Command Palette
Search for a command to run...
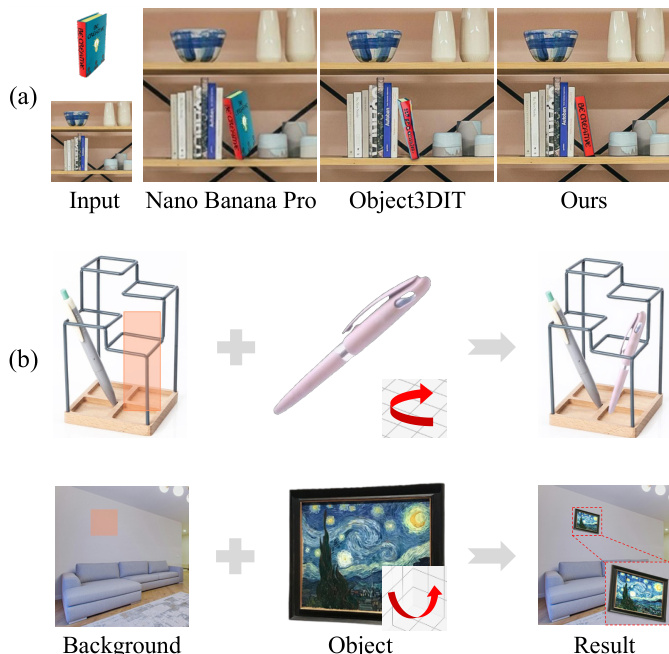
Direkte 3D-bewusste Objektinsertion mittels dekomponierter visueller Proxies
Direkte 3D-bewusste Objektinsertion mittels dekomponierter visueller Proxies
Jingbo Gong Yikai Wang Yushi Lan Yuhao Wan Ziheng Ouyang Rui Zhao Ming-Ming Cheng Qibin Hou Chen Change Loy
Zusammenfassung
Object Insertion zielt darauf ab, ein Referenzobjekt nahtlos in einen festgelegten Bereich eines Hintergrundbildes zu integrieren. Aktuelle, Diffusions-basierte Methoden erreichen eine hohe visuelle Qualität, formulieren die Insertion jedoch als eine einfache 2D-Inpainting-Aufgabe, bieten keine explizite Steuerung der 3D-Pose des Objekts und schränken ihre praktische Anwendbarkeit ein. Wir präsentieren DIRECT (Decomposed Injection for Reference Composition and Target-integration), ein neuartiges Framework, das interaktive Posenmanipulation mit hochfider 2D-Bildsynthese kombiniert, um eine posenkontrollierbare Objekt-Insertion zu ermöglichen. Unsere Methode zerlegt die Insertionsbedingungen in drei ergänzende Komponenten: eine Appearance-Guidance, die visuelle Details aus dem Referenzobjekt extrahiert, eine Geometry-Guidance, die aus dem benutzerangepassten 3D-Proxy abgeleitet wird, sowie eine Context-Guidance, die vom Zielhintergrund stammt. Durch die Einspeisung über separate Pfade vermeidet DIRECT eine Feature-Verflechtung und bewahrt gleichzeitig das Erscheinungsbild der Referenz, folgt der benutzerspezifischen Pose und passt das Objekt an die Zielszene an. Darüber hinaus führen wir eine automatisierte Pipeline zur Datenerstellung ein, um die Vielfalt und Qualität der Trainingsdaten zu verbessern. Experimente zeigen, dass DIRECT frühere Methoden sowohl in der geometrischen Kontrollierbarkeit als auch in der visuellen Qualität übertrifft.
One-sentence Summary
DIRECT (Decomposed Injection for Reference Composition and Target-integration) introduces a pose-controllable object insertion framework that decomposes visual conditions into separate appearance, geometry, and context pathways to prevent feature entanglement, overcoming the limitations of prior 2D inpainting methods while outperforming existing approaches in geometric controllability and visual quality.
Key Contributions
- The paper introduces DIRECT, a pose-controllable object insertion framework that addresses the limitations of 2D inpainting by lifting a single reference image into an interactive 3D proxy for explicit spatial guidance.
- The method decomposes insertion conditions into appearance, geometry, and context signals routed through independent pathways to prevent feature entanglement, enabling precise pose manipulation while preserving reference details and adapting to target backgrounds.
- An automated data construction pipeline enhances training diversity and quality, with empirical evaluations demonstrating superior geometric controllability and visual fidelity relative to prior methods.
Introduction
Reference-guided image generation has significantly advanced object insertion by leveraging diffusion backbones to preserve identity and harmonize scenes. This capability is essential for applications like virtual staging and augmented reality, yet current methods remain confined to the 2D plane and cannot enforce explicit 3D pose control. Prior approaches struggle with this requirement because text prompts introduce spatial ambiguity, parametric controls fail to map sparse parameters to accurate pixel-level geometry, and existing 3D datasets lack real-world visual complexity. To overcome these limitations, the authors propose DIRECT, a framework that lifts a reference image into a coarse 3D proxy and renders it under a specified 6-DoF pose to generate a dense geometric condition. By decomposing the conditioning signals into independent pathways for geometry, appearance, and scene context, the model enforces strict spatial alignment while preserving high-fidelity textures. The authors also automate the synthesis of a large-scale paired training dataset from single-view images, enabling robust generalization and state-of-the-art performance in pose-controllable object insertion.
Dataset

-
Dataset Composition and Sources: The authors construct a hybrid training dataset of approximately 160,000 image pairs designed for pose-controllable object insertion. The collection merges a curated subset of SA-1B with filtered samples from MVIgNet to balance real-world scene complexity with 3D geometric consistency.
-
Subset Details:
- SA-1B Derivative: Yields 65,000 pairs. The authors filter this source using a Qwen3-VL agent and SAM-3 to isolate fully visible, structurally complete objects within complex backgrounds.
- MVIgNet Derivative: Yields 93,000 pairs. These samples undergo strict quality filtering to remove video extraction artifacts and ensure reliable 3D consistency.
-
Data Usage and Mixture: The combined 160,000 pairs are used exclusively for training the model to learn precise pose control. The authors maintain a 65,000 to 93,000 ratio between the two subsets, effectively merging diverse in-the-wild compositions with structured multi-view data to improve generalization.
-
Processing and Construction Pipeline: The authors implement a two-stage automated workflow. First, the VLM agent proposes object categories, SAM-3 generates candidate segmentation masks, and the agent performs a zoom-in verification on localized crops to discard occluded items and confirm boundary precision. Second, the pipeline adopts a Real-Target, Synthetic-Source strategy. The original image serves as the ground truth target, while a verified object mask is extracted and processed through Qwen-Image-Edit with an angle-editing adapter. This generative model rotates the isolated object to a random novel viewpoint to create the reference input, preserving identity while synthesizing the required pose variation.
Method
The authors leverage a decomposed generative framework, DIRECT, to achieve pose-controllable object insertion by explicitly integrating 3D geometric constraints into a high-fidelity 2D image synthesis pipeline. The core of the method involves decomposing the insertion conditions into three complementary components: appearance guidance, geometry guidance, and context guidance. This decomposition enables the model to simultaneously preserve the reference object's identity, adhere to the user-specified 6-DoF pose, and harmonize the inserted object with the background scene, thereby overcoming the limitations of conventional 2D inpainting methods that lack explicit 3D control.
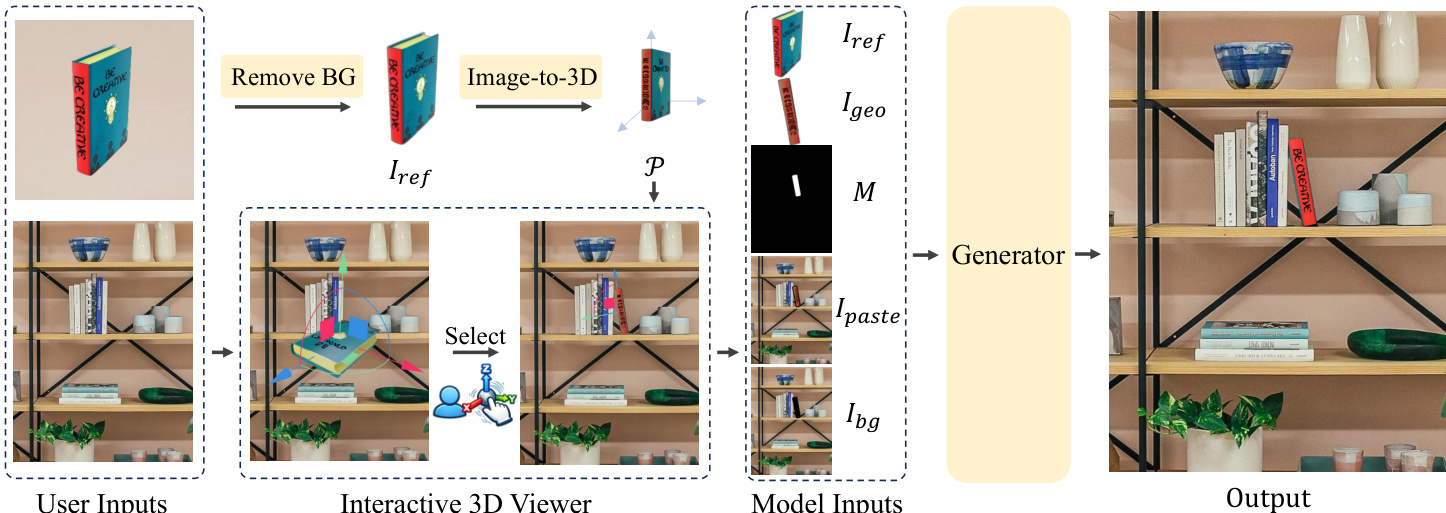
The framework begins with a 3D visual proxy lifting step. Given a 2D reference object image, Iref, the system generates a manipulable 3D proxy, P, which allows users to intuitively translate and rotate the object in 3D space to specify the desired pose, ξ. This pose is then rendered into a dense geometry guidance image, Igeo, which serves as a spatial signal for the generation process. To ensure the model correctly interprets the pose, the authors employ an RGB-based geometric condition, which resolves the semantic ambiguity present in standard signals like depth or normal maps, particularly for symmetric objects, as illustrated in the figure below.
The appearance guidance is provided by the original reference image, Iref, which contains high-fidelity texture and identity details. The geometry guidance, Igeo, derived from the 3D proxy, provides precise pose information but often suffers from texture degradation due to the limitations of single-view reconstruction. To reconcile these complementary signals, the model is trained to generate the output image Iout by conditioning on a triplet of guidance signals: the appearance Iref, the geometry Igeo, and the context Ψ(Ibg), which represents the global scene semantics of the background image. The overall framework is designed to process these signals through separate pathways to avoid feature entanglement.
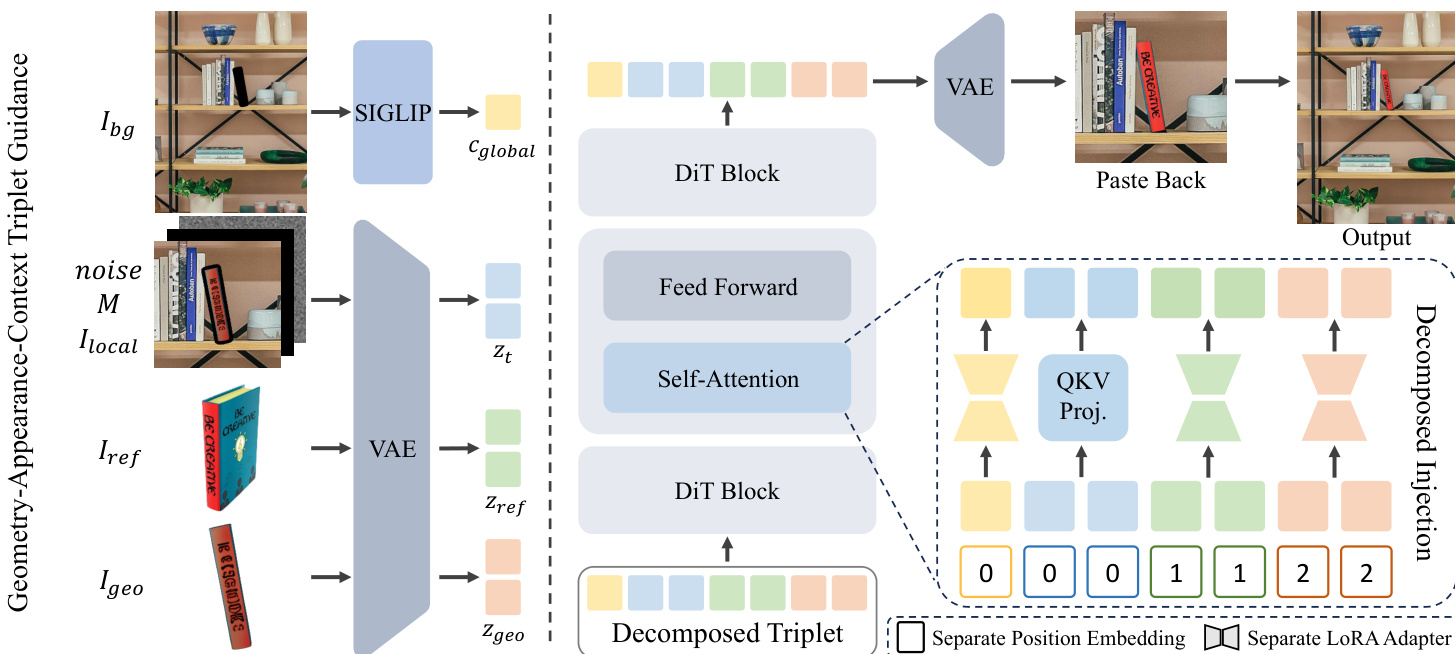
The context guidance is handled at two levels to balance resolution and global awareness. Locally, a high-resolution crop of the background around the insertion region, denoted as Ilocal, is created by pasting the geometry guidance Igeo into the background Ibg within the mask M. This local composite is fed to the inpainting backbone. Globally, the full-frame background Ibg is encoded by a frozen SIGLIP encoder to obtain global context tokens, cglobal, which provide scene-level semantics. These tokens allow the model to attend to the entire scene's lighting and composition, ensuring photometric harmony.
To effectively merge these distinct signals, the model employs a decomposed injection strategy. Both Iref and Igeo are encoded into latent tokens, zref and zgeo, while cglobal is derived from Ibg. The noisy target latent, zt, is combined with these condition tokens to form a unified sequence. Two mechanisms ensure the signals are processed independently: first, distinct Rotary Positional Embeddings (RoPE) are assigned to the appearance and geometry tokens, spatially isolating them in the attention mechanism. Second, modality-specific LoRA adapters are introduced within the self-attention layers, forcing the model to learn condition-specific transformations for extracting structural pose, identity, and global context.
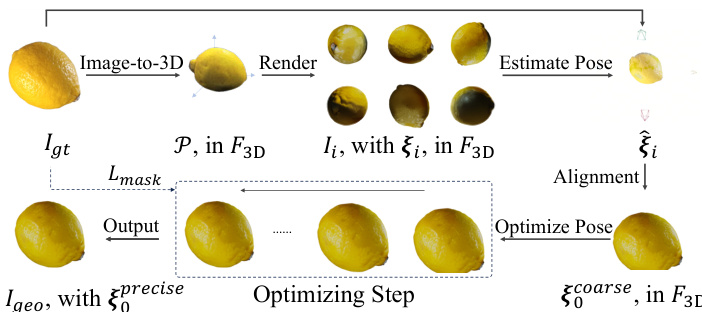
During training, the model is optimized using a standard rectified flow matching objective, with only the LoRA adapters and linear projectors being trained while the backbone remains frozen. To prevent the model from overfitting to the precise mask boundary, a shape-decomposed mask augmentation strategy is employed, replacing the ground truth mask with a random real-object mask during training. A progressive resolution training strategy is also adopted, starting with fixed 5122 crops and fine-tuning with larger 10242 crops to achieve high-resolution synthesis. The geometric condition Igeo is automatically derived during training through a geometric alignment pipeline. This pipeline estimates the optimal 6-DoF pose of the 3D proxy to match the target object in the ground truth image, using a combination of pose estimation and differentiable rendering to refine the pose and generate the precise Igeo for efficient training. This entire process is illustrated in the figure below.
Experiment
The evaluation utilizes a curated hybrid benchmark of real and synthesized image pairs to compare the proposed framework against cascaded 3D-aware and 2D insertion baselines across different generative backbones. Quantitative and qualitative assessments demonstrate that the method consistently outperforms existing approaches by achieving superior identity preservation, background harmonization, and precise pose adherence. Additional experiments validate the model's stability across large pose variations, the necessity of decomposed guidance injection to prevent feature entanglement, and its capacity to correct artifacts from intermediate 3D reconstructions. Overall, the results confirm that explicitly integrating geometric, appearance, and contextual signals enables reliable, high-fidelity object insertion while maintaining strict structural control.
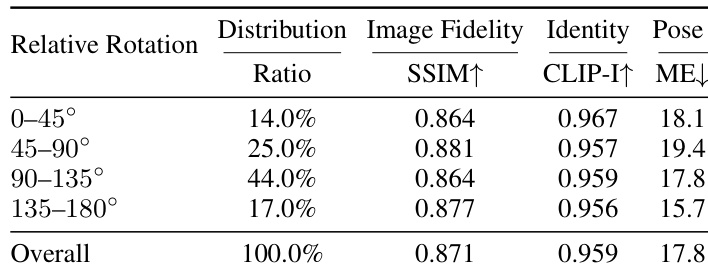
The authors analyze the impact of pose-change magnitude on generation quality by stratifying the benchmark into bins based on relative rotation angles. Results show that performance remains stable across different pose-change ranges, with no significant degradation in image fidelity, identity preservation, or pose accuracy as the rotation increases. The overall metrics indicate consistent performance across all bins, suggesting robustness to both moderate and large pose variations. Performance remains stable across different pose-change ranges, with no significant degradation in image fidelity, identity preservation, or pose accuracy. The model maintains consistent results across various relative rotation bins, indicating robustness to large pose variations. Overall metrics show no noticeable decline, demonstrating reliable performance under diverse pose-change conditions.
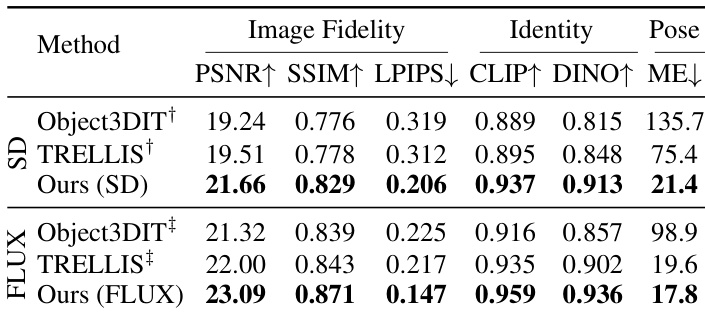
The authors conduct a quantitative evaluation comparing their method against baseline models using metrics for image fidelity, identity preservation, and pose accuracy. Their approach consistently outperforms all baselines across both Stable Diffusion and FLUX-based frameworks, demonstrating superior results in all evaluated categories. The results indicate that their method effectively integrates geometric, appearance, and contextual guidance to produce high-fidelity, pose-accurate, and identity-preserving object insertions. The proposed method achieves the best performance across all metrics under both Stable Diffusion and FLUX backbones. The approach demonstrates consistent superiority in image fidelity, identity preservation, and pose accuracy compared to baselines. Results show stable performance across different pose-change magnitudes, indicating robustness to large geometric variations.
The authors compare their method with baselines in terms of runtime and memory usage, showing that their approach achieves faster inference times across 3D and 2D components and lower overall processing time while maintaining competitive memory consumption. The results indicate that their method is more efficient than the compared models, particularly in the 2D and overall processing stages. The proposed method achieves faster inference times in both 3D and 2D components compared to the baselines. The overall processing time of the proposed method is significantly lower than that of the compared models. The proposed method uses competitive memory resources despite its improved efficiency.

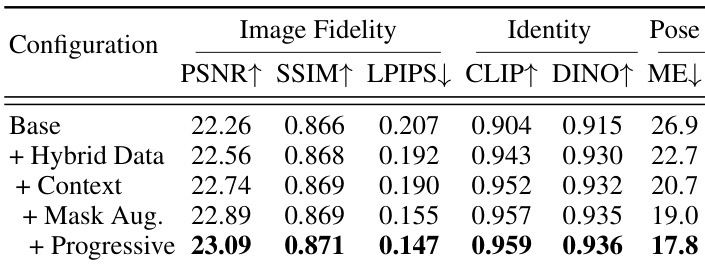
The authors present an ablation study comparing different components of their framework on a set of quantitative metrics. Results show that each added component contributes to improved performance, with the full configuration achieving the best results across all metrics. The improvements are particularly notable in image fidelity, identity preservation, and pose accuracy, indicating that each design choice plays a role in enhancing the overall synthesis quality. The full framework achieves the best performance across all metrics compared to individual components. Adding hybrid data significantly improves identity preservation and pose accuracy. Progressive training leads to the highest gains in image fidelity and pose accuracy.
The authors compare their method against baselines using a quantitative the the table that evaluates image fidelity, identity preservation, and pose accuracy. Their approach achieves superior results across all metrics, particularly in image quality and identity, while maintaining strong pose accuracy. The improvements are attributed to context and appearance guidance, as well as a decomposed injection mechanism that enhances robustness to degraded 3D reconstructions. the method outperforms baselines in image fidelity and identity preservation, achieving the highest scores in PSNR, SSIM, LPIPS, CLIP-I, and DINO. The approach demonstrates strong pose accuracy, with significantly lower matching error compared to baselines. Results show consistent improvements across both Stable Diffusion and FLUX-based backbones, indicating generalization to different generative models.

The experimental evaluation compares the proposed method against established baselines across Stable Diffusion and FLUX frameworks, validating its performance in image fidelity, identity preservation, and pose accuracy. Additional tests assess robustness to varying pose-change magnitudes, computational efficiency, and the individual contributions of framework components through ablation studies. Results consistently demonstrate that the approach outperforms existing models while maintaining strong reliability under large geometric variations and degraded 3D inputs. Furthermore, the ablation and efficiency analyses confirm that each architectural design and training strategy meaningfully enhances synthesis quality while delivering faster inference and competitive memory usage.