HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

MEMORY-CACHING: RNNs mit wachsendem Speicher

Roboterwerte: Evaluierung von Haushaltsrobotern, wenn menschliche Werte im Konflikt stehen

























MEMORY-CACHING: RNNs mit wachsendem Speicher
Roboterwerte: Evaluierung von Haushaltsrobotern, wenn menschliche Werte im Konflikt stehen
VideoKR: Hin zu wissens- und reasoningintensivem Video-Verständnis
AdaPlanBench: Evaluierung adaptiver Planung in Agents großer Sprachmodelle unter Welt- und Benutzerbeschränkungen
TIDE: Proaktive Multi-Problementdeckung mittels Vorlagen-gesteuerter Iteration
ArcANE: Bleiben Language Agents im Rollenspiel zur richtigen Zeit in Charakter?
Code2LoRA: Hypernetzwerk-generierte Adapter für Code-Sprachmodelle unter Softwareevolution
Selbstdistillierter Policy Gradient
GSM-Symbolic: Das Verständnis der Einschränkungen der mathematischen Schlussfolgerung in großen Sprachmodellen
MUSE-Autoskill: Selbstentwickelnde Agenten durch Fertigkeitserstellung, Gedächtnis, Management und Evaluation
Nemotron 3 Ultra: Open-Source, effizientes Mixture-of-Experts-Hybridmodell aus Mamba und Transformer für agentic reasoning
Qwen-Image-Flash: Jenseits des objektiven Designs
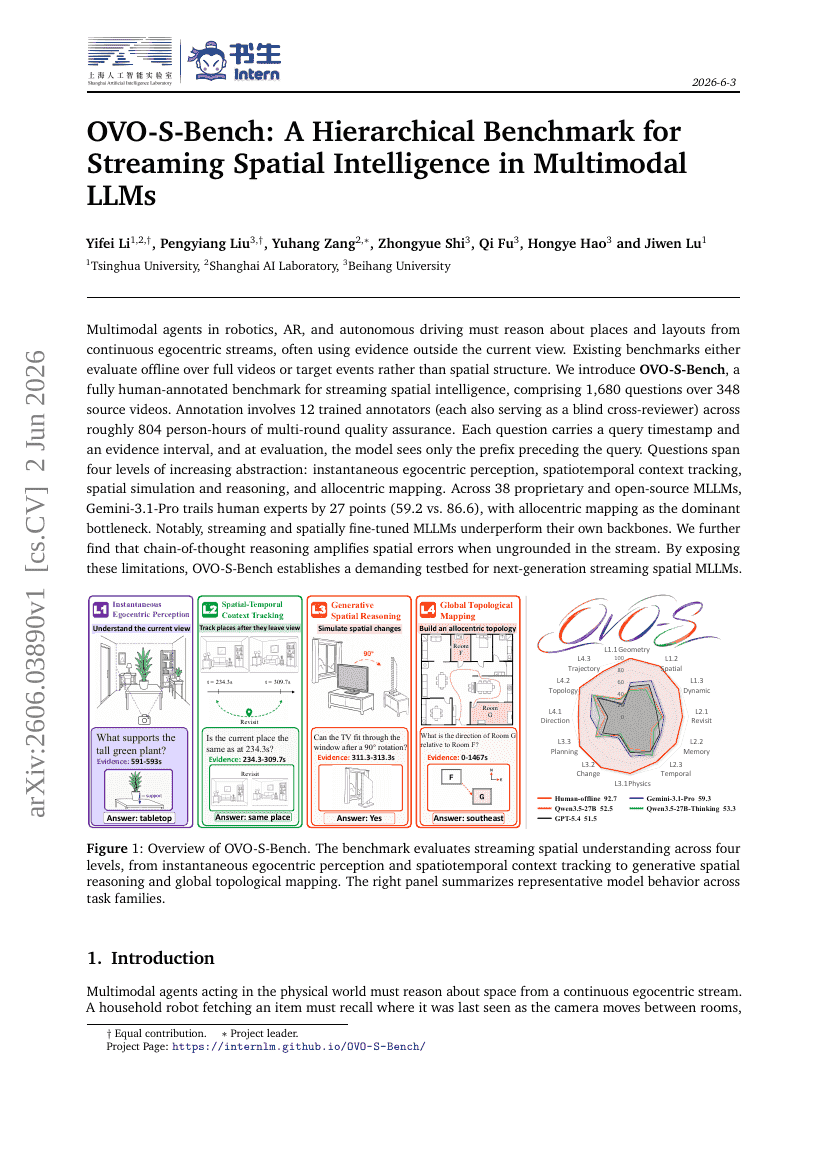
OVO-S-Bench: Ein hierarchisches Benchmark für Streaming-Raumintelligenz in multimodalen LLMs
Reproduktion, Analyse und Detektion von Reward Hacking in rubrikbasiertem Verstärkungslernen
Wo gehen Deep-Research-Agents falsch? Span-Ebene-Fehlerlokalisierung in Agent-Trajektorien
Audio-Interaktionsmodell
Cosmos 3: Omnimodale Weltmodelle für physische KI
Lernen, schnell und langsam: Auf dem Weg zu LLMs, die sich kontinuierlich anpassen
LEAP: Beschleunigung von LLMs für formale Mathematik mit agentic frameworks
Weltmodelle treffen auf Sprachmodelle: Zur Komplementarität von konkretem und abstraktem Denken
Von Aktivierung zu Kausalität: Entdeckung kausaler visueller Repräsentationen im menschlichen Gehirn
Eine lokale Störungstheorie für domänenübergreifende Interferenz und Wiederherstellung in Multi-Domain-RL
Humanoid-GPT: Skalierung von Daten und Struktur für Zero-Shot-Bewegungsverfolgung
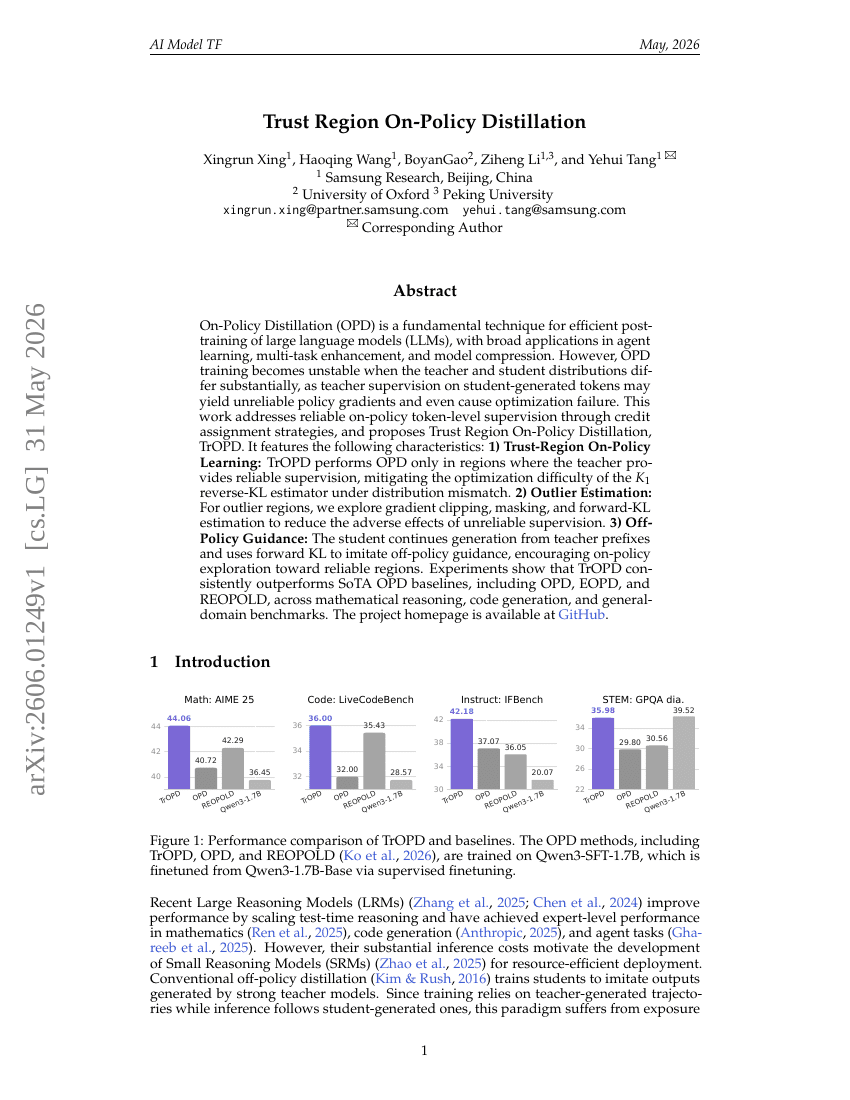
Vertrauensbereich On-Policy Distillation
OCC-RAG: Optimaler kognitiver Kern für treue Fragenbeantwortung
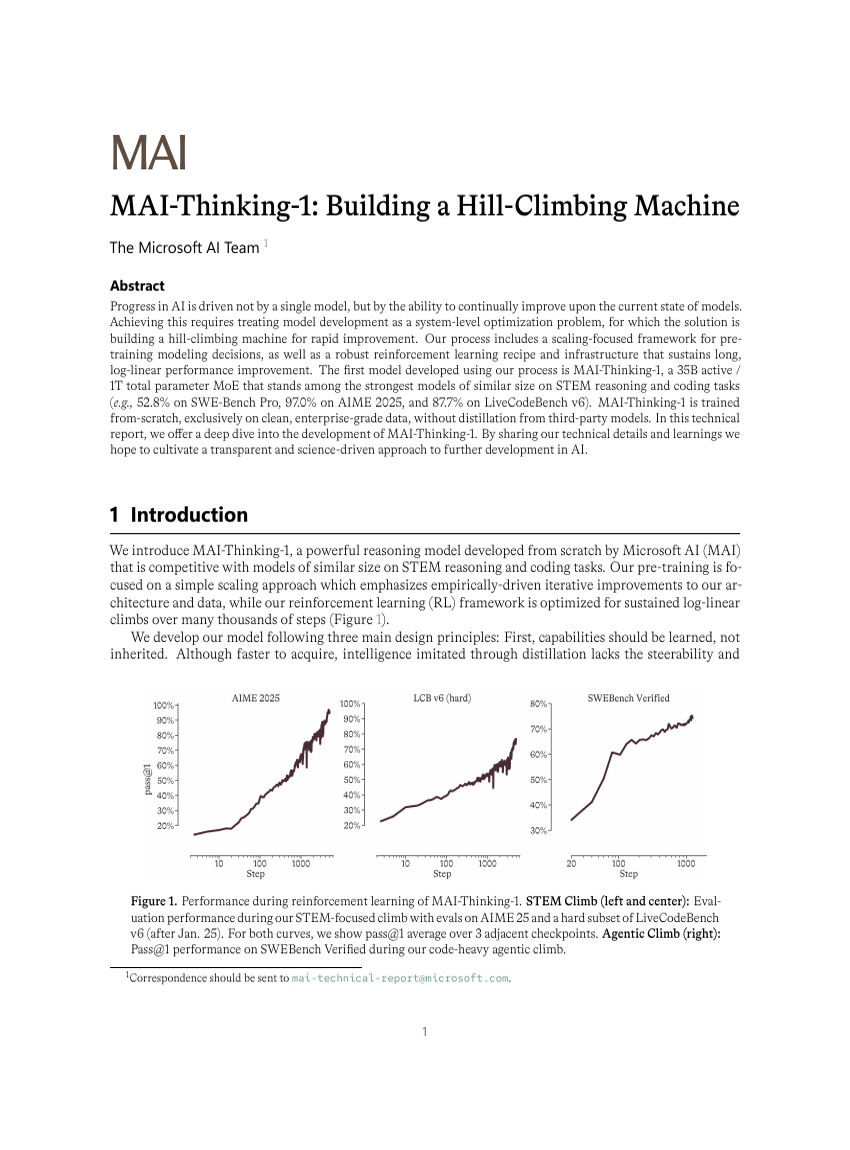
MAI-Thinking-1: Entwicklung einer Hill-Climbing-Maschine
VLM3: Visuell-Sprachmodelle sind nativ 3D-Lerner
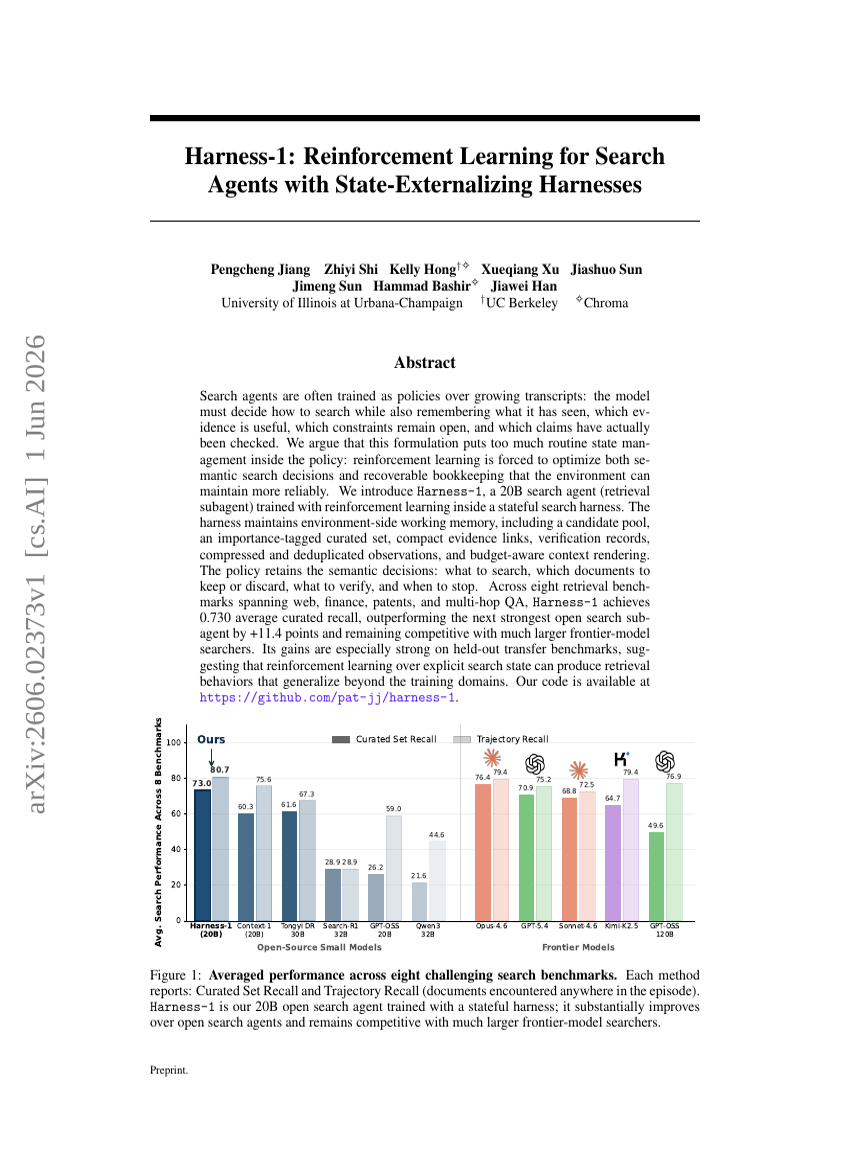
Harness-1: Verstärkungslernen für Suchagenten mit zustandsauslagernden Harnesses
DeepCrack: Eine tiefe hierarchische Merkmalslernalchitektur zur Segmentierung von Rissen
VideoMLA: Niedrigrangiger Latenter KV-Cache für Minuten-Skalen-Autoregressive Video-Diffusion
Draft-OPD: On-Policy Distillation für spekulative Entwurfsmodelle
K-BrowseComp: Ein Web-Browsing-Agent-Benchmark, der in koreanischen Kontexten verankert ist
VideoKR: Hin zu wissens- und reasoningintensivem Video-Verständnis
AdaPlanBench: Evaluierung adaptiver Planung in Agents großer Sprachmodelle unter Welt- und Benutzerbeschränkungen
TIDE: Proaktive Multi-Problementdeckung mittels Vorlagen-gesteuerter Iteration
ArcANE: Bleiben Language Agents im Rollenspiel zur richtigen Zeit in Charakter?
Code2LoRA: Hypernetzwerk-generierte Adapter für Code-Sprachmodelle unter Softwareevolution
Selbstdistillierter Policy Gradient
GSM-Symbolic: Das Verständnis der Einschränkungen der mathematischen Schlussfolgerung in großen Sprachmodellen
MUSE-Autoskill: Selbstentwickelnde Agenten durch Fertigkeitserstellung, Gedächtnis, Management und Evaluation
Nemotron 3 Ultra: Open-Source, effizientes Mixture-of-Experts-Hybridmodell aus Mamba und Transformer für agentic reasoning
Qwen-Image-Flash: Jenseits des objektiven Designs
OVO-S-Bench: Ein hierarchisches Benchmark für Streaming-Raumintelligenz in multimodalen LLMs
Reproduktion, Analyse und Detektion von Reward Hacking in rubrikbasiertem Verstärkungslernen
Wo gehen Deep-Research-Agents falsch? Span-Ebene-Fehlerlokalisierung in Agent-Trajektorien
Audio-Interaktionsmodell
Cosmos 3: Omnimodale Weltmodelle für physische KI
Lernen, schnell und langsam: Auf dem Weg zu LLMs, die sich kontinuierlich anpassen
LEAP: Beschleunigung von LLMs für formale Mathematik mit agentic frameworks
Weltmodelle treffen auf Sprachmodelle: Zur Komplementarität von konkretem und abstraktem Denken
Von Aktivierung zu Kausalität: Entdeckung kausaler visueller Repräsentationen im menschlichen Gehirn
Eine lokale Störungstheorie für domänenübergreifende Interferenz und Wiederherstellung in Multi-Domain-RL
Humanoid-GPT: Skalierung von Daten und Struktur für Zero-Shot-Bewegungsverfolgung
Vertrauensbereich On-Policy Distillation
OCC-RAG: Optimaler kognitiver Kern für treue Fragenbeantwortung
MAI-Thinking-1: Entwicklung einer Hill-Climbing-Maschine
VLM3: Visuell-Sprachmodelle sind nativ 3D-Lerner
Harness-1: Verstärkungslernen für Suchagenten mit zustandsauslagernden Harnesses
DeepCrack: Eine tiefe hierarchische Merkmalslernalchitektur zur Segmentierung von Rissen
VideoMLA: Niedrigrangiger Latenter KV-Cache für Minuten-Skalen-Autoregressive Video-Diffusion
Draft-OPD: On-Policy Distillation für spekulative Entwurfsmodelle
K-BrowseComp: Ein Web-Browsing-Agent-Benchmark, der in koreanischen Kontexten verankert ist