Command Palette
Search for a command to run...
Wenn Werkzeuge versagen: Benchmarking dynamisches Replanning und Anomaliebewältigung in LLM Agents
Wenn Werkzeuge versagen: Benchmarking dynamisches Replanning und Anomaliebewältigung in LLM Agents
Dongsheng Zhu Xuchen Ma Yucheng Shen Xiang Li Yukun Zhao Shuaiqiang Wang Lingyong Yan Dawei Yin
Zusammenfassung
Bestehende Benchmarks evaluieren Tool-Integrated Reasoning (TIR) in LLMs auf idealisierten „happy paths“ und übersehen dabei weitgehend reale Tool-Ausfälle. Wir stellen ToolMaze vor, einen Benchmark zur dynamischen Pfadfindung und Fehlerbehebung in TIR agents. Um systematisches Replanning von blindem Trial-and-Error zu trennen, setzt ToolMaze auf ein zweidimensionales Design: eine DAG-basierte topologische Komplexität sowie eine 2imes2 Taxonomie von Tool-Perturbationen (explizit/implizit, transient/permanent). Die Auswertungen zeigen, dass Perturbationen die Leistung nahezu aller Modelle verschlechtern, wobei die stärksten Einbrüche bei impliziten semantischen Fehlern auftreten. Getrieben von einem systematischen Übertrauen in korrupte Ausgaben, sinkt die Perturbation Recovery Rate (PRR) in diesen Szenarien um etwa 37%, während komplexe Topologien agents in nutzlose Trial-and-Error-Schleifen gefangen halten. Entscheidend ist, dass die agentic fault-tolerance mit der Modellgröße 3.66imes langsamer als die grundlegende Aufgabenausführung zunimmt, was dynamisches Replanning als einen eigenständigen Engpass hervorhebt, der durch Modellskalierung oder Prompting nicht adressiert wird. Die Daten und der Code sind unter https://github.com/Zhudongsheng75/ToolMaze verfügbar.
One-sentence Summary
The authors introduce TOOLMAZE, a benchmark that isolates systematic replanning from blind trial-and-error by evaluating LLM agents across DAG-based topological complexities and a two-by-two taxonomy of tool perturbations, revealing that implicit semantic failures trigger the sharpest performance drops and that fault-tolerance improves with model scale 3.66 times slower than basic execution, thereby identifying dynamic replanning as a distinct bottleneck unaddressed by scaling or prompting.
Key Contributions
- Introduces TOOLMAZE, a benchmark for dynamic path discovery and error recovery in tool-integrated reasoning agents that systematically evaluates fault tolerance under real-world tool failures rather than idealized execution paths.
- Establishes a two-dimensional evaluation framework combining DAG-based topological complexity with a 2×2 taxonomy of explicit, implicit, transient, and permanent tool perturbations to isolate systematic replanning from blind trial-and-error.
- Demonstrates through empirical evaluation that implicit semantic failures reduce the Perturbation Recovery Rate by around 37 percent and that agentic fault-tolerance scales 3.66 times slower than basic task execution, identifying dynamic recovery as a distinct bottleneck unaddressed by model scaling or prompting.
Introduction
Integrating external tools has evolved large language models into dynamic Tool-Integrated Reasoning agents capable of executing complex, multi-step workflows. This capability matters because real-world deployments operate within failure-prone dependency graphs where agents routinely encounter both explicit execution errors and subtle semantic corruptions that can trigger cascading logic failures. Prior evaluation frameworks largely rely on idealized happy-path scenarios or inject random perturbations, leaving them unable to systematically measure an agent's capacity for anomaly detection and structured replanning. The authors introduce TOOLMAZE, a benchmark that frames robustness evaluation as a two-dimensional grid combining directed acyclic graph complexity with controlled perturbation modes. By injecting failures at predetermined nodes and providing exhaustive ground-truth recovery paths, the framework isolates true dynamic replanning capabilities through targeted metrics like recovery cost and perturbation recovery rate, revealing a critical gap between general task success and genuine agentic fault tolerance.
Dataset

-
Dataset composition and sources: The authors compile a curated benchmark of 270 hand-crafted tool simulations modeled after real-world APIs. These tools operate deterministically using static lookup tables, with select implementations maintaining lightweight execution state to replicate actual service behavior. The corpus spans six application domains (Financial, Travel, Office, Shopping, IoT, and General) to cover diverse enterprise and consumer workflows.
-
Key subset details and metadata: Each tool carries two complementary metadata tags: a functional category (Source, Processor, or Action) and an application domain. The dataset organizes these tools into 126 alternative groups that enable multi-path task topologies. Perturbation subsets are structured into four classes (P1 through P4), featuring realistic HTTP error codes and logical corruption types like physics violations, tool leakage, and temporal contradictions. Domain-balanced sampling ensures even distribution across all sectors, while intra-category similarity checks confirm high semantic diversity and minimal template overlap.
-
Data usage and processing workflow: Rather than a training corpus, this dataset functions as a dedicated evaluation benchmark designed to populate a complexity versus perturbation (C×P) evaluation matrix. The authors employ a tool-first generation pipeline that constructs directed acyclic graphs before drafting natural language queries, guaranteeing both semantic coherence and mathematical completeness. They enumerate a ground-truth solution space for each task and designate the shortest valid path as the baseline to quantify agent recovery efficiency. Task naturalization uses a two-stage translation process, followed by a strict reverse validation step where an independent LLM reconstructs tool dependencies to prevent semantic drift.
-
Structural constraints and validation rules: DAG assembly enforces acyclicity and requires every well-formed graph to include at least one Source node and one Action node, bridged by optional Processors. Semantic validation filters incoherent data flows by verifying that upstream outputs meaningfully bind to downstream inputs. Strict parameter binding rules dictate how object and scalar fields are passed between steps, while domain consistency checks explicitly forbid semantically mismatched tool combinations. All simulations are engineered to remove external network dependencies and rate-limit variability, ensuring fully reproducible results without sacrificing structural fidelity.
Method
The TOOLMAZE framework is structured as a pipeline that evaluates large language model (LLM) agents along two orthogonal axes: task complexity (C) and perturbation mode (P). This dual-axis evaluation enables a systematic assessment of an agent's fault tolerance and its capacity to discover alternative valid tool-call paths following failures. The framework integrates task construction, a runtime perturbation engine, and evaluation modules to generate and assess benchmark instances defined by coordinates (C,P).
The task complexity axis, C, governs the topological structure of the directed acyclic graph (DAG) used to represent workflows, determining the number of alternative tool-call paths an agent must consider. Four levels of complexity are defined: C1 (linear) presents a single, unbranching path; C2 (1-to-N alternatives) introduces functionally equivalent substitutes, requiring direct single-step substitution; C3 (many-to-many multi-path) creates a combinatorial space of valid recovery paths across interacting sub-graphs, testing breadth-first planning; and C4 (integrated multi-branch) combines multiple C2 and C3 patterns within a single DAG, demanding the agent to reason over multiple branching nodes, each potentially containing 1-to-N or many-to-many recovery subgraphs. The perturbation mode axis, P, dictates the nature of the failure encountered during agent inference. This axis is defined by a 2×2 taxonomy based on error manifestation and temporal persistence. Explicit failures involve machine-readable exceptions, such as HTTP 404 errors, which obstruct program execution, while implicit failures generate structurally compliant but semantically flawed outputs, necessitating autonomous verification. Temporal persistence distinguishes transient failures, resolvable via simple retries, from permanent ones that require dynamic rerouting or graceful termination. These dimensions yield four distinct modes: P1 (Explicit-Transient), P2 (Explicit-Permanent), P3 (Implicit-Transient), and P4 (Implicit-Permanent).
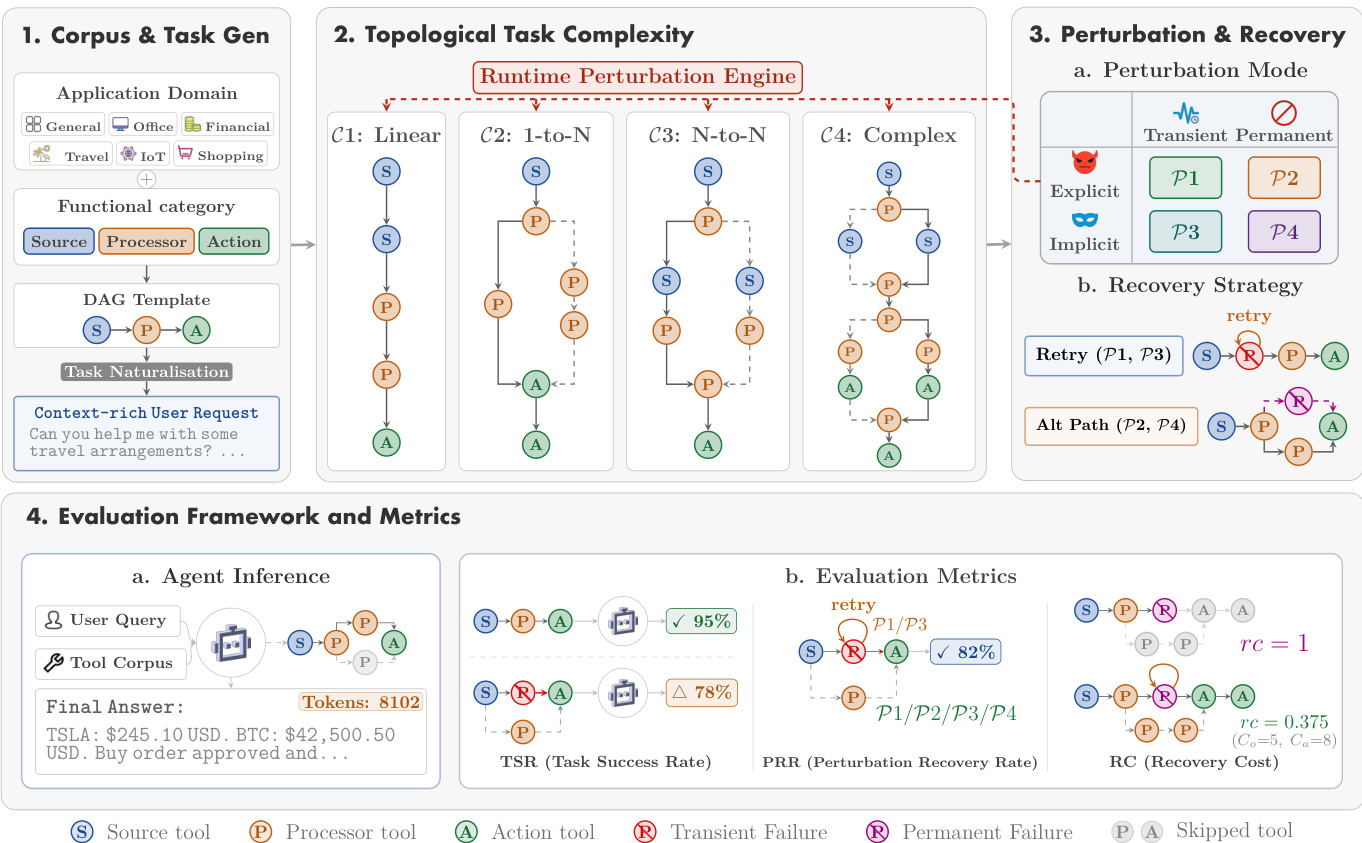
The runtime perturbation engine is responsible for dynamically realizing the P-axis during agent inference. It employs deterministic perturbation injection, where each task is assigned a perturbation profile specifying which tool on the preferred path should fail and the synthetic response to return. At runtime, when the agent calls a tool, the engine checks this profile; if the call matches a fault rule, it returns the pre-specified synthetic response; otherwise, it forwards the call to the standard tool simulator. This ensures that every model under evaluation receives identical injected fault responses, eliminating variance from the perturbation mechanism. Fault activation rules are applied in multi-path tasks, where faults are associated with an alternative group instead of a fixed tool. Once the agent invokes any tool in the group, the engine assigns the fault to that chosen tool and disables further activations within the same group, ensuring the perturbation is triggered regardless of the selected valid path while preventing multiple alternatives in the same group from being perturbed simultaneously. For C2 and C3 tasks, this mechanism is applied globally to the single alternative group. For C4 tasks, it is applied independently per parallel slot, so each branch can trigger at most one local perturbation without affecting the others. After activation, the P-axis semantics apply uniformly: P1 and P3 faults affect only the initial invocation, whereas P2 and P4 faults make the targeted tool permanently unavailable or corrupted.
The framework's overall architecture is illustrated in Figure 2. The process begins with corpus and task generation, where application domains and functional categories are selected to create a context-rich user request. This request is then naturalized into a DAG template, forming the basis for the task. The topological task complexity levels C1 through C4 are defined, each with distinct DAG topologies. The runtime perturbation engine, which is responsible for injecting the P-axis perturbations, is integrated into the evaluation pipeline. The evaluation metrics assess agent performance, including the task success rate (TSR), perturbation recovery rate (PRR), and recovery cost (RC), which measure the agent's ability to handle failures and recover efficiently. The evaluation framework also includes agent inference, where the agent processes the user query and tool corpus to generate a final answer. The entire process is designed to comprehensively assess resilient replanning strategies under diverse failure conditions.
Experiment
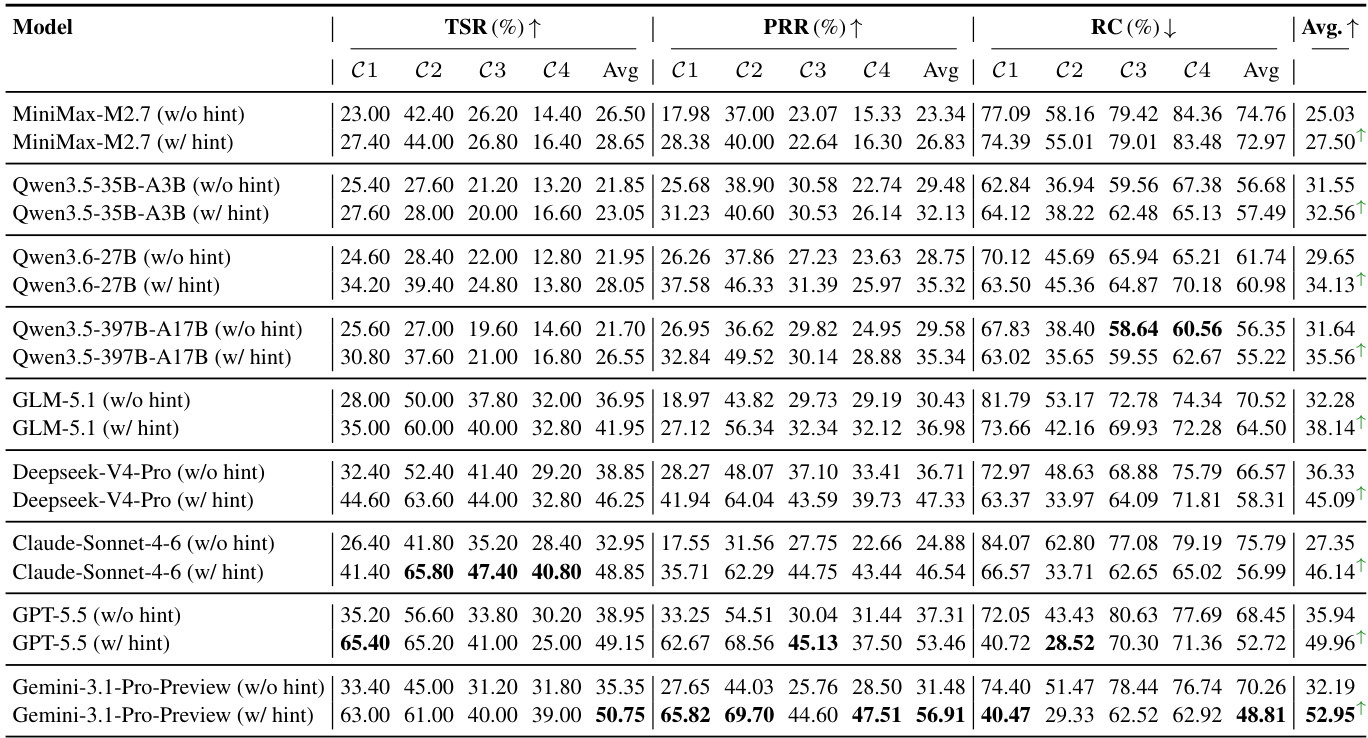
The evaluation framework tests a range of open-weight and proprietary LLMs on the TOOLMAZE benchmark, which systematically introduces explicit and implicit transient or permanent tool failures across varying topological complexities to validate agents' dynamic replanning and error recovery capabilities. Results demonstrate that navigating idealized execution paths and recovering from real-world anomalies are fundamentally decoupled, as even state-of-the-art models experience significant performance degradation and elevated recovery costs under perturbation. While failure-aware prompting and moderate task complexity provide partial mitigation, agents consistently struggle with implicit semantic failures due to systemic over-trust in corrupted outputs. Furthermore, fault tolerance scales at a significantly slower rate than baseline task completion, indicating that robust dynamic replanning remains a distinct bottleneck that current model scaling and prompting strategies fail to address.
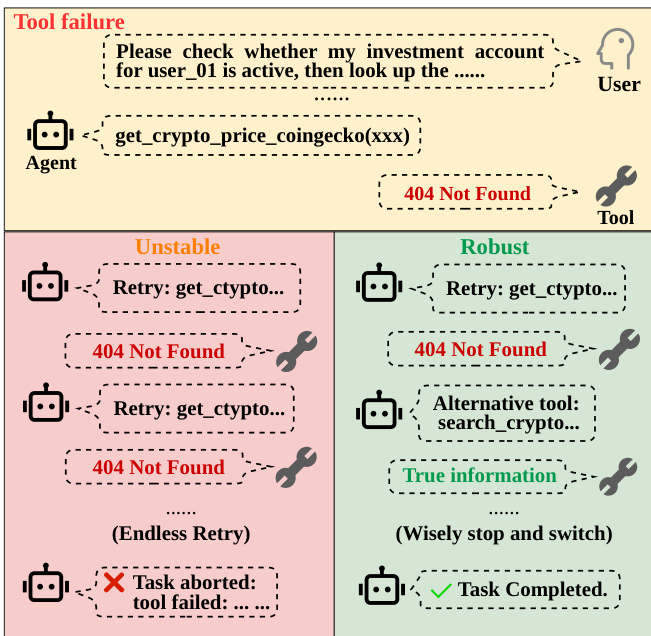
The authors evaluate the robustness of various language models in handling tool-use failures under different perturbation modes and task complexities. Results show that models perform significantly worse under perturbations compared to non-perturbed conditions, with performance degradation being more severe under implicit semantic failures. The use of a failure-aware prompt improves recovery capabilities, but the gap between basic task execution and fault-tolerance remains substantial, indicating that dynamic replanning is a distinct challenge not resolved by model scaling alone. Models exhibit significant performance drops under perturbations, with the sharpest declines occurring in implicit semantic failure scenarios. The failure-aware prompt consistently improves recovery outcomes, but the overall gap in fault-tolerance persists across all models. Fault-tolerance improves at a much slower rate than basic task execution with increasing model size, highlighting a distinct capability gap in dynamic replanning.
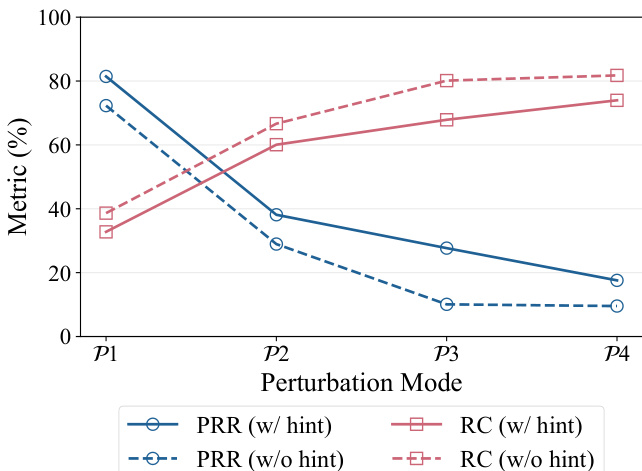
The authors evaluate the performance of LLMs on a benchmark that tests dynamic replanning and error recovery in tool-use tasks under various perturbation modes. Results show that recovery success rates decline and recovery costs increase as perturbations shift from explicit and transient to implicit and permanent, indicating that agents struggle more with deceptive failures. The failure-aware prompt improves recovery performance but does not eliminate the gap between simple and complex failures. Recovery success rates decrease and recovery costs increase as perturbations become more implicit and permanent. The failure-aware prompt consistently improves recovery performance compared to the standard prompt. Agents exhibit a significant drop in recovery success under implicit semantic failures, indicating a fundamental challenge in detecting and recovering from deceptive errors.
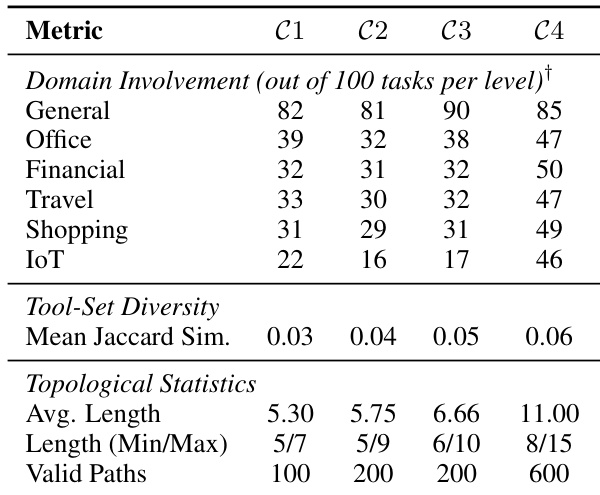
The the the table provides an overview of the task complexity levels used in the experiment, detailing domain involvement, tool-set diversity, and topological statistics across four complexity levels (C1 to C4). As complexity increases from C1 to C4, domain involvement varies, tool-set diversity increases, and topological complexity grows significantly, with longer average paths and a higher number of valid execution paths. These metrics indicate that tasks become more diverse and structurally complex with higher complexity levels. Domain involvement varies across complexity levels, with General and IoT domains showing higher participation in more complex tasks. Tool-set diversity increases with complexity, as measured by Mean Jaccard Similarity. Topological complexity grows with complexity level, indicated by longer average paths and a larger number of valid execution paths in higher levels.
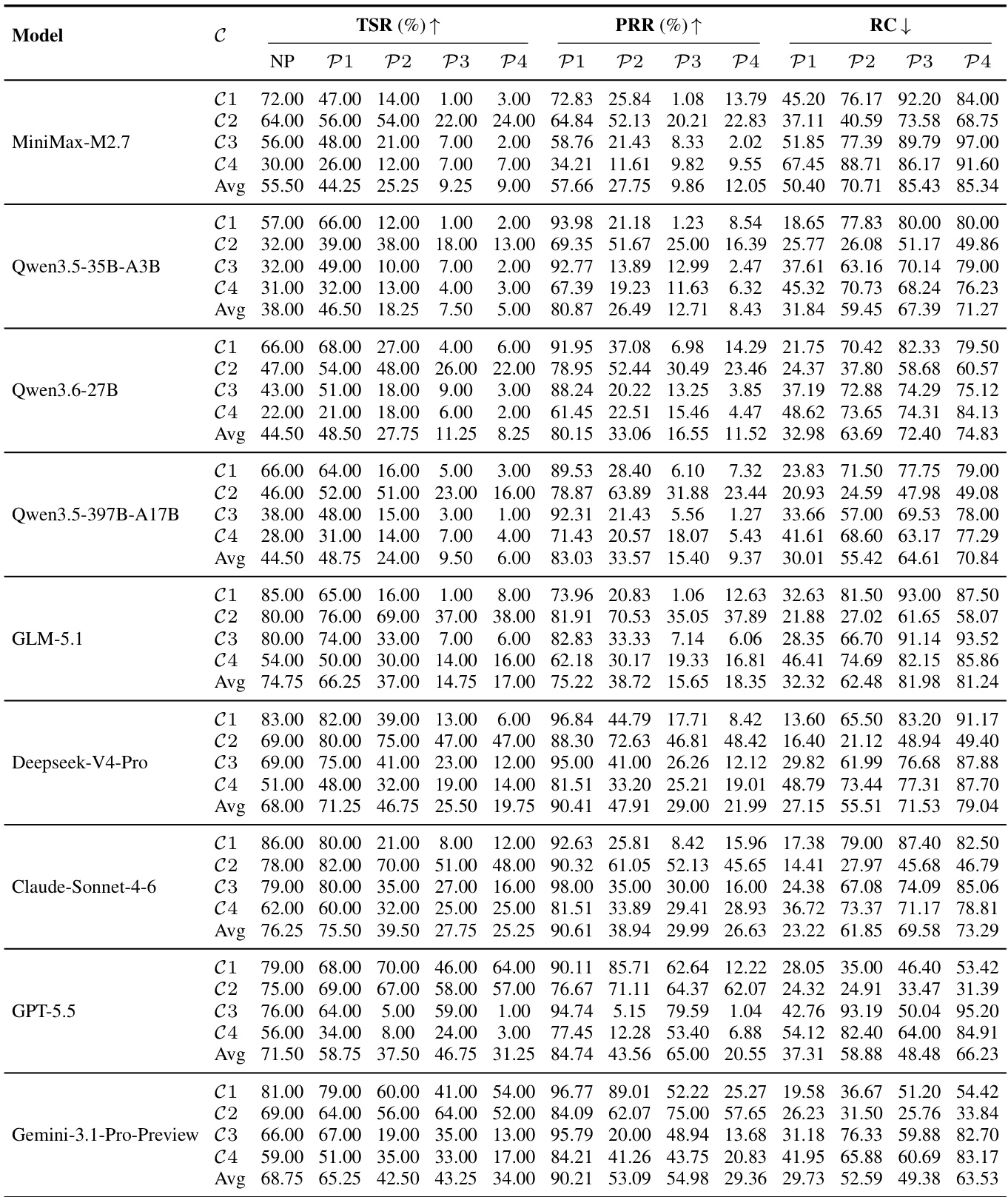
The authors evaluate a range of language models on a benchmark designed to assess robustness in tool-use scenarios involving perturbations and varying task complexity. Results show that models exhibit significant performance degradation under perturbed conditions compared to non-perturbed settings, with recovery capabilities and replanning efficiency being particularly affected. The evaluation reveals that model scale improves task completion more rapidly than fault-tolerance, and explicit prompting provides only partial improvement in handling implicit semantic failures. Models show substantial performance drops under perturbation compared to non-perturbed settings, indicating that robustness is not a natural by-product of general task proficiency. Recovery performance declines and recovery cost increases as perturbations become more implicit and persistent, suggesting a fundamental challenge in detecting semantic errors. Fault-tolerance improves much more slowly with model size than task completion, highlighting dynamic replanning as a distinct capability not addressed by scaling alone.
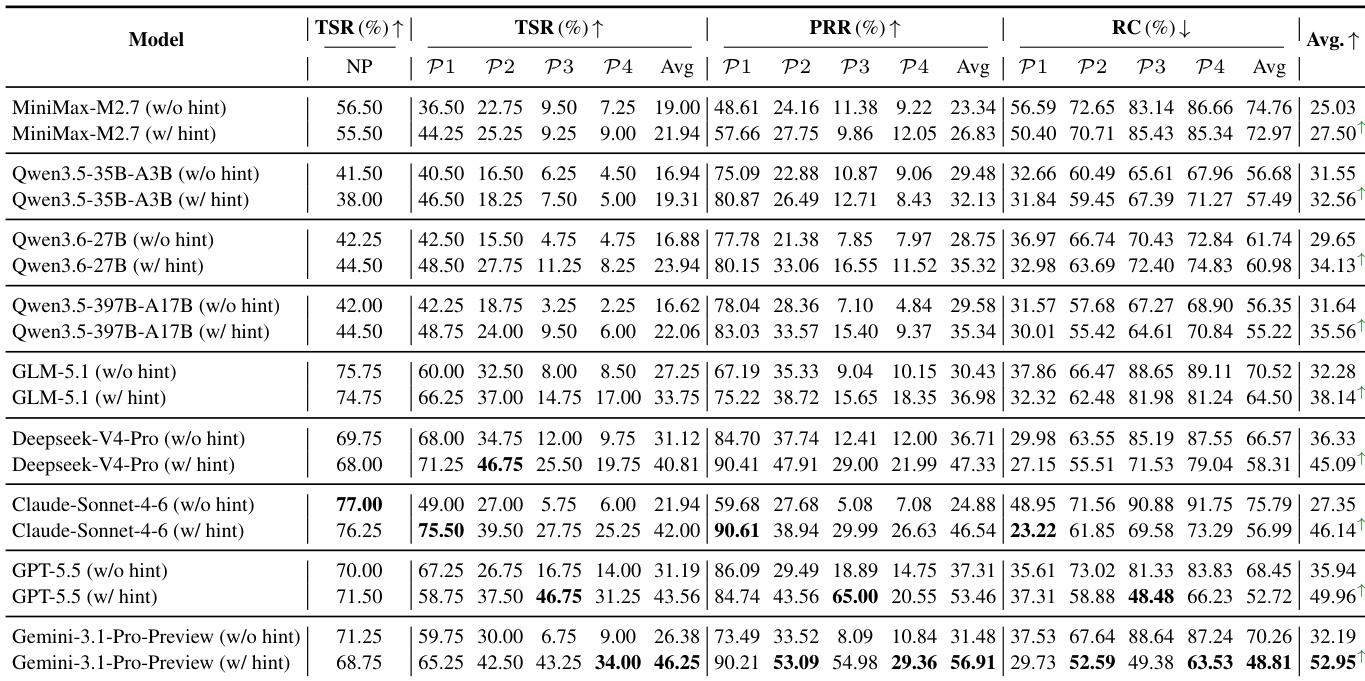
The authors evaluate a range of large language models on a benchmark designed to test dynamic path discovery and error recovery in tool-integrated reasoning. Results show that performance degrades significantly under perturbation conditions compared to non-perturbed settings, with explicit and implicit failures affecting recovery differently. The failure-aware prompt consistently improves outcomes, but models still struggle with implicit semantic errors and exhibit inefficient replanning, especially in complex scenarios. Performance drops sharply under perturbation modes compared to non-perturbed conditions, indicating that recovery is a distinct challenge from basic task completion. Explicit perturbations are easier to handle than implicit ones, with models showing much lower recovery rates and higher recovery costs for semantic errors. A failure-aware prompt improves recovery, but models still fail to recover effectively from persistent implicit failures, suggesting a fundamental limitation in anomaly detection and replanning.
The experiments evaluate large language models on a benchmark designed to assess dynamic replanning and error recovery during tool-use tasks across varying perturbation modes and increasing complexity levels. Results indicate that model performance degrades substantially under perturbations, with implicit semantic failures posing the greatest challenge for detection and recovery. While failure-aware prompting and increased model scale both enhance basic task execution, they only partially improve fault-tolerance, revealing a persistent gap in handling deceptive errors. Ultimately, the findings demonstrate that robust dynamic replanning remains a distinct capability that cannot be resolved through scaling or standard prompting alone.