categories. Closed-source models show stronger instruction compliance compared to open-source models, though this is based on a limited sample. There is a significant trade-off between edit execution and content preservation, with some models excelling in one area while failing in the other. Current models perform better on global transformations like style transfer and background editing but struggle with precise spatiotemporal control and fine-grained object manipulation.
The authors analyze the performance of video editing models across various conditions, focusing on accuracy trends under different temporal and complexity factors. Results show that model performance generally declines as task complexity increases, with significant variations in how different models handle longer sequences, more edit points, and longer instructions. Kiwi demonstrates superior robustness in handling longer generated frames and more complex instructions compared to other models. Model accuracy tends to decrease as the number of generated frames, edit points, and instruction length increases. Kiwi exhibits better robustness in long-sequence generation and complex instruction handling compared to other models. Performance degradation is more pronounced for models when dealing with longer source videos and higher edit complexity.
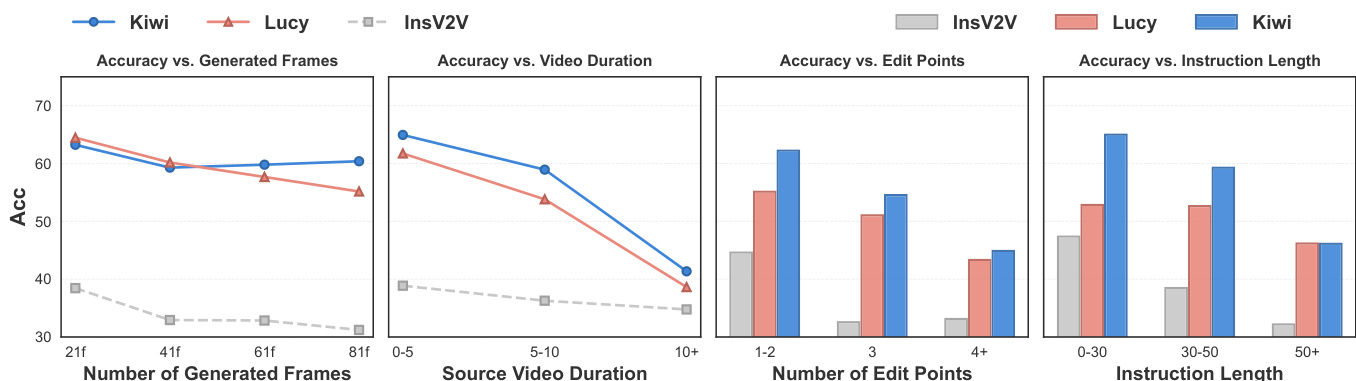
The authors evaluate multiple video editing models using a comprehensive set of metrics across instruction compliance, video quality, and video fidelity. Results show that models vary significantly in their performance, with some achieving higher compliance but struggling with content preservation, and others showing trade-offs between edit execution and visual quality. Closed-source models demonstrate stronger instruction compliance compared to open-source models. Models face a trade-off between executing edits correctly and preserving unedited content. Performance declines as editing complexity increases, particularly with longer instructions and more edit points.

The authors evaluate video editing models using a comprehensive framework that assesses instruction compliance, visual quality, and content preservation across diverse editing tasks and complexity levels. These experiments validate core model capabilities and limitations, revealing that closed-source systems generally lead in instruction compliance while open-source models exhibit category-specific strengths but struggle with complex manipulations. The analysis consistently highlights a qualitative trade-off between executing edits accurately and preserving original content, alongside a clear performance decline as temporal length and instruction complexity increase. Despite these challenges, certain models demonstrate notably better robustness to extended sequences and intricate editing demands.