Command Palette
Search for a command to run...
SlideTailor:面向科学论文的个性化演示文稿生成
SlideTailor:面向科学论文的个性化演示文稿生成
Wenzheng Zeng Mingyu Ouyang Langyuan Cui Hwee Tou Ng
摘要
自动演示文稿生成能够显著简化内容创作流程。然而,由于每位用户的偏好各不相同,现有表述不充分的生成方法往往导致结果不理想,难以满足个体用户的具体需求。为此,我们提出了一项新任务,即基于用户指定的偏好来指导从论文到幻灯片的生成过程。我们设计了一种受人类行为启发的智能体框架——SlideTailor,该框架能够逐步生成可编辑且与用户意图对齐的幻灯片。与传统方法要求用户以详尽的文本形式描述偏好不同,我们的系统仅需用户提供一对“论文-幻灯片”示例以及一个视觉模板——这两种输入均为自然且易于提供的素材,能够隐式地编码用户在内容组织与视觉风格方面的丰富偏好。尽管这些输入具有隐式性和无标注的特点,我们的框架仍能有效提取并泛化其中的偏好信息,从而指导个性化的幻灯片生成。此外,我们引入了一种新颖的“语音链”(chain-of-speech)机制,用于将幻灯片内容与预设的口头讲解逻辑对齐,显著提升了生成幻灯片的质量,并支持下游应用,如视频演示制作。为支持这一新任务,我们构建了一个基准数据集,涵盖多样化的用户偏好,并设计了具有可解释性的评估指标,以实现稳健的性能评估。大量实验结果验证了所提框架的有效性与优越性。
一句话总结
新加坡国立大学的研究人员提出 SlideTailor,一种受人类行为启发的智能体框架,通过从隐式输入(如示例论文-幻灯片对和视觉模板)中推断用户偏好,生成与用户对齐且可编辑的幻灯片,无需显式文本描述。该系统采用“链式语音”机制,使幻灯片内容与计划的口头讲解同步,提升了视频演示等下游应用的质量。在新构建的、具有可解释性指标的基准上进行评估,SlideTailor 在个性化和可用性方面均优于现有方法。
主要贡献
- 现有论文转幻灯片生成方法常因缺乏明确规范、采用“一刀切”模式,难以契合个体用户偏好,导致自动化演示中的内容与视觉设计质量不佳。
- SlideTailor 引入一种受人类行为启发的智能体框架,从隐式输入(一篇论文-幻灯片示例对和一个 .pptx 模板)中推断丰富、多维度的用户偏好,实现无需详细文本指令即可生成个性化、可编辑的幻灯片。
- 该框架引入一种新颖的“链式语音”机制,使幻灯片内容与计划的口头讲解对齐,并在新构建的基准数据集上以可解释性指标进行评估,证明其在偏好对齐和整体演示质量方面表现更优。
引言
作者针对从科学论文生成个性化演示幻灯片的挑战展开研究。这一任务传统上将幻灯片创建视为一种“一刀切”的文档到幻灯片转换,忽视了演示设计的主观性。先前方法或缺乏用户定制能力,或依赖于详尽的显式偏好输入,这对大多数用户而言既负担沉重又不切实际。为克服这一局限,作者提出 SlideTailor,一种受人类行为启发的智能体框架,通过论文-幻灯片示例对和视觉模板这两种自然存在的输入,隐式学习用户偏好——这些输入本身便蕴含了内容与美学偏好,无需显式说明。系统将这些隐式信号提炼为偏好画像,再通过“链式语音”机制使幻灯片内容与计划的口头讲解对齐,提升连贯性,并支持下游视频演示生成。其关键贡献在于构建了一个包含多样化、可解释性指标的基准数据集,用于评估偏好对齐与演示质量,结果表明 SlideTailor 在个性化和整体幻灯片质量方面均优于现有方法。
数据集
- 该数据集名为 PSP(Paper-to-Slides with Preferences),旨在支持带有显式用户偏好建模的定制化论文转幻灯片研究。
- 数据集由三个核心部分构成:200 篇科学论文作为输入目标,50 组高质量的论文-幻灯片对,反映多样化的结构与风格偏好,以及 10 个学术幻灯片模板,代表常见的研究导向布局与美学风格。
- 来源论文从顶级人工智能与科学会议的公开论文集中人工筛选,涵盖 AAAI、ACL、CVPR、NeurIPS、Nature、Science、The Lancet 和 Chemical Reviews Letters 等,覆盖人工智能、机器学习、自然语言处理、计算机视觉、化学与医学等领域,确保主题与风格的广泛多样性。
- 50 组论文-幻灯片对旨在代表多种演讲者风格与学科惯例,支持对内容结构与美学展示偏好的建模。
- 10 个模板捕捉标准的学术幻灯片设计模式,为生成过程中的版式定制提供基础。
- 该数据集支持高达 100,000 种独特的输入组合(200 篇论文 × 50 组对 × 10 个模板),是目前最大的论文转幻灯片生成基准,且唯一支持开放式偏好建模。
- 论文中,作者使用该数据集训练并评估其模型,将 200 篇目标论文作为输入,并与 50 组论文-幻灯片对及 10 个模板组合,形成多样化的训练混合数据。
- 训练过程中,模型同时以输入论文和由论文-幻灯片对与模板推导出的指定偏好信号为条件,从而生成符合特定结构与美学偏好的幻灯片。
- 未对源论文或幻灯片进行显式裁剪;作者依赖于所选配对中的原始内容与布局结构。
- 每个样本的元数据包括来源会议、研究领域、演示风格与模板标识符,支持细粒度分析与基于偏好的评估。
方法
作者采用模块化框架 Slide-Tailor,解决偏好引导的论文转幻灯片生成任务。整体架构旨在从源论文生成演示幻灯片,同时遵循用户提供的内容与美学偏好。该过程始于两种不同的用户输入:一个论文-幻灯片样本对,作为内容偏好(如叙事流与重点)的参考;一个 .pptx 模板文件,编码美学偏好(如版式、色彩与字体)。这些输入通过一个流水线处理:首先从样本对与模板中提炼隐式偏好,再利用这些偏好指导生成结构化的幻灯片大纲与最终幻灯片实现。
该框架的核心分为两个主要阶段:偏好提炼与偏好引导的幻灯片规划。第一阶段为隐式偏好提炼,系统分析提供的论文-幻灯片样本对以提取内容偏好,同时分析模板文件以提取美学偏好。这通过一系列专用模块实现。Paper Reorganizer 处理输入论文与参考论文-幻灯片对,生成组织化内容,捕捉期望的结构与重点。Slide Outline Designer 基于重组后的内容与用户偏好,生成包含幻灯片主题、目的、演讲草稿与内容风格的详细演示大纲。该大纲随后由语音脚本生成器进一步优化。与此同时,Template Selector 利用从模板中提取的美学偏好,为大纲中的每张幻灯片推荐合适的布局。
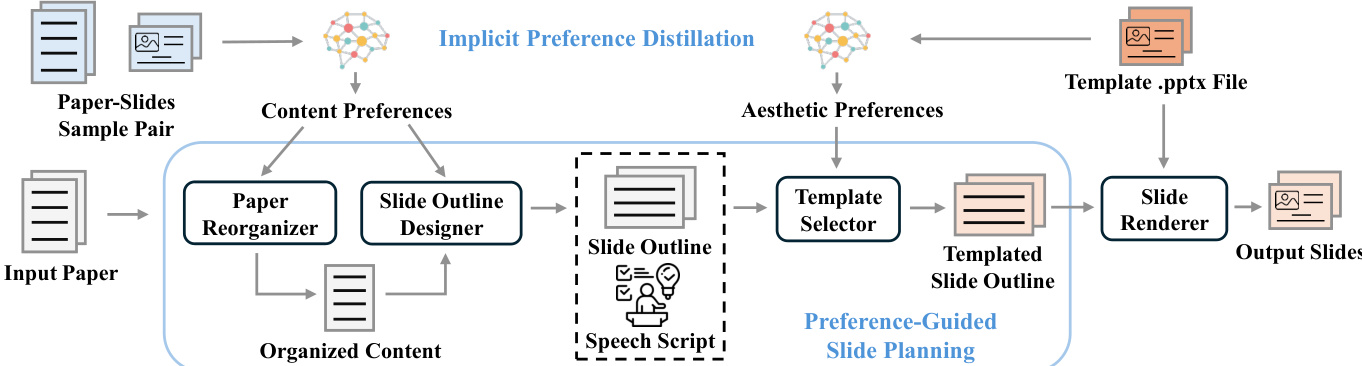
第二阶段为偏好引导的幻灯片规划,整合第一阶段的输出。Slide Renderer 将模板化幻灯片大纲与选定模板结合,生成最终输出幻灯片。这通过一个布局感知智能体实现,该智能体将计划的内容元素(如标题、文字、图像)映射到模板中的具体组件(如文本框、图像占位符)。此结构化映射可能涉及修改、替换或插入元素,以确保内容连贯性。随后,代码智能体生成可执行代码,直接对 .pptx 文件应用这些修改,保留原始布局与主题,同时生成完全可编辑的幻灯片。该框架还支持生成与演讲者意识匹配的视频演示,通过将生成的幻灯片与合成的语音及说话头视频组合,确保音视频同步。

该框架的设计实现了灵活且用户友好的演示创建方式。通过将内容与美学偏好作为独立、正交的输入,系统支持模块化适配。采用基于模板的编辑策略,确保最终输出保持用户期望的视觉风格,同时完全可编辑。整个流程由一系列专用模块驱动,包括 Paper Reorganizer、Slide Outline Designer 与 Template Selector,协同工作,将原始论文转化为精炼、个性化的演示文稿。
实验
- 在 PSP 数据集上使用 50 个目标论文进行评估,所提出的 SlideTailor 框架在基于 MLLM 的评估中获得 75.8% 的综合得分,超越三个最先进基线(ChatGPT、AutoPresent、PPTAgent),在基于偏好与无偏好指标上均表现更优。
- 展现出强大适应性,与开源模型 Qwen2.5-72B-Instruct 和 Qwen2.5-VL-72B-Instruct 在性能上具有竞争力,证实其在不同 MLLM 后端上均具备鲁棒性,无需针对特定模型进行调优。
- 消融实验表明,移除内容偏好引导导致关键指标(覆盖率、流畅性、内容结构)性能下降约 10%,验证了隐式偏好提炼的重要性;禁用“链式语音”机制使整体质量从 66.4% 降至 47.3%,凸显其在提升内容清晰度与连贯性中的关键作用。
- 60 次独立人工评估(4 名标注者,30 个案例)显示,SlideTailor 在 81.63% 的案例中优于 PPTAgent,且人工评分与 MLLM 评分之间存在强相关性(Pearson r = 0.64),验证了自动评估框架的有效性。
- 定性分析确认,SlideTailor 在美学与内容结构方面均与输入模板和示例幻灯片高度对齐,实现准确的视觉元素提取、合理的幻灯片排序,以及文本与视觉的有效融合,在版式保真度、视觉一致性与信息丰富性方面优于基线。
结果表明,人工评分与基于 MLLM 的评估在基于偏好与无偏好指标上均呈现强相关性,Pearson 相关系数在 0.602 至 0.683 之间,所有 p 值均低于 0.01。所有指标的平均相关系数为 0.638,表明自动评估框架与人工判断高度一致。

作者通过计算标注者间评分的绝对差异,分析人工评估的一致性。结果显示,对于基于偏好的指标,内容结构的平均绝对差异为 0.73,美学的为 0.95,分别有 86.67% 和 78.33% 的案例在 1 分以内;对于无偏好指标,内容与美学的平均绝对差异分别为 0.80 与 0.87,分别有 83.33% 与 81.67% 的案例在 1 分以内,表明人工评估者之间存在中等程度的一致性。

作者通过消融研究评估框架中关键组件的影响,结果表明,移除内容偏好引导会显著降低基于偏好的各项指标表现,尤其在覆盖率、流畅性与内容结构方面。禁用“链式语音”机制也导致整体性能大幅下降,尤其在内容质量方面,凸显了将幻灯片规划与预期讲解对齐的重要性。完整系统在所有指标上均取得最高分,证明了两个组件的有效性。

作者采用全面的基于偏好与无偏好的指标评估幻灯片生成方法,结果显示,当使用 GPT-4.1 时,其框架在所有指标上获得最高综合得分 75.8%,在两类指标上均优于所有基线。该方法在内容结构与美学设计方面与用户偏好高度对齐,同时在内容清晰度与视觉吸引力方面生成高质量幻灯片,经自动评估与人工评估双重验证。

作者采用全面的指标集评估其框架与现有基线的性能,结果显示,其方法在所有基于偏好与无偏好的指标上均优于 PPTAgent。具体而言,其方法在内容结构、美学对齐、内容质量与整体演示方面得分更高,展现出更强的用户偏好对齐能力与更高的通用幻灯片质量。
