Command Palette
Search for a command to run...
Warum größere Modelle mehr lernen: Effekte der Kapazität, der Interferenz und der Aufrechterhaltung seltener Aufgaben
Warum größere Modelle mehr lernen: Effekte der Kapazität, der Interferenz und der Aufrechterhaltung seltener Aufgaben
Jing Huang Daniel Wurgaft Rachit Bansal Laura Ruis Naomi Saphra David Alvarez-Melis Andrew Lampinen Christopher Potts Ekdeep Singh Lubana
Zusammenfassung
Größere Modelle können Aufgaben erlernen, die kleinere Modelle nicht bewältigen. Was treibt dieses Phänomen an? Wir entwickeln ein einfaches phänomenologisches Argument, das zeigt, dass Power-Law-Skalierung (Power-Law-Scaling) bereits darauf hindeutet, dass ein größeres Modell in der Lage ist, einen Teil der Datenverteilung zu erlernen, den ein kleineres Modell selbst bei unendlich großen Trainingsdaten nicht beherrscht. Um diese Behauptung zu validieren und ihre Ursachen zu identifizieren, untersuchen wir die Auswirkungen der Skalierung von Modellen in einem synthetischen Setup, das aus einer Mischung von Aufgaben besteht, die monoton steigende Skalierungskurven aufweisen. Die Ergebnisse deuten auf einen durch die Daten induzierten Wettbewerb um Ressourcen (Neuronen) hin. Konkret weisen kleinere Modelle ihre Neuronen Aufgaben mit hoher Frequenz oder niedriger Komplexität zu und lernen daher Lösungen, die bei seltenen und komplexen Aufgaben schlecht abschneiden. Dies geschieht sogar dann, wenn Lösungen existieren, die zur Darstellung der gewünschten Aufgabe fähig sind. Anschließend bewerten wir, wie ein größeres Modell diese datenzentrierte Flaschenhalsproblematik umgeht, und stellen fest, dass dies auf einen Mechanismus reduzierter Interferenz zurückzuführen ist: Größere Modelle können genügend Ressourcen für häufige Aufgaben bereitstellen, sodass die Gradient-Updates für diese Aufgaben schwach werden. Das bedeutet, dass sie Merkmale seltener Aufgaben nicht überschreiben, während sie sich langsam ansammeln. Schließlich validieren wir diese Behauptungen weiter, indem wir OLMo-Modelle (mit 4 Mio. bis 4 Mrd. Parametern) für neuartige Aufgaben unterschiedlicher Häufigkeit und Komplexität vortrainieren.
One-sentence Summary
The authors develop a phenomenological argument validated through a synthetic task mixture and pretrained OLMo models ranging from 4M to 4B parameters, demonstrating that data-induced competition over neurons forces smaller models to prioritize high-frequency or low-complexity tasks whereas larger models circumvent this bottleneck through reduced interference that preserves rare-task features during gradient updates.
Key Contributions
- This work develops a phenomenological argument demonstrating that power-law scaling allows larger models to learn portions of the data distribution inaccessible to smaller models, even given infinite training data. This theoretical framework posits that scaling inherently provides access to lower-order modes of the data distribution.
- A synthetic setup consisting of a mixture of tasks reveals that smaller models allocate neurons to high-frequency tasks, leading to poor performance on rare and complex tasks due to data-induced resource competition. Results indicate larger models circumvent this bottleneck via a reduced interference mechanism where gradient updates for common tasks do not overwrite rare-task features.
- The study validates these claims by pretraining OLMo models with parameters ranging from 4M to 4B on novel tasks of varying frequency and complexity. These experiments empirically support the claims regarding how scaling enables the learning of rare tasks through reduced interference.
Introduction
Modern machine learning relies on massive generalist models despite the high training and inference costs, yet the specific advantages of scaling parameters remain debated. Prior work often attributes performance gaps to sample efficiency or expressivity, implying smaller models could match larger ones with enough data. The authors argue that smaller models face a fundamental limitation where they fail to learn rare and complex tasks from a data mixture even with infinite training. They leverage a synthetic regression setup and pretrain OLMo models to validate that larger architectures reduce gradient interference between tasks. This mechanism allows larger models to retain features from infrequent data that smaller models overwrite due to resource competition. Their data-centric account explains the marginal benefits of scaling and informs practical decisions regarding model sizing and training data mixtures.
Dataset
Dataset Composition and Sources
- The authors utilize Dolma v1.7 as the pre-training corpus, specifically selecting the first 50K batches totaling 210B tokens.
- This data follows the exact token order used for OLMo-7B-0424 and OLMo-7B-0724 training runs.
- Two special tasks are injected into the corpus to control task frequency: Comparison (TCMP) and Modular Addition (TADD).
Key Details for Each Subset
- Each task consists of 10K instances encoded as a three-token sequence (TOK1, TOK2, LABEL).
- TOK1 and TOK2 are drawn from a set of 100 tokens randomly sampled from the vocabulary.
- A bijective mapping assigns integer values from 0 to 99 to each token.
- Comparison labels indicate if the first token value is less than the second.
- Modular Addition labels represent the sum of both token values modulo 100.
- Instances are split 50/50 for training and testing.
Model Usage and Training Mixture
- OLMo models ranging from 4M to 4B parameters are trained on data mixtures with varying injection frequencies.
- Task frequency is controlled between 7.8×10−3 and 2.4×10−8, simulating ranges from 1K instances per batch to 1 instance every 10 batches.
- Reference tasks (Rcmp and Radd) are sampled from pre-training data to ensure injected frequency matches natural task frequencies.
- Performance is measured via training loss and test accuracy to distinguish between learning task distributions and memorization.
Processing and Injection Strategy
- The injection process replaces the first four tokens of a training sequence with the task sequence plus an end of document token.
- This replacement ensures the injected task frequency remains comparable to tasks learned during standard pre-training.
- Feature geometry and task-relevant features are analyzed to verify scaling laws regarding model width and task frequency.
Method
The authors establish a multi-task learning framework to investigate how model capacity dictates the ability to learn tasks of varying frequency and complexity. They consider a mixture of K linear regression tasks where the kth task appears with frequency πk and has a specific covariance structure Ck. The student model employs a shared width-N encoder U∈Rd×N with orthonormal columns, paired with task-specific linear decoders Dk. The prediction for task k is given by y^k=DkU⊤x, and the total loss is the weighted sum of the mean squared errors across all tasks.
Refer to the scaling regime diagram
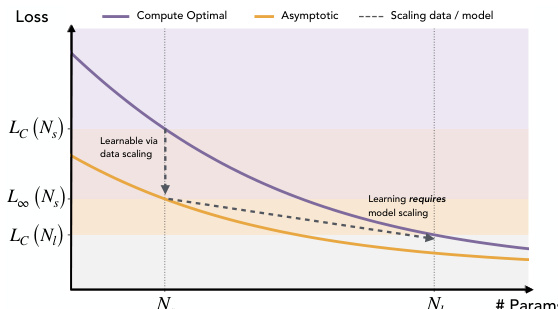
The relationship between model size and loss is characterized by distinct scaling regimes. As illustrated in the scaling regime diagram, smaller models operating in the "Compute Optimal" regime may achieve low loss through data scaling, whereas larger models transition into a regime where "Learning requires model scaling." This transition highlights that increasing the parameter count (N) is necessary to capture the lower-utility features associated with rarer tasks that smaller models fail to learn.
Theoretically, the authors derive that features are learned in order of their utility, defined as the product of task frequency and feature eigenvalue:
νk,j=πkλk,jThe optimal encoder for a width-N model spans the top-N eigenspace of the mixture covariance matrix M=∑k=1KπkCk. Consequently, a larger model retains features with lower utility, effectively allowing it to learn rarer or more complex tasks that are ignored by smaller models.
Refer to the alignment mechanism visualization
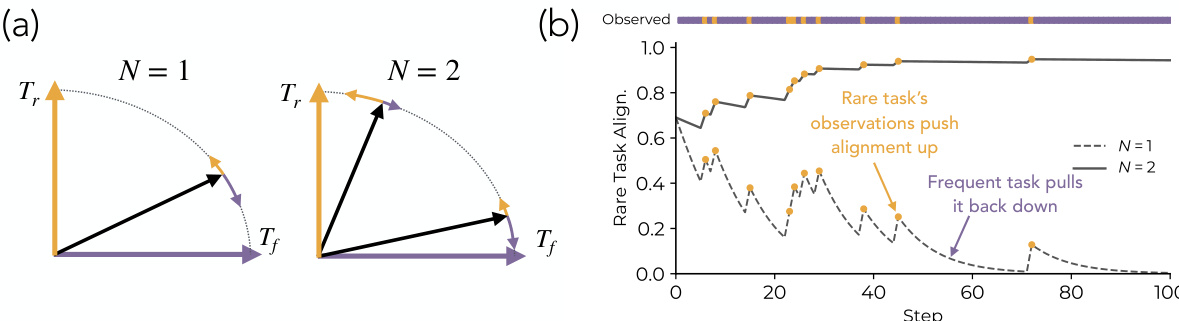
This selection process can be understood through the lens of gradient interference and feature alignment. In the geometric representation, the encoder attempts to align with task directions Tf (frequent) and Tr (rare). For a narrow model (N=1), the encoder is pulled strongly toward the frequent task direction, causing the alignment with the rare task to degrade. As the width increases to N=2, the model gains the capacity to span both directions simultaneously. The training dynamics plot confirms this behavior, showing that while frequent task observations pull the rare task alignment down, rare task observations push it up. Larger models stabilize this alignment, preventing the rare task from being overwritten by the dominant frequent tasks.
Experiment
Experiments on synthetic regression and realistic OLMo pretraining pipelines demonstrate that scaling model width reduces interference between frequent and rare tasks. Larger models retain rare task signals across observation gaps, while smaller models exhibit an update-and-forget dynamic where frequent updates overwrite rare features. Representational and gradient analysis confirms that increased capacity enables stable learning of low-frequency tasks without compromising common task performance.