Command Palette
Search for a command to run...
InsertAnywhere:连接4D场景几何与扩散模型以实现逼真的视频物体插入
InsertAnywhere:连接4D场景几何与扩散模型以实现逼真的视频物体插入
Hoiyeong Jin Hyojin Jang Jeongho Kim Junha Hyung Kinam Kim Dongjin Kim Huijin Choi Hyeonji Kim Jaegul Choo
摘要
基于扩散模型的视频生成技术近年来取得显著进展,为可控视频编辑开辟了新的可能。然而,由于缺乏对四维(4D)场景的充分理解,以及在处理遮挡关系和光照效应方面存在不足,真实场景下的视频对象插入(Video Object Insertion, VOI)仍面临重大挑战。为此,我们提出InsertAnywhere——一种新型的VOI框架,能够实现几何一致的对象定位与外观逼真的视频合成。本方法首先引入一个具备4D感知能力的掩码生成模块,该模块通过重建场景几何结构,并在时间维度上保持一致性地传播用户指定的对象位置,同时确保遮挡关系的连贯性。在此空间基础之上,我们进一步扩展了基于扩散的视频生成模型,使其能够联合生成插入对象及其周围局部环境的动态变化,包括光照、阴影等视觉细节。为支持监督训练,我们构建了ROSE++——一个具备光照感知能力的合成数据集。该数据集通过将原始的ROSE对象移除数据集转换为三元组形式:包含被移除对象的视频、包含对象的视频,以及由视觉语言模型(VLM)生成的参考图像,从而为模型提供精确的上下文对齐监督信号。通过大量实验验证,我们证明所提出的框架能够在多种真实世界场景中生成几何合理、视觉连贯的物体插入结果,显著优于现有研究方法及商业级模型。
一句话总结
韩国科学技术院(KAIST AI)与SK电信的研究人员提出了InsertAnywhere,一种基于扩散模型的视频物体插入框架,该框架融合了4D场景理解与光照感知合成,能够在复杂运动和视角下实现几何一致且外观忠实的物体放置,在真实生产场景中优于以往方法。
主要贡献
-
我们提出了一种4D感知的掩码生成模块,能够从输入视频中重建场景几何,并将用户指定的物体放置信息跨帧传播,确保几何一致性、时间连贯性以及对遮挡的准确处理,即使在复杂相机运动下也能保持稳定。
-
我们的框架扩展了基于扩散的视频生成模型,通过利用几何感知掩码序列和上下文感知扩散先验,联合合成插入物体及其周围局部变化(如光照、阴影和反射),实现更自然的视觉融合。
-
我们构建了ROSE++,一个新颖的光照感知合成数据集,通过在ROSE物体移除数据集基础上引入VLM生成的参考图像进行增强,支持通过反向物体移除任务进行监督训练,并在性能上超越现有研究与商业模型。
引言
研究人员利用4D场景理解与基于扩散的视频生成技术,实现逼真的视频物体插入(VOI),这是电影后期制作和商业广告应用中的关键技术能力,要求物体能无缝融入动态场景,同时保证几何精度与视觉保真度。以往工作因受限于4D场景建模能力,常出现物体位置不一致的问题,且难以处理遮挡与光照变化,尤其在复杂运动场景中插入物体时表现不佳。本文主要贡献为InsertAnywhere框架:首先使用4D感知掩码生成模块重建场景几何,并在时间上保持连贯性地传播物体掩码,即使在遮挡情况下也能实现精准定位;随后扩展扩散模型,通过在ROSE++这一新型合成数据集上训练,联合生成插入物体及其周围局部变化(如光照与阴影),该数据集通过在物体移除视频中引入VLM生成的参考图像,将移除任务反转为插入任务。该方法实现了高保真、外观一致的视频生成,适用于实际生产环境。
数据集
- ROSE++数据集是一个合成的、光照感知的数据集,专为训练视频物体插入(VOI)模型而设计,包含四个核心组成部分:移除物体的视频、包含物体的视频、对应的物体掩码视频以及参考物体图像。
- 该数据集源自原始的ROSE数据集,后者专为物体移除任务设计,包含包含物体的视频、物体掩码以及移除了物体及其副作用(阴影、反射、光照变化)的视频。
- 为支持VOI训练,作者将ROSE数据集重构为:以移除物体的视频作为源,以包含物体的视频作为目标,形成监督训练对。
- 由于原始ROSE数据集缺乏显式的参考物体图像,作者引入基于VLM的物体检索流程:对每段视频,采样包含目标物体的n帧,提取物体区域,将这些多视角裁剪图像与文本提示一同输入视觉-语言模型(VLM),生成m张白底候选物体图像。
- 候选图像通过基于DINO的相似性度量进行排序,该度量将每张生成图像与视频帧中的原始物体裁剪进行比较,选择平均相似度得分最高的图像作为最终参考物体图像。
- 该方法确保了上下文对齐,避免了以往直接从视频帧中裁剪物体所导致的复制粘贴伪影,保持了训练与推理阶段输入条件的一致性。
- 数据集在训练中混合使用多种视频类型与物体类别,训练划分经过精心平衡,以覆盖多样化的场景与物体外观。
- 训练过程中,作者采用裁剪策略,从多帧中提取物体区域,为VLM提供多视角上下文,提升生成参考图像的质量与一致性。
- 每个样本的元数据包含场景类型、物体类别以及帧级掩码标注,支持细粒度评估与分析。
- 为评估,作者提出了VOIBench,一个包含50段视频剪辑的基准测试集,涵盖室内、室外与自然环境,每段视频包含两个物体。针对每个场景爬取语义相关的物体,共生成100段评估视频。
- 评估指标包括主体一致性(CLIP-I, DINO-I)、视频质量(VBench:图像质量、背景/主体一致性、运动平滑性)以及遮挡条件下的多视角一致性。
方法
研究人员提出了一种两阶段框架,用于实现逼真的视频物体插入(VOI),该框架结合了4D场景理解与基于扩散的视频合成。整体架构如框架图所示,包含两个阶段:4D感知掩码生成阶段与视频物体插入阶段。第一阶段生成时间一致且几何准确的掩码序列,编码物体在场景中的位置、尺度与遮挡关系。该掩码序列随后作为条件输入到第二阶段的扩散视频生成器中,实现对插入物体与场景光照、阴影、运动等自然融合的逼真视频合成。
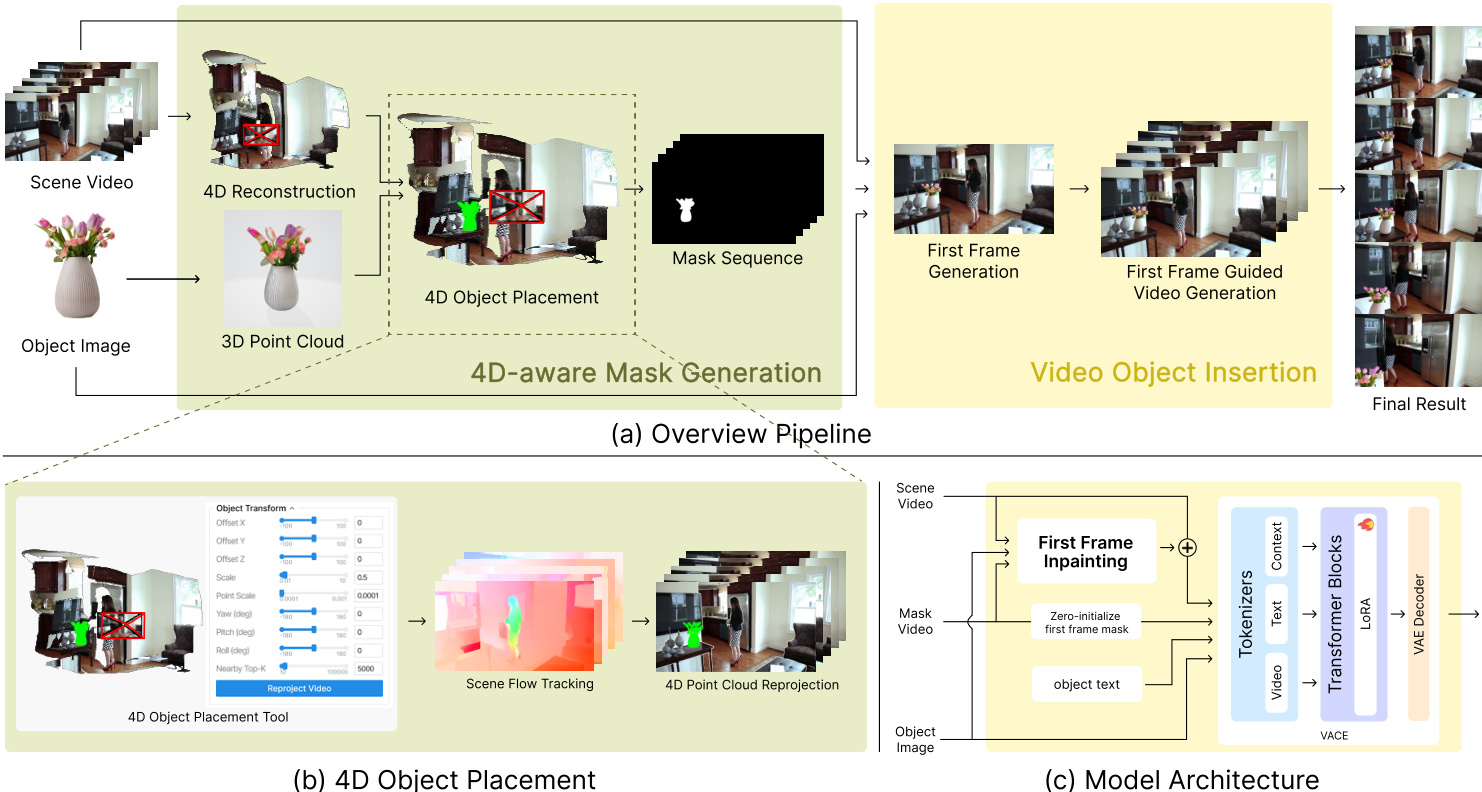
4D感知掩码生成阶段首先对输入视频进行4D场景重建。该重建基于Uni4D范式,通过整合多个预训练视觉模型(包括深度估计、光流与分割网络)的预测,联合估计每帧的几何结构与相机运动。重建后的4D场景为环境提供了鲁棒的时空表征。用户随后在3D重建场景中(通常对应第一帧)交互式地放置并缩放参考物体。物体图像通过预训练的单视角重建网络转换为3D点云。该点云通过刚性变换与重建场景对齐,交互式界面控制该变换,以精确调整物体相对于场景几何的位置、朝向与大小。

为确保时间一致性,物体运动通过场景光流在帧间传播。使用SEA-RAFT估计场景的稠密光流场,物体运动通过计算第一帧中物体周围K个最近3D点的平均3D运动向量进行优化。基于场景光流的传播机制更新物体中心,确保插入物体的运动在物理上合理,并与周围场景动态同步。传播完成后,物体的每个3D点通过估计的相机内参与外参重新投影到各帧的图像平面。该相机对齐的重投影步骤考虑了相机运动、视差与遮挡,为每帧生成几何一致的轮廓。生成的合成视频序列随后由分割模型处理,提取出时间对齐的二值掩码序列,作为视频生成阶段的几何感知且时间一致的空间条件。
视频物体插入阶段利用预训练的图像物体插入模型作为强先验,引导最终视频的合成。作者通过LoRA模块微调视频扩散模型,实现高效适配,同时保留模型原有的预训练视频生成能力,并提升其在物体插入场景中的适应性。模型架构如图所示,首先生成初始帧,以高保真度建立物体的外观与光照条件。该视觉参考随后在整个后续视频生成过程中传播,以维持颜色、纹理与光照的一致性。模型在ROSE++数据集上训练,通过显式监督几何与光照关系,学习光照与阴影感知行为,从而实现柔和阴影与材质依赖的阴影合成。
实验
- 定性结果表明,InsertAnywhere在物体保真度与遮挡处理方面优于Pika Pro与Kling,4D感知掩码使其在复杂场景(如物体从手后移动)中表现稳健。
- 定量结果(表3)显示,InsertAnywhere在CLIP-I与DINO-I得分上最高,表明主体一致性更优,并在整体视频质量与多视角一致性方面表现突出,而基线方法引入了背景伪影。
- 消融实验确认,4D感知掩码对遮挡处理至关重要,首帧修复有助于初始物体身份保持,而基于ROSE++的LoRA微调显著提升光度一致性,实现逼真的光照与阴影生成。
- 用户研究(表4)显示,InsertAnywhere在所有评估维度(物体真实感、光照一致性、遮挡完整性、整体自然度)均获得强烈偏好,投票比例高于基线方法。
- 在ROSE++数据集上,LoRA微调使模型能够动态适应场景光照,实现物体光照与阴影的自适应生成,显著提升VBench得分与物理合理性。
作者通过定量评估将本方法与基线方法在主体与视频质量指标上进行比较。结果表明,本方法在主体一致性与多视角一致性方面得分最高,同时在背景一致性与图像质量方面也优于其他方法,表明整体视频真实感与物体保真度更优。

结果表明,与使用随机帧参考的基线方法相比,所提方法在多视角一致性方面表现更优,得分达到0.5857,而基线为0.5295。该提升证明了基于VLM的物体生成在捕捉时空结构与防止遮挡相关不一致方面的有效性。

作者通过消融实验评估框架中不同组件的影响,表格展示了在主体一致性、视频质量与多视角一致性指标上的定量结果。结果表明,完整方法(“Ours”)在所有评估指标上均取得最高分,优于组件更少的配置,验证了4D感知掩码、首帧修复与基于ROSE++的LoRA微调的有效性。

作者通过用户研究评估本方法与基线方法的性能,结果如表所示。结果显示,本方法在所有评估标准上得分显著更高,尤其在物体真实感、遮挡完整性与整体自然度方面表现突出,证明了在视频物体插入中具有更优的真实感与一致性。
