Command Palette
Search for a command to run...
VideoKR: Hin zu wissens- und reasoningintensivem Video-Verständnis
VideoKR: Hin zu wissens- und reasoningintensivem Video-Verständnis
Lin Fu Zheyuan Yang Yang Wang Tingyu Song Arman Cohan Yilun Zhao
Zusammenfassung
Wir stellen VideoKR vor, den ersten großskaligen Trainingskorpus, der speziell entwickelt wurde, um das wissens- und reasoningintensive Video-Verständnis zu stärken. Er umfasst 315K Video-Reasoning-Beispiele zu 145K neu gesammelten, CC-lizenzierten Videos aus Expertenbereichen. Wir entwickeln eine human-in-the-loop, skillorientierte Pipeline zur Beispielgenerierung, die darauf abzielt, zunehmend tiefere Video-Reasoning-Fähigkeiten zu fördern, wobei gleichzeitig die Schwierigkeit, Vielfalt und Zuverlässigkeit sowohl der Beispiele als auch ihrer CoT-Begründungen sichergestellt wird. Zudem kuratieren wir VideoKR-Eval, einen neuen, von Experten annotierten Benchmark, bei dem die Fragen echtes Video-Verständnis und wissensintensives Reasoning erfordern, anstatt auf textliche Abkürzungen zurückzugreifen. Unsere Experimente zeigen, dass unter einer standardmäßigen SFTrightarrowGRPO-Pipeline auf VideoKR nachtrainierte Modelle das wissensintensive Video-Reasoning im Vergleich zu früheren Post-Training-Ansätzen übertreffen, während sie beim allgemeinen Video-Reasoning wettbewerbsfähig bleiben. Dies unterstreicht das Daten-Design als einen entscheidenden Treiber für Fortschritte im Video-Reasoning. Darüber hinaus führen wir umfassende Ablationen durch, um die Beiträge von VideoKR isoliert zu bewerten, und liefern damit handlungsrelevante Erkenntnisse für zukünftige Forschungsarbeiten.
One-sentence Summary
VideoKR introduces a 315K-example corpus derived from 145K CC-licensed expert-domain videos and a human-in-the-loop, skill-oriented generation pipeline that ensures reliable chain-of-thought rationales, enabling models post-trained via an SFT-to-GRPO pipeline to outperform prior approaches on knowledge-intensive reasoning while remaining competitive on general tasks, as validated by the expert-annotated VideoKR-Eval benchmark.
Key Contributions
- This work introduces VideoKR, a large-scale training corpus comprising 315,000 video reasoning examples generated from 145,000 newly collected, CC-licensed videos spanning 82 professional domains.
- A skill-oriented example generation pipeline decomposes video understanding into three complementary capabilities and employs human-in-the-loop verification to ensure the difficulty, diversity, and reliability of examples paired with Chain-of-Thought rationales.
- VideoKR-Eval, a new expert-annotated benchmark, is curated to prevent textual shortcuts, and experiments demonstrate that models post-trained on the proposed corpus outperform prior approaches on knowledge-intensive video reasoning tasks.
Introduction
Multimodal foundation models for video understanding have advanced rapidly, yet they remain constrained when transitioning from basic visual perception to complex reasoning tasks that demand domain expertise and multi-step inference. Existing training datasets predominantly target surface-level perception and everyday activities, leaving models ill-equipped to handle specialized domains, scientifically grounded explanations, or non-observable principles. To address this gap, the authors introduce VideoKR, the first large-scale corpus explicitly designed for knowledge- and reasoning-intensive video understanding. They curate 145,000 professionally sourced videos across 82 domains and deploy a skill-oriented question-answering framework that decomposes reasoning into three core capabilities, pairing each example with high-quality chain-of-thought rationales. By providing both supervised fine-tuning and reinforcement learning datasets alongside a rigorously vetted evaluation benchmark, the authors demonstrate that standard post-training on VideoKR significantly outperforms existing approaches without requiring complex reward engineering.
Dataset
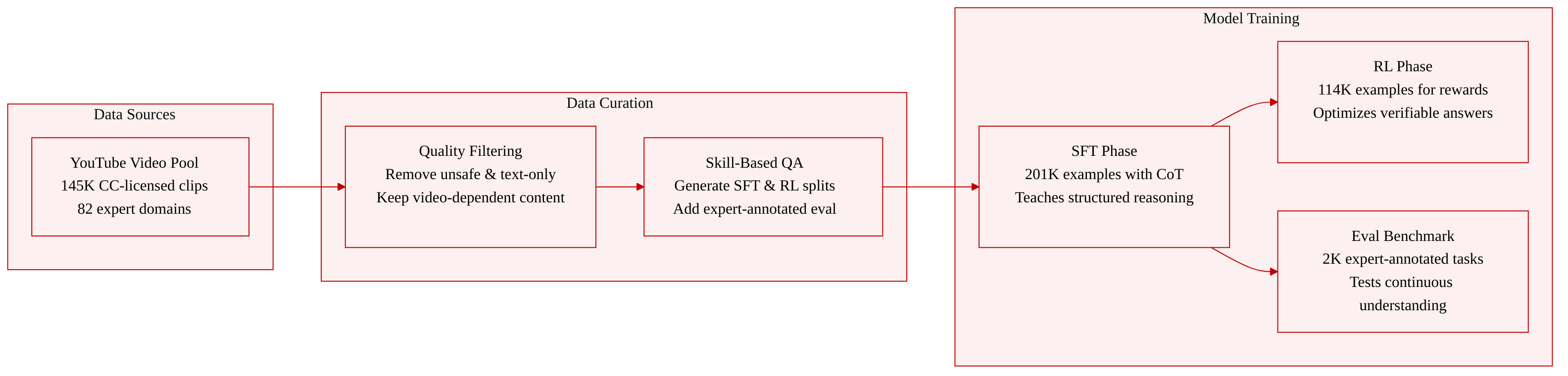
-
Dataset Composition and Sources
- The authors introduce VideoKR, a large-scale training corpus comprising 315,537 video reasoning examples drawn from 145,000 newly collected videos.
- All source videos are CC-licensed and retrieved via the YouTube Data API, focusing on expert-domain scenarios across 82 undergraduate subjects in Natural Sciences, Healthcare, Humanities and Social Sciences, and Engineering.
- The corpus is organized through a four-layer Domain Knowledge Bank (Subject, Course, Lecture, and Knowledge Point) containing 63,745 validated knowledge points to guide video retrieval and question generation.
-
Subset Details
- VideoKR-SFT-201K: Contains 201,000 examples allocated for supervised fine-tuning. Each entry includes a question, answer options, and a validated chain-of-thought rationale.
- VideoKR-RL-114K: Comprises 114,000 examples reserved for reinforcement learning with verifiable rewards. These entries retain only the question and final answer to allow the policy model to generate its own reasoning traces during optimization.
- VideoKR-Eval: A 2,000-example benchmark built by filtering and re-annotating samples from VideoMMMU, MMVU, and SciVideoBench. It retains 1,254 original examples that require continuous video understanding and adds 746 expert-reannotated questions grounded in visual evidence.
-
Training Usage and Processing
- The authors partition the full dataset randomly while preserving video-level grouping to create the SFT and RLVR splits.
- Models are post-trained using a standard SFT followed by a GRPO pipeline. The SFT phase learns structured reasoning from the 201K examples, while the RL phase optimizes against verifiable answers using the 114K subset.
- Example generation follows a skill-oriented framework targeting three capabilities: Basic Video Reasoning, Knowledge-enhanced Video Perception, and Knowledge-Intensive Video Reasoning. Questions are formatted as multiple-choice or open-ended prompts to support verifiable RLVR supervision.
-
Filtering, Cropping, and Metadata Construction
- Videos exceeding 30 minutes are excluded to align with the model context limits.
- The authors apply a multi-stage filtering pipeline that removes unsafe content via Azure AI moderation, screens for relevance using both textual metadata and visual MLLM assessments, and enforces strict video dependency by discarding any example solvable with text plus a single frame.
- Reasoning traces undergo self-consistency verification and independent MLLM validation to ensure each step is grounded in observable evidence or standard domain knowledge.
- To prevent evaluation leakage, the corpus undergoes YouTube-ID matching and near-duplicate detection using perceptual hashing on 20-second video windows.
- All synthetic steps are audited through a human-in-the-loop protocol that dynamically selects from a pool of seven frontier models based on strict error rate thresholds.
Method
The authors leverage a structured, multi-stage pipeline for constructing the VideoKR dataset, which is designed to support knowledge- and reasoning-intensive video understanding. The framework begins with domain knowledge bank construction, where 63,745 knowledge points are curated across 82 subjects and four disciplines, forming the basis for targeted video collection. Each knowledge point is used to generate search keywords, which are then used to retrieve videos with closed captions from a large-scale video repository. The retrieved videos are subsequently filtered based on relevance to the targeted scenarios, ensuring alignment with the underlying knowledge domain.
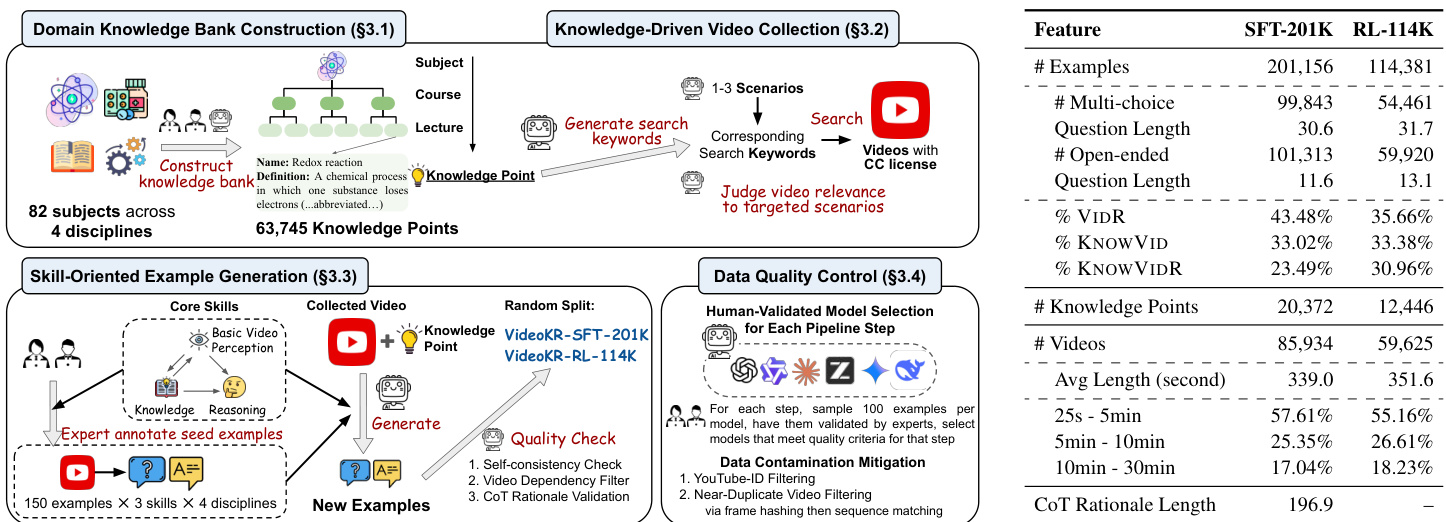
As shown in the figure below, the process continues with skill-oriented example generation, where core skills such as basic video perception and reasoning are defined. Expert annotators generate seed examples using a structured template that includes a video input, a question, and a correct answer. These examples are used to train models to generate new video-based questions and answers. The generated examples are then subjected to a quality check process that includes self-consistency checks, video dependency filtering, and CoT rationale validation to ensure high-quality, logically sound outputs. The resulting dataset is split into SFT-201K and RL-114K subsets, with the RL subset used for reinforcement learning.
Data quality control is enforced through human-validated model selection, where for each step, 100 examples are sampled per model and evaluated by experts to ensure they meet quality criteria. This process includes data contamination mitigation strategies such as YouTube-ID filtering and near-duplicate video filtering via frame hashing and sequence matching. The final dataset contains 85,934 videos for SFT and 59,625 for RL, with an average length of 339 seconds and 351.6 seconds, respectively. The dataset is further characterized by its distribution of multi-choice and open-ended questions, as well as the percentage of videos containing knowledge points and their respective rationale lengths.
For post-training, the authors adopt a standard supervised fine-tuning (SFT) followed by GRPO (Generalized Reinforcement Policy Optimization) pipeline. The base models used are Qwen2.5-VL-7B-Instruct and Qwen3-VL-8B-Instruct, with SFT performed on the VideoKR-SFT-201K dataset for one epoch. The resulting SFT checkpoint is then used to run GRPO on the VideoKR-RL-114K dataset for one epoch. For Qwen3-VL-8B-Instruct, a Zero-RL training approach is also evaluated by directly applying GRPO to the RL dataset. The training setup uses a batch size of 32, with a maximum video token number of 4,096 and a maximum of 128 frames. The GRPO reward function combines format and accuracy rewards, defined as R=0.1⋅Rf+0.9⋅Ra, where Rf is 1.0 if the output satisfies the required format and Ra uses ROUGE for open-ended QA and Exact Match for multiple-choice tasks. Training is conducted on up to 8 NVIDIA A800 GPUs, with learning rates of 1×10−5 for SFT and 5×10−6 for RL, optimized with AdamW. The maximum response length is set to 2,048 tokens, and GRPO rollout generation uses a rollout size of 8 and a temperature of 1.0, with a KL penalty coefficient of 0.01.
Experiment
The evaluation employs a standardized protocol across general and knowledge-intensive video reasoning benchmarks to ensure fair comparisons by mitigating prior prompt misalignment issues. Main experiments validate that post-training on VideoKR consistently enhances capabilities, particularly when combining supervised fine-tuning with reinforcement learning, while ablation studies confirm that integrating diverse reasoning skills and chain-of-thought supervision is essential for advanced performance. Frame-scaling and qualitative analyses further demonstrate that the model effectively leverages richer temporal evidence and exhibits deeper, insight-driven reasoning patterns. Ultimately, the results highlight that VideoKR surpasses existing corpora by providing a sufficiently challenging data distribution that drives meaningful capability gains beyond what saturated benchmarks can offer.
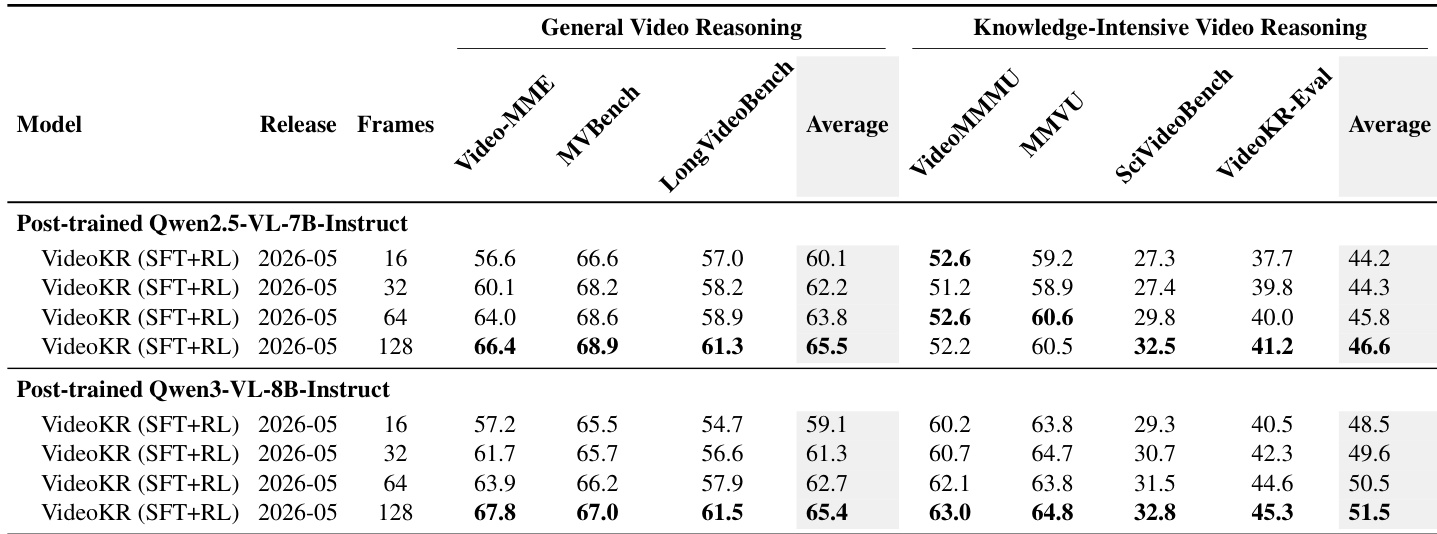
The authors evaluate post-trained models on video reasoning benchmarks, focusing on improvements from training with VideoKR data. Results show that post-training on VideoKR enhances performance, particularly on knowledge-intensive tasks, with gains observed across different model scales and training configurations. The improvements are most significant for models trained with both supervised fine-tuning and reinforcement learning, and the benefits are consistent across varying input frame counts. Post-training on VideoKR consistently improves model performance, especially on knowledge-intensive video reasoning tasks. Models trained with both supervised fine-tuning and reinforcement learning achieve higher performance than those trained with either method alone. The benefits of VideoKR training are consistent across different input frame budgets, indicating robustness to inference-time frame scaling.
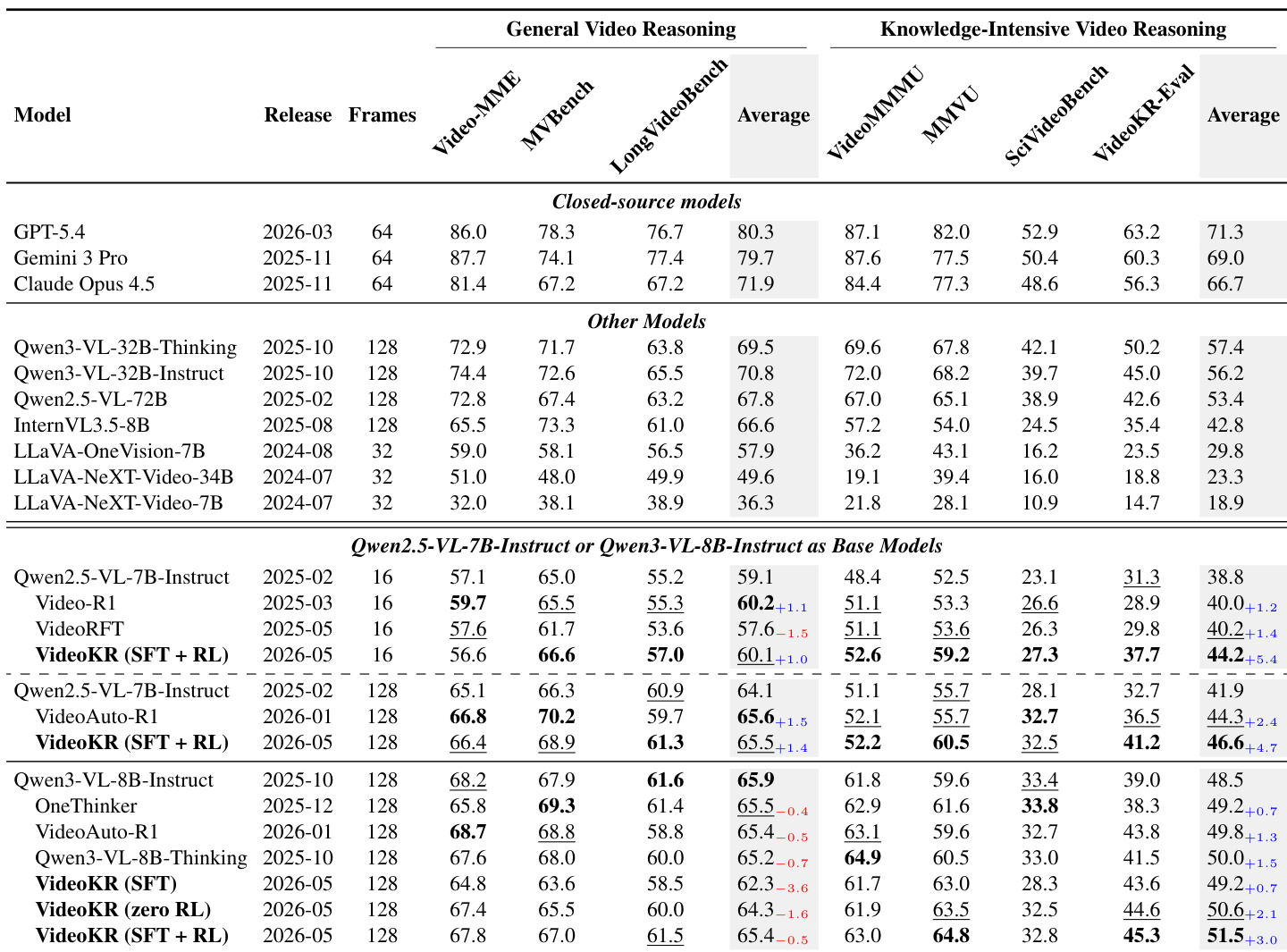
The authors compare multiple models on video reasoning benchmarks, focusing on performance differences between models trained on various post-training corpora. Results show that models trained on VideoKR consistently outperform others, particularly on knowledge-intensive tasks, and that the gains are more pronounced when combining supervised fine-tuning with reinforcement learning. The performance improves with increasing input frames, indicating the benefit of richer visual and temporal context. Models trained on VideoKR achieve higher performance than those trained on other corpora, especially on knowledge-intensive benchmarks. Combining supervised fine-tuning with reinforcement learning yields better results than either method alone. Performance increases with more input frames, suggesting that richer visual and temporal context enhances reasoning.
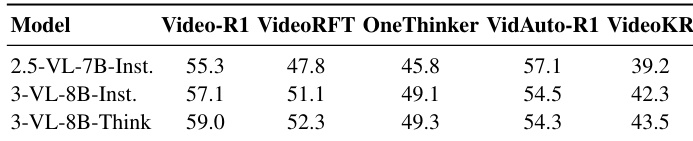
The authors evaluate the effectiveness of their VideoKR dataset by comparing post-trained models against baseline models across general and knowledge-intensive video reasoning benchmarks. Results show that post-training with VideoKR consistently improves model performance, particularly on knowledge-intensive tasks, and that the model benefits from increasing input frames during inference. The dataset's design, which integrates domain knowledge and structured reasoning, contributes to stronger performance gains compared to prior corpora. Post-training on VideoKR improves model performance across all benchmarks, with the most significant gains on knowledge-intensive tasks. Increasing the number of input frames during inference consistently improves model accuracy for both base and post-trained models. The VideoKR dataset, which includes expert-validated examples and structured reasoning, outperforms prior open-source corpora in post-training experiments.
The authors evaluate the performance of post-trained models on video reasoning benchmarks, focusing on general and knowledge-intensive tasks. Results show that increasing the number of input frames consistently improves accuracy for both base and post-trained models, with the best performance achieved at 128 frames. The post-trained Qwen3-VL-8B-Instruct model achieves the highest scores on knowledge-intensive benchmarks, outperforming other models in this category. Increasing input frames leads to consistent performance improvements across all models and benchmarks. The post-trained Qwen3-VL-8B-Instruct model achieves the highest scores on knowledge-intensive video reasoning benchmarks. Post-training on VideoKR improves model performance, with gains most pronounced on knowledge-intensive tasks.
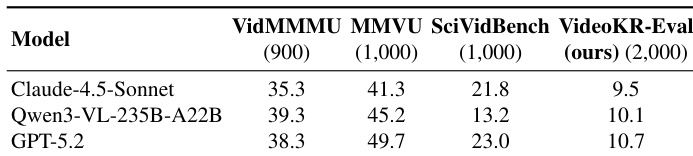
The authors compare several models on a set of video reasoning benchmarks, including general and knowledge-intensive tasks. The results show that models trained on the VideoKR dataset achieve higher performance on knowledge-intensive benchmarks, particularly on the VideoKR-Eval task, indicating improved reasoning capabilities through post-training. Post-training on VideoKR improves model performance, especially on knowledge-intensive video reasoning tasks. Models trained with VideoKR data achieve higher scores on the VideoKR-Eval benchmark compared to other models. The improvements are more pronounced on knowledge-intensive benchmarks than on general video reasoning tasks.
The authors evaluate post-trained video reasoning models across general and knowledge-intensive benchmarks to assess the impact of the VideoKR dataset and various training configurations. The experiments validate that incorporating VideoKR consistently enhances model capabilities, particularly for knowledge-heavy tasks, by leveraging expert-validated examples and structured reasoning. Performance gains are most pronounced when supervised fine-tuning is combined with reinforcement learning, and results remain robust as the number of input frames increases, demonstrating effective utilization of richer visual and temporal context. Overall, the findings confirm that VideoKR post-training significantly strengthens video reasoning proficiency compared to prior corpora and alternative training approaches.