Command Palette
Search for a command to run...
MEMORY-CACHING: RNNs mit wachsendem Speicher
MEMORY-CACHING: RNNs mit wachsendem Speicher
Ali Behrouz Zeman Li Yuan Deng Peilin Zhong Meisam Razaviyayn Vahab Mirrokni
Zusammenfassung
Transformers haben sich als De-facto-Architekturen für die meisten aktuellen Fortschritte in der Sequenzmodellierung etabliert, vor allem aufgrund ihrer wachsenden Speicherkapazität, die mit der Kontextlänge skaliert. Während dies für Retrieval-Aufgaben plausibel ist, führt es zu einer quadratischen Komplexität, was aktuelle Studien dazu angeregt hat, praktikable subquadratische rekurrente Alternativen zu erforschen. Obwohl diese rekurrenten Architekturen in verschiedenen Domänen vielversprechende Ergebnisse liefern, schneiden sie in speicherintensiven Aufgaben (recall-intensive tasks) oft schlechter ab als Transformers, was häufig auf ihre festgelegte Speicherkapazität zurückgeführt wird. In diesem Beitrag stellen wir Memory Caching (MC) vor, eine einfache, aber effektive Technik, die rekurrente Modelle durch das Zwischenspeichern von Checkpoints ihrer Speicherzustände (auch bekannt als hidden states) verbessert. MC ermöglicht es, die effektive Speicherkapazität von RNNs mit der Sequenzlänge wachsen zu lassen und bietet so einen flexiblen Kompromiss, der zwischen dem festen Speicher (d. h. O(L)-Komplexität) von RNNs und dem wachsenden Speicher (d. h. O(L²)-Komplexität) von Transformers interpoliert. Wir schlagen vier Varianten von MC vor, darunter gated aggregation und sparse selective mechanisms, und diskutieren deren Auswirkungen auf sowohl lineare als auch tiefe memory modules. Unsere experimentellen Ergebnisse im Bereich Language Modeling sowie bei Long-Context-Verständnisaufgaben zeigen, dass MC die Leistung rekurrenter Modelle verbessert und damit seine Effektivität bestätigt.
One-sentence Summary
This paper introduces Memory Caching (MC), which enhances recurrent models by caching checkpoints of memory states to enable growing memory capacity that interpolates between the O(L) complexity of RNNs and the O(L2) complexity of Transformers, demonstrating improved performance on language modeling and long-context understanding tasks.
Key Contributions
- This work introduces Memory Caching (MC), a technique that enhances recurrent models by caching checkpoints of their memory states to allow effective memory capacity to grow with sequence length. The method offers a flexible trade-off that interpolates between the fixed memory complexity of RNNs and the growing memory complexity of Transformers.
- Four variants of MC are proposed, including gated aggregation and sparse selective mechanisms, with implications discussed for both linear and deep memory modules. These designs extend the framework's applicability across different memory module structures.
- Experimental results on language modeling and long-context understanding tasks demonstrate that MC enhances the performance of recurrent models. These findings support the effectiveness of the proposed technique in addressing performance gaps in recall-intensive tasks.
Introduction
Transformers dominate sequence modeling due to their associative memory capabilities, yet their quadratic complexity limits scalability for long contexts. Recurrent alternatives provide linear efficiency but struggle with recall-intensive tasks because their fixed-size states force information loss over time. The authors introduce Memory Caching to enhance recurrent models by storing checkpoints of their hidden states throughout the input sequence. This technique allows effective memory capacity to grow with sequence length, offering a flexible trade-off between the efficiency of RNNs and the performance of Transformers. They propose four variants including gated aggregation and sparse selective mechanisms to optimize how these cached memories are utilized, and results indicate this approach closes the accuracy gap with Transformers on long-context tasks while maintaining superior inference efficiency.
Method
The authors introduce Memory Caching (MC) as a technique to interpolate between the efficiency of Recurrent Neural Networks (RNNs) and the retrieval capabilities of Transformers. The core framework treats the sequence model as an associative memory that is optimized during the forward pass. To manage long sequences without incurring quadratic computational costs, the model divides the input into segments S(1),…,S(N). For each segment, the model maintains a memory state that is updated recurrently. Once a segment is processed, its final memory state is saved as a checkpoint. This establishes a distinction between the current 'Online Memory' and the historical 'Cached Memories'.
As shown in the framework diagram, the architecture aggregates information from these multiple memory states to compute the output for the current query. The system maintains a set of cached memories from previous segments alongside the current online memory, allowing the model to access information across arbitrary distances.
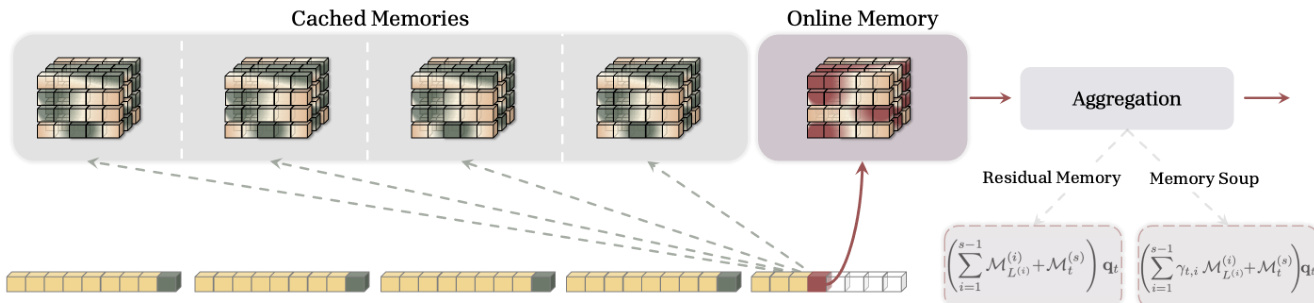
Several aggregation strategies are proposed to combine these memories effectively. The Residual Memory variant simply sums the outputs from the online and cached memories. To enable input-dependent selection, the Gated Residual Memory (GRM) introduces gating parameters that modulate the contribution of each segment based on the current input context. Another approach, Memory Soup, constructs a single data-dependent memory module by interpolating the parameters of the cached memories, effectively creating a specialized retrieval function for each token.
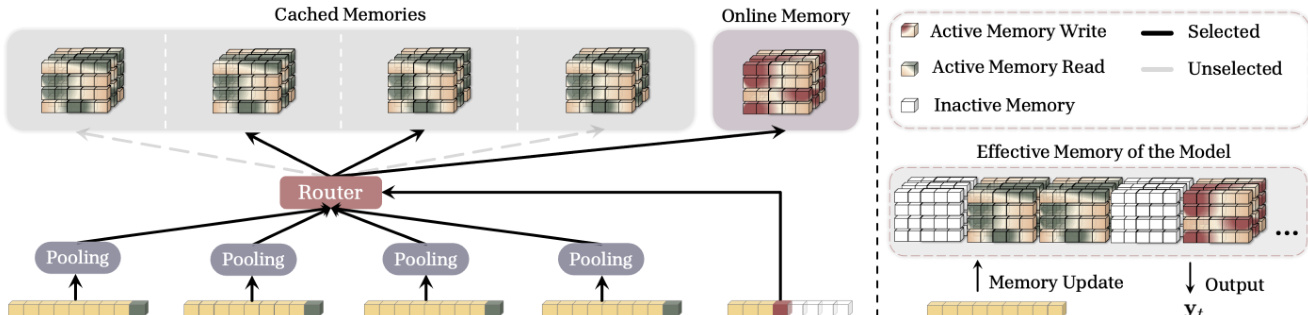
To improve efficiency for very long sequences, the authors introduce Sparse Selective Caching (SSC). This method uses a router to measure the contextual similarity between the current token and past segments, selecting only a subset of the most relevant cached memories for retrieval. This approach reduces the computational overhead by avoiding the processing of all cached states for every token.
Refer to the diagram illustrating the router mechanism, which highlights how the model activates specific memory blocks for reading and writing while leaving others inactive. The router ensures that only the necessary memory components are accessed, optimizing both memory consumption and inference speed.
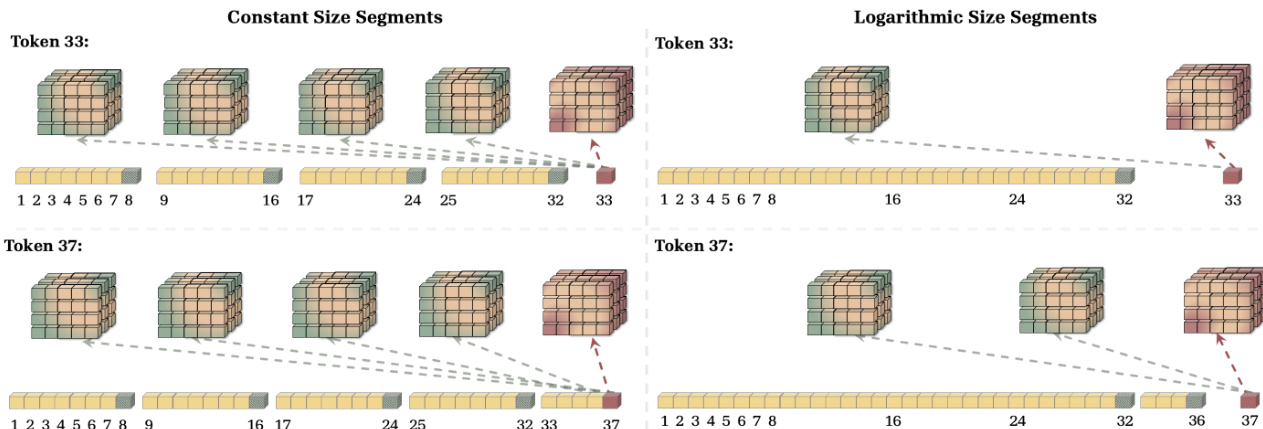
The segmentation strategy significantly impacts the balance between memory capacity and computational complexity. Constant size segments provide uniform resolution across the sequence, whereas logarithmic size segments reduce the number of cached states to O(logL). This segmentation choice allows the model to trade off between the level of compression and the computational cost of retrieval.
The visual comparison of these segmentation approaches demonstrates how logarithmic segmentation groups tokens into exponentially increasing segment sizes, offering a more efficient alternative for handling long contexts compared to constant size segments.
Experiment
The study evaluates memory caching variants across language modeling, long-context retrieval, and understanding tasks using benchmarks such as LongBench and Needle-in-a-Haystack. Results demonstrate that these enhanced models consistently outperform baseline recurrent models and narrow the performance gap with Transformers by effectively distributing compression loads and increasing effective memory capacity. Additionally, ablation studies validate the contribution of specific design choices to robustness, while efficiency analysis confirms that the variants offer a scalable middle ground between recurrent models and Transformers with minimal overhead.
The provided configuration details outline the hyperparameters for two model scales evaluated in the study. The larger model variant features a wider hidden dimension and is trained on a significantly larger token budget, whereas the smaller variant is deeper with more attention heads. These settings establish the baseline for evaluating memory caching and long-context capabilities across different model capacities. The larger model variant is trained on a substantially larger token budget compared to the smaller variant. The smaller model architecture employs a greater number of blocks and attention heads but operates with a smaller hidden dimension. Peak learning rates are scaled inversely to model size, with the smaller model utilizing a higher rate.

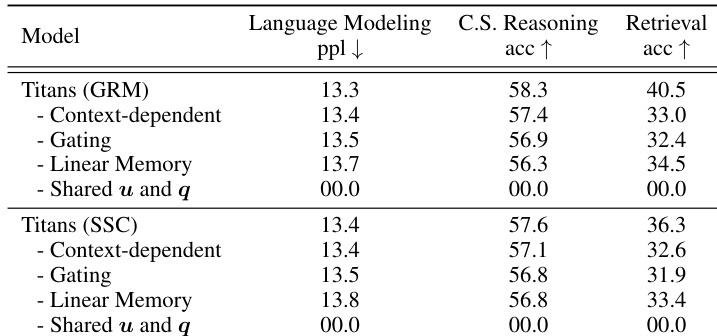
The authors present an ablation study on the Titans model to evaluate the contribution of specific design choices such as context-dependency, gating, and memory linearity. The results indicate that removing these components consistently degrades performance across language modeling, reasoning, and retrieval tasks. Furthermore, a configuration that shares specific parameters causes the model to fail completely, highlighting the necessity of the proposed architecture. Removing the context-dependent mechanism or gating leads to lower accuracy in reasoning and retrieval tasks. Replacing the memory module with a linear version increases perplexity and reduces accuracy compared to the baseline. Sharing specific parameters causes the model to fail completely, highlighting the necessity of the proposed architecture.
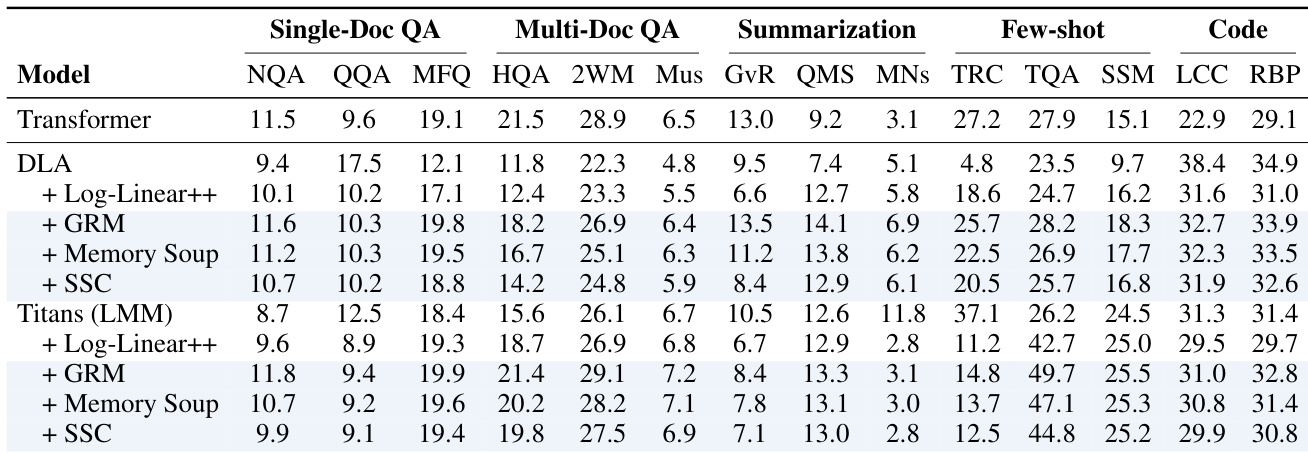
The the the table compares the performance of Transformer, DLA, and Titans models enhanced with various memory caching strategies across single-document QA, multi-document QA, summarization, few-shot learning, and code generation tasks. Results indicate that memory caching variants, particularly GRM and SSC, generally provide consistent improvements over the base recurrent models and the Log-Linear++ method, especially in multi-document and few-shot scenarios. While Transformers serve as a strong baseline, the enhanced recurrent models demonstrate competitive performance, often surpassing the Transformer in specific few-shot and retrieval benchmarks. Memory caching strategies like GRM and SSC consistently yield better results than the Log-Linear++ approach across most task categories. Enhanced recurrent models show significant performance gains in Multi-Doc QA and Few-shot tasks compared to their base versions. The Titans model with GRM achieves notably high performance in Few-shot TQA, surpassing the standard Transformer baseline.
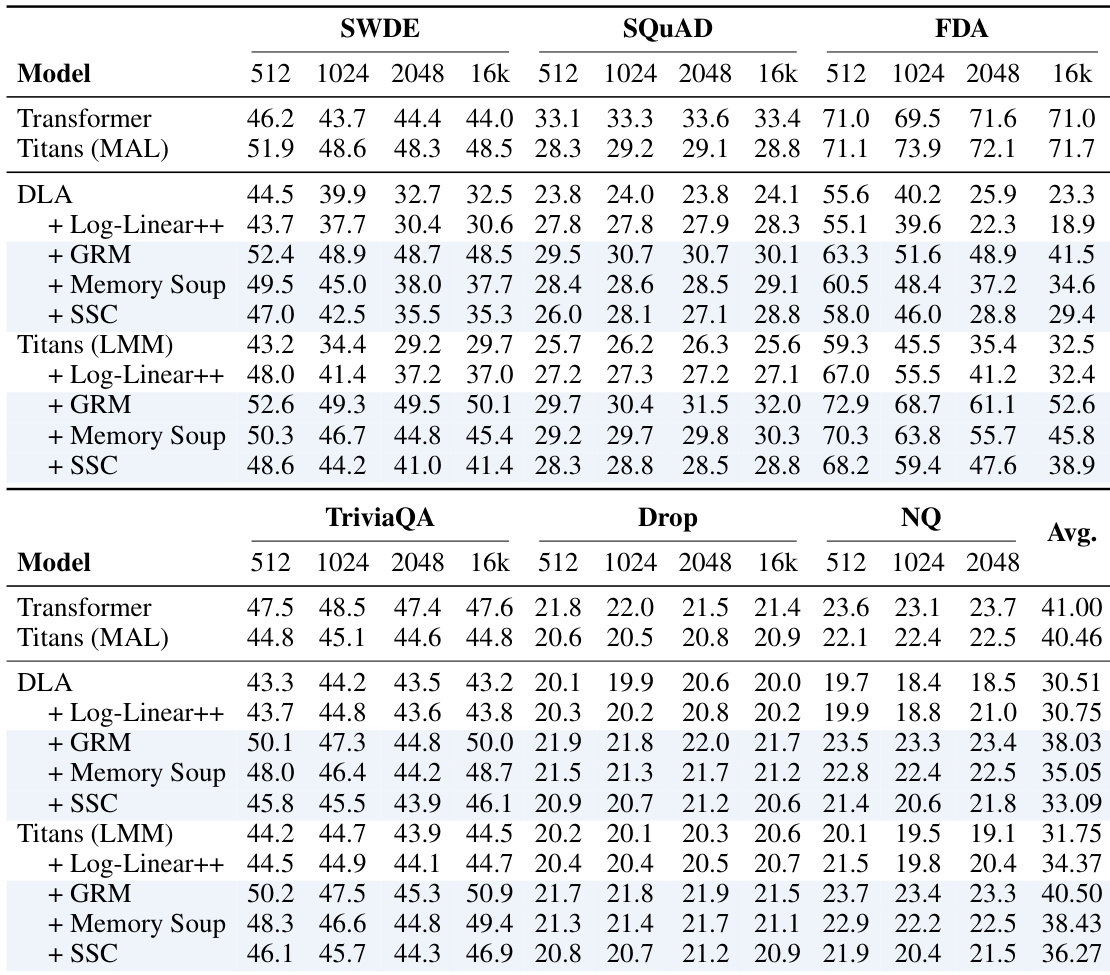
The authors evaluate memory caching enhanced models on in-context retrieval tasks, comparing them against standard Transformers and baseline recurrent models. Results indicate that memory caching variants consistently outperform their base models and offer competitive performance against Transformers, particularly when using GRM or SSC segmentation methods. The authors attribute these gains to the increased effective memory capacity that scales with sequence length. Memory caching variants provide consistent improvements over baseline recurrent models across diverse datasets and context lengths. The GRM and SSC methods achieve superior results compared to other memory caching strategies like Log-Linear++. Enhanced recurrent models close the performance gap with Transformers, with some variants outperforming the Transformer baseline on specific tasks.
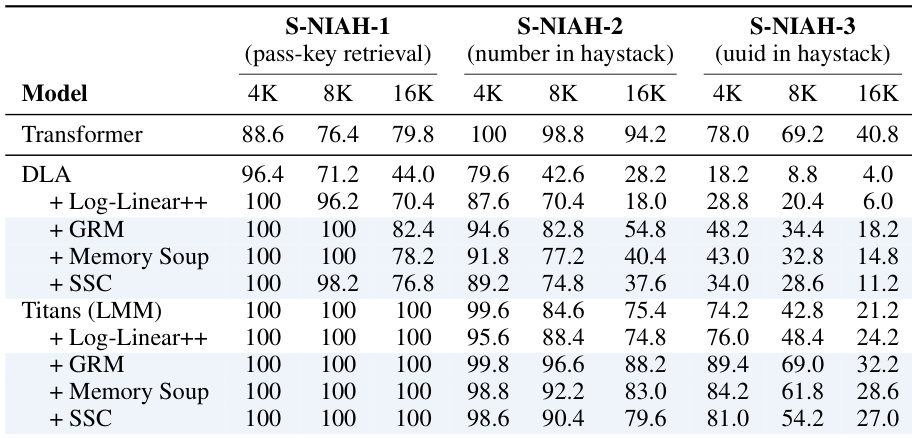
The authors evaluate memory caching variants against baseline models on Needle-in-a-Haystack retrieval tasks with varying context lengths. Results show that memory caching consistently improves retrieval accuracy, particularly for longer sequences where baseline models struggle. Titans-based models enhanced with memory caching achieve superior performance, often reaching near-perfect accuracy across different retrieval types and context lengths. Memory caching variants significantly boost retrieval performance over baseline DLA and Transformer models, especially as context length increases. Titans models combined with memory caching methods like SSC and GRM achieve the highest accuracy, maintaining perfect scores on pass-key retrieval tasks regardless of sequence length. SSC and GRM generally outperform Log-Linear++ approaches, demonstrating better robustness in retrieving specific information from long contexts.
The evaluation utilizes two model scales to establish baselines for assessing memory caching and long-context capabilities. An ablation analysis confirms that specific architectural components like context dependency and gating are essential, as their removal degrades performance on reasoning and retrieval tasks. Comparative experiments demonstrate that memory caching strategies, particularly GRM and SSC, consistently outperform baseline recurrent models and Log-Linear++ methods while achieving competitive results against Transformers, especially in long-context retrieval scenarios.