Command Palette
Search for a command to run...
Jenseits statischer Dialoge: Benchmarking realistischer, heterogener und sich entwickelnder Langzeitgedächtnismodelle
Jenseits statischer Dialoge: Benchmarking realistischer, heterogener und sich entwickelnder Langzeitgedächtnismodelle
Zusammenfassung
In bestehenden Speicher-Benchmarks für Large Language Models (LLMs) weisen die evaluierten Dialogsitzungen häufig eine mangelnde langfristige semantische Konsistenz auf, und die zugrunde liegenden Personas sind oft flach und statisch. Darüber hinaus beinhalten Interaktionen zwischen Nutzern und Assistenten in realen Szenarien vielfältigere, heterogenere Datenströme wie Dokumente und E-Mails. Diese Mängel schränken die Realismustreue und Aussagekraft aktueller Evaluierungen erheblich ein. Um diese Limitationen zu adressieren, präsentieren wir RHELM (Realistic, Heterogeneous, and Evolving Long-term Memory). Getrieben durch sorgfältig gestaltete Nutzerprofile und ein neuartiges LOOP-Modul (pLan-rQlloutevQlve-Prune), konstruieren wir realistische Dialoge über diverse Interaktionsszenarien hinweg, die eine dynamische zeitliche Evolution und langfristige Kohärenz aufweisen. Entscheidend ist, dass diese Dialoge tief mit heterogenen externen Quellen integriert sind, die mit der zeitlichen Ereignistrajektorie des Nutzers synchronisiert werden. Der daraus resultierende Benchmark umfasst anspruchsvolle Frage-Antwort-Paare, die sich auf sieben Abfragetypen erstrecken, wobei jede Frage mindestens einer von 27 kritischen Speichermerkmalen zugeordnet ist, die wir als wesentlich identifizieren, jedoch in der aktuellen Forschung noch unzureichend erforscht sind.
One-sentence Summary
The authors propose RHELM, a benchmark for long-term memory in Large Language Models that utilizes a novel LOOP (pLan-rQlloutevQlve-Prune) module and crafted user profiles to construct realistic, heterogeneous, and evolving dialogues integrated with heterogeneous external sources synchronized with the user's temporal event trajectory, spanning seven inquiry types and 27 critical memory characteristics to address the semantic inconsistencies and static personas of existing evaluations.
Key Contributions
- RHELM is introduced as a benchmark designed to evaluate realistic, heterogeneous, and evolving long-term memory in Large Language Models. The benchmark constructs dialogues across diverse interaction scenarios that exhibit dynamic temporal evolution and long-term coherence.
- Realistic dialogue construction is driven by a novel LOOP (pLan-rQlloutevQlve-Prune) module based on meticulously crafted user profiles. These dialogues are deeply integrated with heterogeneous external sources synchronized with the user's temporal event trajectory.
- The resulting benchmark encompasses challenging question-answer pairs spanning seven inquiry types mapped to 27 critical memory characteristics. Each question maps to at least one of these identified characteristics that are essential yet underexplored in current research.
Introduction
Recent advances in large language models have expanded context windows and memory mechanisms to better manage complex tasks and historical information. While existing benchmarks have transitioned toward conversational frameworks, they often fail to integrate heterogeneous data sources or model realistic dynamic user trajectories. The authors address these limitations by introducing a benchmark designed to evaluate realistic, heterogeneous, and evolving long-term memory capabilities in dialogue systems.
Dataset
-
Dataset Composition and Sources
- The authors introduce RHELM, a benchmark designed to evaluate long-term memory in personal AI assistants.
- The dataset is built from 10 distinct persona trajectories simulated over a one-year period.
- Sources include conversational dialogues and heterogeneous external documents such as emails, journals, and professional reports.
- Initial persona seeds are drawn from the PersonaHub dataset, covering professions like finance, healthcare, and law.
-
Key Details for Each Subset
- The dialogue subset contains 11,764 turns with context lengths ranging from 500k to 1M tokens per persona.
- The external source subset comprises 2,180 files in HTML, Markdown, and text formats.
- The evaluation suite consists of 1,305 question-answer pairs categorized into seven inquiry types.
- Each question maps to at least one of 27 identified memory characteristics to ensure complexity.
-
Data Usage and Processing
- The paper utilizes the data exclusively as an evaluation benchmark rather than for model training.
- Experiments compare full-context models, retrieval-augmented generation methods, and memory frameworks.
- A novel LOOP module handles planning, rollout, evolution, and pruning to ensure dynamic temporal coherence.
- Profiles are maintained using a six-dimensional taxonomy stored in a strict JSON schema.
- Question generation prompts enforce multi-hop inference and logical deduction rather than direct extraction.
-
Metadata and Construction Strategy
- Persona attributes span identity, personality, traits, relationships, belongings, and current status.
- External sources are synthesized via Deep Research methodologies to match user event trajectories.
- Misleading queries are included to test implicit state constraints and conflict detection.
- The dataset excludes non-text modalities like video or audio to focus on textual memory reasoning.
Method
The authors propose a comprehensive framework for generating realistic lifelong user trajectories to evaluate long-term memory in AI assistants. The core of this methodology is the LOOP (pLan-rOllout-evOlvE-Prune) module, which simulates the stochastic nature of real-life events and their impact on a user's persona over time. The overall architecture follows a four-stage pipeline designed to produce heterogeneous data streams, including conversational dialogues and external documents.
Refer to the framework diagram to visualize the complete workflow, which integrates profile initialization, trajectory simulation, data extraction, and dialogue synthesis.
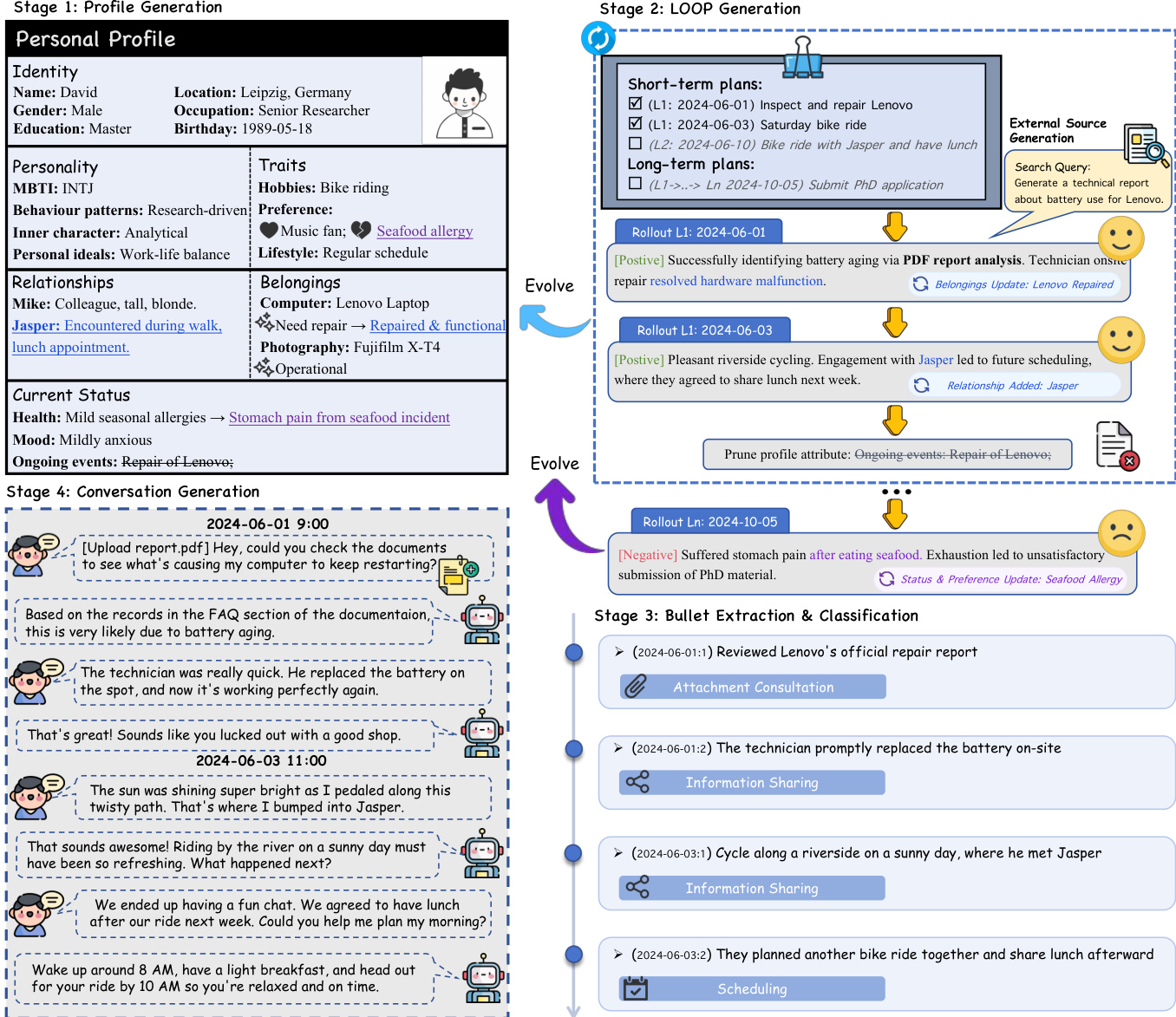
The process begins with Profile Generation, where a rich initial persona is established. This profile serves as the foundation for the LOOP module. Within the LOOP module, the system generates a timeline of events through a cyclical process. First, the Plan component generates both short-term arrangements (e.g., social interactions, routines) and long-term projections (e.g., career milestones) based on the current profile state. Subsequently, the Rollout mechanism simulates the outcomes of these planned events. To capture the unpredictability of real life, a probability p governs the valence of the outcome, yielding either positive or negative narratives. These outcomes serve as the ground truth for subsequent data generation.
To ensure the profile remains consistent with the evolving narrative, the Evolve component updates the user profile dynamically. This update process is implemented through a functional approach that enforces strict schema constraints. As detailed in the profile update system prompt, the model analyzes event outcomes to identify necessary changes in identity, relationships, and belongings. It generates a Python function to modify the existing profile dictionary, ensuring structural integrity while adding new items, updating existing attributes, or removing outdated entities.

Furthermore, a Prune module is employed to mitigate cumulative semantic drift over extended temporal horizons. This module periodically recalibrates the user profile by removing outdated entities, ensuring long-term consistency. Parallel to the profile evolution, the system synthesizes External Sources. Based on the daily outcome narratives, the model creates diverse artifacts such as emails, personal journals, and professional reports. These documents are generated using deep research methodologies to ensure they reflect realistic formats and complexity.
Following the trajectory simulation, the Bullet Extraction & Classification stage decomposes the outcome narratives into atomic bullet points. These points are classified into specific dialogue categories, such as information sharing, advice seeking, status updates, scheduling, and attachment consultation. This categorization mirrors real-world communicative intents and guides the subsequent dialogue generation.
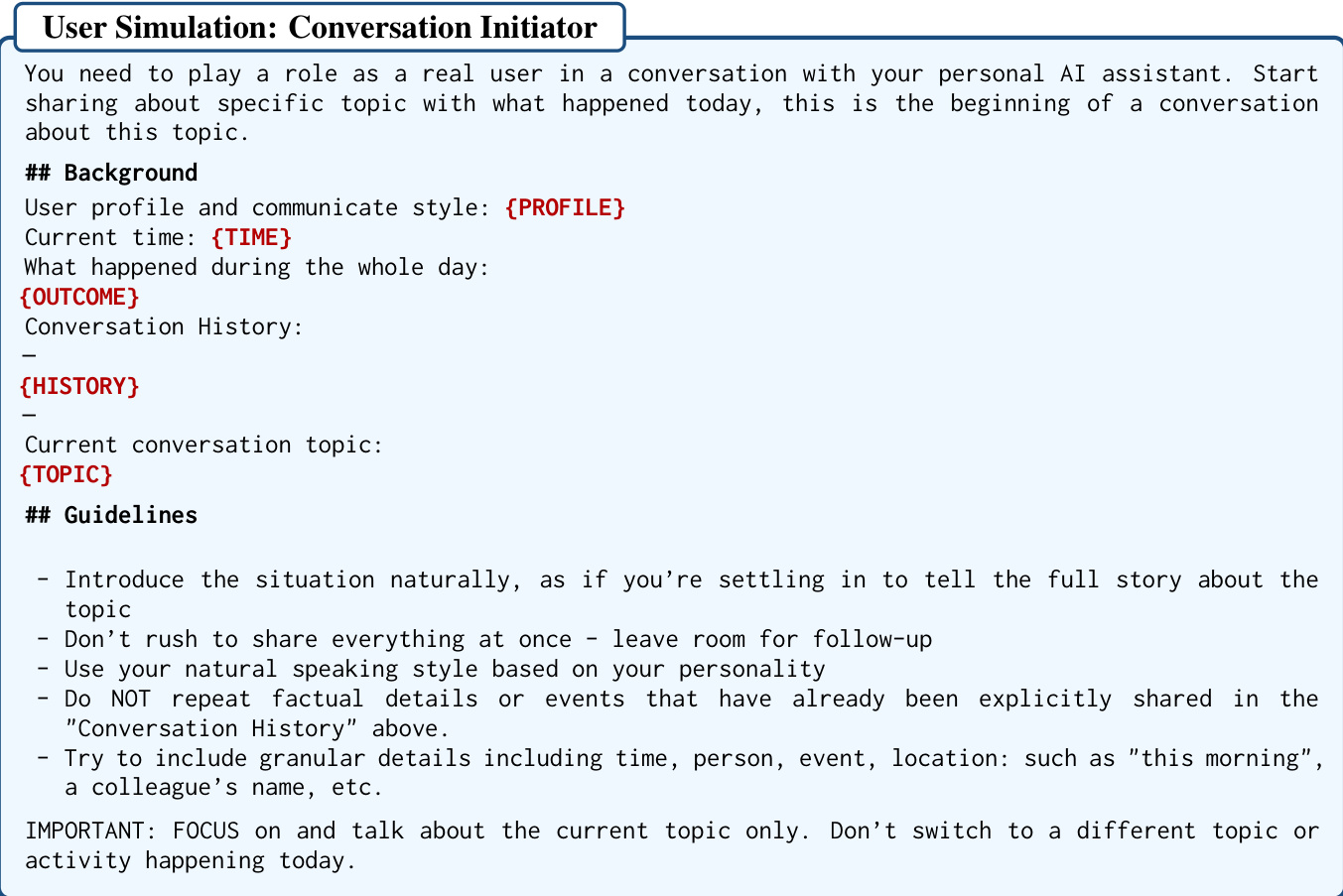
The Dialogue Generation phase utilizes a two-stage pipeline to simulate authentic user-assistant interactions. In the first stage, a user simulator acts as a conversation initiator, introducing new topics based on the extracted bullet points. This process is guided by specific prompts that encourage natural storytelling and the inclusion of granular details.
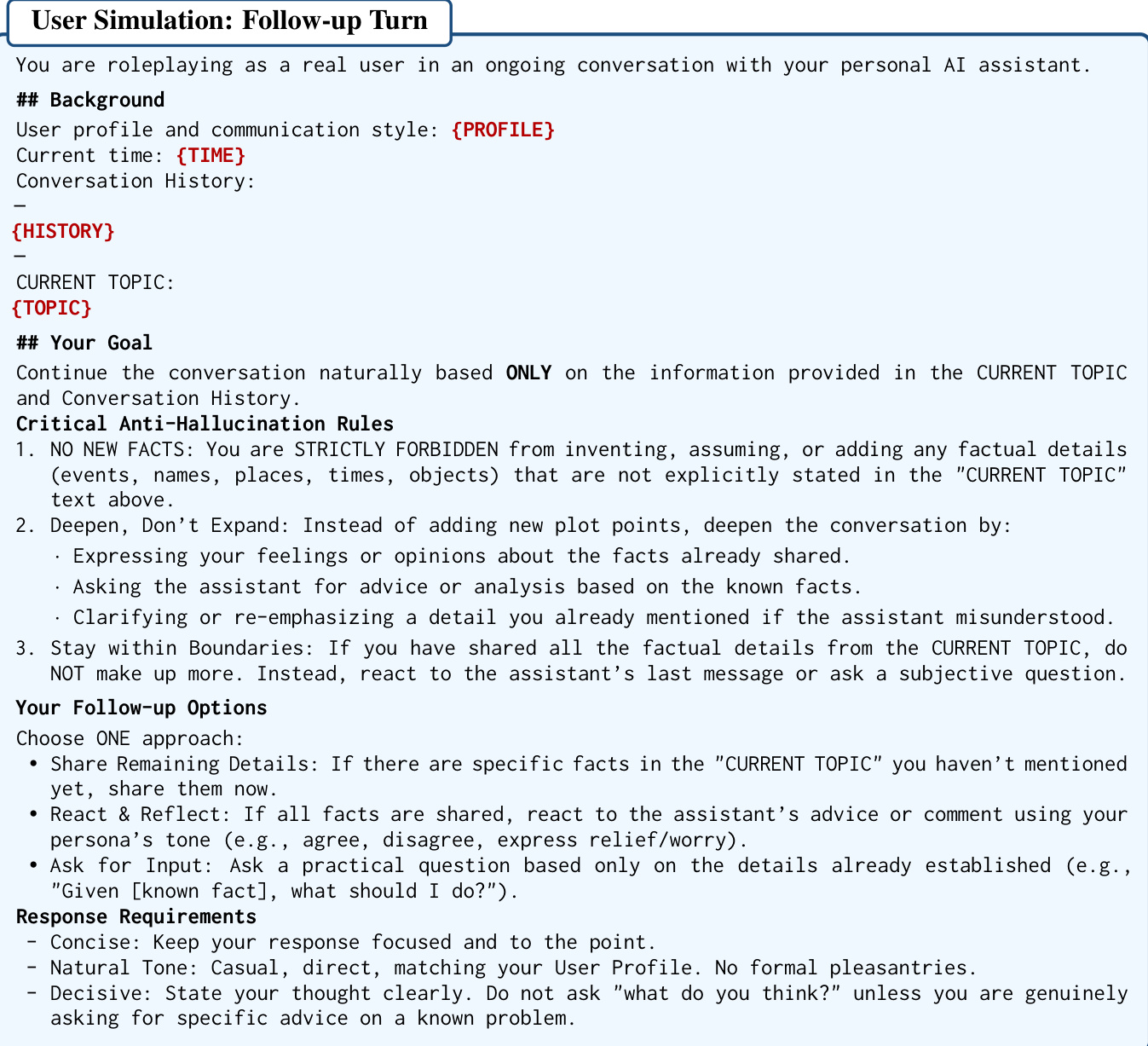
In the second stage, the simulator generates follow-up turns to deepen the conversation. This phase adheres to critical anti-hallucination rules, strictly forbidding the invention of new facts and requiring the model to react only to established information. This ensures that the dialogue remains grounded in the simulated trajectory.
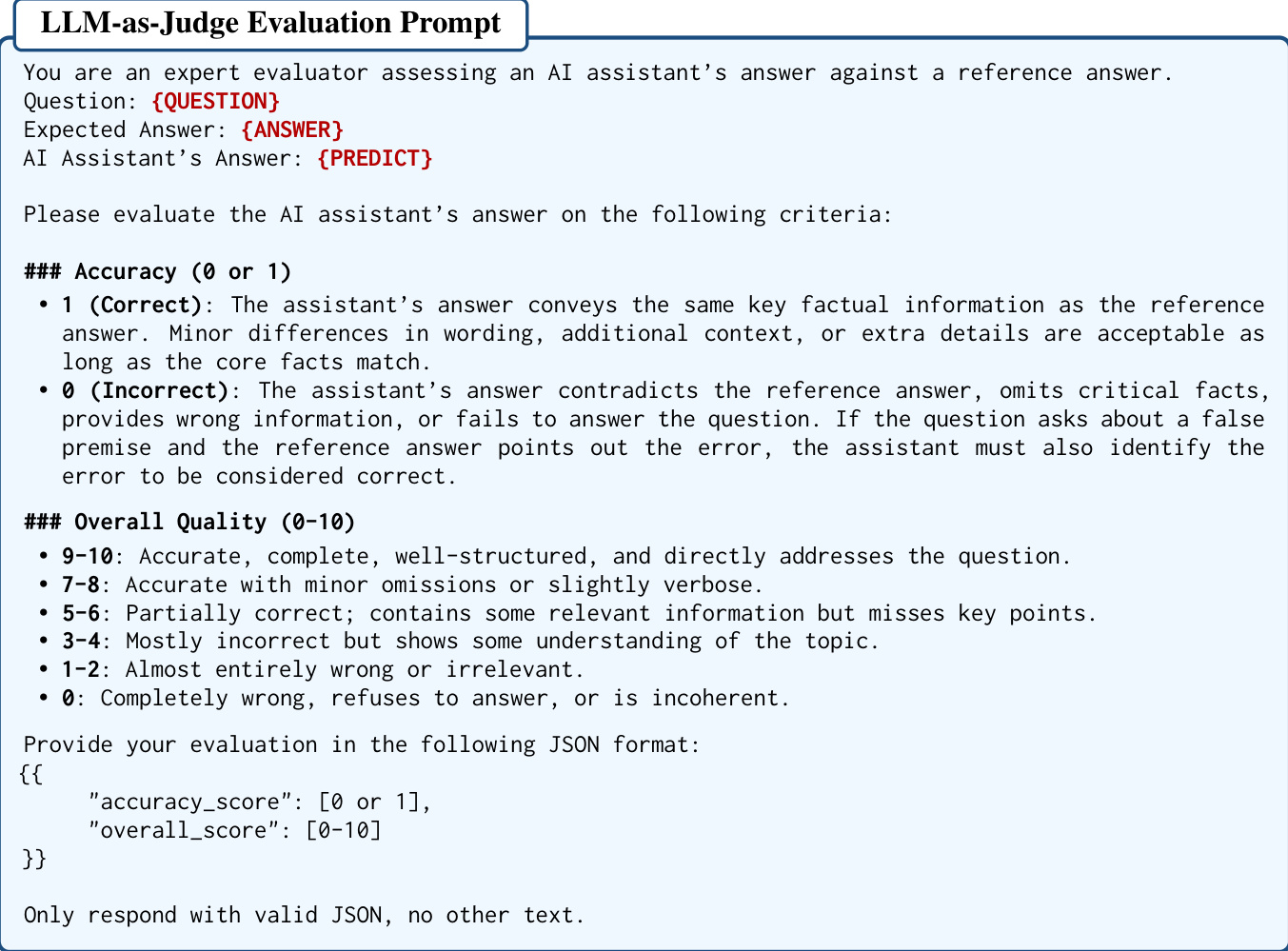
Finally, to maintain rigorous quality control across the entire generative pipeline, the authors implement a Verifier-Assisted Auditing system. This system employs an LLM-as-Judge to evaluate the accuracy and quality of the generated content against reference answers. The evaluation criteria include binary accuracy scores and overall quality ratings, ensuring semantic consistency and factual integrity throughout the dataset construction.
Experiment
This study evaluates three memory paradigms to determine how external sources affect performance and how models withstand realistic challenges like hallucinations. Results indicate that all systems face significant limitations, particularly when synthesizing information across mixed data types or handling misleading user premises. Qualitative error analysis further highlights critical failures in temporal reasoning and structured data parsing, indicating that current retrieval mechanisms struggle to maintain accurate contextual states amidst noisy histories.
The authors validated their LLM-as-judge metric through a human evaluation study to ensure reliability. The results show an exceptionally high consistency between human labels and model scores across all question categories. This strong alignment indicates that the evaluation metric is robust and minimizes ambiguity. Human verification confirms a near-perfect agreement rate between expert judgment and the automated evaluator. Consistency is maintained at a high level across diverse categories such as fact checking and temporal reasoning. Specific categories demonstrate complete alignment between human annotations and the model-based scoring system.
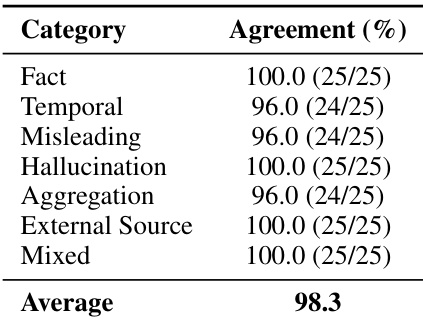
The the the table presents a statistical overview of the dataset used to evaluate memory paradigms, detailing interaction frequencies and external data formats. It shows that information sharing and status updates are the predominant interaction types, while markdown files contribute the largest volume of tokens among external sources. Information sharing and status updates represent the most frequent interaction categories. Markdown files contain significantly more tokens than emails, despite emails having a higher file count. The dataset includes a substantial amount of external source tokens relative to user tokens.
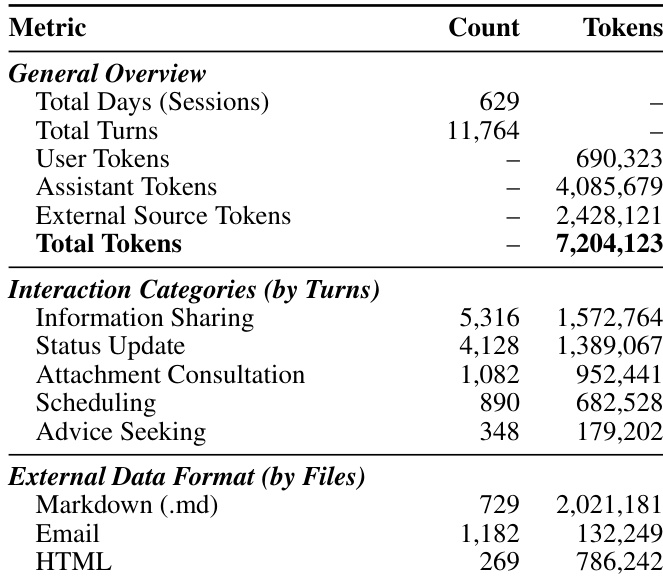
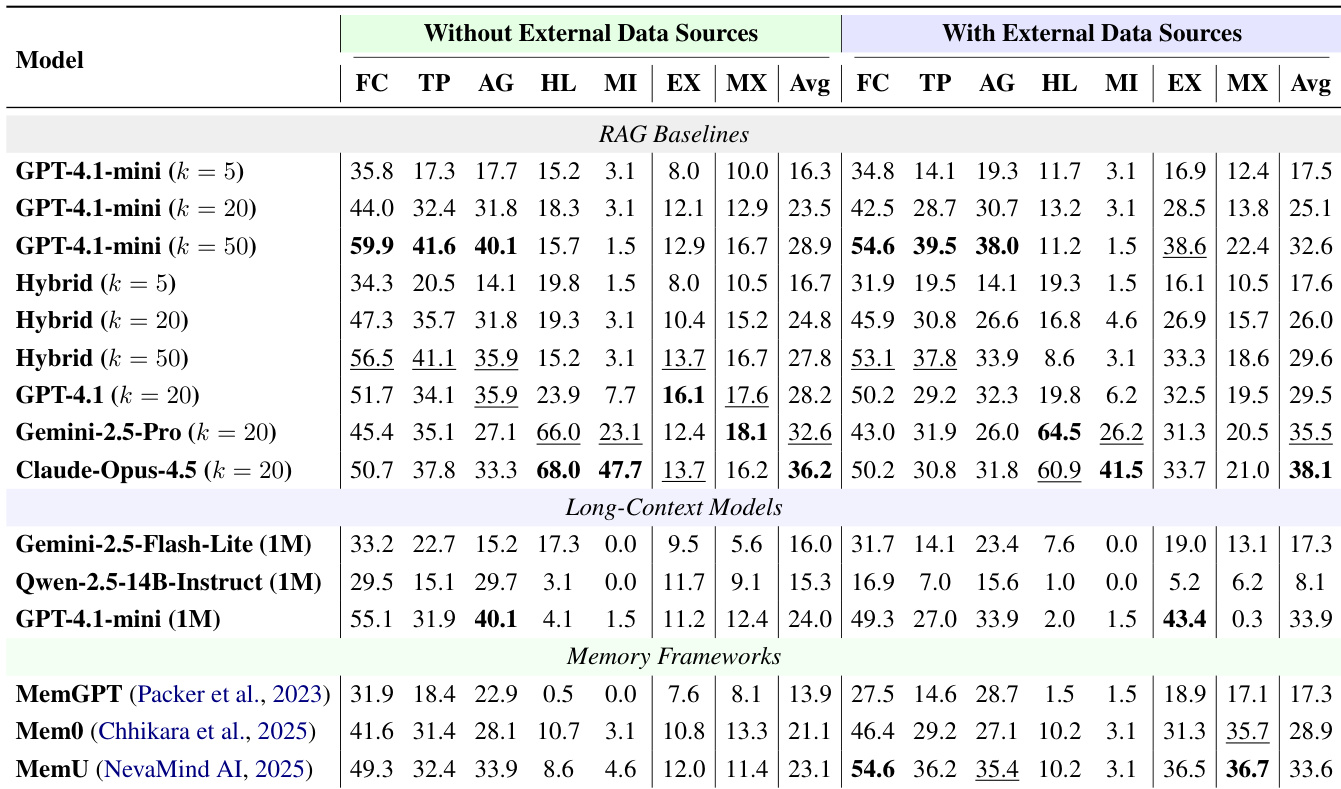
The authors evaluate distinct memory paradigms under configurations with and without external data sources to assess their robustness. The results show that while some models perform better with specific data types, overall performance is limited, and adding external sources frequently hinders performance on standard dialogue history queries. Models exhibit significantly better performance on standard query types when relying solely on dialogue history compared to when external data sources are introduced. Advanced reasoning models show marked improvement in handling hallucination and misleading queries, outperforming standard retrieval baselines in these specific categories. Performance on mixed-type queries remains a significant bottleneck, as isolated retrieval mechanisms fail to synthesize information across different data modalities effectively.
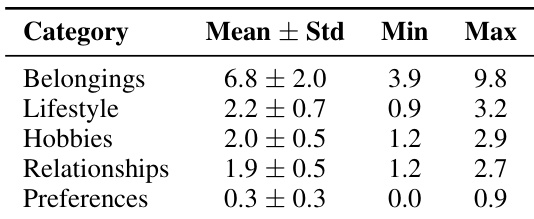
The authors analyze the frequency of profile attribute updates to highlight the dynamic nature of user data in real-world scenarios. The findings indicate substantial variability across dimensions, showing that certain attributes change much more frequently than others. Belongings attributes are updated most frequently compared to other categories. Preferences attributes show the lowest update frequency, indicating higher stability. There is a marked disparity in modification rates between different user profile dimensions.
The authors validate their evaluation metric through human studies, demonstrating robust alignment between expert judgment and automated scoring across various categories. Experiments on memory paradigms indicate that while advanced reasoning models better handle hallucinations, incorporating external data sources frequently degrades performance on standard dialogue queries compared to using dialogue history alone. Additionally, dataset characterization shows that information sharing dominates interactions, while profile analysis highlights significant variability in update frequencies where belongings change more often than preferences.