HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Jenseits euklidischen Clippings: Überwindung des Explorationskollapses in LLM-RL durch Riemannsche isometrische Policy-Optimierung

Skalierungsgesetze für hypernetzwerkbasierte Wissensinjektion in großen Sprachmodellen

Eine Prüfung für aktive Beobachter

Jenseits der relevanzzentrierten Suche: Rubrikenorientierte Auswahl und Rangordnung von Dokumentensets

Self Gradient Forcing: Native Langzeit-Videoextrapolation

SLAI T-Rex: Vollparameter-Post-Training der DeepSeek-V4-Familie auf Ascend SuperPOD

Vera: Ein geschichtetes Diffusionsmodell für inhaltsbewahrende Videobearbeitung

Zweistufige Meta-Bewertungsraster für die Evaluation offener Textgenerierung: GAMUT, ein Benchmark für faktische Vollständigkeit

Automatisierte Entdeckung besitzt kein universell überlegenes Steuerungssystem
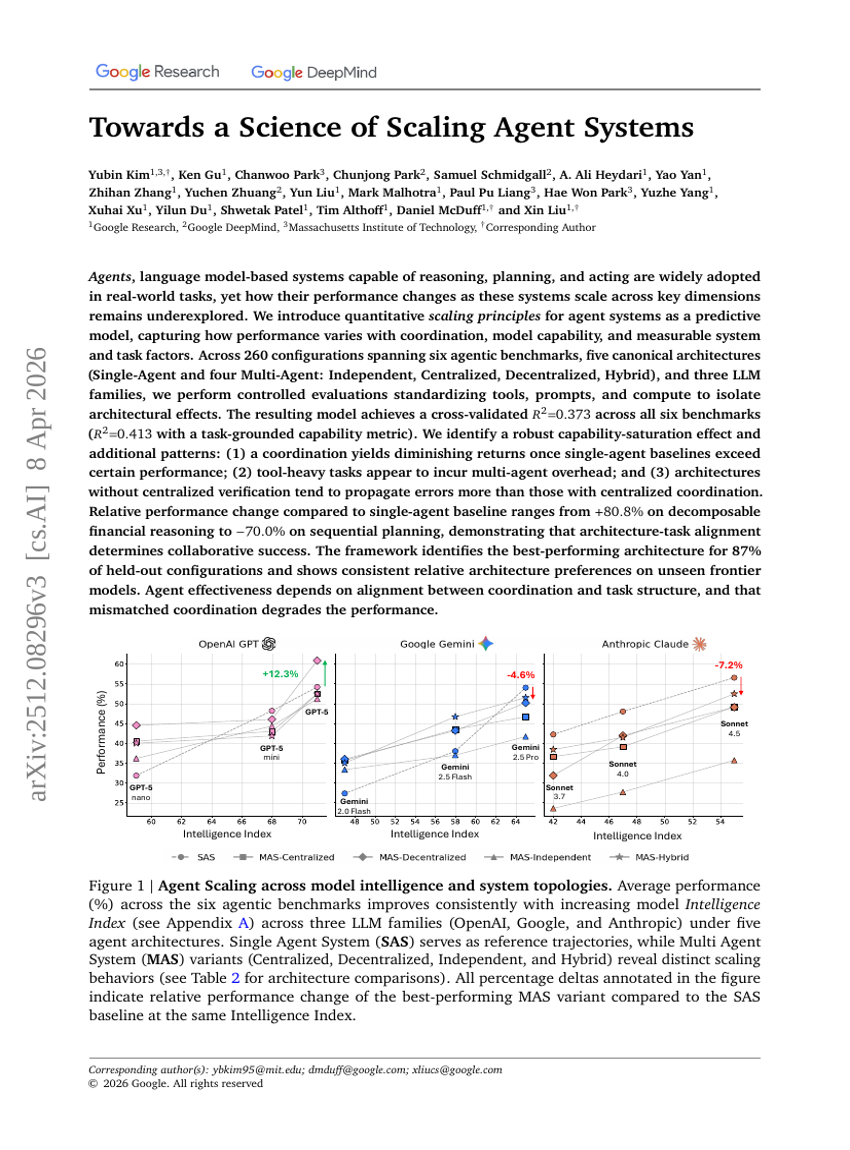
Auf dem Weg zu einer Wissenschaft der Skalierung von Agentensystemen

AlayaWorld: Interaktive Langzeithorizont-Weltmodellierung – Vollständiger Technischer Bericht

Mage-Flow: Ein effizientes Foundation-Modell mit nativer Auflösung für Bildgenerierung und -bearbeitung

DataFlow-Harness: Eine geerdete Code-Agent-Plattform zur Konstruktion editierbarer LLM-Datenpipelines

Textvorlagen-Token als implizite semantische Register in Diffusion-Transformern

Generativer Welt-Renderer in Spielgeschwindigkeit

Unendliche interaktive Welt-Rollouts auf einer einzelnen Desktop-GPU

UniMoMo: Einheitliche generative Modellierung von 3D-Molekülen für das De-novo-Binder-Design

Messung von Belohnungsstreben durch kontrastive Glaubensaktualisierungen

LLM-as-a-Coach: Erfahrungsbasiertes Lernen für nicht verifizierbare Aufgaben

Apple-π: Ein Benchmark zur Bewertung von Videogenerierungsmodellen hinsichtlich der Verankerung physikalischer Gesetze

HOMIE: Human-Objekt-zentrierte Videopersonalisierung durch multimodale intelligente Erweiterung

SWE-Pruner Pro: Das Coder-LLM weiß bereits, was zu kürzen ist

DeepSearch-World: Selbstdestillation für Deep-Search-Agenten in einer verifizierbaren Umgebung

EvolvingWorld: Ein offenes Schema-Framework für ko-evolvierende Rollenspielagenten und Weltmodelle in interaktiven literarischen Welten

TimeLens2: Generalist Video Temporal Grounding mit multimodalen LLMs

Verständnis des Reasoning von Pretraining bis Post-Training

Rekursive Selbstverbesserung in der KI: Von begrenzter Selbstverfeinerung zu autonomen Forschungsschleifen
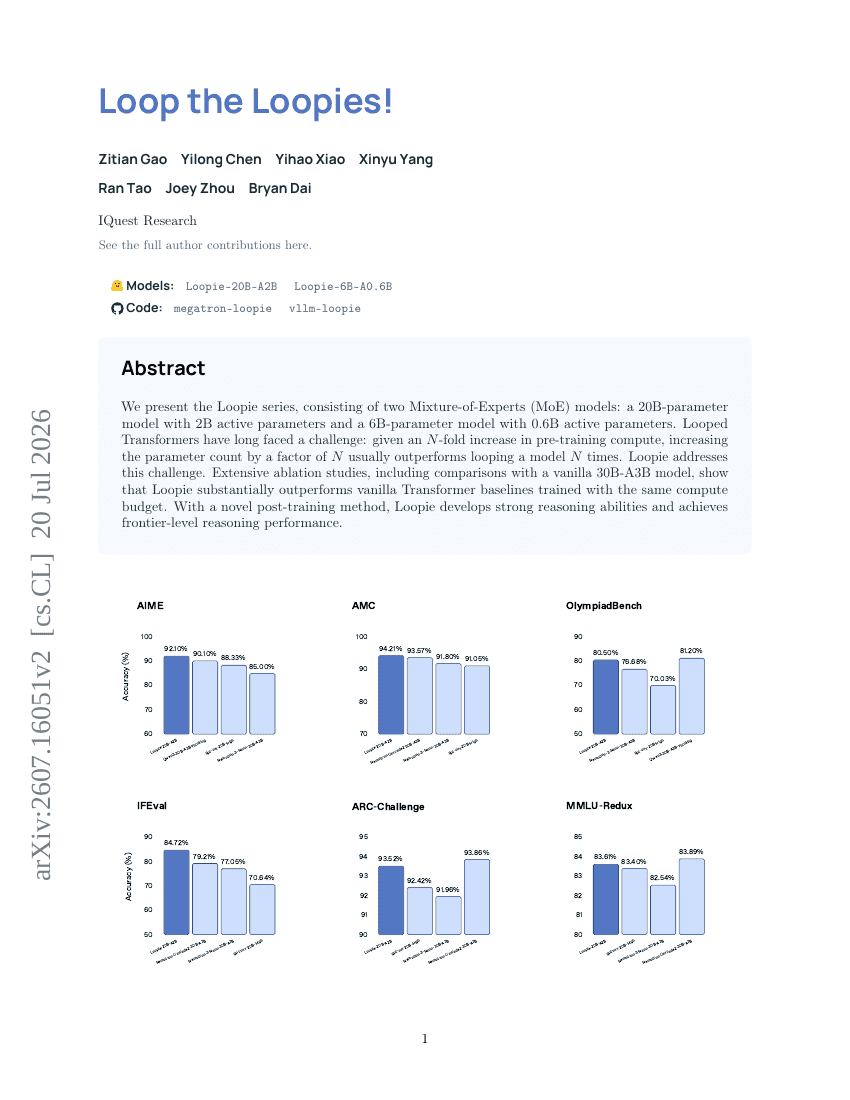
Loop the Loopies!

On-Policy Delta Distillation
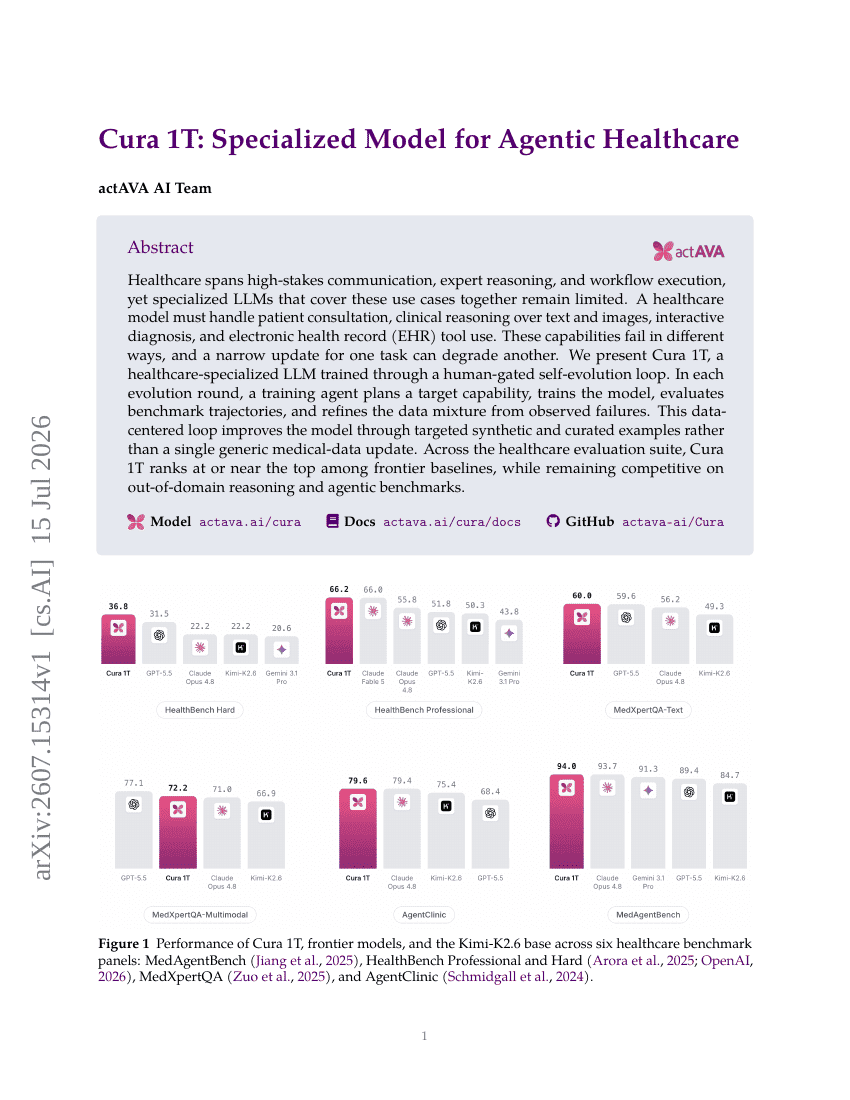
Cura 1T: Ein durch eine menschlich gesteuerte Selbstentwicklungsschleife trainiertes, gesundheitsspezialisiertes LLM

Von menschenzentrierter zu agentischer Code-Überprüfung: Der Einfluss verschiedener Generationen generativer KI-Technologie auf die Überprüfungsqualität
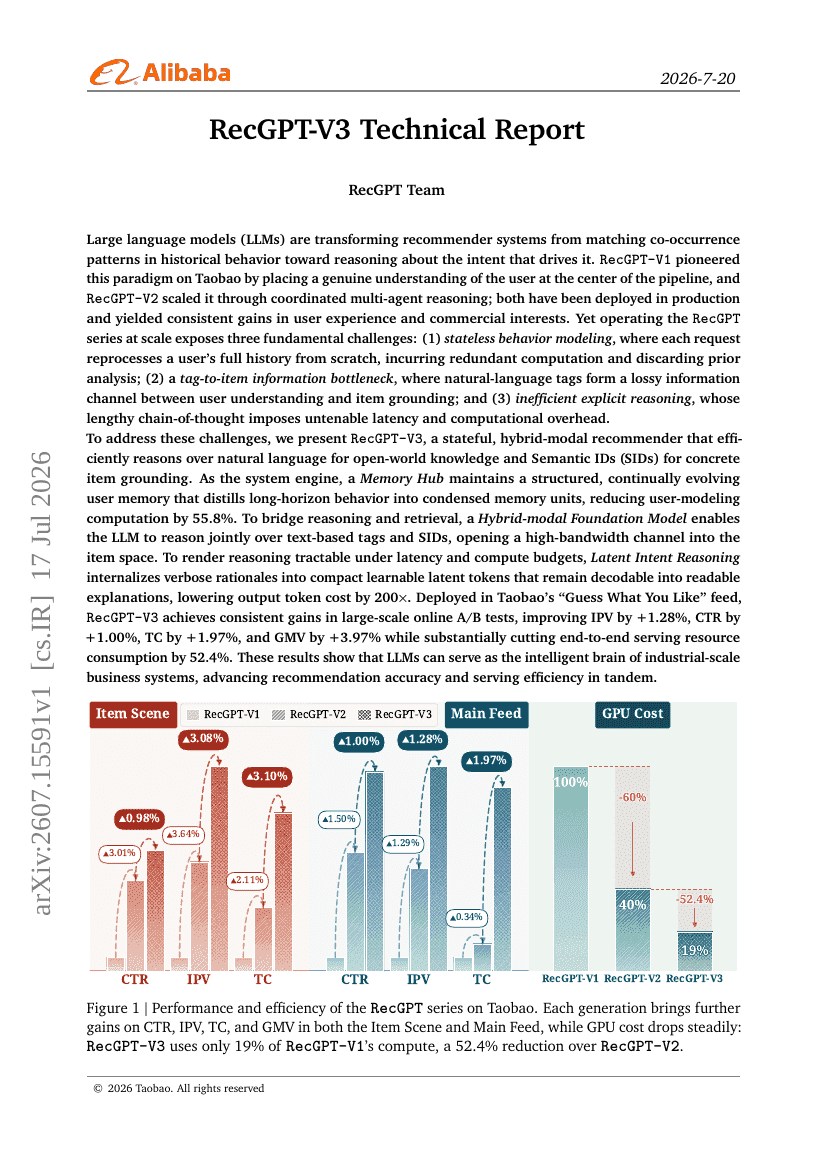
RecGPT-V3 Technischer Bericht
Jenseits euklidischen Clippings: Überwindung des Explorationskollapses in LLM-RL durch Riemannsche isometrische Policy-Optimierung
Skalierungsgesetze für hypernetzwerkbasierte Wissensinjektion in großen Sprachmodellen
Eine Prüfung für aktive Beobachter
Jenseits der relevanzzentrierten Suche: Rubrikenorientierte Auswahl und Rangordnung von Dokumentensets
Self Gradient Forcing: Native Langzeit-Videoextrapolation
SLAI T-Rex: Vollparameter-Post-Training der DeepSeek-V4-Familie auf Ascend SuperPOD
Vera: Ein geschichtetes Diffusionsmodell für inhaltsbewahrende Videobearbeitung
Zweistufige Meta-Bewertungsraster für die Evaluation offener Textgenerierung: GAMUT, ein Benchmark für faktische Vollständigkeit
Automatisierte Entdeckung besitzt kein universell überlegenes Steuerungssystem
Auf dem Weg zu einer Wissenschaft der Skalierung von Agentensystemen
AlayaWorld: Interaktive Langzeithorizont-Weltmodellierung – Vollständiger Technischer Bericht
Mage-Flow: Ein effizientes Foundation-Modell mit nativer Auflösung für Bildgenerierung und -bearbeitung
DataFlow-Harness: Eine geerdete Code-Agent-Plattform zur Konstruktion editierbarer LLM-Datenpipelines
Textvorlagen-Token als implizite semantische Register in Diffusion-Transformern
Generativer Welt-Renderer in Spielgeschwindigkeit
Unendliche interaktive Welt-Rollouts auf einer einzelnen Desktop-GPU
UniMoMo: Einheitliche generative Modellierung von 3D-Molekülen für das De-novo-Binder-Design
Messung von Belohnungsstreben durch kontrastive Glaubensaktualisierungen
LLM-as-a-Coach: Erfahrungsbasiertes Lernen für nicht verifizierbare Aufgaben
Apple-π: Ein Benchmark zur Bewertung von Videogenerierungsmodellen hinsichtlich der Verankerung physikalischer Gesetze
HOMIE: Human-Objekt-zentrierte Videopersonalisierung durch multimodale intelligente Erweiterung
SWE-Pruner Pro: Das Coder-LLM weiß bereits, was zu kürzen ist
DeepSearch-World: Selbstdestillation für Deep-Search-Agenten in einer verifizierbaren Umgebung
EvolvingWorld: Ein offenes Schema-Framework für ko-evolvierende Rollenspielagenten und Weltmodelle in interaktiven literarischen Welten
TimeLens2: Generalist Video Temporal Grounding mit multimodalen LLMs
Verständnis des Reasoning von Pretraining bis Post-Training
Rekursive Selbstverbesserung in der KI: Von begrenzter Selbstverfeinerung zu autonomen Forschungsschleifen
Loop the Loopies!
On-Policy Delta Distillation
Cura 1T: Ein durch eine menschlich gesteuerte Selbstentwicklungsschleife trainiertes, gesundheitsspezialisiertes LLM
Von menschenzentrierter zu agentischer Code-Überprüfung: Der Einfluss verschiedener Generationen generativer KI-Technologie auf die Überprüfungsqualität
RecGPT-V3 Technischer Bericht