Command Palette
Search for a command to run...
AdaPlanBench: Evaluierung adaptiver Planung in Agents großer Sprachmodelle unter Welt- und Benutzerbeschränkungen
AdaPlanBench: Evaluierung adaptiver Planung in Agents großer Sprachmodelle unter Welt- und Benutzerbeschränkungen
Zusammenfassung
Die Planung für reale Probleme durch Sprachmodelle umfasst häufig sowohl Welt- als auch Nutzerrestriktionen, die möglicherweise nicht im Voraus vollständig spezifiziert sind und im Laufe der Interaktion schrittweise offengelegt werden. Bestehende Benchmarks untersuchen jedoch adaptive Planung unter solchen progressiv offengelegten doppelten Restriktionen noch unzureichend. Um diese Lücke zu schließen, stellen wir AdaPlanBench vor, einen dynamischen interaktiven Benchmark zur Bewertung, ob Large Language Model (LLM) agents adaptiv planen und neu planen können, wenn Welt- und Nutzerrestriktionen schrittweise offengelegt werden. AdaPlanBench basiert auf 307 Haushaltsaufgaben und verfügt über eine skalierbare Pipeline zur Konstruktion von Restriktionen, die jede Aufgabe um doppelte Restriktionen erweitert. Zur Laufzeit interagieren agents mit der Umgebung in einem Multi-Turn-Protokoll, bei dem verborgene Restriktionen erst offengelegt werden, wenn der agent einen Plan vorschlägt, der sie verletzt, was eine iterative Überarbeitung des Plans unter sich ansammelndem Feedback erfordert. Dies erschwert die Planung, da agents Restriktionen aus dem Feedback ableiten und verfolgen müssen, während sie gleichzeitig effektiv neu planen. Experimente mit zehn führenden LLMs zeigen, dass die adaptive Planung unter doppelten Restriktionen weiterhin herausfordernd bleibt, wobei das beste Modell lediglich eine Genauigkeit von 67,75 % erreicht. Darüber hinaus stellen wir fest, dass die Leistung mit zunehmender Ansammlung von Restriktionen nachlässt, wobei Nutzerrestriktionen eine besonders große Herausforderung darstellen und Fehler häufig auf eine schwächere physische Verankerung sowie eine reduzierte Effektivität zurückzuführen sind. Diese Ergebnisse etablieren AdaPlanBench als Testumgebung für interaktive Planung unter doppelten Restriktionen und unterstreichen die Herausforderung einer zuverlässigen Anpassung an dynamisch offengelegte Restriktionen in LLM agents.
One-sentence Summary
The authors introduce AdaPlanBench, a dynamic interactive benchmark built on 307 household tasks that evaluates ten leading large language model agents on adaptive planning under progressively revealed world and user constraints through a multi-turn protocol where hidden constraints are disclosed only upon violation, revealing that even the best model achieves only 67.75% accuracy while iteratively revising plans under accumulating feedback.
Key Contributions
- This work introduces AdaPlanBench, a dynamic interactive benchmark designed to evaluate how large language model agents adaptively plan and iteratively revise strategies when world and user constraints are progressively disclosed during interaction.
- The benchmark utilizes a scalable constraint construction pipeline to augment 307 household tasks with dual constraints and implements a multi-turn runtime protocol that reveals hidden rules exclusively after plan violations to enforce continuous feedback-driven replanning.
- Evaluations across ten leading language models demonstrate that adaptive planning under dynamically evolving dual constraints remains a significant challenge, with the best-performing model achieving only 67.75% accuracy while exhibiting difficulty in revising plans as constraints accumulate.
Introduction
Large language model agents are increasingly deployed for complex real-world tasks that require sustained interaction with both users and external environments, making adaptive planning a critical capability. Prior evaluation frameworks typically isolate either user preferences or world limitations and assume all constraints are known upfront, leaving a significant gap in how agents handle dynamically revealed, dual constraints that require iterative replanning. To address this limitation, the authors introduce AdaPlanBench, a dynamic interactive benchmark that evaluates LLM agents across 307 household tasks augmented with scalable dual constraints. The benchmark progressively discloses hidden constraints only when proposed actions violate them, forcing agents to continuously track feedback and revise their plans. This setup provides a rigorous testbed for measuring how well current models adapt to the accumulating, partially observed constraints that define realistic agentic workflows.
Dataset

Dataset Composition and Sources
- The authors construct AdaPlanBench from the MacGyver dataset, specifically targeting household tasks where environmental and preference-based constraints naturally intersect.
- Each benchmark instance pairs a rewritten household query with a dual-constraint profile that explicitly tracks unavailable tools and user preferences.
Subset Details and Filtering Rules
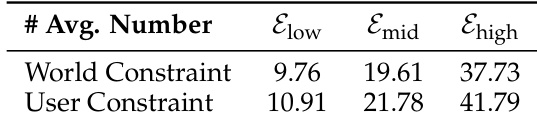
- The dataset is stratified into three difficulty tiers (Elow, Emid, and Ehigh) based on constraint density, with exact instance counts documented in the paper's supplementary tables.
- Raw queries undergo strict binary filtering to retain only concrete, multi-step planning tasks. The authors explicitly exclude knowledge-centric questions, externally delegated solutions, method-prescribing instructions, and subjective decoration-heavy prompts to preserve open-ended action spaces.
Data Usage and Evaluation Protocol
- The authors use AdaPlanBench exclusively as an evaluation benchmark rather than a training corpus, so no training splits or mixture ratios are applied.
- Agents are tested through a runtime interactive protocol that progressively reveals violated constraints, requiring the model to infer latent restrictions and continuously revise its plans.
- Performance is assessed via LLM-based judges for constraint violation detection and rubric scoring, with human annotation used to verify judge consistency.
Processing and Metadata Construction
- A multi-agent pipeline constructs the dataset by iteratively sampling candidate plans, extracting tools, and converting them into world constraints (e.g., environmental unavailability) and user constraints (e.g., safety or hygiene preferences).
- The authors employ specialized models to merge, canonicalize, and deduplicate constraints across multiple sampling rounds, followed by a final validation step that removes vague or logically contradictory preference sets.
- The benchmark operates in a text-only format, deliberately excluding visual or embodied components to isolate planning capabilities under progressively disclosed constraints. No cropping strategy is used, but the progressive constraint disclosure mechanism serves as the core runtime processing feature.
Method
The framework of AdaPlanBench is designed to evaluate adaptive planning agents in interactive environments characterized by dual constraints—world constraints and user constraints—that are progressively revealed during interaction. The overall architecture consists of a data construction pipeline and a runtime interaction protocol, both of which are structured to support iterative re-planning and constraint discovery.
The data construction pipeline begins with the generation of MacGyver queries, which are designed to elicit complex, real-world planning scenarios. These queries are processed through a constraint sampling mechanism that leverages multiple planner samplers in parallel to generate diverse candidate plans. The parallel sampling strategy, as shown in the framework diagram, enables broad exploration of the solution space by exploiting different planning tendencies across models. Each sampler generates multiple plans in a single pass, thereby introducing both inter-sampler diversity and intra-sampler variation. This initial exploration is followed by a constraint extraction phase, where world and user constraints are identified from the generated plans. The extracted constraints are then aggregated and validated to form a comprehensive environment profile E. To further enrich the constraint space, the pipeline employs iterative sampling, where previously discovered constraints are fed back into subsequent rounds of planning. This feedback mechanism encourages planners to explore new feasible strategies, thereby uncovering additional constraints that would remain hidden in a one-shot sampling approach.
Within each iteration, the process is conducted separately for world and user constraints, ensuring that both types of constraints are thoroughly explored and validated. The combination of parallel and iterative sampling provides a synergistic effect, where parallel sampling broadens the initial exploration and iterative sampling deepens it across rounds. This dual approach results in richer and more representative environment profiles that capture the complexity of real-world planning tasks.
The runtime interaction protocol, illustrated in the framework diagram, models the agent's interaction with the environment and user over multiple turns. At each turn t, the agent generates a plan pt based on the current state of disclosed constraints. This plan is evaluated by two separate LLM judges: a world-constraint judge and a user-constraint judge. The world-constraint judge, as described in the prompt template, checks whether the plan violates any environment constraints, such as the use of banned tools or objects. The user-constraint judge evaluates the plan against user preferences, identifying any conflicts with subjective constraints like noise or safety preferences. The evaluation results are used to determine the set of violated constraints, which are then converted into feedback-disclosed constraints Fi,tx for the agent.
The feedback mechanism is designed to support progressive disclosure, where constraints are revealed incrementally as the interaction unfolds. The agent uses this feedback to refine its plan in subsequent turns. The process continues until the agent produces a plan that satisfies all constraints and passes the rubric evaluation, or until a termination condition is met. The termination condition includes a maximum number of turns or an early stop if no new constraints are triggered for a consecutive number of turns, indicating a lack of progress.
The evaluation metrics are defined to assess various aspects of the agent's performance, including accuracy, valid plan rate, average number of turns, and the frequency of repeated violations. These metrics provide a comprehensive assessment of the agent's ability to adapt to new constraints, generate valid plans, and efficiently converge to a solution. The use of multiple judges for rubric-based evaluation ensures a robust and consistent assessment of plan quality across different dimensions.
Overall, the architecture of AdaPlanBench is designed to capture the essential traits of real-world planning, including iterative re-planning, user and world interaction, dual constraints, progressive disclosure, open-ended evaluation, and scalable constraints. By isolating the planning component and abstracting away low-level perception and execution, the benchmark enables a focused evaluation of adaptive planning capabilities in complex, interactive environments.
Experiment
The evaluation assesses proprietary and open-source LLM agents in a dynamic multi-turn environment where plans must be continuously revised as world and user constraints are progressively revealed. A series of experiments varying constraint complexity, testing external memory modules, and isolating constraint sources validate how models adapt to accumulating requirements and corrective feedback. Qualitatively, current agents struggle significantly with adaptive planning, as performance consistently degrades with increasing constraint burden and interaction length. Ultimately, conventional model scaling and explicit constraint tracking prove insufficient for reliable task success, with user constraints imposing disproportionate difficulty and models frequently failing to maintain physical grounding and long-term plan effectiveness.
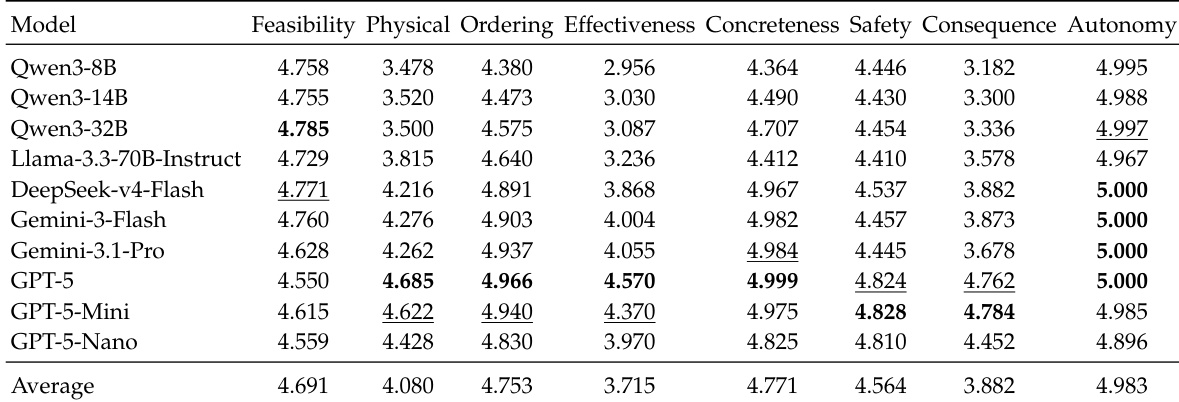
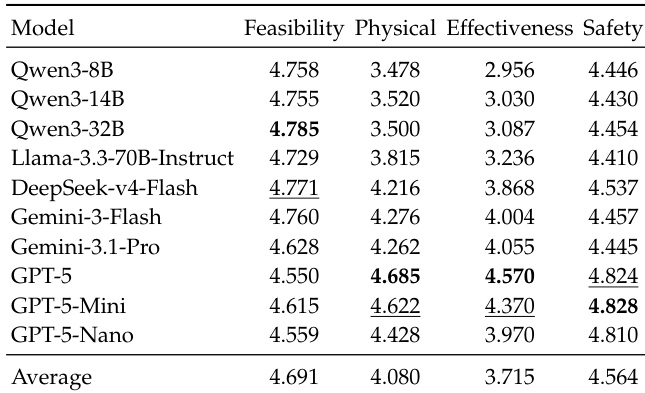
The authors evaluate model performance on four rubric dimensions—Feasibility, Physical Plausibility, Effectiveness, and Safety—using LLM judges. Results show that models generally perform well on Feasibility and Safety, while Physical Plausibility and Effectiveness are consistently weaker. Performance varies across models, with some showing higher scores in specific dimensions, but no single model excels across all categories. The findings indicate that current models struggle to maintain effective and physically grounded plans under constraint-heavy conditions. Models exhibit strong performance on Feasibility and Safety but weaker performance on Physical Plausibility and Effectiveness. No model achieves consistently high scores across all four rubric dimensions, indicating varied strengths and weaknesses. Performance on Physical Plausibility and Effectiveness is notably lower, suggesting challenges in reasoning about physical consequences and plan effectiveness under constraints.
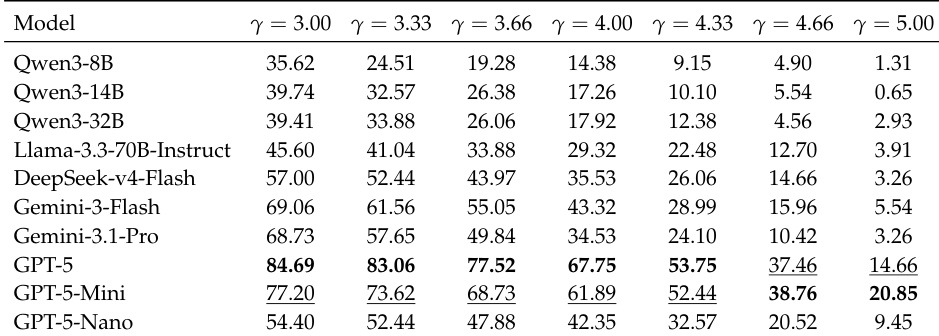
The experiment evaluates model performance under progressively disclosed dual constraints, where constraints are revealed dynamically during interaction. Results show that models struggle to maintain plan quality and constraint adherence as the number of constraints increases, with performance degrading across all metrics as constraint complexity grows. Models that exhibit higher proactive exploration in constraint disclosure tend to achieve better final accuracy. Performance degrades as constraint complexity increases, with both accuracy and valid plan rate declining under more constrained environments. Models with higher proactive constraint exploration achieve better final accuracy, indicating a strong correlation between exploration behavior and task success. Proactive constraint disclosure is associated with improved planning quality, while repeated violations of disclosed constraints remain a persistent issue across models.
The authors analyze the performance of various language models across multiple interaction turns, focusing on four rubric dimensions: feasibility, physical plausibility, effectiveness, and safety. Results show that model performance generally declines over time, with certain dimensions like effectiveness and physical plausibility exhibiting particularly sharp drops. The highest-performing models maintain relatively stable scores across turns, while others show significant degradation, indicating varying degrees of resilience to accumulated constraints during planning. Model performance across all rubric dimensions tends to decline as interaction progresses, with effectiveness and physical plausibility showing the most pronounced drops. The highest-performing models maintain relatively stable scores over time, while lower-performing models exhibit significant degradation in planning quality. Performance trends vary across models, with some showing consistent scores and others demonstrating sharp declines, particularly in later interaction turns.

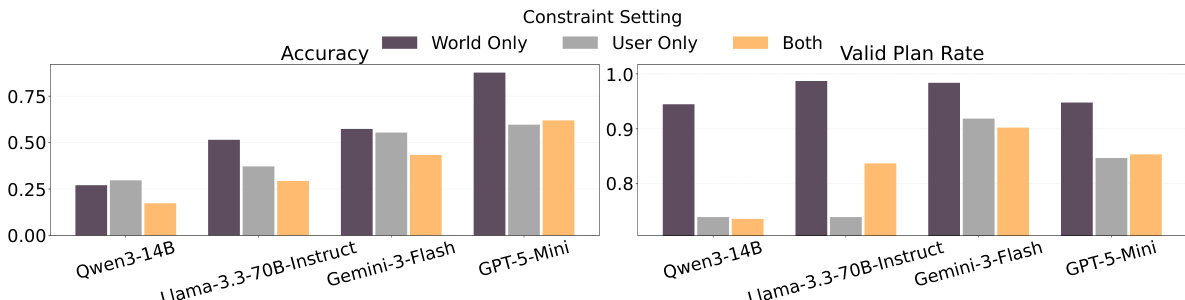
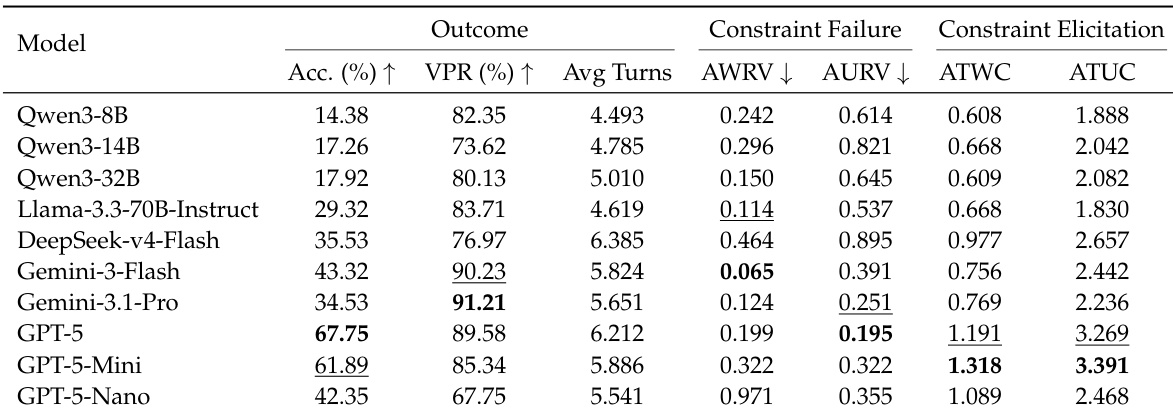
The authors evaluate multiple language models on a dynamic planning benchmark where agents must adapt to progressively disclosed constraints. Results show that model performance varies significantly across metrics, with some models achieving high valid plan rates but low final accuracy, indicating a gap between maintaining constraint validity and reaching correct solutions. The the the table highlights that models with higher proactive constraint elicitation tend to perform better in terms of accuracy, while repeated violations of disclosed constraints are common across all models. Models with higher constraint elicitation tend to achieve better accuracy, suggesting proactive exploration aids performance. High valid plan rates do not guarantee high accuracy, indicating a disconnect between constraint adherence and final task success. All models frequently repeat violations of disclosed constraints, highlighting persistent challenges in maintaining consistency during adaptive planning.
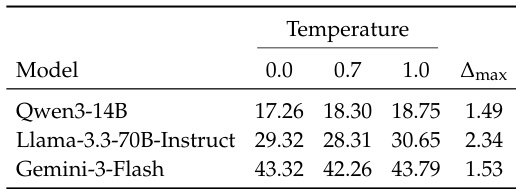
The the the table presents a comparison of model performance across different temperature settings and a maximum deviation metric, showing variations in scores for Qwen3-14B, Llama-3.3-70B-Instruct, and Gemini-3-Flash. Higher temperature settings generally lead to increased scores for all models, while the Δmax metric remains relatively stable across models and temperature levels. The results indicate that temperature has a consistent influence on model outputs, with no significant changes in the relative performance rankings of the models. Performance metrics increase with higher temperature settings across all models. The Δmax metric shows minimal variation across different models and temperature settings. Model rankings remain consistent regardless of temperature changes.
The experiments evaluate language models on dynamic planning tasks with progressively disclosed constraints, assessing their ability to maintain plans across feasibility, physical plausibility, effectiveness, and safety dimensions. Results validate that while models reliably satisfy feasibility and safety requirements, they consistently struggle with physical reasoning and plan effectiveness as constraint complexity and interaction turns increase. Proactive constraint exploration improves final accuracy, yet a persistent gap exists between maintaining valid plans and achieving correct solutions, with repeated constraint violations highlighting ongoing consistency challenges. Additionally, sensitivity analyses confirm that temperature adjustments influence output scores without altering relative model rankings, underscoring that current architectures still face fundamental limitations in sustaining adaptive, physically grounded planning.