HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

MAKIEVAL: Ein mehrsprachiges automatisches Framework auf Grundlage von WiKIdata zur Evaluierung der kulturellen Sensibilität von LLMs

GeneralVLA-2: Geometriebewusste Rekonstruktion und gesteuerter Speicher für die Roboterplanung



























MAKIEVAL: Ein mehrsprachiges automatisches Framework auf Grundlage von WiKIdata zur Evaluierung der kulturellen Sensibilität von LLMs
GeneralVLA-2: Geometriebewusste Rekonstruktion und gesteuerter Speicher für die Roboterplanung
Mehrfach-Reflektives Masking ermöglicht das Schlussfolgern in Mask-Diffusionsmodellen
BrainG3N: Ein Tokenizer mit zwei Verwendungszwecken zur kontrollierbaren 3D-Gehirn-MRT-Generierung
GateMem: Benchmarking der Speicherverwaltung in Multi-Principal Shared-Memory Agents
MemSlides: Ein hierarchisches, gedächtnisgesteuertes Agent-Framework für die personalisierte Folien-Generierung mit mehrstufiger lokaler Überarbeitung
PerceptionDLM: Parallele Regionswahrnehmung mit multimodalen Diffusionssprachmodellen
Code-World-Modelle für das allgemeine Spielen von Spielen
Jenseits statischer Leaderboards: Prädiktive Validität für die Evaluation von LLM Agents
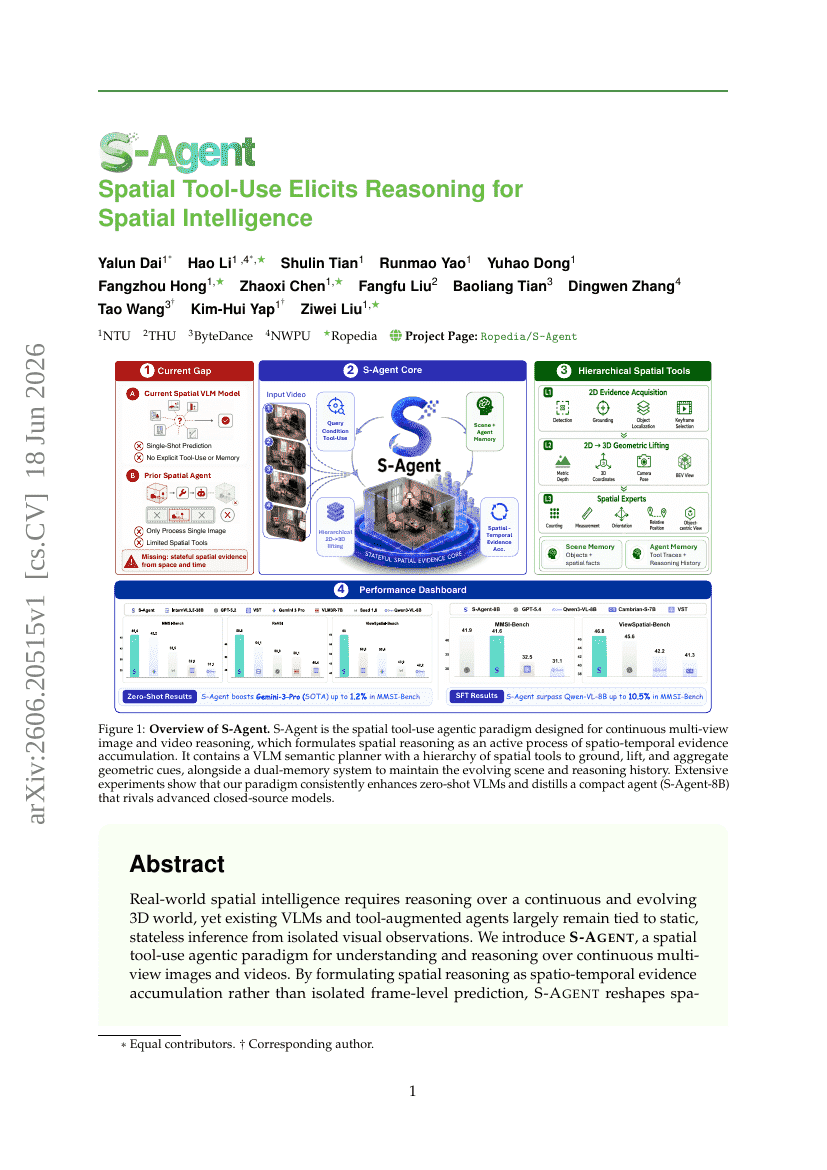
S-Agent: Räumliche Werkzeugnutzung fördert das Schlussfolgern für räumliche Intelligenz
Multi-LCB: Erweiterung von LiveCodeBench auf mehrere Programmiersprachen
Verspieltes agentices Roboterlernen
DragMesh-2: Physikalisch plausible geschickte Hand-Objekt-Interaktion mit gelenkigen Objekten
Moebius: 0.2B leichtgewichtiges Bildinpainting-Framework mit 10B-Niveau-Leistung
EfficientRollout: Systembewusstes selbstspekulatives Dekodieren für RL-Rollouts
Vertraue dem richtigen Lehrer: Qualitätsbewusste Selbstdistillation für GUI-Verankerung
Verstärkung der Zwei-Pfad-Schlussfolgerung in räumlichen Bild-Sprach-Modellen
SAE-Interventionen sind unzuverlässig: Post-Interventions-Wiederherstellung unterdrückten Verhaltens
Kairos: Ein nativer Weltmodell-Stack für physische KI
Guava: Ein effektiver und universeller Rahmen für verkörperte Manipulation
Jenseits der aktuellen Beobachtung: Evaluation multimodaler großer Sprachmodelle in kontrollierbaren nicht-markovschen Spielen
LifeSciBench: Evaluierung von Language Models für realistische, experten-niveau Aufgabensets in den Life Sciences
TRIAGE: Dialektische Schlussfolgerung für erklärbare Risikovorhersage auf unregelmäßig abgetasteten medizinischen Zeitreihen mit LLMs
LectūraAgents: Ein Multi-Agent-Framework für adaptives personalisiertes KI-unterstütztes Lernen und verkörperten Unterricht
GameCraft-Bench: Können Agents spielbare Spiele End-to-End in einer realen Game-Engine erstellen?
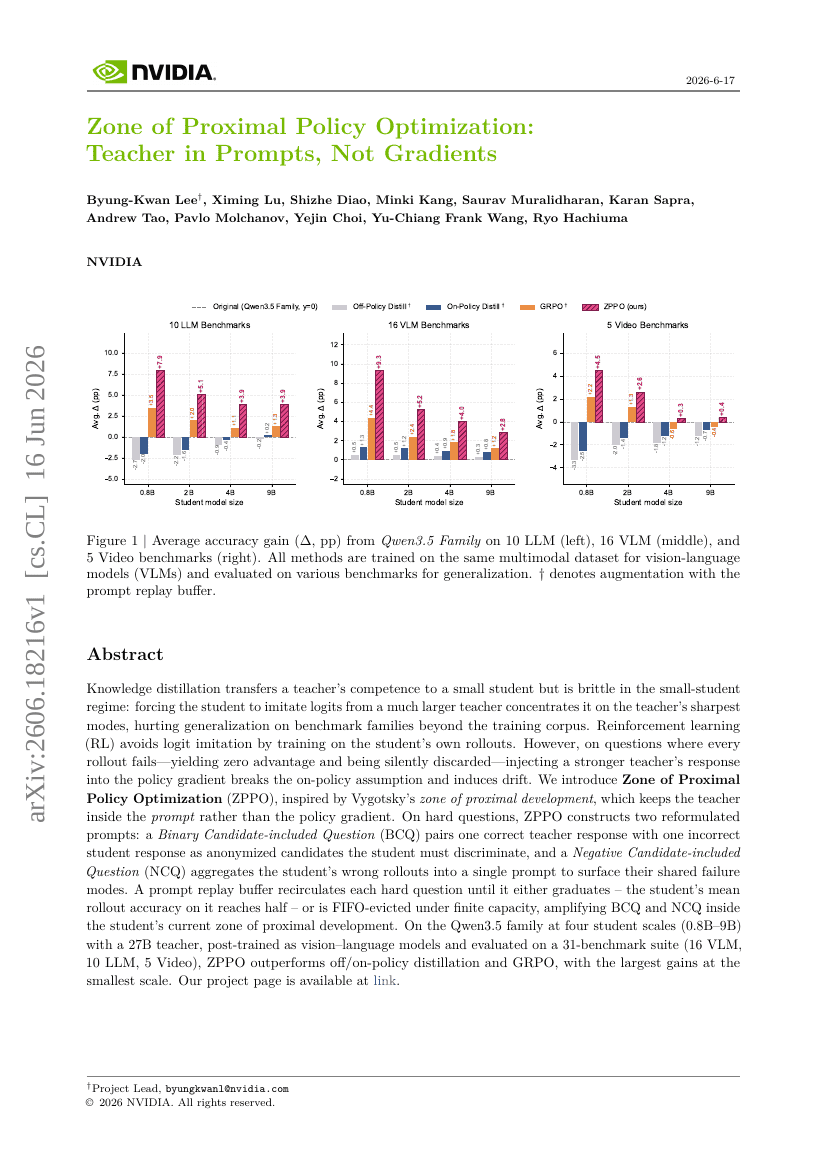
Zone der proximalen Politikoptimierung: Lehrer in Prompts, nicht in Gradienten
ACE-Ego-0: Vereinheitlichung von egozentrischen menschlichen und robotischen Daten für VLA Pretraining
LoopCoder-v2: Nur einmal durchlaufen für effiziente Skalierung der Testzeit-Berechnung
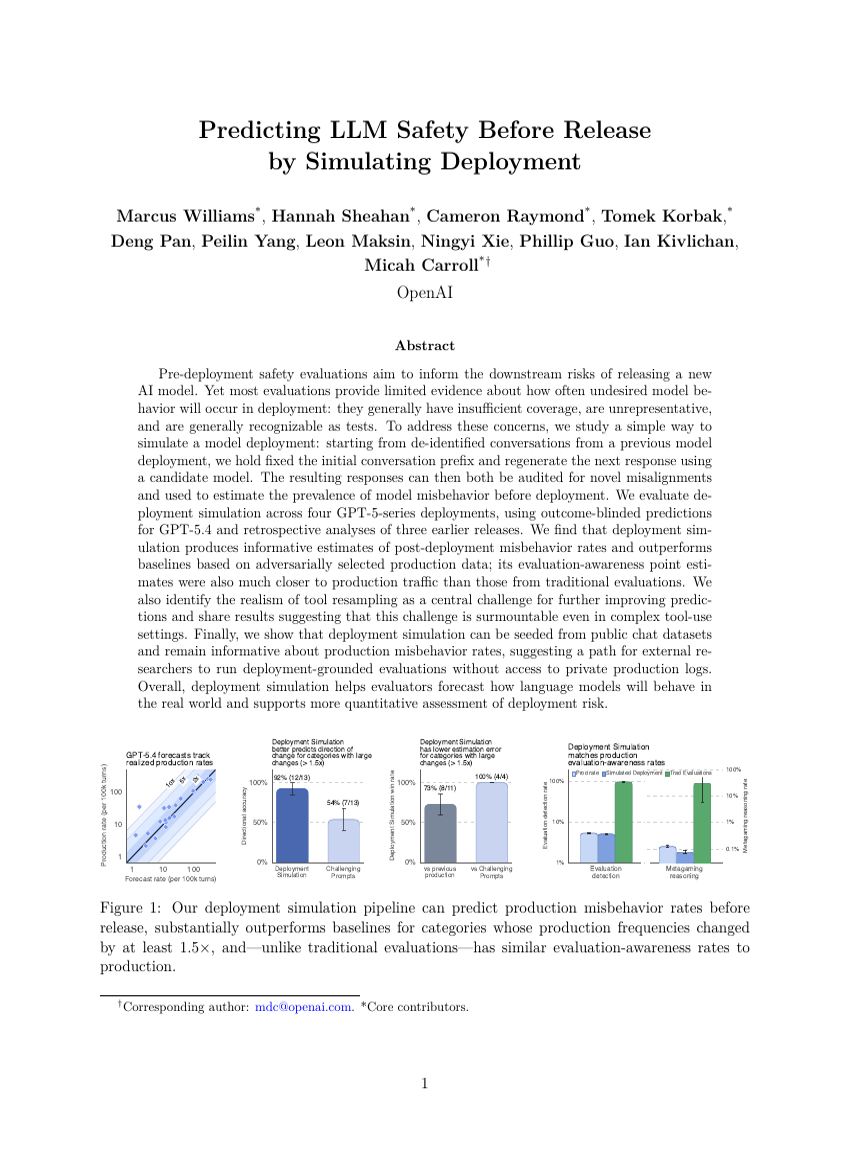
Vorhersage der Sicherheit von LLMs vor der Veröffentlichung durch Simulation des Betriebs
FastContext: Training eines effizienten Repository-Explorers für Coding Agents
VibeThinker-3B: Erforschung der Grenzen überprüfbaren Schlussfolgens in kleinen Sprachmodellen
DreamX-World 1.0: Ein universell einsetzbares interaktives Weltmodell
Mehrfach-Reflektives Masking ermöglicht das Schlussfolgern in Mask-Diffusionsmodellen
BrainG3N: Ein Tokenizer mit zwei Verwendungszwecken zur kontrollierbaren 3D-Gehirn-MRT-Generierung
GateMem: Benchmarking der Speicherverwaltung in Multi-Principal Shared-Memory Agents
MemSlides: Ein hierarchisches, gedächtnisgesteuertes Agent-Framework für die personalisierte Folien-Generierung mit mehrstufiger lokaler Überarbeitung
PerceptionDLM: Parallele Regionswahrnehmung mit multimodalen Diffusionssprachmodellen
Code-World-Modelle für das allgemeine Spielen von Spielen
Jenseits statischer Leaderboards: Prädiktive Validität für die Evaluation von LLM Agents
S-Agent: Räumliche Werkzeugnutzung fördert das Schlussfolgern für räumliche Intelligenz
Multi-LCB: Erweiterung von LiveCodeBench auf mehrere Programmiersprachen
Verspieltes agentices Roboterlernen
DragMesh-2: Physikalisch plausible geschickte Hand-Objekt-Interaktion mit gelenkigen Objekten
Moebius: 0.2B leichtgewichtiges Bildinpainting-Framework mit 10B-Niveau-Leistung
EfficientRollout: Systembewusstes selbstspekulatives Dekodieren für RL-Rollouts
Vertraue dem richtigen Lehrer: Qualitätsbewusste Selbstdistillation für GUI-Verankerung
Verstärkung der Zwei-Pfad-Schlussfolgerung in räumlichen Bild-Sprach-Modellen
SAE-Interventionen sind unzuverlässig: Post-Interventions-Wiederherstellung unterdrückten Verhaltens
Kairos: Ein nativer Weltmodell-Stack für physische KI
Guava: Ein effektiver und universeller Rahmen für verkörperte Manipulation
Jenseits der aktuellen Beobachtung: Evaluation multimodaler großer Sprachmodelle in kontrollierbaren nicht-markovschen Spielen
LifeSciBench: Evaluierung von Language Models für realistische, experten-niveau Aufgabensets in den Life Sciences
TRIAGE: Dialektische Schlussfolgerung für erklärbare Risikovorhersage auf unregelmäßig abgetasteten medizinischen Zeitreihen mit LLMs
LectūraAgents: Ein Multi-Agent-Framework für adaptives personalisiertes KI-unterstütztes Lernen und verkörperten Unterricht
GameCraft-Bench: Können Agents spielbare Spiele End-to-End in einer realen Game-Engine erstellen?
Zone der proximalen Politikoptimierung: Lehrer in Prompts, nicht in Gradienten
ACE-Ego-0: Vereinheitlichung von egozentrischen menschlichen und robotischen Daten für VLA Pretraining
LoopCoder-v2: Nur einmal durchlaufen für effiziente Skalierung der Testzeit-Berechnung
Vorhersage der Sicherheit von LLMs vor der Veröffentlichung durch Simulation des Betriebs
FastContext: Training eines effizienten Repository-Explorers für Coding Agents
VibeThinker-3B: Erforschung der Grenzen überprüfbaren Schlussfolgens in kleinen Sprachmodellen
DreamX-World 1.0: Ein universell einsetzbares interaktives Weltmodell