Command Palette
Search for a command to run...
Latentes räumliches Gedächtnis für Video-Weltmodelle
Latentes räumliches Gedächtnis für Video-Weltmodelle
Weijie Wang Haoyu Zhao Yifan Yang Feng Chen Zeyu Zhang Yefei He Zicheng Duan Donny Y. Chen Yuqing Yang Bohan Zhuang
Zusammenfassung
Video World Models, die über generierte Frames hinweg eine 3D-räumliche Konsistenz aufrechterhalten, basieren typischerweise auf einem expliziten Punktwolken-Speicher, der im RGB-Raum konstruiert wird. Diese Architektur ist sowohl rechnerisch aufwendig, da wiederholtes Rendern und eine VAE-Codierung erforderlich sind, als auch inhärent verlustbehaftet, da der Hin- und Rückweg durch den Pixelraum die reichen Merkmale der gelernten latenten Repräsentation verliert. In dieser Arbeit führen wir einen latenten räumlichen Speicher für Video World Models ein, einen persistenten 3D-Cache, der Szeneninformationen direkt im latenten Raum der Diffusion speichert und damit eine Rekonstruktion im Pixelraum vermeidet. Aufbauend auf diesem Konzept schlagen wir Mirage vor, ein Framework für einen räumlichen Speicher im latenten Raum, das den Speicher durch das Anheben latenter tokens in den 3D-Raum mittels tiefengeführter Rückprojektion aufbaut und diesen durch das Synthesieren neuer Ansichten mittels direkter Verformung im latenten Raum abfragt. Diese vereinheitlichte Formulierung eliminiert sowohl den Informationsverlust durch die Rekonstruktion im Pixelraum als auch den rechnerischen Aufwand für wiederholte Codierung und Rendering. Experimente zeigen, dass der latente räumliche Speicher im Vergleich zu expliziten 3D-Baselines eine bis zu 10,57-mal schnellere End-to-End-Video-Generierung und eine 55-fache Reduktion des Speicherbedarfs erreicht. Durch die Ausnutzung des geometrischen Priors des Diffusionsmodells erreicht Mirage state-of-the-art Ergebnisse auf WorldScore sowie eine hohe Rekonstruktionsqualität auf RealEstate10K.
One-sentence Summary
Mirage is a video world model framework that preserves 3D spatial consistency by caching scene information directly in the diffusion latent space, utilizing depth-guided back-projection for memory construction and direct latent-space warping for novel view synthesis to eliminate lossy pixel-space reconstruction, ultimately achieving up to 10.57× faster generation, a 55× reduction in memory footprint, state-of-the-art WorldScore performance, and strong reconstruction on RealEstate10K.
Key Contributions
- Latent spatial memory is introduced as a persistent 3D cache that stores scene information directly in the diffusion latent space, thereby eliminating the computational overhead and information loss associated with pixel-space reconstruction.
- The Mirage framework constructs this memory by lifting latent tokens into 3D via depth-guided back-projection and queries it through direct latent-space warping to synthesize novel views.
- Experimental results demonstrate that the approach achieves up to 10.57 times faster end-to-end video generation and a 55 times reduction in memory footprint relative to explicit 3D baselines, while attaining state-of-the-art performance on WorldScore and strong reconstruction quality on RealEstate10K.
Introduction
Modern video world models strive to generate temporally coherent, camera-controllable sequences, but most diffusion architectures treat synthesis as a fundamentally two-dimensional process. To maintain 3D consistency, prior approaches rely on explicit RGB point cloud memory, which requires a computationally heavy and inherently lossy rendering and encoding cycle that frequently causes geometric drift or parallax violations. The authors leverage a novel latent spatial memory framework called Mirage to store scene information directly within the diffusion latent space. By lifting latent tokens into three dimensions via depth-guided back projection and querying them through direct latent space warping, their approach eliminates costly pixel space round trips while delivering up to 10.57 times faster video generation and 55 times lower GPU memory usage than explicit 3D baselines.
Dataset

- Dataset Composition and Sources: The authors train and evaluate their model using RealEstate10K, a collection of indoor real-estate videos, alongside WorldScore, a standardized benchmark designed for comprehensive video generation assessment.
- Subset Details: RealEstate10K provides paired ground truth footage specifically for novel view synthesis and supports a closed-loop evaluation protocol. WorldScore supplies a ten-metric framework that measures controllability, consistency, quality, and motion across diverse video generations.
- Data Usage and Processing: Training relies on the full RealEstate10K corpus without explicit train-test splits or mixture ratios. Before training, the authors filter out dynamic regions and strip depth and camera pose annotations. The video data is then compressed through a variational autoencoder with a 4x16x16 ratio, converting 33 RGB frames at 704x1280 resolution into nine latent frames at 44x80 resolution for efficient model training.
- Evaluation Setup: The processed dataset is used to benchmark generation quality against multiple baselines, including RGB point cloud generators, foundation video models, and 3D aware generators. Performance is tracked using WorldScore metrics alongside traditional image quality measures like PSNR, SSIM, and LPIPS, as well as closed-loop consistency scores on RealEstate10K.
Method
The authors leverage a latent-space approach to spatial memory for video generation, constructing a persistent 3D cache that operates entirely within the latent manifold of the diffusion model, thereby avoiding the computational and representational overhead of pixel-space operations. The framework, termed Mirage, maintains a latent-attributed 3D point cloud M={(pi,fi)}, where each point pi∈R3 is a world-space coordinate and fi∈RC is a latent feature vector directly derived from the VAE encoder output, matching the native input space of the diffusion backbone. This design contrasts with prior methods that store RGB colors in a point cloud, which necessitate expensive rasterization and re-encoding steps to condition the generator.

The overall process begins with initialization, where the initial frame I0 is encoded into a latent tensor z0 by the VAE encoder E. Using a depth map D0, camera pose E0, and intrinsics K0, each latent cell (u,v) is back-projected into world space to generate a memory point puv, and the corresponding latent token fuv=z0[:,v,u] is stored. This seeded cache is then used in a repeated readout-update cycle to generate the video sequence autoregressively.
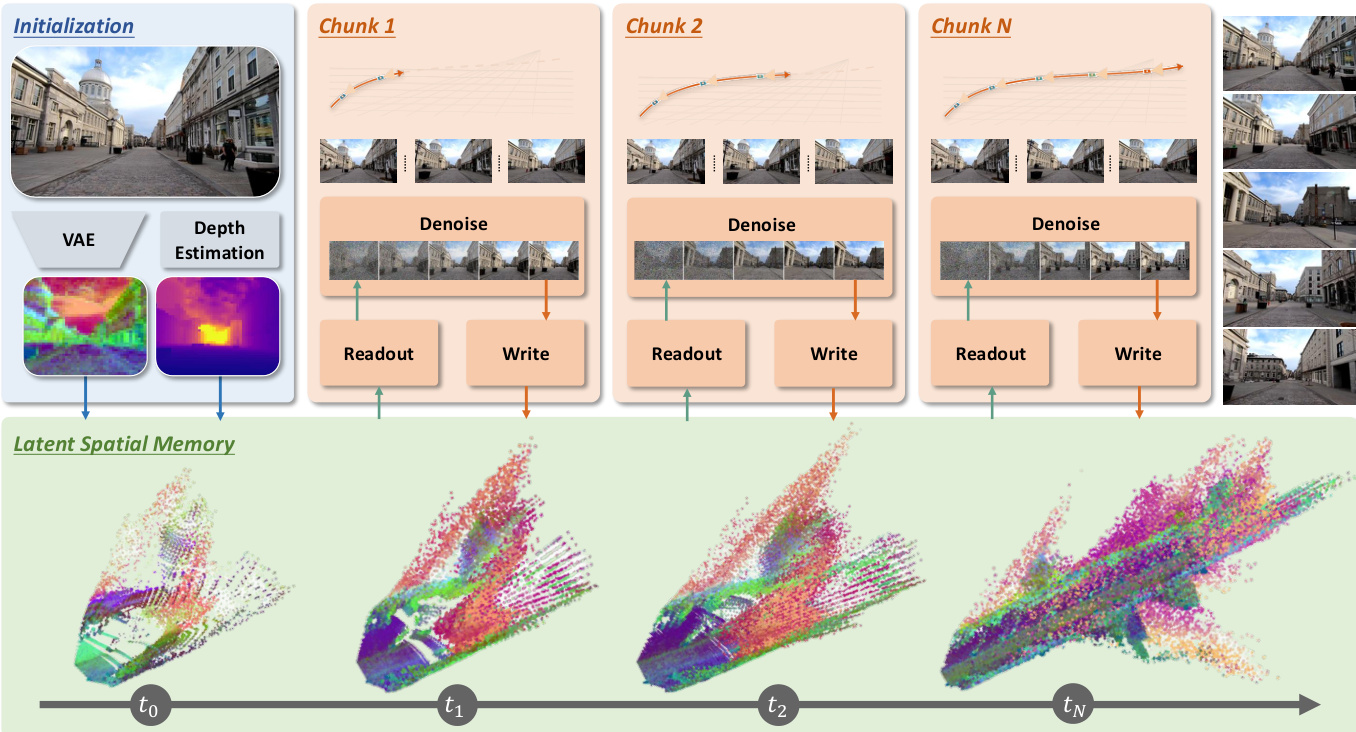
During the generation of each chunk, the latent memory is queried for conditioning signals. For a target view (Et,Kt), the memory points are projected onto the target camera grid at the latent resolution. For each latent cell (u,v), the frontmost projected point (determined by z-buffering) is selected, and its associated latent feature fi is retrieved as the readout z^t(u,v). A binary visibility mask mt is also generated to indicate which cells have received a valid projection. These readout features and the visibility mask are concatenated and injected into the diffusion backbone via a ControlNet-style side branch, which aligns the latent memory signal with the model's internal feature space without requiring a bridging encoder. This allows the backbone to denoise the chunk entirely in the latent domain, eliminating the need for pixel-space rendering.
After the chunk is generated, the system updates the persistent cache. The newly generated frames are re-encoded into clean latent tensors z~t by the VAE, and their depth maps are estimated. The latent tokens are then back-projected into the cache using the same procedure as initialization, but only for cells that are outside detected dynamic object and sky regions, as determined by an open-vocabulary entity extractor and a video segmenter. This filtering ensures that only static, geometrically reliable scene content is added to the cache, preserving its coherence. The updated memory is then used for subsequent chunks, and the denoised latents from the current chunk are carried forward as short-term temporal context for the next. This autoregressive update process, which occurs at the chunk level, amortizes the decode-and-re-encode cost and avoids pixel-space operations in the critical conditioning path, leading to significant efficiency gains.
Experiment
Evaluated across WorldScore and RealEstate10K benchmarks for world generation, novel view synthesis, and closed-loop consistency, the experiments validate that Mirage’s latent spatial memory significantly outperforms RGB caches and memory-free baselines in long-horizon stability and geometric coherence. Ablation studies and efficiency analyses confirm that operating entirely in latent space eliminates costly pixel-space round trips, reduces memory scaling, and preserves rich semantic features that raw color channels cannot capture. Ultimately, the approach anchors the generator to a consistent spatial representation, preventing cumulative drift and maintaining structural integrity even on challenging or out-of-domain trajectories.
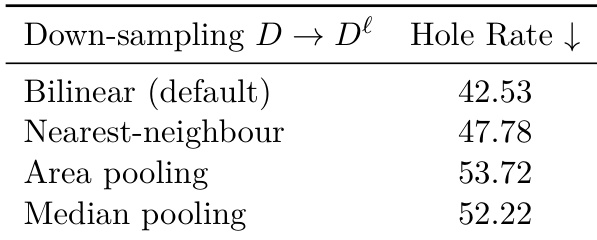
The experiment evaluates the impact of different depth down-sampling methods on cache construction, focusing on the hole rate as a measure of coverage. The results show that bilinear interpolation achieves the lowest hole rate, indicating better coverage of the latent grid compared to other methods, which suggests it is more effective at preserving spatial structure in the cache. Bilinear interpolation results in the lowest hole rate among the tested down-sampling methods. Nearest-neighbour, area pooling, and median pooling exhibit higher hole rates, indicating less effective coverage of the latent grid. The choice of down-sampling method significantly affects cache coverage, with bilinear interpolation being the most effective.
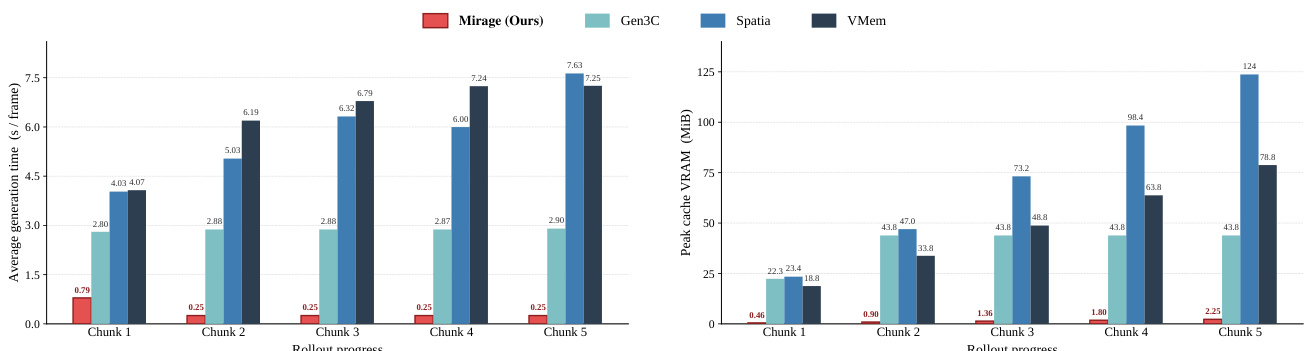
The authors compare the efficiency of Mirage with baseline methods across multiple rollout chunks, focusing on per-frame generation time and peak VRAM usage. Results show that Mirage maintains a consistent per-frame cost and minimal memory growth, while other methods exhibit significant increases in both metrics as the rollout progresses. This demonstrates the advantage of latent spatial memory in reducing computational overhead and memory footprint. Mirage maintains a stable per-frame generation time across rollout chunks, whereas other methods show increasing time requirements. Mirage's peak VRAM usage grows slowly with rollout progress, in contrast to the rapid increase observed in other methods. The efficiency gains of Mirage are attributed to eliminating the pixel-space round trip in the conditioning loop, resulting in lower memory consumption and faster processing.
The authors evaluate the impact of different components on the full Mirage system using a the the table that compares performance across multiple metrics. Results show that the full system outperforms all ablated variants, with the most significant drops observed when the dynamic object filter is removed or when using an RGB cache instead of a latent one. The full system achieves the highest scores in all categories, particularly in 3D and photometric consistency, while ablation studies reveal that key design choices like latent spatial memory and dynamic filtering are critical for maintaining long-term stability and coherence. The full Mirage system achieves the highest scores across all metrics compared to ablated variants. Removing the dynamic object filter leads to the most significant performance drop, especially in 3D and photometric consistency. Using an explicit RGB point cloud instead of a latent cache results in lower performance, indicating the importance of preserving semantic and textural information in latent space.

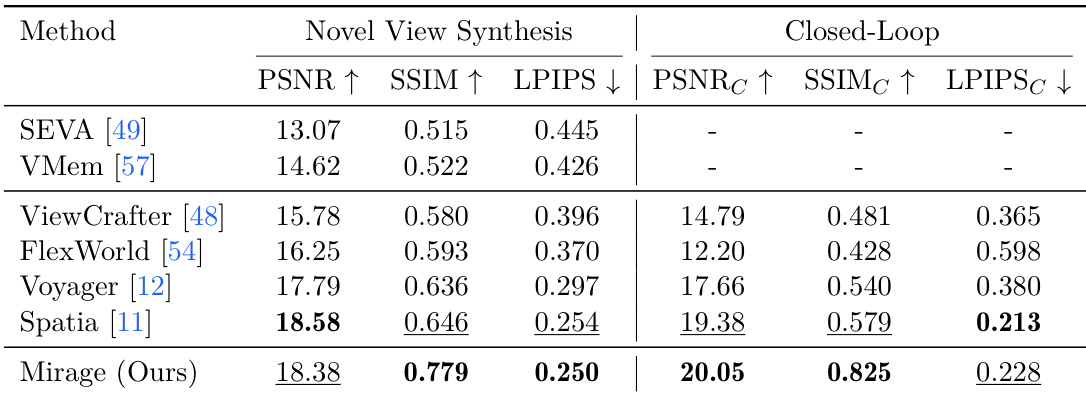
The authors evaluate their method, Mirage, against several baselines on novel view synthesis and closed-loop consistency tasks. Results show that Mirage achieves the highest performance in both settings, outperforming other methods in key metrics while maintaining strong geometric and photometric consistency. The method demonstrates superior efficiency compared to RGB-based cache approaches, with significantly lower per-frame computational cost and memory footprint. Mirage achieves the best results in both novel view synthesis and closed-loop consistency tasks compared to all baselines. Mirage shows superior efficiency with lower per-frame computational cost and memory usage than RGB-based cache methods. Mirage maintains strong geometric and photometric consistency, outperforming other methods in key metrics under both evaluation protocols.
The authors evaluate the impact of different depth sources on the performance of Mirage, a system that uses latent spatial memory for video generation. Results show that the default depth source, DepthAnything 3, consistently outperforms alternatives across all metrics, including average score, static and dynamic partition performance, and 3D and photometric consistency. While other depth sources maintain competitive results, the advantage of the default source is most pronounced in 3D consistency and photometric quality, indicating that the choice of depth estimator influences the coherence and stability of the generated scenes. DepthAnything 3 achieves the highest performance across all metrics compared to alternative depth sources. The default depth source shows the strongest improvement in 3D and photometric consistency. Alternative depth sources maintain competitive results but are consistently outperformed by the default in key areas.

The evaluation systematically examines the Mirage framework across cache construction techniques, computational efficiency, component ablations, novel view synthesis, closed-loop consistency, and depth source selection. The experiments validate that bilinear interpolation optimizes latent grid coverage, while the latent spatial memory architecture ensures stable computational overhead and minimal memory expansion during extended generation rollouts. Ablation studies demonstrate that the dynamic object filter and latent caching mechanism are critical for preserving geometric and photometric coherence, with the complete system consistently outperforming baseline methods in synthesis quality and efficiency. Additionally, the default depth estimator further enhances scene stability and visual fidelity, confirming the overall robustness of the proposed approach.