Command Palette
Search for a command to run...
SurgWorld:通过世界建模从视频中学习外科机器人策略
SurgWorld:通过世界建模从视频中学习外科机器人策略
摘要
数据稀缺仍是实现完全自主手术机器人的根本障碍。尽管大规模视觉-语言-动作(VLA)模型通过利用来自多样化领域的视频与动作配对数据,在家庭及工业操作任务中展现出出色的泛化能力,但手术机器人领域却严重缺乏同时包含视觉观测与精确机器人运动学信息的数据集。相比之下,大量手术视频资源虽已存在,但普遍缺乏对应的动作标签,导致无法直接应用模仿学习或VLA模型的训练方法。为此,本文提出一种新策略:基于专为手术物理人工智能设计的“SurgWorld”世界模型,学习策略模型以缓解该问题。我们构建了“手术动作文本对齐”(Surgical Action Text Alignment, SATA)数据集,其中包含专为手术机器人设计的详细动作描述。在此基础上,我们基于最先进的物理人工智能世界模型与SATA数据集,构建了SurgeWorld系统,能够生成多样化、可泛化且高度真实的手术视频。我们首次采用逆动力学模型,从合成手术视频中推断出伪运动学信息,从而生成合成的视频-动作配对数据。实验表明,使用这些增强数据训练的手术VLA策略,在真实手术机器人平台上显著优于仅基于真实示范数据训练的模型。本方法通过充分利用海量未标注手术视频与生成式世界建模技术,为实现可扩展的自主手术技能学习提供了新路径,从而开启了通用性强、数据高效手术机器人策略的新可能。
一句话总结
来自英伟达、香港中文大学、成均馆大学、温州医科大学、新加坡国立大学和瑞金医院的研究者提出SurgWorld——一种新颖的框架,该框架利用在精心筛选的SATA数据集上训练的大规模手术世界模型,通过逆动力学建模生成高保真度的合成视频-动作对,实现了视觉-语言-动作策略在手术机器人上的数据高效且可泛化的训练,在缝合针操作任务中显著优于仅使用真实数据的基线模型。
主要贡献
- 手术机器人领域存在数据稀缺问题,尤其是缺乏配对的视频-运动学数据,尽管存在大量未标注的手术视频,这阻碍了通用机器人策略的训练。
- 研究者提出SurgWorld,一种基于扩散的世界模型,其在精心筛选的SATA数据集上进行训练,能够生成逼真的、任务一致的手术视频,并首次利用逆动力学模型从合成视频轨迹中推断伪运动学数据。
- 在真实手术机器人上的评估表明,使用SurgWorld生成的真实与合成数据联合训练的VLA策略,相比仅基于真实示范训练的模型,显著降低了轨迹预测误差并表现出更优性能。
引言
研究者针对自主手术机器人中的关键挑战——数据稀缺问题展开研究,由于伦理、后勤和安全限制,高质量的视频-运动学配对数据极为有限。尽管视觉-语言-动作(VLA)模型已在家庭和工业场景中实现了通用操作,但其在手术领域的应用受限于缺乏大规模、标注完善的视觉与精确机器人动作关联数据集。此前通过物理仿真器生成合成数据的努力存在显著的视觉与动态域差距,而现有手术视频生成模型通常任务特定且缺乏稳健的文本-动作对齐。为克服这些局限,研究者提出SurgWorld,一种基于精心筛选、专家标注数据集SATA构建的手术世界模型,该数据集包含2,447段视频片段,涵盖8种手术类型及四种基础手术动作:缝针抓取(689段)、缝针穿刺(989段)、缝线牵拉(475段)和打结(294段)。研究者利用该模型生成逼真的、任务一致的手术视频,并首次通过逆动力学模型从合成视频轨迹中推断伪运动学数据,从而构建增强的视频-动作配对数据。该合成数据使手术VLA策略的训练显著优于仅依赖真实示范的模型,展示了通过弥合大量未标注手术视频与机器人控制之间的鸿沟,实现自主手术技能获取的可扩展、数据高效路径。
数据集
- SATA数据集包含2,447段专家标注的视频片段,总帧数超过30万帧,涵盖8种手术类型及四种基础手术动作:缝针抓取(689段)、缝针穿刺(989段)、缝线牵拉(475段)和打结(294段)。
- 数据来源于认证的YouTube手术频道及公开数据集,包括GraSP、SAR-RARP50、Multiypass140、SurgicalActions160、Auto-Laparo和HeiCo,标注经过重新处理以确保一致性和粒度。
- 每段视频均配有详细文本描述,捕捉器械、解剖结构及器械-组织交互之间的空间关系——例如:“左侧持针器穿刺患者背侧静脉复合体的右侧。”
- 该数据集专为物理AI设计,强调细粒度动作标签和工具-组织动态的精确描述,区别于以语义为中心的数据集如SurgVLM-DB。
- 模型训练中,SATA作为视频与文本对齐的主要来源,采用混合比例平衡四种动作类别,以确保训练期间的代表性覆盖。
- 研究者采用裁剪策略聚焦手术部位区域,确保各片段间视觉上下文的一致性。
- 构建元数据,包含动作标签、解剖上下文、器械类型和交互类型,支持手术流程的结构化学习。
- 真实世界轨迹数据包含在橡胶垫上完成“针抓取与交接”任务的60次成功人类遥操作示范,同步包含内窥镜视频(平均217帧)和20维动作运动学数据。
- 动作运动学表示为20维向量,编码左右机械臂的位置、姿态(6D旋转)及夹持器状态,所有数据均相对于内窥镜坐标系,以保证视角一致性。
- 额外使用66个域外片段(约60,000帧)的通用机器人运动数据,用于预训练基础逆动力学模型(IDM),实现跨任务的可迁移运动理解。
- IDM与视觉-语言动作模型(GR00T N1.5)采用相似架构,但IDM不依赖文本提示或机器人状态输入,仅基于视觉输入进行运动预测。
方法
研究者采用Cosmos-Predict2.5模型——一种在多样化机器人与具身数据集上预训练的大规模视频世界模型——作为其手术世界模型SurgWorld的基础。该模型采用基于扩散的潜在视频预测框架,结合Transformer主干网络,以模拟高保真时空动态。为适配手术领域,模型在SATA数据集上进行微调,该数据集包含真实手术轨迹与详细标注。适配过程仅以初始观测帧 I0 和文本提示作为条件,使模型能够预测捕捉手术场景时序演化的未来轨迹。这包括建模器械-组织交互、有限视野运动以及内窥镜手术特有的受限关节运动模式。为确保参数效率并保留模型的通用视频建模能力,采用低秩适配(LoRA)方法,在Transformer的注意力层与前馈层中插入模块。最终模型记为 Wθ,生成视频轨迹 I^1:T=Wθ(I0),其中时空编码器处理初始帧,基于Transformer的潜在动态模块建模时序演化,解码器重建预测帧。

手术视频世界模型的训练采用流匹配(Flow Matching, FM)公式,该方法在潜在空间中提供直接且稳定的训练信号。该方法通过在原始数据样本 I 与噪声向量 ϵ 之间进行时间步 t 的插值,定义基于速度的目标,得到插值潜在变量 It=(1−t)I+tϵ。对应的真值速度为 vt=ϵ−I。模型通过网络 uθ(It,t,c) 预测该速度,其中 c 表示条件帧 I0 与文本提示。训练目标为预测速度与真值速度之间的均方误差(MSE),形式化为 L(θ)=EI,ϵ,c,t∥uθ(It,t,c)−vt∥Q2。该方法提升了优化稳定性与生成样本质量。

为弥合世界模型与具体机器人本体之间的差距,构建了逆动力学模型(IDM)。IDM以同一视频中相隔16帧的两帧作为输入,预测两者之间的每一帧的机器人动作。该模型用于为世界模型生成的合成视频轨迹标注伪动作运动学。如图所示,IDM架构包含一个扩散Transformer,配备SigLIP-2视觉编码器、动作编码器与动作解码器。模型处理两帧输入及对应噪声动作,预测中间动作。

机器人的最终策略通过GR00T视觉-语言-动作模型学习,该模型同样基于扩散Transformer。该模型以当前帧、文本提示和机器人状态为输入,预测未来动作。其架构包括视觉语言模型、状态编码器与动作编码器,全部输入扩散Transformer以生成预测动作。IDM与GR00T策略模型共享相似主干,但在输入与输出上存在差异:IDM专注于从视频帧预测动作,而GR00T模型则融合机器人状态以实现策略学习。世界模型与IDM生成的合成视频与伪运动学数据用于训练GR00T策略,使其能够从真实与合成数据中学习。
实验
- 在SATA数据集上评估SurgWorld的视频生成质量,结果表明其在感知保真度与语义一致性方面优于零样本与粗略提示基线,FVD最低,VBench评分(DD、IQ、OC)最高,定性结果显示在复杂场景下仍能正确生成器械与动作。
- 通过新颖文本提示生成多样化手术序列(如多次针交接),验证新行为泛化能力,显示强文本-视频对齐性与解剖上合理、时序一致的运动,尽管未显式训练此类组合。
- 人类专家评估确认SurgWorld具有临床真实性,在文本-视频对齐、器械一致性与解剖合理性方面获得最高评分,优于零样本与动作类别变体的手术保真度。
- 在5条真实手术轨迹上展示有效少样本适应能力,SurgWorld在SATA上预训练后达到73.2%的任务成功率与最低FVD,显著优于从原始模型直接微调,凸显更高的数据效率与鲁棒性。
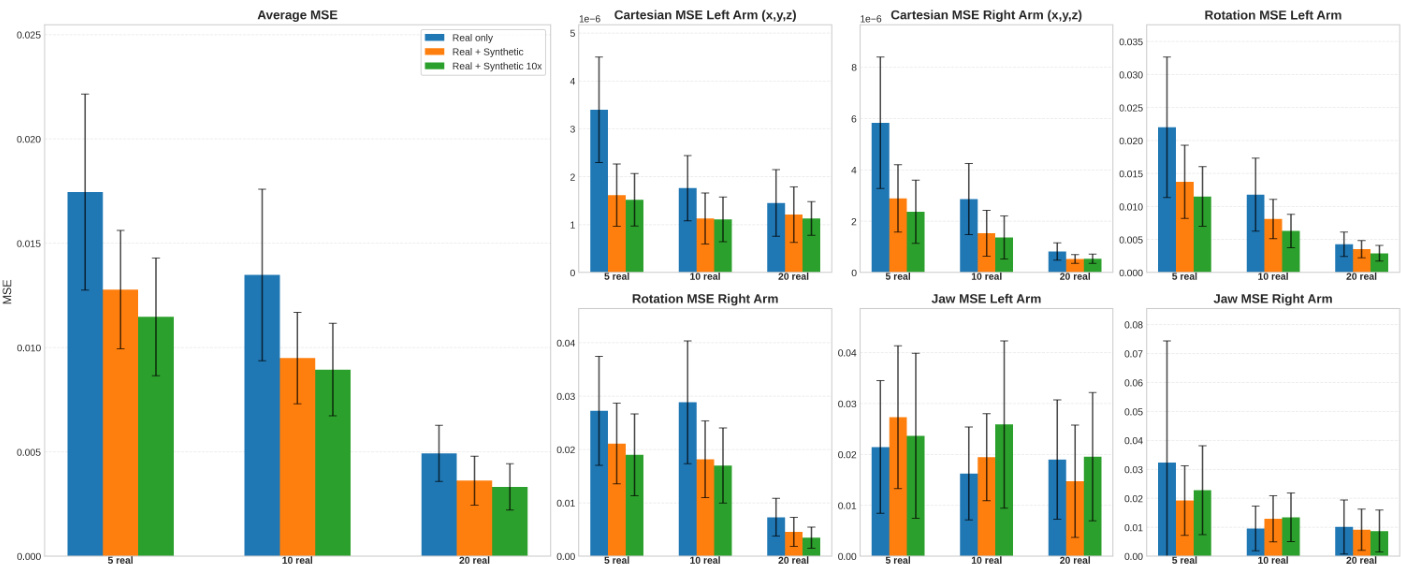
- 证明SurgWorld生成的合成数据可提升下游机器人策略学习:使用56或560条合成视频相比仅真实数据训练,显著降低笛卡尔、旋转与钳口动作的轨迹MSE,且在不同真实数据规模与策略模型(GR00T、π₀.₅)下均保持一致提升。
- 验证单视角合成视频可提升多视角策略性能,即使真实数据包含多相机视角,其优势仍持续存在于不同训练超参数与VLA架构中。
研究者在SATA数据集上评估了三种手术世界模型变体:Zero-Shot、Finetuned-Orig与SurgWorld。结果表明,SurgWorld在任务成功率、FVD与所有VBench指标上均表现最优,表明其在视频质量与任务性能方面均显著领先。

研究者使用表格展示SATA数据集中不同手术动作的视频片段分布,突出数据集在缝针抓取与缝线牵拉等特定手术任务上存在明显偏差。这种不平衡反映了数据采集过程中对特定手术任务的侧重,而打结与缝针穿刺等动作则代表性较弱。

研究者通过比较不同训练配置下的轨迹预测误差,评估合成数据对机器人策略性能的影响。结果表明,引入合成视频可显著降低所有动作分量(笛卡尔、旋转、钳口)的均方误差(MSE),尤其在使用10倍合成数据时提升最为明显。这表明合成数据能有效增强策略学习,尤其在真实数据有限的情况下。
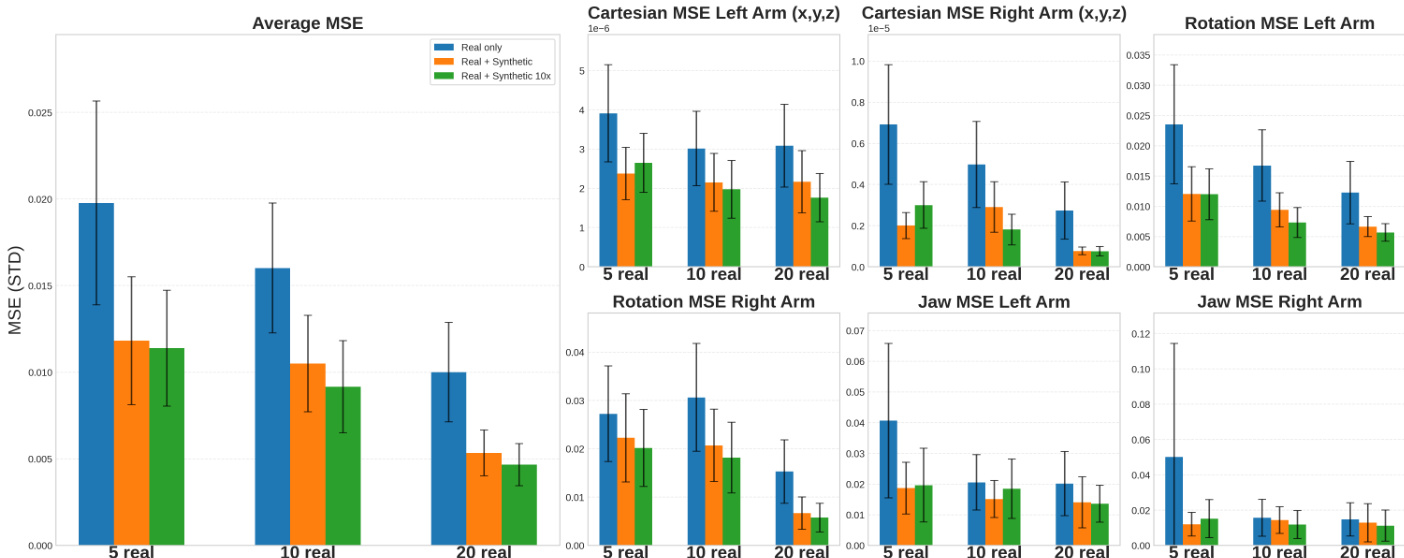
研究者通过比较不同训练配置下的轨迹预测误差,评估合成数据对机器人策略性能的影响。结果表明,引入合成视频可显著降低笛卡尔与旋转动作的均方误差(MSE),最佳性能出现在使用560条合成视频(真实+合成10倍)时,尤其在仅5条真实轨迹的情况下。该优势在不同真实训练数据数量与不同微调步数下均成立,表明合成数据即使在真实数据有限时仍能有效提升策略学习。
结果表明,SurgWorld模型在所有指标上均表现最佳,FVD最低,动态程度、成像质量与整体一致性评分最高,优于零样本与动作类别基线。这表明细粒度、专家标注的文本提示显著提升了手术视频生成的感知真实感与语义一致性。
