Command Palette
Search for a command to run...
LatentSkill: Von Im-Kontext-Textuellen Fähigkeiten zu Im-Gewicht-Latenten Fähigkeiten für LLM Agents
LatentSkill: Von Im-Kontext-Textuellen Fähigkeiten zu Im-Gewicht-Latenten Fähigkeiten für LLM Agents
Zusammenfassung
Agent systems verwenden zunehmend textbasierte Fähigkeiten zur Kodierung wiederverwendbarer Aufgabenabläufe, doch die Einführung dieser Fähigkeiten in den Prompt bei jedem Schritt verursacht erheblichen Kontext-Overhead und exponiert den Fähigkeitsinhalt als Klartext. Wir präsentieren LatentSkill, ein Framework, das textbasierte Fähigkeiten mittels eines vortrainierten hypernetworks in Plug-and-Play-LoRA-Adapter umwandelt. LatentSkill speichert Fähigkeitswissen im weight space anstelle des context space und entfernt skill tokens pro Schritt, wobei modulares Laden, Skalieren und Komposition erhalten bleiben. Auf ALFWorld und Search-QA übertrifft LatentSkill die entsprechende in-context skill baseline bei deutlich weniger prefill tokens: Die Erfolgsrate auf ALFWorld steigt um 21,4 bzw. 13,4 Punkten auf den seen und unseen splits bei 64,1 % weniger prefill tokens, und das exact match auf Search-QA verbessert sich um 3,0 Punkte bei 72,2 % geringerem skill-token overhead. Weitere Analysen zeigen, dass generierte skill LoRAs eine strukturierte semantische Geometrie aufweisen, sich präzise über den LoRA scaling coefficient steuern lassen und bei Ausrichtung der skill components durch parameter-space arithmetic zusammengesetzt werden können. Diese Erkenntnisse deuten darauf hin, dass weight-space skills ein effizientes, modulares und weniger exponiertes Substrat für die Erweiterung von LLM agents darstellen.
One-sentence Summary
LatentSkill converts in-context textual skills into plug-and-play LoRA adapters through a pre-trained hypernetwork to store knowledge in weight space rather than context space, eliminating per-step token overhead while enabling modular scaling and parameter-space composition to outperform in-context baselines on ALFWorld and Search-QA with up to 72.2% lower token overhead.
Key Contributions
- The paper introduces LatentSkill, a framework that converts textual agent skills into modular LoRA adapters through a pre-trained hypernetwork. This method shifts procedural knowledge from the context window to weight space, eliminating per-step token overhead while preserving plug-and-play modularity.
- Evaluations on the ALFWorld and Search-QA benchmarks demonstrate that this weight-space representation outperforms in-context skill baselines. The framework improves task success and exact match scores while reducing prefill token usage by 64.1% and 72.2%, respectively.
- Analysis of the generated adapters reveals that skill weights form a structured semantic geometry and enable precise behavioral control through LoRA scaling coefficients. These adapters further support parameter-space arithmetic when skill components are semantically aligned.
Introduction
LLM agents increasingly rely on reusable textual procedures to navigate complex, long-horizon tasks, but standard approaches that inject these skills directly into prompts create substantial context overhead and expose proprietary logic as readable plaintext. Parametric alternatives like fine-tuning avoid this prompt bloat but permanently fuse skills into model weights, making them difficult to update, remove, or combine on the fly. The authors address this persistent trilemma by introducing LatentSkill, a framework that leverages a pre-trained hypernetwork to transform textual skill descriptions into modular LoRA adapters. By encoding procedural knowledge directly into weight space rather than the context window, the method eliminates repeated prompt tokens while preserving the ability to dynamically load, scale, and compose skills. Experimental results demonstrate that this approach significantly reduces prefill overhead and outperforms traditional in-context baselines on standard agent benchmarks, while revealing that weight-based skills maintain a structured, controllable, and mathematically composable geometry.
Dataset
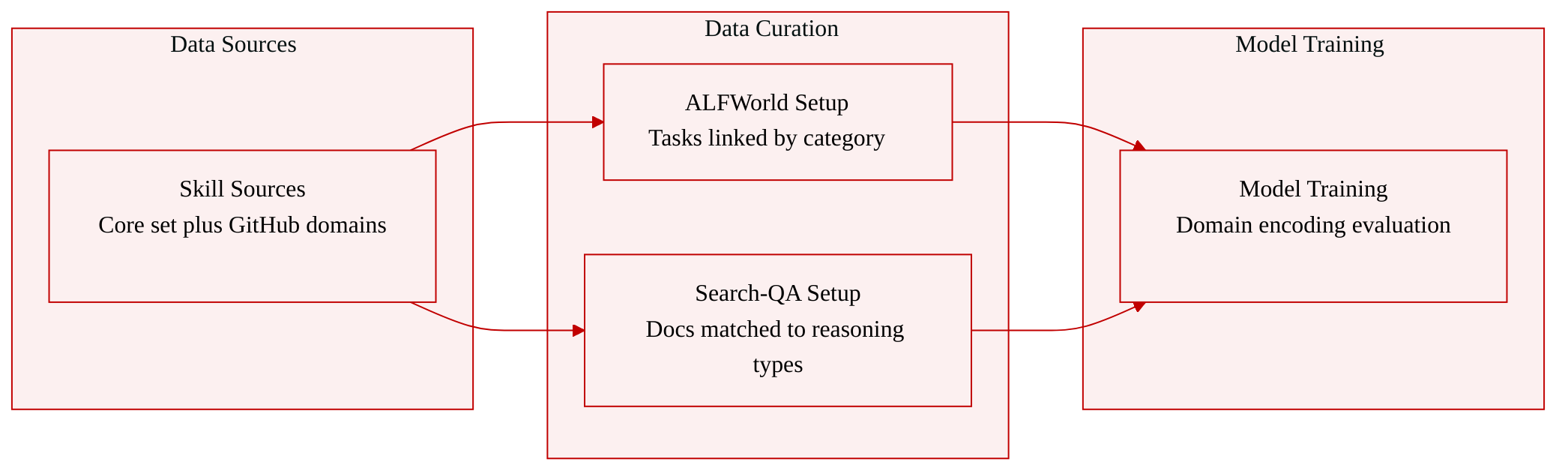
- Dataset composition and sources: The authors construct the dataset around the skill library released by Xia et al. (2026), supplementing it with out-of-domain skill texts collected from public GitHub repositories.
- Key subset details:
- ALFWorld: Skills are assigned to tasks by category rather than retrieval. The Pick and Pick2 task types share a single skill document.
- Search-QA: Three skill documents align with three distinct reasoning types, matched directly according to dataset entries.
- Out-of-Distribution: Contains 18 Code skills, 13 Finance skills, and 11 Writing skills sourced from public GitHub repositories.
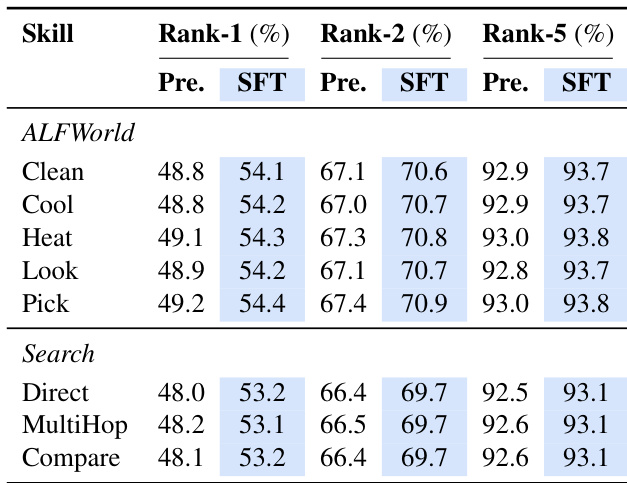
- Data usage: The authors use the dataset to evaluate the domain-level encoding capability of a hypernetwork, specifically testing its ability to generalize to unseen domains. The provided text does not specify training splits or mixture ratios.
- Processing and metadata: Metadata is built by mapping skill documents to predefined task categories or reasoning types. The authors explicitly avoid retrieval-based matching, relying instead on categorical alignment. No cropping strategies are applied.
Method
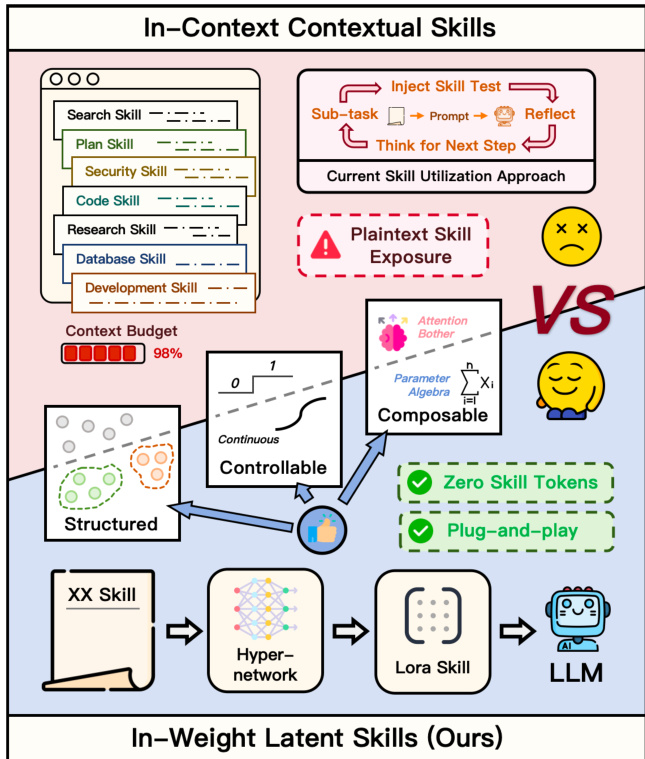
The authors present LatentSkill, a framework that transforms textual agent skills into modular, in-weight LoRA adapters using a hypernetwork-based approach, thereby shifting reusable procedural knowledge from context space to parameter space. The overall architecture, illustrated in the figure below, consists of a skill compiler that generates low-rank adapter weights from skill text, which are then mounted on a frozen backbone LLM to condition its behavior without requiring the skill document to be present in the input prompt. This design enables efficient inference by eliminating the need for repeated context injection while preserving modularity and enabling compositional control.
As shown in the figure below, the framework operates in two primary stages: a document-level pretraining phase and a trajectory-supervised fine-tuning phase. During pretraining, the skill compiler is trained on a corpus of textual skill documents to learn a mapping from natural language to usable LoRA weight updates. The compiler is trained to reconstruct or complete skill documents, with the adaptation of the frozen backbone serving as the supervisory signal. This stage initializes the compiler to generate adapter weights that can reconstruct the original skill text when applied. The training objective is designed such that only the compiler parameters are updated, ensuring that the backbone remains frozen and the knowledge is encoded in the adapter weights.
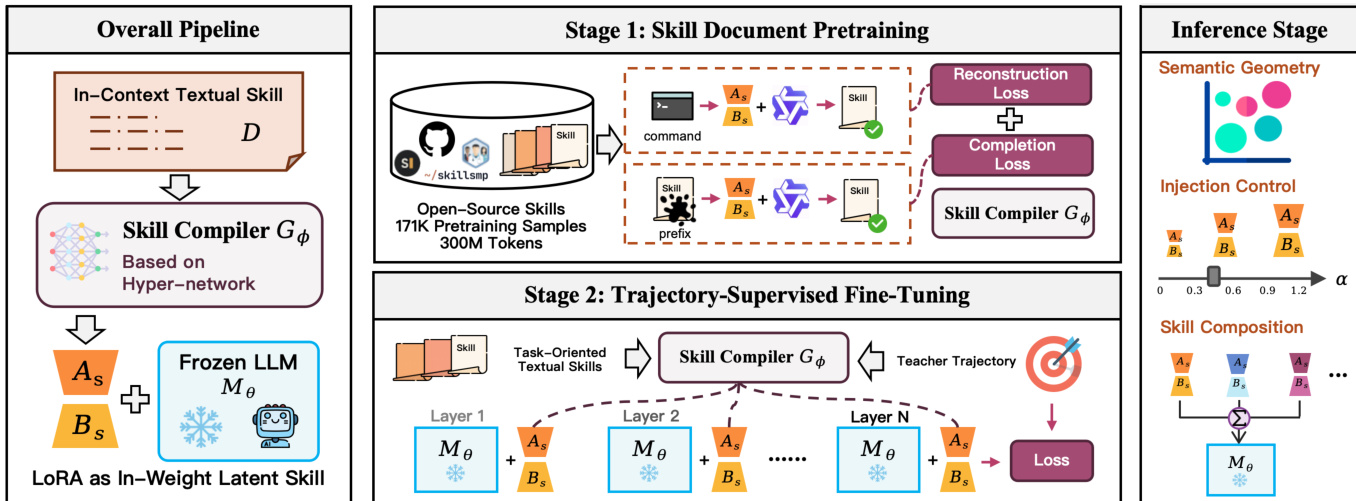
In the second stage, the pre-trained skill compiler undergoes fine-tuning using teacher agent trajectories. Each training example pairs a skill document with a complete interaction trajectory, and the compiler generates a single latent skill that is applied throughout the entire trajectory. The fine-tuning objective encourages the compiler to produce adapter weights that capture consistent, skill-level policy information rather than per-step adaptations, ensuring stable behavior across multi-step interactions. This process aligns the generated adapters with the desired task performance, using the same frozen backbone and updating only the compiler parameters.
At inference time, the skill compiler is decoupled from the agent execution loop. A skill selector chooses one or more relevant skills from a library, and the corresponding adapters are compiled once and stored in a cache. For a selected skill, its cached adapter is mounted on the backbone with a configurable injection strength α, which controls the influence of the latent skill. When multiple skills are selected, their adapters are composed in parameter space through simple addition, enabling flexible and efficient combination of skills. The framework also supports component-level composition, where skills can be decomposed into semantic components that are compiled and composed independently, allowing for more nuanced control over the resulting behavior. This modular and compositional design enables efficient, controllable, and scalable skill deployment in LLM agents.
Experiment
Evaluated on embodied household tasks and search-augmented question-answering benchmarks, the primary experiments validate that encoding textual skills into LoRA weight space significantly outperforms explicit prompt injection in both effectiveness and efficiency. Structural and composability analyses further demonstrate that the latent parameters form a semantically organized geometry that generalizes across domains and enables flexible skill combination when components are properly aligned. Finally, robustness evaluations and architectural ablations confirm consistent resistance to text perturbations and adversarial attacks, while highlighting how skill knowledge is efficiently compressed into low-rank weights concentrated within specific model output modules.
The authors present a method that encodes skill knowledge into low-rank adapter weights rather than injecting it as text into prompts, evaluating it on two benchmarks: ALFWorld and Search-QA. Results show that the approach improves performance on both tasks, with gains particularly pronounced on multi-step and unseen tasks, while also reducing inference-time token usage and interaction trajectory length. The learned skill representations exhibit structured, semantic organization in parameter space, and can be composed in a controlled manner by aligning text decomposition with weight addition. LatentSkill achieves higher performance than text-based skill injection on both ALFWorld and Search-QA, with larger improvements on unseen and multi-step tasks. The method reduces token overhead during inference and shortens interaction trajectories, indicating improved efficiency and effectiveness. Skill representations in the latent space form structured clusters and can be composed effectively through semantically aligned weight addition, demonstrating controllability and composability.
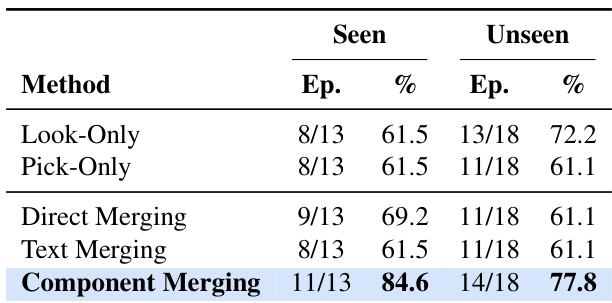
The authors evaluate skill composition methods in parameter space, comparing different merging strategies for combining skills. Results show that Component Merging achieves the highest performance on both seen and unseen task splits, outperforming other configurations while preserving the original skill capabilities. This approach demonstrates effective composition by aligning text decomposition with weight addition, avoiding interference from shared components. Component Merging achieves the highest performance on both seen and unseen task splits. Component Merging preserves the original skill capabilities while adding complementary behavior. The method avoids interference by aligning text decomposition with weight addition.
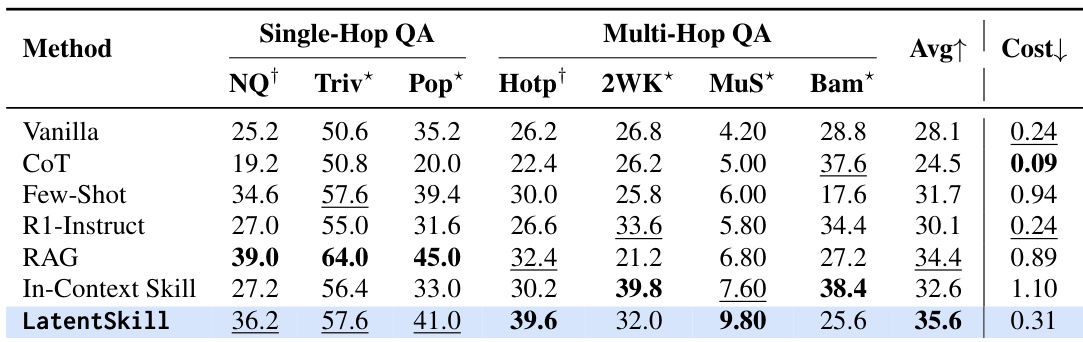
The authors evaluate LatentSkill on a search-augmented QA benchmark, comparing it against several baselines including In-Context Skill. Results show that LatentSkill achieves the highest average performance across both single-hop and multi-hop datasets, with notable improvements on specific tasks. The method also demonstrates lower inference cost compared to other approaches, indicating improved efficiency. LatentSkill achieves the best average performance on both single-hop and multi-hop QA benchmarks. LatentSkill shows significant improvements on key multi-hop tasks compared to other methods. LatentSkill reduces inference cost while maintaining or improving performance.
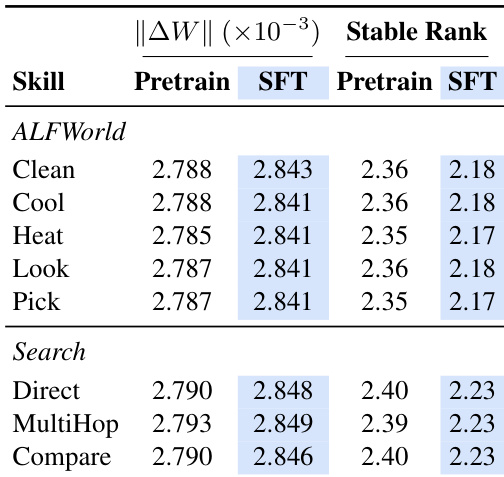
The the the table presents the Frobenius norm and stable rank of LoRA weight increments for various skills across pretraining and fine-tuning stages. The values show consistent magnitude of weight updates across skills and minimal variation between pretrain and SFT, indicating stable and compact encoding. The stable rank is significantly lower than a randomly initialized LoRA, confirming that skill knowledge is compressed into a few dominant singular directions, with fine-tuning further enhancing this low-rank structure. The Frobenius norm of weight increments remains consistent across skills and training stages, suggesting stable magnitude of learned skill representations. The stable rank is substantially lower than random initialization, indicating that skill knowledge is encoded in a low-rank subspace. Fine-tuning reduces the stable rank and increases the energy concentration in the top singular directions, improving encoding efficiency.
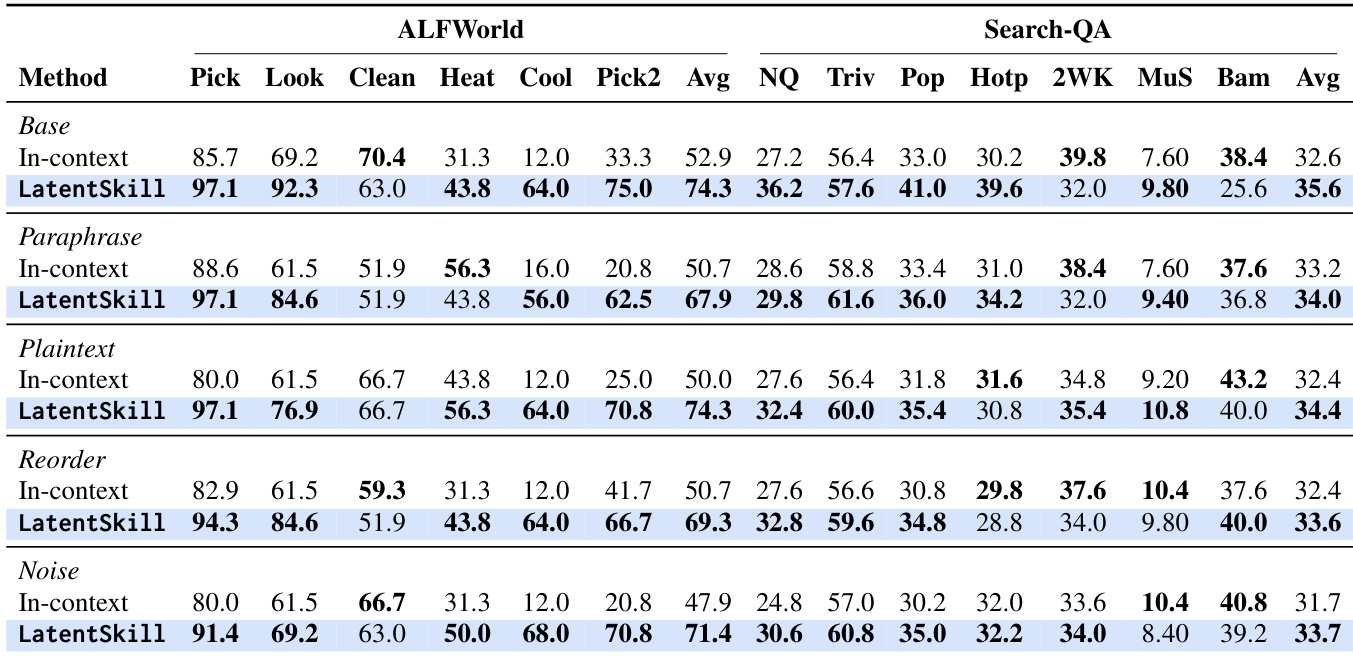
The authors evaluate LatentSkill on two benchmarks, ALFWorld and Search-QA, comparing it against methods that inject skills via text prompts. Results show that LatentSkill achieves higher performance on both benchmarks compared to in-context methods, with improvements particularly pronounced on multi-step tasks. The approach also reduces token usage during inference and leads to shorter interaction trajectories, indicating greater efficiency. Additionally, LatentSkill demonstrates robustness to perturbations in skill text and prompt attacks, maintaining its advantage over in-context methods under various conditions. LatentSkill outperforms in-context methods on both ALFWorld and Search-QA, with significant gains on multi-step tasks and unseen splits. LatentSkill reduces token overhead during inference and shortens interaction trajectories compared to baseline methods. LatentSkill maintains consistent performance improvements under various text perturbations and prompt-level attacks, showing greater robustness than in-context approaches.
The authors evaluate a method that encodes skill knowledge into low-rank adapter weights rather than injecting it as text, testing it across ALFWorld and Search-QA benchmarks against in-context baselines. Results indicate that latent skill integration consistently outperforms text-based approaches, particularly on multi-step and unseen tasks, while simultaneously reducing inference token overhead and shortening interaction trajectories. Additional experiments validate that these representations form structured semantic clusters in parameter space and can be effectively composed through aligned weight merging without mutual interference. Furthermore, low-rank stability analysis confirms that knowledge is compactly encoded within dominant singular directions, and the approach demonstrates strong robustness against text perturbations and prompt attacks.