HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
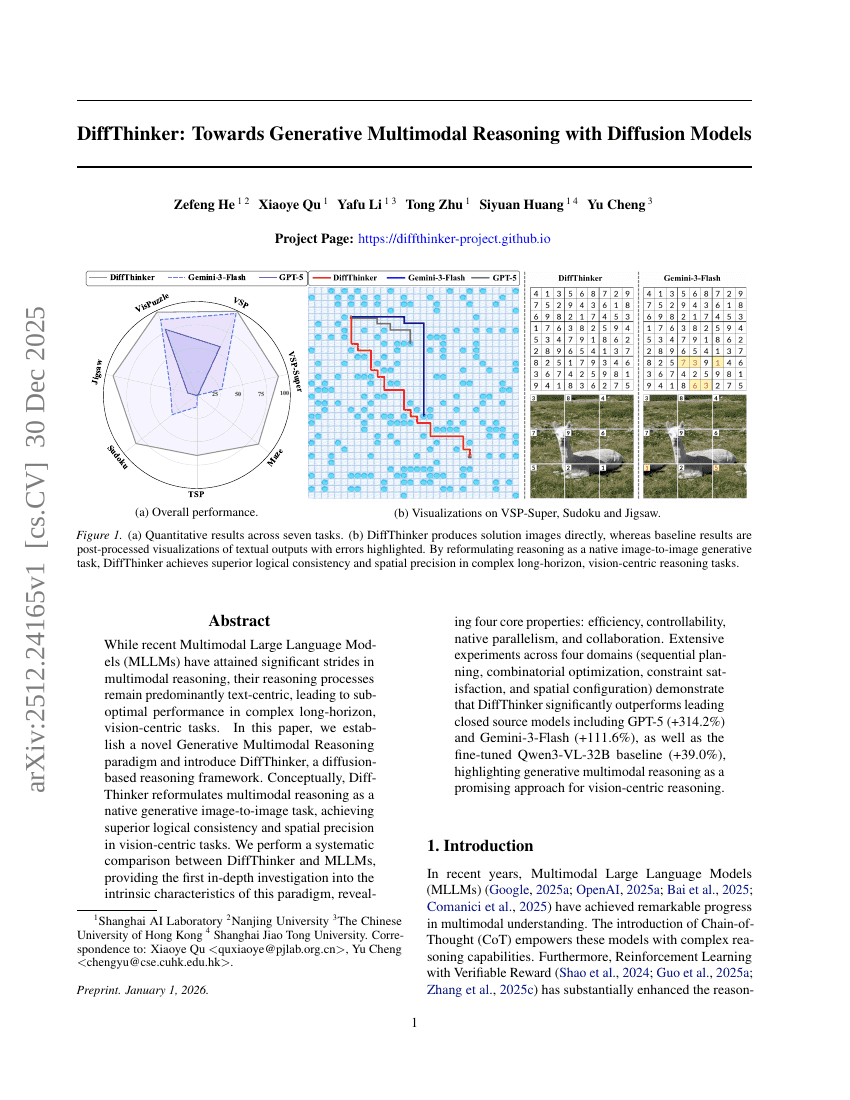
DiffThinker:面向生成式多模态推理的扩散模型

动态大概念模型:自适应语义空间中的潜在推理


























DiffThinker:面向生成式多模态推理的扩散模型
动态大概念模型:自适应语义空间中的潜在推理
基于超图记忆的多步RAG在长上下文复杂关系建模中的优化
人工智能与大脑的交汇:从认知神经科学到自主智能体的记忆系统
开放性推理的扩展以预测未来
GaMO:面向稀疏视图三维重建的几何感知多视角扩散外推
mHC:流形约束超连接
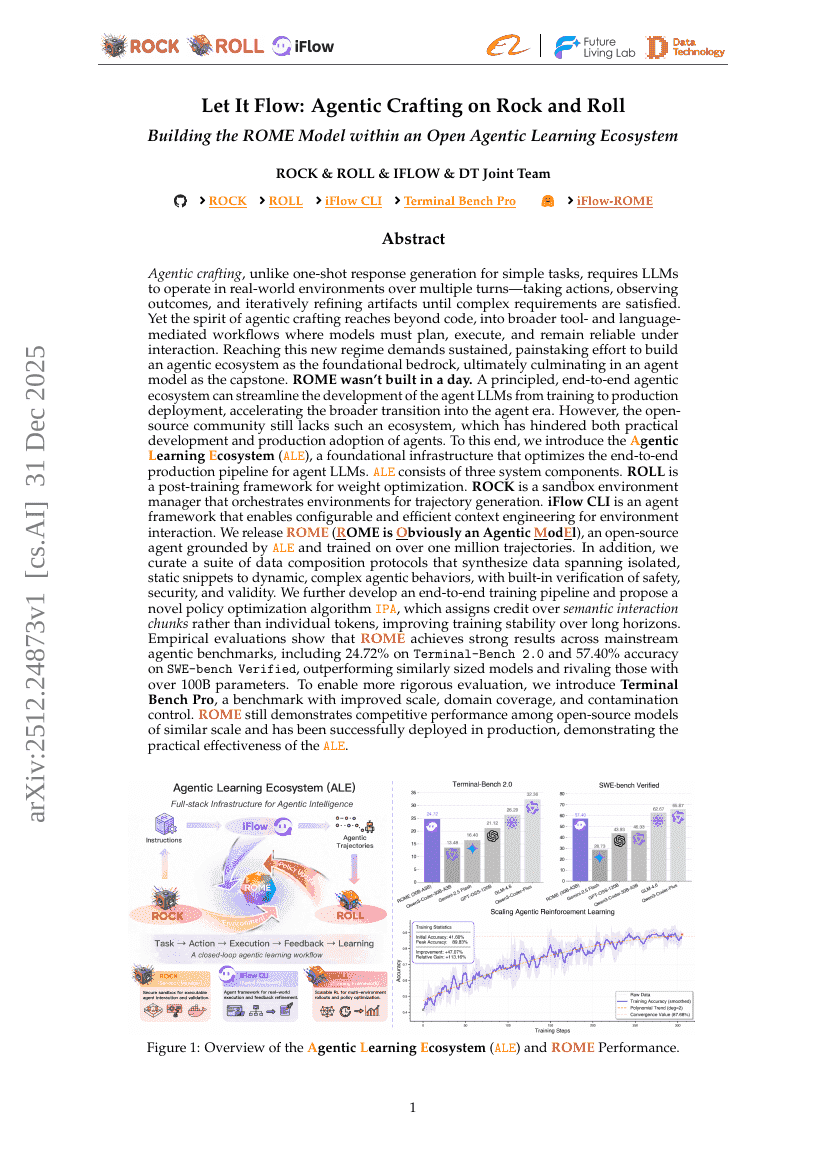
让思维流动:在摇滚乐中构建智能体,于开放智能体学习生态中打造ROME模型
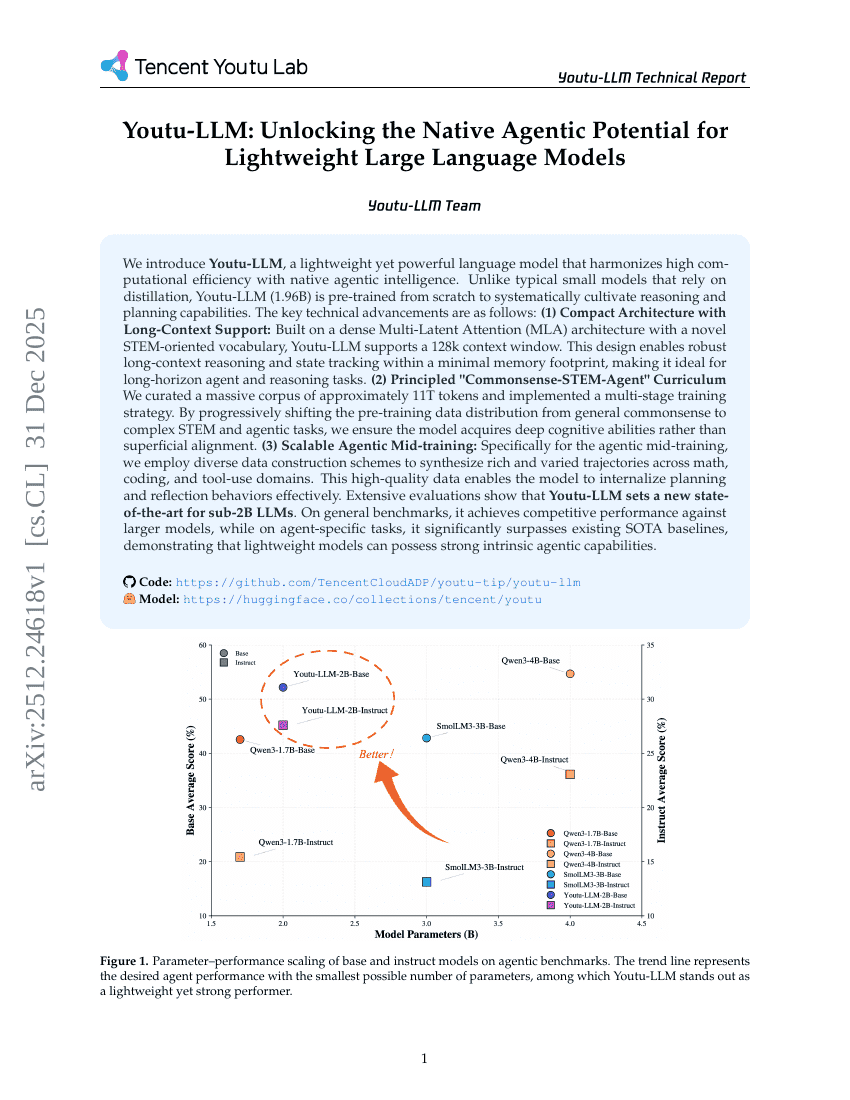
Youtu-LLM:释放轻量级大语言模型的原生智能体潜力
GateBreaker:基于门控机制的专家混合型LLM攻击方法
GraphLocator:基于图引导的因果推理用于问题定位
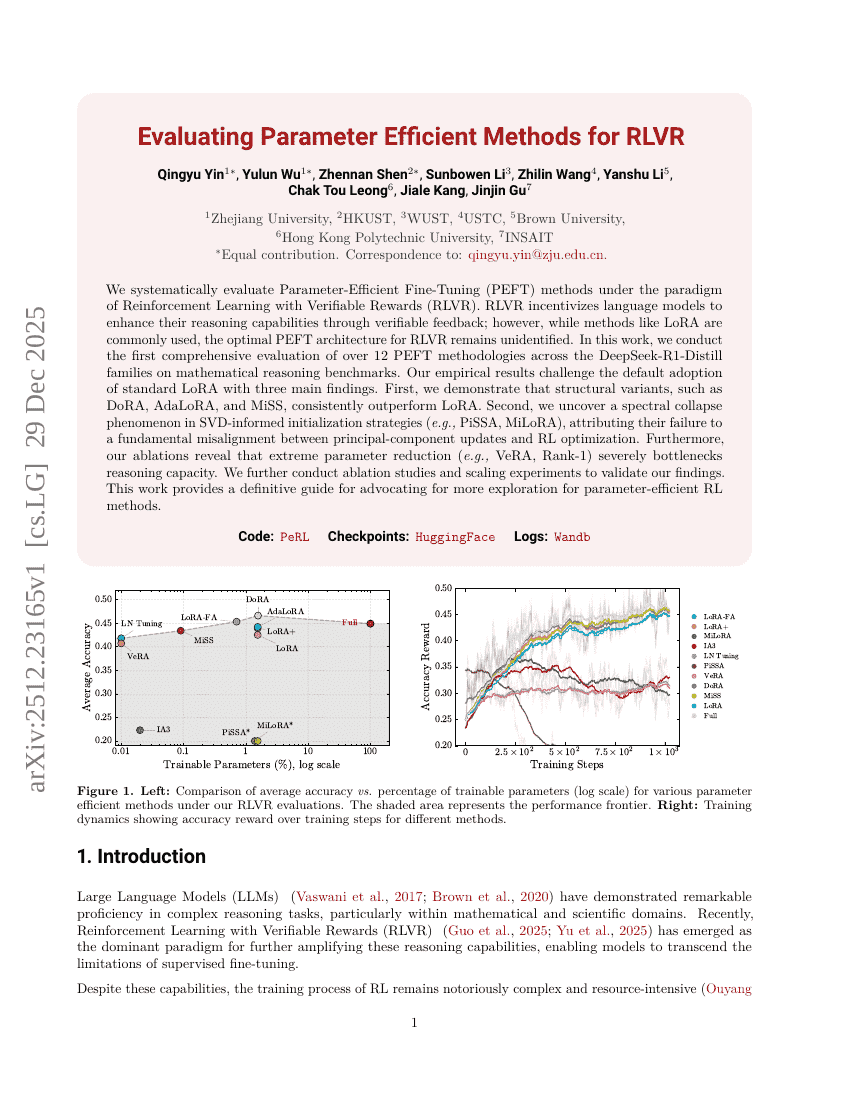
评估参数高效方法在RLVR中的应用
端到端的测试时训练用于长上下文
DreamOmni3:基于涂鸦的编辑与生成
UltraShape 1.0:通过可扩展几何精炼实现高保真3D形状生成
Mimic-Video:面向可泛化机器人控制的视频-动作模型,超越VLAs
HY-Motion 1.0:面向文本到动作生成的流匹配模型扩展
SurgWorld:通过世界建模从视频中学习外科机器人策略
SpotEdit:扩散Transformer中的选择性区域编辑
扩散模型洞悉透明性:将视频扩散模型重用于透明物体的深度与法向估计
SmartSnap:面向自验证Agent的主动证据获取
Yume-1.5:一种文本控制的交互式世界生成模型
LiveTalk:通过改进的自洽蒸馏实现实时多模态交互式视频扩散
通过辅助损失实现专家与路由器在专家混合模型中的耦合
LongFly:基于时空上下文融合的长时程无人机视觉-语言导航
注意力并非你所需要的
SlideTailor:面向科学论文的个性化演示文稿生成
InSight-o3:通过泛化视觉搜索赋能多模态基础模型
InsertAnywhere:连接4D场景几何与扩散模型以实现逼真的视频物体插入
面向心智地图感知的检索增强生成以提升长上下文理解
衡量大语言模型中短文本的真实性
DeepSearchQA:弥合深度研究Agent的全面性差距
基于超图记忆的多步RAG在长上下文复杂关系建模中的优化
人工智能与大脑的交汇:从认知神经科学到自主智能体的记忆系统
开放性推理的扩展以预测未来
GaMO:面向稀疏视图三维重建的几何感知多视角扩散外推
mHC:流形约束超连接
让思维流动:在摇滚乐中构建智能体,于开放智能体学习生态中打造ROME模型
Youtu-LLM:释放轻量级大语言模型的原生智能体潜力
GateBreaker:基于门控机制的专家混合型LLM攻击方法
GraphLocator:基于图引导的因果推理用于问题定位
评估参数高效方法在RLVR中的应用
端到端的测试时训练用于长上下文
DreamOmni3:基于涂鸦的编辑与生成
UltraShape 1.0:通过可扩展几何精炼实现高保真3D形状生成
Mimic-Video:面向可泛化机器人控制的视频-动作模型,超越VLAs
HY-Motion 1.0:面向文本到动作生成的流匹配模型扩展
SurgWorld:通过世界建模从视频中学习外科机器人策略
SpotEdit:扩散Transformer中的选择性区域编辑
扩散模型洞悉透明性:将视频扩散模型重用于透明物体的深度与法向估计
SmartSnap:面向自验证Agent的主动证据获取
Yume-1.5:一种文本控制的交互式世界生成模型
LiveTalk:通过改进的自洽蒸馏实现实时多模态交互式视频扩散
通过辅助损失实现专家与路由器在专家混合模型中的耦合
LongFly:基于时空上下文融合的长时程无人机视觉-语言导航
注意力并非你所需要的
SlideTailor:面向科学论文的个性化演示文稿生成
InSight-o3:通过泛化视觉搜索赋能多模态基础模型
InsertAnywhere:连接4D场景几何与扩散模型以实现逼真的视频物体插入
面向心智地图感知的检索增强生成以提升长上下文理解
衡量大语言模型中短文本的真实性
DeepSearchQA:弥合深度研究Agent的全面性差距