Command Palette
Search for a command to run...
Über die Geometrie der On-Policy-Distillation
Über die Geometrie der On-Policy-Distillation
Zhennan Shen Yanshu Li Qingyu Yin Chak Tou Leong Zhilin Wang Yanxu Chen Rongduo Han Sunbowen Lee Yi R. Fung
Zusammenfassung
On-Policy-Distillation (OPD) wird zunehmend zur Verbesserung des Reasonings großer Sprachmodelle eingesetzt, doch ihre Trainingsdynamiken sind nach wie vor nur unzureichend verstanden. Wir charakterisieren die Trajektorie der OPD-Updates im Parameterraum und vergleichen sie mit Supervised Fine-Tuning (SFT) sowie Reinforcement Learning with Verifiable Rewards (RLVR). Eine Reihe von Parameterraum-Diagnosen ordnet OPD konsistent einem entspannten Off-Principal-Regime zu: Im Vergleich zu SFT betreffen seine Updates weniger Gewichte und vermeiden Hauptachsen stärker, während sie im Vergleich zu RLVR weniger stark eingeschränkt bleiben. Jenseits dieser statischen Lokalisierung zeigt OPD ein Subspace-Locking: Seine kumulativen Updates treten schnell in einen schmalen, niedrigdimensionalen Kanal ein. Die Einschränkung des Trainings auf den früh im Training gebildeten Update-Unterraum erhält die OPD-Leistung, verschlechtert jedoch SFT erheblich, was darauf hindeutet, dass der gesperrte Unterraum für OPD funktionell ausreichend ist. Kontrollexperimente zeigen weiterhin, dass das Sparsifizieren der Update-Tokens und das Verschieben der Rollout-Generierung auf Off-Policy die Rangdynamiken erhalten, während die Mischung der OPD-Zielfunktion mit RLVR diese verändert. Insgesamt deuten diese Ergebnisse darauf hin, dass OPD nicht lediglich ein Zwischenpunkt zwischen SFT und RLVR ist, sondern eine eigene Update-Geometrie im Parameterraum induziert.
One-sentence Summary
Parameter-space diagnostics comparing on-policy distillation for large language model reasoning with supervised fine-tuning and reinforcement learning with verifiable rewards reveal that OPD dynamics occupy a relaxed off-principal regime and rapidly undergo subspace locking, indicating that OPD induces a distinct low-dimensional update geometry that preserves performance when constrained to its early update subspace rather than merely serving as an intermediate point between supervised fine-tuning and reinforcement learning with verifiable rewards.
Key Contributions
- This paper characterizes the parameter-space trajectory of on-policy distillation by introducing a relaxed off-principal regime that positions it between supervised fine-tuning and reinforcement learning with verifiable rewards. Diagnostics across update sparsity, spectral drift, and principal-subspace rotation demonstrate that on-policy distillation applies more selective, geometry-preserving updates than supervised fine-tuning while remaining less constrained than reinforcement learning.
- The analysis identifies a subspace locking phenomenon where cumulative parameter updates rapidly converge into a narrow, low-dimensional channel during early training. Tracking effective dimension and spectral shapes across checkpoints reveals that constraining subsequent optimization to this early subspace preserves on-policy distillation performance while significantly degrading supervised fine-tuning, confirming the channel is functionally sufficient.
- Control experiments isolating token supervision density, rollout policy, and objective composition demonstrate that sparsifying tokens and shifting rollouts off-policy preserve the low-rank dynamics. Interpolating with reinforcement learning objectives disrupts this trajectory, confirming that the locked subspace is robust to runtime perturbations but highly sensitive to the training objective.
Introduction
Large reasoning models have advanced complex mathematical and programming tasks through post-training methods like supervised fine-tuning and reinforcement learning, yet on-policy distillation remains poorly understood despite its empirical success. Prior geometric analyses only cover supervised fine-tuning and reinforcement learning in isolation, making it impossible to predict how on-policy distillation navigates parameter space since it inherently blends dense token-level guidance with on-policy sampling. The authors leverage a suite of parameter-space diagnostics to locate on-policy distillation in a relaxed off-principal regime between these two paradigms and identify an early subspace locking phenomenon where training rapidly converges to a stable low-dimensional update channel. They further demonstrate that this trajectory is strictly controlled by objective composition rather than token supervision density, providing a clear geometric framework to guide future algorithm design.
Dataset
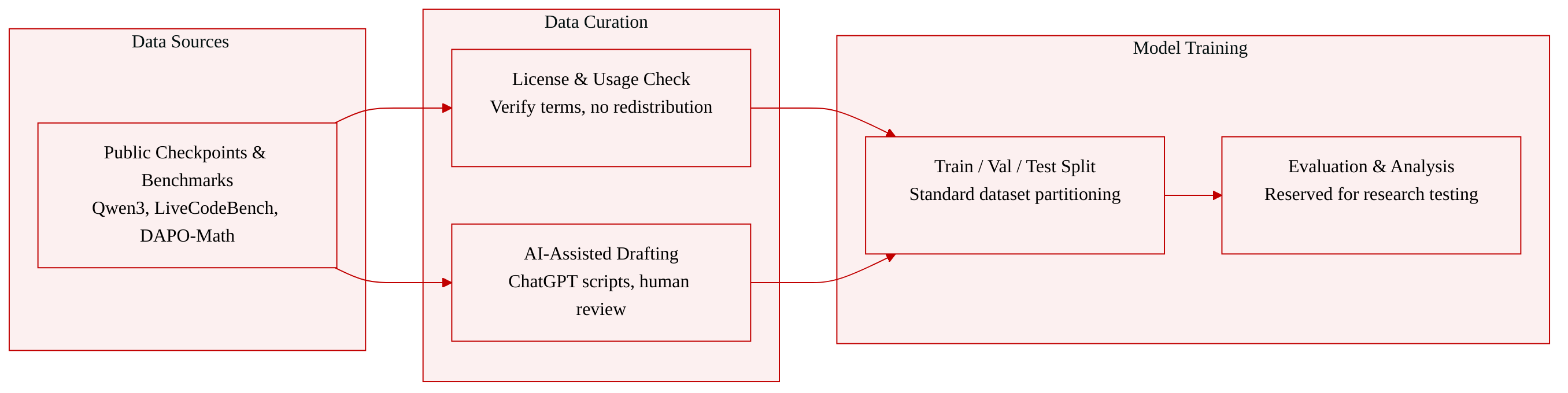
- Dataset Composition and Sources: The authors do not construct a custom dataset. They compile their evaluation suite from publicly available model checkpoints, datasets, and benchmarks, specifically citing Qwen3, DAPO-Math-17k, Dolci-Think SFT, DeepCoder, and LiveCodeBench.
- Key Details for Each Subset: Each artifact is sourced from open repositories and validated against its original license or usage terms. The authors verify that all components align with their intended research purposes and explicitly confirm that none of the original materials are redistributed.
- Data Usage and Processing: The collected artifacts are reserved strictly for research evaluation and analysis rather than model training. The authors also leverage ChatGPT to draft initial plotting and analysis scripts, but all experimental designs, numerical results, and code logic are independently reviewed and edited by the research team.
- Metadata and Additional Processing: The provided sections do not describe custom cropping strategies, metadata construction, or training mixture ratios. The workflow prioritizes transparent citation, license compliance, and human verification for all AI-assisted writing and code generation.
Method
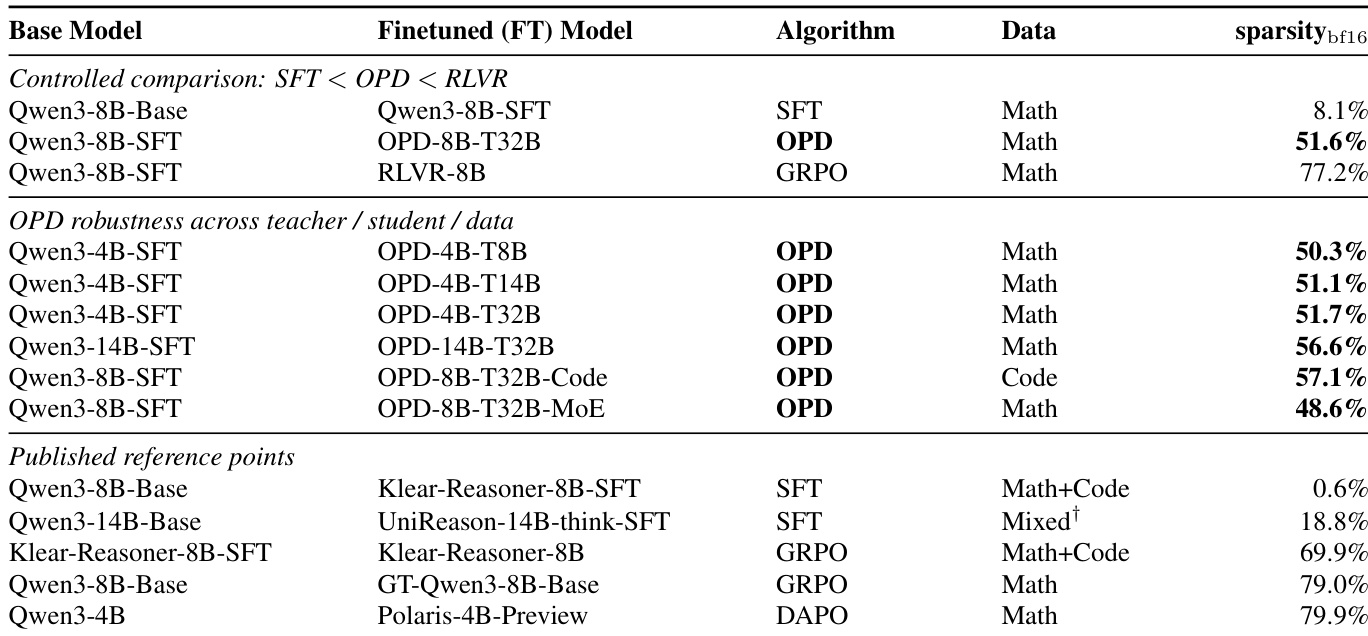
The authors leverage a framework to analyze the parameter-space dynamics of on-policy distillation (OPD) by comparing it against supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). The overall framework is structured around four key diagnostics: update sparsity, principal-angle rotation, spectral drift, and update-mask overlap. These metrics are used to characterize the location and evolution of parameter updates in the space of a large language model. As shown in the figure below, the framework positions OPD within a relaxed off-principal regime, distinct from both SFT and RLVR. SFT induces dense updates that affect a large number of weights and rotate the pretrained subspace strongly, while RLVR exhibits highly localized updates that preserve the pretrained geometry. OPD occupies an intermediate position, affecting fewer weights than SFT and avoiding principal directions more strongly than SFT, yet remaining less constrained than RLVR.
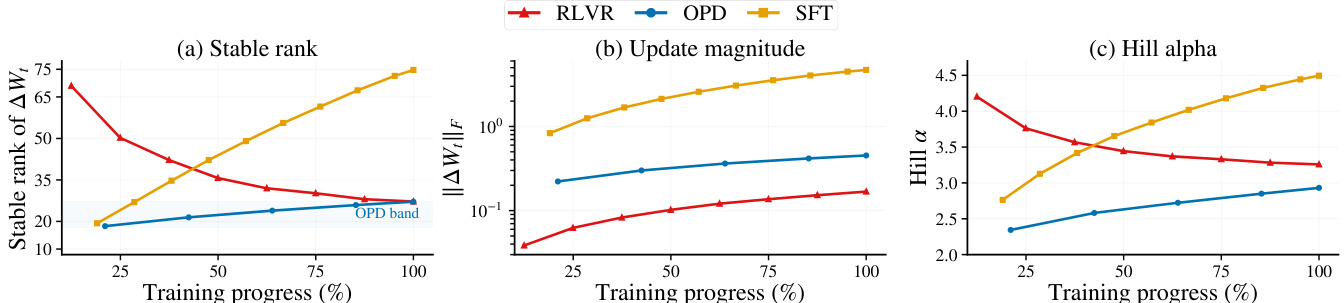
The authors further investigate the training trajectory of OPD, revealing a phenomenon they term subspace locking. This refers to the rapid convergence of cumulative parameter updates into a narrow, low-dimensional subspace early in training. The cumulative update ΔWt=Wt−W0 at each checkpoint is analyzed to track this trajectory. The stable rank, defined as srang(ΔWt)=∥ΔWt∥ob2∥ΔWt∥F2, is used to measure the effective number of dominant singular directions carrying the update energy. The Frobenius norm, ∥ΔWt∥F, is used to measure the magnitude of the cumulative update. As illustrated in the figure below, OPD's stable rank rapidly stabilizes at a low value, indicating that the updates are confined to a small subspace. This locked subspace is functionally sufficient for OPD, as constraining training to it preserves performance, whereas the same constraint severely degrades SFT. This suggests that the update geometry of OPD is not merely an intermediate state but an emergent property of its training dynamics.

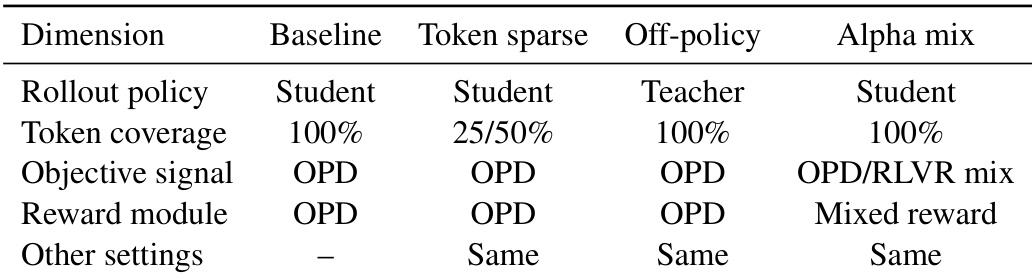
To understand the mechanisms that maintain this locked subspace, the authors conduct a series of control experiments. They perturb three candidate factors: token-level teacher supervision, rollout generation policy, and objective composition. The experiments reveal that sparsifying the update tokens and shifting rollout generation off-policy preserve the rank dynamics, indicating that these runtime perturbations do not disrupt the locked subspace. In contrast, mixing the OPD objective with RLVR changes the rank dynamics. The authors provide a mechanistic explanation based on gradient source. The OPD gradient is a sum of token-level corrections, gOPD=∑tJt⊤δt, where Jt is the local Jacobian and δt is the teacher-student token discrepancy. If the token gradients share a dominant update subspace, masking or changing the rollout policy primarily rescales the second moment, preserving the leading spectral directions. However, objective mixing changes the gradient source itself, combining the OPD and RLVR gradients: gα=αgOPD+(1−α)gRLVR. This alters the covariance geometry, explaining why it breaks the OPD-like rank trajectory. The figure below summarizes these interventions and their impact, showing that the locked subspace is robust to token and policy changes but sensitive to objective composition.

Experiment
The experiments evaluate OPD against supervised fine-tuning and reinforcement learning baselines across diagnostic setups designed to characterize parameter-space geometry, update dynamics, and functional sufficiency. Results demonstrate that OPD occupies an intermediate, off-principal regime that preserves model geometry more effectively than supervised fine-tuning while remaining less constrained than reinforcement learning. Additional analyses validate that OPD rapidly locks into a persistent, low-dimensional update subspace that emerges early and withstands runtime perturbations, while functional sufficiency tests confirm that constraining updates to this early channel maintains performance. Collectively, these findings establish that OPD’s locked subspace is a robust and functionally sufficient driver of learning.
The authors compare different fine-tuning methods and their parameter updates, showing that OPD occupies an intermediate regime between SFT and RLVR in terms of sparsity and subspace rotation. OPD exhibits a low-dimensional update channel that emerges early and is functionally sufficient for training, maintaining stability under runtime perturbations. The results highlight OPD's distinct update pattern, characterized by early subspace locking and consistent spectral properties across variants. OPD lies between SFT and RLVR in sparsity and subspace rotation, showing intermediate selectivity and geometry preservation. OPD develops a low-dimensional update channel early in training that remains stable and is functionally sufficient for learning. OPD's spectral profile is robust to runtime perturbations but sensitive to changes in the objective composition.
The authors analyze the parameter-space dynamics of OPD, showing it occupies an intermediate regime between SFT and RLVR in terms of sparsity, subspace rotation, and update localization. OPD exhibits a low-dimensional update channel that emerges early in training and is functionally sufficient for learning, with its spectral profile remaining stable under various runtime perturbations. The results indicate that OPD's low-dimensional structure is not due to small updates but rather a persistent and early-locked update subspace. OPD lies between SFT and RLVR in sparsity and subspace rotation, showing intermediate selectivity and geometry preservation. OPD's update channel emerges early and remains stable, demonstrating functional sufficiency under rank constraints. The low-dimensional update profile of OPD is robust to runtime perturbations but sensitive to changes in objective composition.
The authors analyze the parameter-space dynamics of OPD, showing that it occupies a relaxed off-principal regime between SFT and RLVR, with intermediate selectivity and geometry preservation. OPD maintains a low-dimensional update subspace from early training, which emerges early and is functionally sufficient for learning, as demonstrated by robust performance under rank constraints. These findings are supported by stable rank, update magnitude, and spectral shape diagnostics across training progress. OPD exhibits a low-dimensional update subspace that emerges early and remains stable throughout training, distinguishing it from SFT and RLVR. The early low-dimensional update channel in OPD is functionally sufficient, as training remains robust under a rank-16 constraint. OPD's spectral profile is robust to runtime perturbations but sensitive to changes in objective composition, indicating that the update geometry is tied to the learning objective.
The authors analyze the parameter-space behavior of OPD across various variants, focusing on how changes in teacher and student scales, data domains, and random seeds affect the update dynamics. Results show that OPD maintains a consistent low-dimensional update channel across different configurations, with only minor variations in update scale and spectral shape, indicating robustness to these changes. The early emergence and functional sufficiency of this update channel are preserved, suggesting it is a stable feature of the OPD process. OPD maintains a consistent low-dimensional update channel across different teacher and student scales, data domains, and random seeds. Changes in training configurations primarily affect update scale rather than spectral shape, indicating robustness in the update geometry. The early-emerging and functionally sufficient update channel remains stable under various perturbations, highlighting its persistence in OPD.
The experiments evaluate the parameter-space dynamics of OPD by comparing its fine-tuning trajectory against SFT and RLVR while testing its robustness under rank constraints, architectural variations, and runtime perturbations. Qualitative analysis reveals that OPD consistently occupies an intermediate regime between the two baselines in terms of sparsity and subspace geometry. Rather than relying on minor parameter changes, OPD uniquely establishes a low-dimensional, early-locked update channel that remains functionally sufficient for learning. This structural pattern demonstrates strong stability across diverse configurations, though it remains sensitive to shifts in the underlying learning objective.