HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten
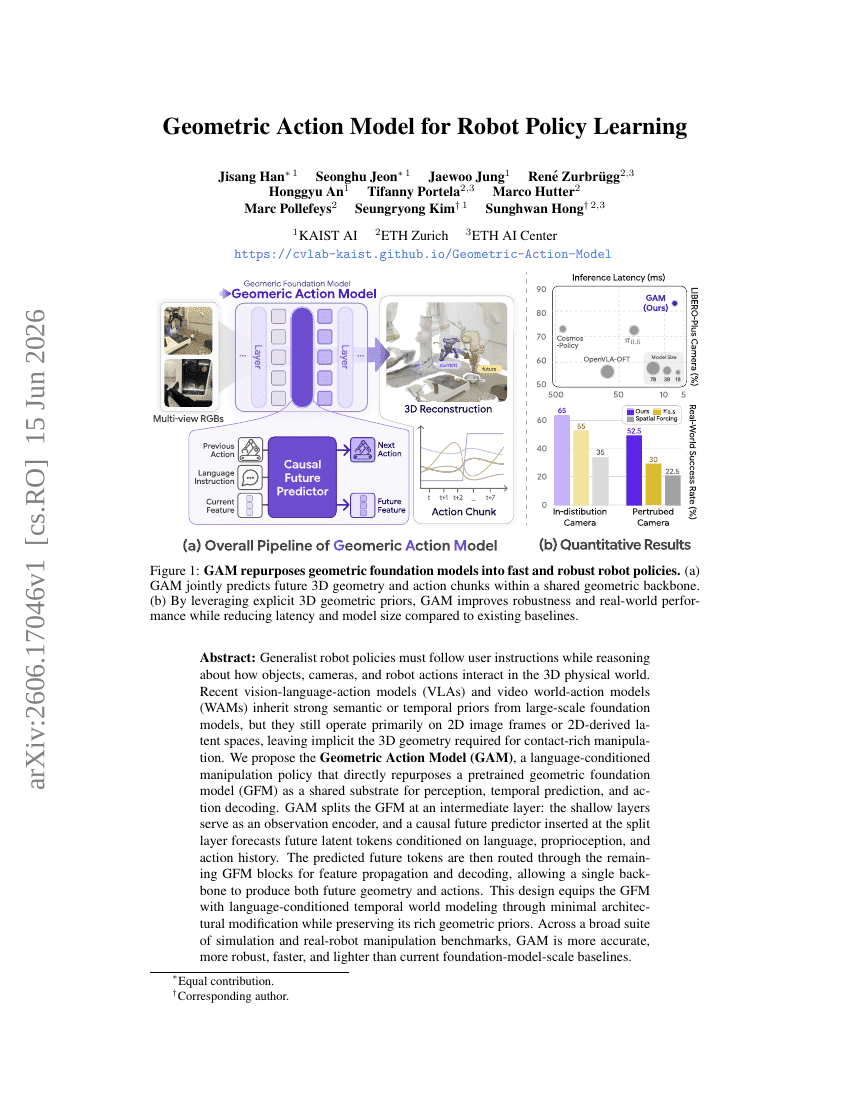
Geometrisches Aktionsmodell für das Roboter-Policy-Lernen

Datenjournalist Agent: Transformieren von Daten in überprüfbare multimodale Geschichten














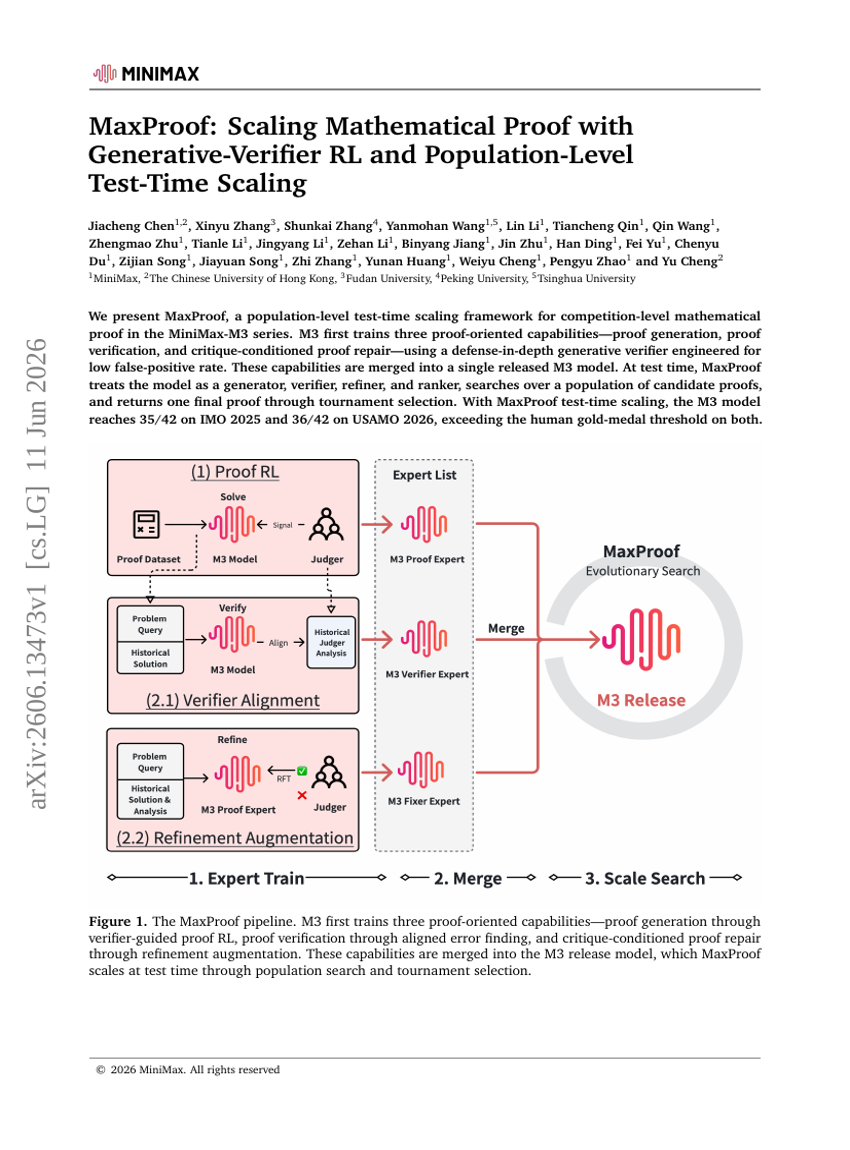
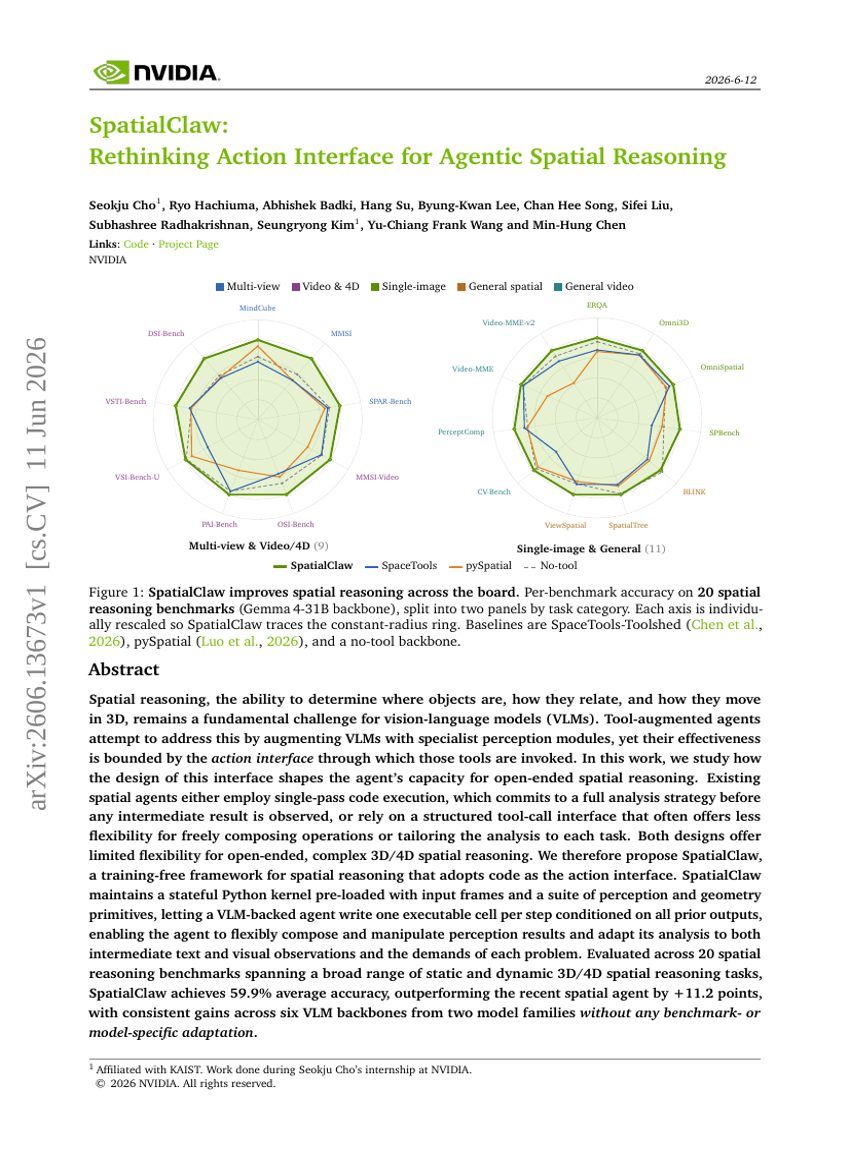


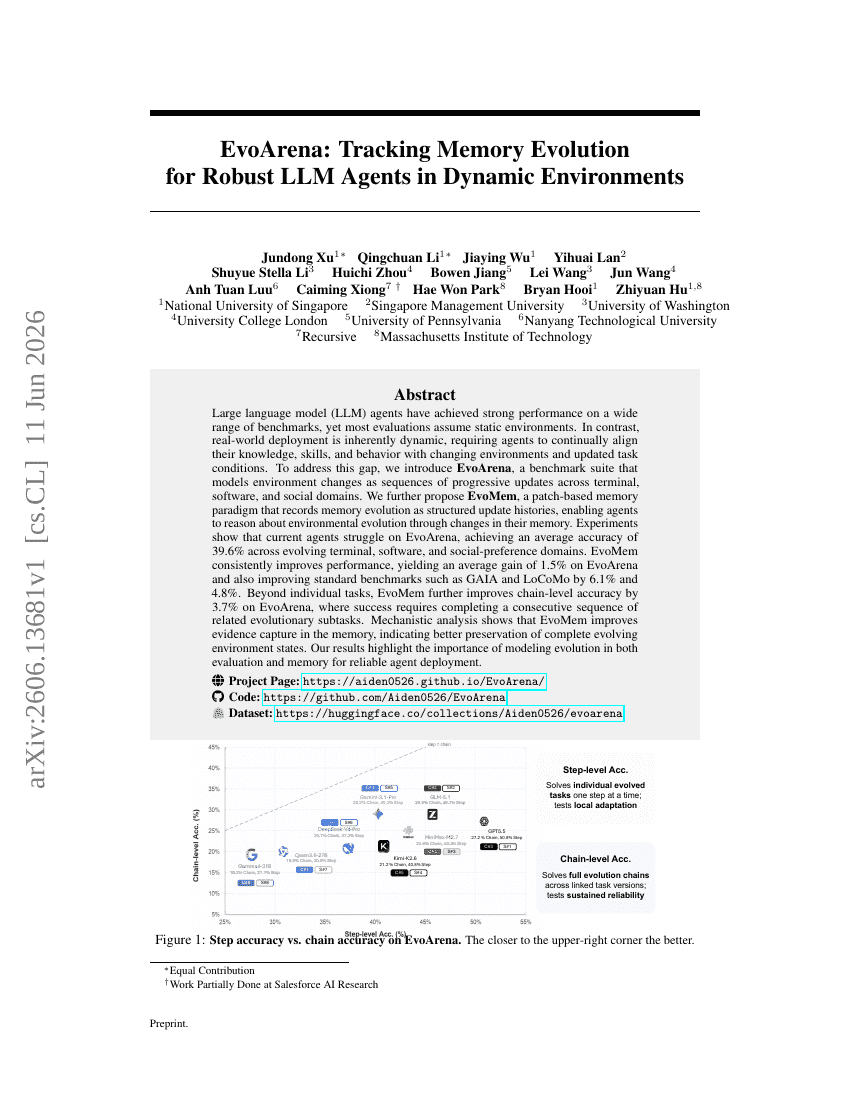

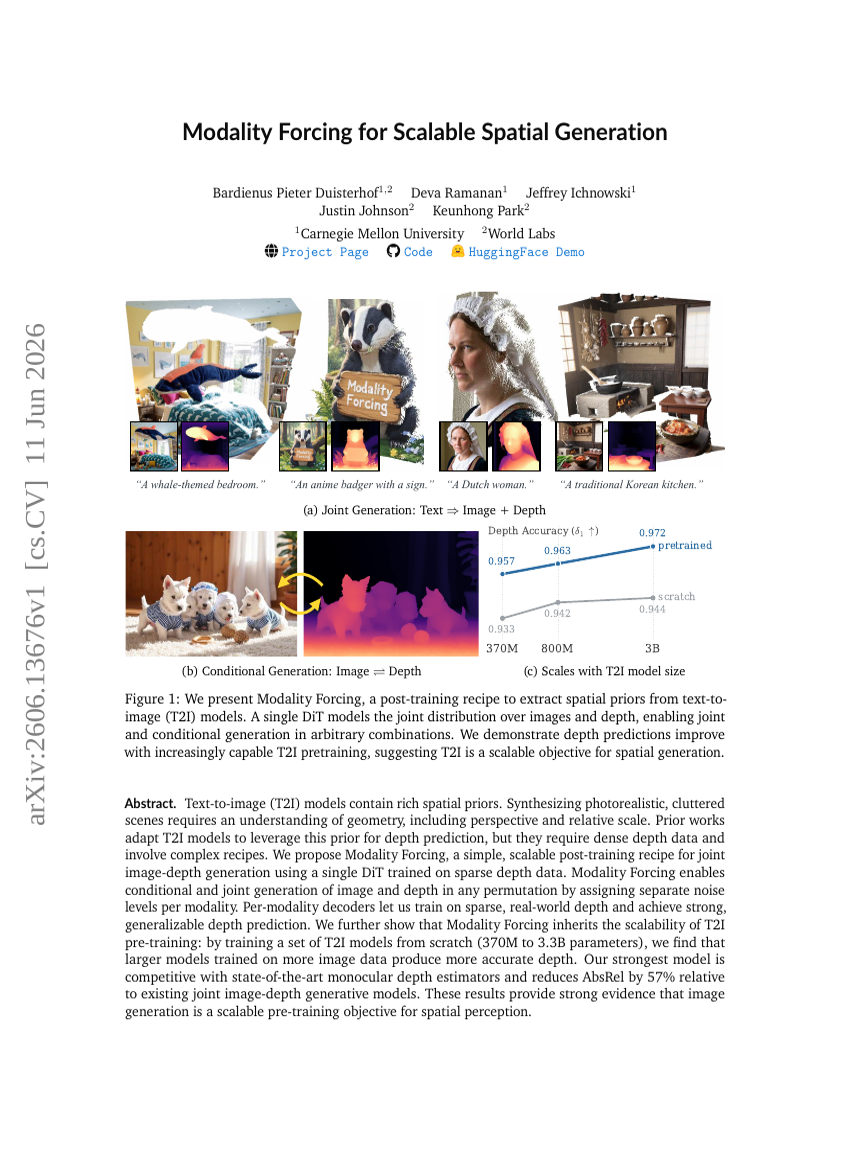







Geometrisches Aktionsmodell für das Roboter-Policy-Lernen
Datenjournalist Agent: Transformieren von Daten in überprüfbare multimodale Geschichten
JoyAI-VL-Interaktion: Echtzeit-Vision-Sprache-Interaktions-Intelligenz
dots.tts Technischer Bericht
Deterministische Videotiefenschätzung mit generativen Vorwissen
Entfaltung von Galaxienbildern für schwache Gravitationslinseneffekte mit unrolltem Plug-and-Play ADMM
Künstliche Intelligenz muss Spezialisierung durch supermenschlich anpassungsfähige Intelligenz umsetzen
Sycophantische Chatbots verursachen wahnhafte Spiralen, selbst bei idealen Bayesians
Agenten des Chaos
HarnessX: Eine komponierbare, adaptive und evolvierbare Agent-Harness-Foundry
Orchestra-o1: Omnimodal Agent Orchestrierung
Vom Chatbot zum digitalen Kollegen: Der Paradigmenwechsel hin zu persistenter autonomer KI
Gedächtnis wird rekonstruiert, nicht abgerufen: Graphenspeicher für LLM Agents
APPO: Agentische Prozedurale Policy-Optimierung
OmniDirector: Allgemeines Multi-Shot-Kamera-Klonen ohne gekreuzte Datenpaare
InterleaveThinker: Stärkung agenzgetriebener interleavierter Generierung
MaxProof: Skalierung mathematischer Beweise durch generativen Verifier-RL und populationsspezifisches Test-Zeit-Skalieren
SpatialClaw: Überdenken der Aktionsschnittstelle für agentische räumliche推理 注:由于题目中的“推理”是中文,为了保持与SCI/SSCI期刊翻译风格的一致性,这里应该使用英文 "Reasoning" 来翻译,因此正确的德语翻译应该是: SpatialClaw: Überdenken der Aktionsschnittstelle für agentisches räumliches Reasoning 但根据要求,只输出输入的内容,所以最终答案为: SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
WEAVEBENCH: Ein Langzeit-Praxis-Benchmark für Computer-Use Agents mit hybriden Schnittstellen
MiniMax-Sparse-Aufmerksamkeit
EvoArena: Verfolgen der Gedächtnisevolution für robuste LLM Agents in dynamischen Umgebungen
Flex4DHuman: Flexible Mehransichts-Videodiffusion für die 4D-Rekonstruktion von Menschen
Modalitäten erzwingen für skalierbare räumliche Generierung
Von AGI zu ASI
Weltverfolgung: Generative geometrische Strukturen, die pixelgenau mit den sichtbaren Daten korrelieren, jenseits des sichtbaren Spektrums
Reguläre f-Divergenz-Kerntests
Pretraining rekurrenter Netzwerke ohne Rekurrenz
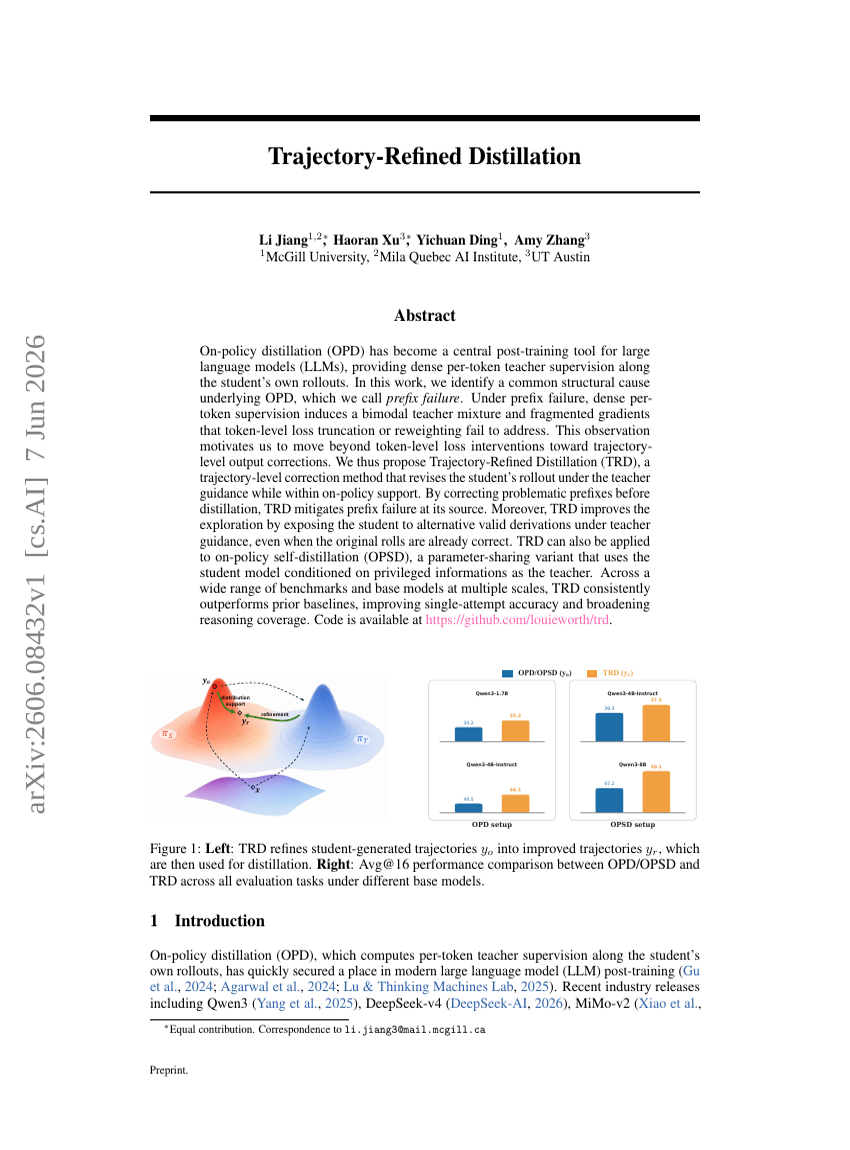
Trajektorienverfeinerte Distillation
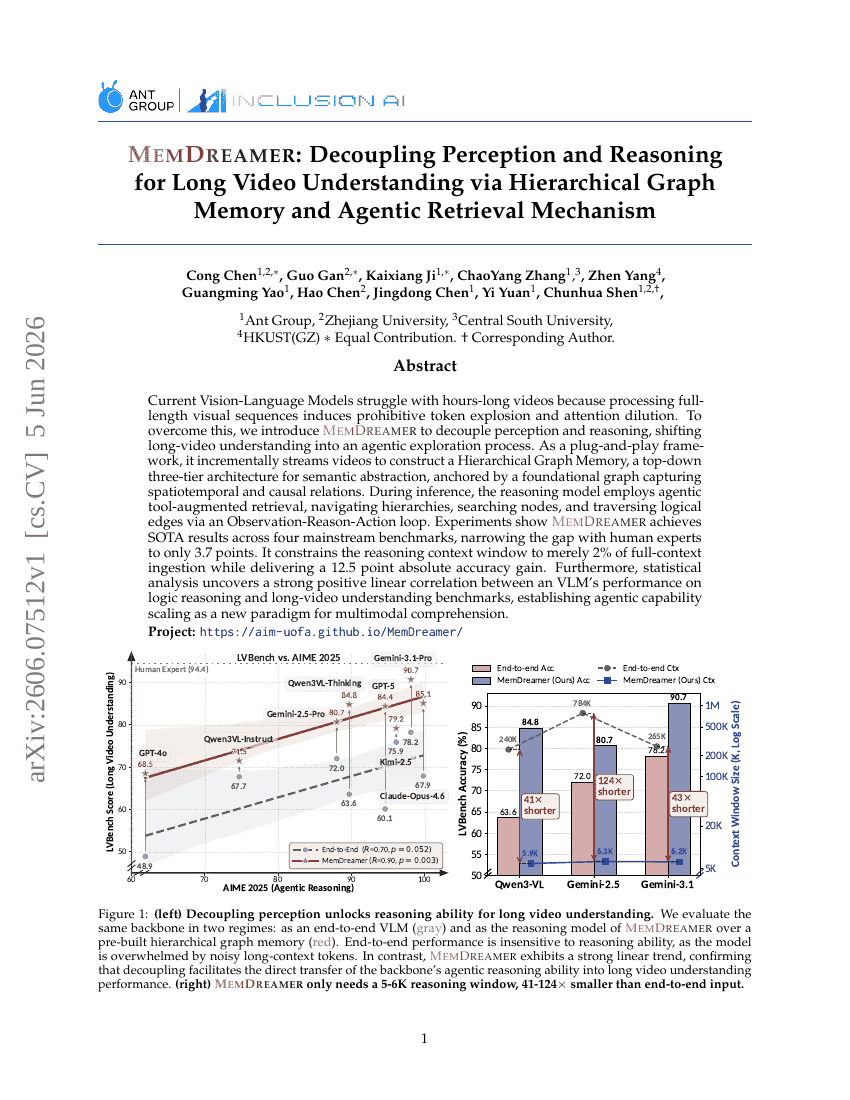
MemDreamer: Entkopplung von Wahrnehmung und Schlussfolgerung für das Verständnis langer Videos mittels Hierarchischem Graphen-Gedächtnis und Agentic Retrieval Mechanismus
SearchSwarm: Hin zu Delegationsintelligenz in Agentic LLMs für Langzeit-Tiefenrecherche
Retrospektive Harness-Optimierung: Verbesserung von LLM-Agents durch Selbstpräferenz gegenüber Trajektorien-Rollouts
Rolle-Agent: Bootstrapping von LLM Agents mittels Dual-Rollen-Evolution
JoyAI-VL-Interaktion: Echtzeit-Vision-Sprache-Interaktions-Intelligenz
dots.tts Technischer Bericht
Deterministische Videotiefenschätzung mit generativen Vorwissen
Entfaltung von Galaxienbildern für schwache Gravitationslinseneffekte mit unrolltem Plug-and-Play ADMM
Künstliche Intelligenz muss Spezialisierung durch supermenschlich anpassungsfähige Intelligenz umsetzen
Sycophantische Chatbots verursachen wahnhafte Spiralen, selbst bei idealen Bayesians
Agenten des Chaos
HarnessX: Eine komponierbare, adaptive und evolvierbare Agent-Harness-Foundry
Orchestra-o1: Omnimodal Agent Orchestrierung
Vom Chatbot zum digitalen Kollegen: Der Paradigmenwechsel hin zu persistenter autonomer KI
Gedächtnis wird rekonstruiert, nicht abgerufen: Graphenspeicher für LLM Agents
APPO: Agentische Prozedurale Policy-Optimierung
OmniDirector: Allgemeines Multi-Shot-Kamera-Klonen ohne gekreuzte Datenpaare
InterleaveThinker: Stärkung agenzgetriebener interleavierter Generierung
MaxProof: Skalierung mathematischer Beweise durch generativen Verifier-RL und populationsspezifisches Test-Zeit-Skalieren
SpatialClaw: Überdenken der Aktionsschnittstelle für agentische räumliche推理 注:由于题目中的“推理”是中文,为了保持与SCI/SSCI期刊翻译风格的一致性,这里应该使用英文 "Reasoning" 来翻译,因此正确的德语翻译应该是: SpatialClaw: Überdenken der Aktionsschnittstelle für agentisches räumliches Reasoning 但根据要求,只输出输入的内容,所以最终答案为: SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
WEAVEBENCH: Ein Langzeit-Praxis-Benchmark für Computer-Use Agents mit hybriden Schnittstellen
MiniMax-Sparse-Aufmerksamkeit
EvoArena: Verfolgen der Gedächtnisevolution für robuste LLM Agents in dynamischen Umgebungen
Flex4DHuman: Flexible Mehransichts-Videodiffusion für die 4D-Rekonstruktion von Menschen
Modalitäten erzwingen für skalierbare räumliche Generierung
Von AGI zu ASI
Weltverfolgung: Generative geometrische Strukturen, die pixelgenau mit den sichtbaren Daten korrelieren, jenseits des sichtbaren Spektrums
Reguläre f-Divergenz-Kerntests
Pretraining rekurrenter Netzwerke ohne Rekurrenz
Trajektorienverfeinerte Distillation
MemDreamer: Entkopplung von Wahrnehmung und Schlussfolgerung für das Verständnis langer Videos mittels Hierarchischem Graphen-Gedächtnis und Agentic Retrieval Mechanismus
SearchSwarm: Hin zu Delegationsintelligenz in Agentic LLMs für Langzeit-Tiefenrecherche
Retrospektive Harness-Optimierung: Verbesserung von LLM-Agents durch Selbstpräferenz gegenüber Trajektorien-Rollouts
Rolle-Agent: Bootstrapping von LLM Agents mittels Dual-Rollen-Evolution