Command Palette
Search for a command to run...
InSight-o3:通过泛化视觉搜索赋能多模态基础模型
InSight-o3:通过泛化视觉搜索赋能多模态基础模型
Kaican Li Lewei Yao Jiannan Wu Tiezheng Yu Jierun Chen Haoli Bai Lu Hou Lanqing Hong Wei Zhang Nevin L. Zhang
摘要
能够让人工智能代理“通过图像进行思考”,需要推理与感知能力的复杂融合。然而,当前开放的多模态代理在推理能力方面仍存在显著不足,而这正是完成现实世界任务(如分析包含密集图表或示意图的文档、导航地图等)所至关重要的环节。为弥补这一差距,我们提出了 O3-Bench,一个专为评估多模态推理能力而设计的新基准,其特点在于对视觉细节进行交错式关注。O3-Bench 包含一系列极具挑战性的问题,要求代理通过多步推理,从图像的不同区域中整合细微的视觉信息。即便对于前沿系统如 OpenAI o3,其在 O3-Bench 上的准确率也仅为 40.8%,凸显了该任务的难度。为推动进展,我们提出了 InSight-o3,一种多代理框架,由一个视觉推理代理(vReasoner)和一个视觉搜索代理(vSearcher)组成。我们首次引入“广义视觉搜索”这一任务,旨在定位以自由语言描述的、具有关系性、模糊性或概念性的图像区域,而不仅限于自然图像中的简单物体或图形。随后,我们训练了一个专用于该任务的多模态大语言模型(LLM),采用强化学习进行优化。作为即插即用的组件,我们的 vSearcher 能够显著提升前沿多模态模型(作为 vReasoner)在多种基准测试中的表现。这一成果标志着向强大、类 o3 的开放系统迈出了切实一步。相关代码与数据集可访问:https://github.com/m-Just/InSight-o3。
一句话总结
香港科技大学与华为的研究人员提出 INSIGHT-o3,一种多智能体框架,其中包含一个经过目标训练的视觉搜索智能体(vSearcher),通过强化学习实现对关系性或概念性区域的泛化视觉搜索,显著提升了 OpenAI o3 等开放智能体在需要细粒度视觉整合的任务中的多模态推理能力,该能力在新提出的 O3-BENCH 基准上得到验证。
主要贡献
-
本文提出 O3-BENCH,一个新基准,旨在评估复杂真实任务(如地图导航和跨图表分析)中的多模态推理能力,要求智能体通过整合高信息密度图像中分散区域的细微视觉细节进行多步推理——这类任务即使前沿模型如 OpenAI o3 也难以应对,准确率仅达 40.8%。
-
作者提出 INSIGHT-o3,一种多智能体框架,将图像推理分解为两个专用组件:用于高层推理的视觉推理智能体(vReasoner)和用于定位概念性或关系性描述区域的视觉搜索智能体(vSearcher),从而实现分而治之的方法,更有效地应对交错推理任务。
-
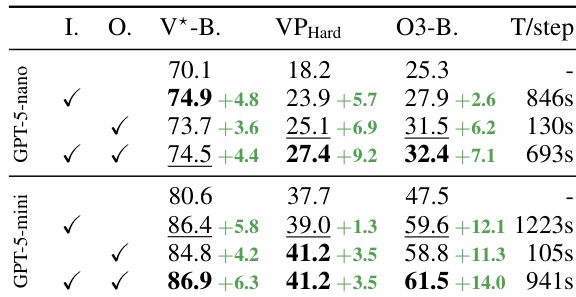
作者提出 InSight-o3-vS,一种通过强化学习训练的多模态模型,专用于泛化视觉搜索——即在自由形式语言描述下定位模糊、关系性或概念性区域——作为即插即用组件使用时表现出显著性能提升,使 GPT-5-mini 在 O3-BENCH 上的准确率从 39.0% 提升至 61.5%,Gemini-2.5-Flash 在 V*-Bench 上的准确率从 80.1% 提升至 87.6%。
引言
AI 智能体对复杂、高信息密度视觉内容(如地图、图表和示意图)进行推理的能力,对于文档分析、导航等现实应用至关重要,但当前开放的多模态模型在处理交错的、多步推理任务时仍存在困难。以往的基准和系统主要关注简单的物体定位或单区域查询,难以应对跨空间分散图像区域的关系性、模糊或概念性区域描述。作者提出 O3-BENCH,一个新基准,通过具有挑战性的现实任务评估深度视觉推理能力,要求跨区域证据聚合。为应对这一挑战,作者提出 INSIGHT-o3,一种多智能体框架,其中视觉推理智能体(vReasoner)由一个专用的视觉搜索智能体(vSearcher)增强。vSearcher 通过强化学习训练,执行泛化视觉搜索——在任意图像中使用自由形式语言定位概念性描述区域——从而实现精确、即插即用的现有多模态模型增强。该方法在多个基准上显著提升性能,展示了通往开放、类 o3 推理系统的一条实用路径。
数据集
- O3-BENCH 数据集包含 204 张高分辨率、信息密集的图像:117 张复合图表和 87 张数字地图,共生成 345 个多选问答对(163 个基于图表,182 个基于地图)。
- 图表图像来源于 MME-RealWorld 的“图表与表格”子集及互联网,通过 PP-DocLayout_plus-L 进行筛选,仅保留至少检测出 8 个布局的图像,以确保高视觉复杂度。地图图像通过关键词搜索从互联网手动收集,聚焦于场所级地图(如校园、公园、公交路线),要求阅读图例并视觉定位实体,排除依赖世界知识的大尺度制图。
- 每个问答对包含六个选项,其中四个干扰项来自图像或与正确答案视觉相似,第六个选项(F)为“无正确选项”,用于在无有效选项时鼓励模型评估整张图像。
- 数据集通过混合流程构建:使用布局检测、OCR 和 GPT-5 生成每张图像的五个候选问题,随后经过严格的人工筛选、验证和重写,以确保事实准确性、多跳推理和清晰性。
- 为确保难度,所有候选 QA 由三个专有多模态大模型(GPT-5-mini、Gemini-2.5-Flash、Doubao-Seed-1.6)评估;被三者全部解决的条目被剔除。最终条目由独立评审员进行交叉验证,以确保一致性和正确性。
- 平均每样本包含 8.7 个布局和 2.4 个目标布局,图像分辨率范围为 2K 至 10K 像素(平均:3,967 × 4,602 像素),反映高信息密度及对细粒度视觉搜索的需求。
- 训练阶段,作者通过拼接来自 Visual CoT 和 V* 过滤子集的低至中等分辨率图像生成循环内强化学习(RL)数据,确保目标区域小且需主动搜索。循环外 RL 数据则来自 InfographicVQA,使用 PP-DocLayout_plus-L 检测并合并布局框,再由 GPT-5-nano 生成简洁、视觉相关的区域描述,模拟真实搜索查询。
- 在两种训练数据中,布局框均按大小、宽高比和相关性进行过滤,严格规则避免平凡或过大区域。图表和表格保持为独立单元,合并框需验证以维持有意义上下文。
- 最终训练数据旨在激励视觉搜索:拼贴图增加视觉密度和任务难度,而循环外数据提供区域描述,引导目标探索但不暴露内容,从而在强化学习中实现有效的奖励塑造。
方法
作者提出 INSIGHT-O3,一种双智能体框架,旨在解决多模态语言模型中高层推理与细节视觉感知的整合难题。该系统将问题求解流程分解为两个专用智能体:视觉推理智能体(vReasoner)和视觉搜索智能体(vSearcher)。vReasoner 负责高层抽象推理和问题分解,而 vSearcher 专注于从输入图像中定位和检索特定视觉证据。这种分离使 vReasoner 能专注于逻辑推理,在需要时发出视觉信息请求,而 vSearcher 则高效定位并返回请求区域。智能体间的交互遵循多轮协议:vReasoner 生成区域描述,vSearcher 在图像中定位对应区域,返回的裁剪区域再反馈给 vReasoner 进行进一步分析。该过程迭代进行,直至 vReasoner 能够自信地生成最终答案。该框架设计为模块化,使 vSearcher 可作为即插即用组件,增强多种 vReasoner 模型的性能。
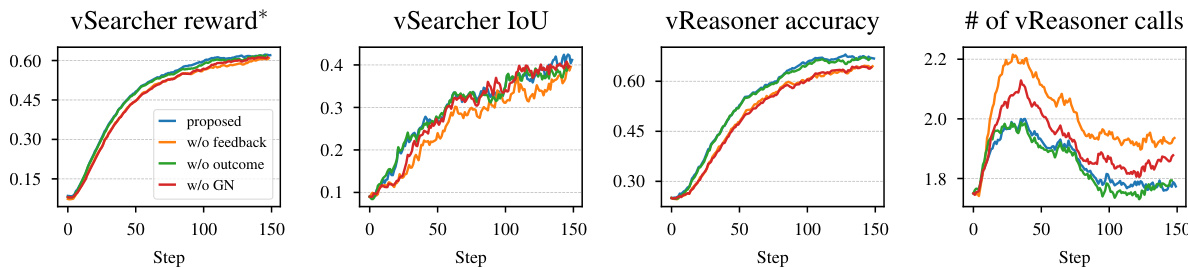
vSearcher 智能体的训练采用混合强化学习(RL)算法,结合循环内与循环外组件,如训练流程所示。循环外组件利用预生成的区域描述与真实边界框配对,通过直接的交并比(IoU)监督实现高效训练。这使 vSearcher 能够基于精确文本描述准确定位区域。相比之下,循环内组件使用训练期间 vReasoner 实时生成的区域描述,更贴近推理阶段将遇到的真实、动态任务。该方法确保 vSearcher 学会处理推理智能体使用的自然、常具模糊性的语言。

vSearcher 的奖励函数设计旨在鼓励准确的定位和工具的使用。对于循环外 RL,奖励为格式奖励与 IoU 奖励的加权和,其中 IoU 奖励定义为 rIoU=max{0,IoU(b,b∗)−α}/(1−α),α 为决定最小可接受重叠的阈值。该奖励结构激励 vSearcher 生成不仅准确,且至少使用一次图像裁剪工具验证结果的区域。对于循环内 RL,使用伪 IoU 奖励 r^IoU,其来源于 vReasoner 的反馈。vReasoner 根据预测对任务的相关性评估为“有帮助”或“无帮助”,该评分与最终答案正确性结合形成伪奖励:r^IoU=I[s=c=1]。该机制提供更真实(尽管更嘈杂)的监督形式,反映 vSearcher 输出的实际效用。
训练目标基于 GRPO 算法,针对混合训练设置进行了修改。一批 vSearcher 输出的目标函数定义为 J(θ)=M1∑i=1M∣oi∣1∑t=1∣oi∣{min[γt(θ)A^t,clip(γt(θ),1−ϵ,1+ϵ)A^t]−βDKL[πθ∣∣πref]}。两个组件的优势估计方式不同:循环外组件的优势通过组均值和标准差归一化,而循环内组件则在所有动态生成任务上全局归一化。这种全局归一化是必要的,因为循环内任务不形成独立组,优势估计需在整个动态生成查询集中可比。策略模型 πθ 被训练以最大化此目标,工具响应标记的损失被掩码,因其不由策略生成。
实验
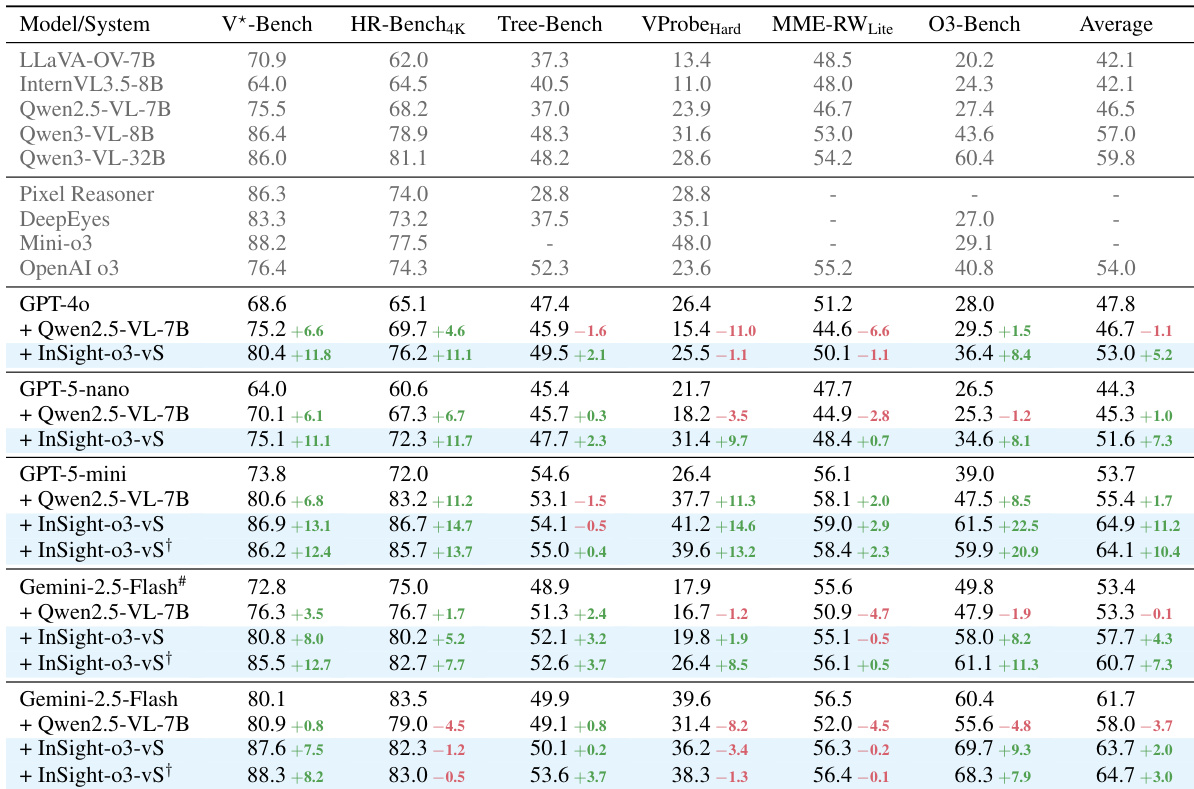
- 主实验:在 GPT-5-mini-2025-08-07(vReasoner)下训练 InSight-o3-vS 作为视觉搜索智能体,集成到多种 vReasoner 模型(包括 Gemini-2.5-Flash 和 GPT-5-nano)中,均在多个基准上实现显著性能提升。
- 泛化能力:InSight-o3-vS 将 GPT-5-nano 在 VisualProbe-Hard 上的准确率从 21.7% 提升至 31.4%,在 O3-BENCH 上从 26.5% 提升至 34.6%,整体从 44.3% 提升至 51.6%。在 Gemini-2.5-Flash 下,其在 V*-Bench 和 O3-BENCH 上均取得 7–10% 的领先优势。
- O3-BENCH 性能:引入 InSight-o3-vS 后,GPT-5-mini 在 O3-BENCH 上与 Gemini-2.5-Flash 的差距从 21.4% 缩小至 8.2%,凸显图像推理的关键作用。
- 输入分辨率:更高图像分辨率有助于性能提升,但 InSight-o3-vS 在 0.8M 像素(训练分辨率的 25%)下仍有效,性能下降极小,且在低分辨率下 vSearcher 调用次数更高。
- 消融实验:混合 RL 训练(循环内 + 循环外)优于单一组件,完整设置表现最佳。结合反馈与全局归一化的奖励设计优于消融变体。
- 目标布局消融:向 GPT-5-mini 和 Qwen2.5-VL-7B 提供目标布局可显著提升 O3-BENCH 上的准确率,证实精确视觉定位的必要性。
- 失败分析:多数错误源于 vReasoner 的幻觉或对视觉证据的误读,而非 vSearcher 失败;InSight-o3-vS 始终返回与自然语言描述高度一致的高质量裁剪图像。
- 开源模型集成:使用 Qwen3-VL-32B vReasoner 的 InSight-o3 超越基线模型和非 RL 基线,表明其在开源模型中具有巨大潜力。
作者评估了训练与测试图像分辨率对模型性能的影响,表明训练时更高分辨率可提升各基准上的结果。当测试分辨率提高时,性能通常随之改善,但使用 vSearcher 的优势随 vReasoner 已能清晰感知细节而减弱。vSearcher 在不同分辨率下性能稳定,高分辨率因初始图像清晰度更高,导致 vSearcher 调用次数减少。

作者使用 InSight-o3-vS(以 GPT-5-mini 为 vReasoner 训练的视觉搜索智能体)来增强多种多模态模型的性能。结果显示,InSight-o3-vS 显著提升了 GPT-5-mini 和 Gemini-2.5-Flash 在多个基准上的平均性能,尤其在 O3-Bench 上,有效缩小了这些模型与更强基线之间的性能差距。
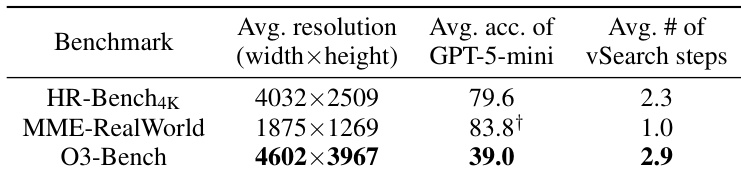
结果显示,O3-Bench 的平均图像分辨率显著高于 HR-Bench4K 和 MME-RealWorld,且 GPT-5-mini 在 O3-Bench 上的平均准确率低于其他两个基准。O3-Bench 所需的平均 vSearch 步数也更高,表明该基准任务解决难度更大。
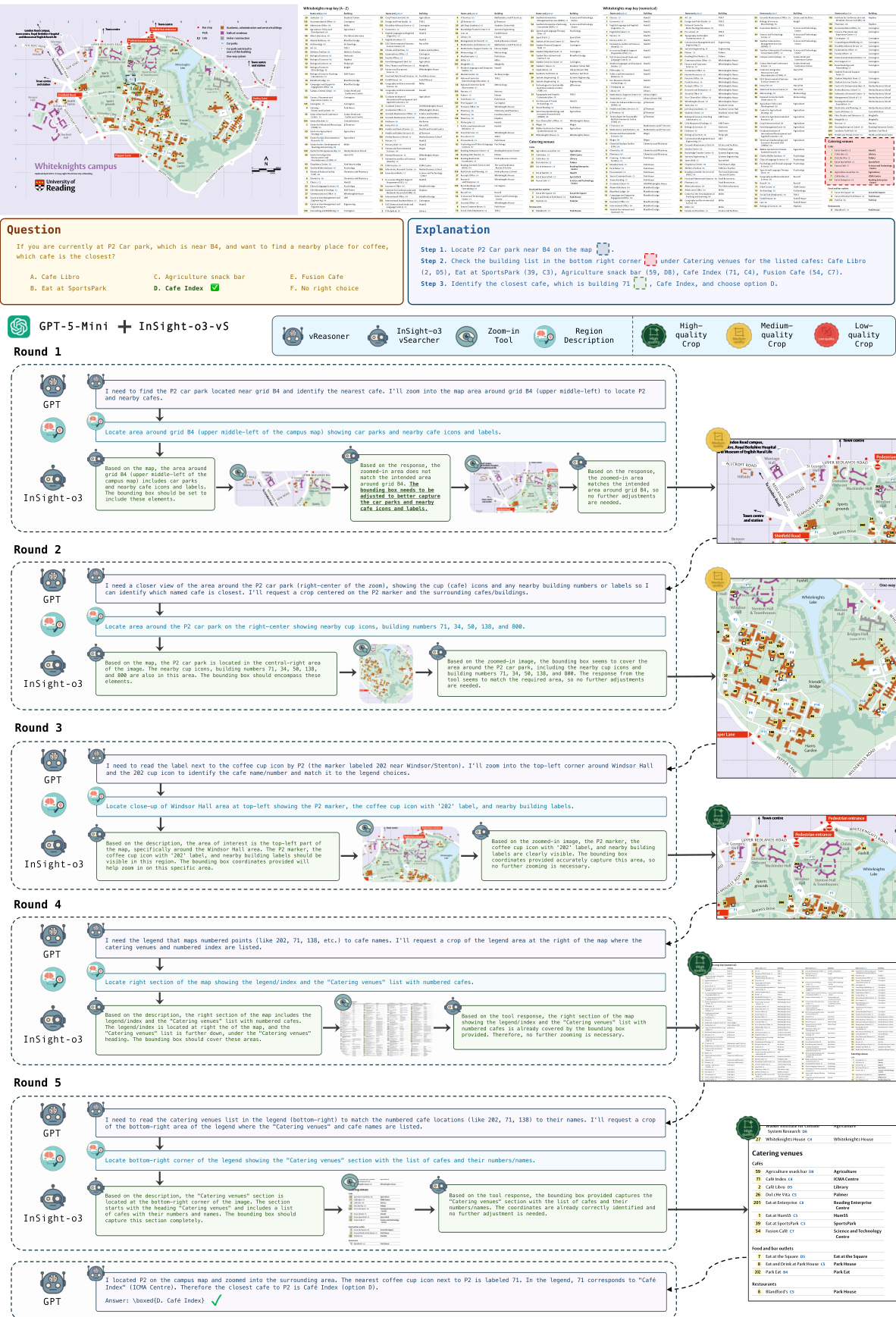
作者使用 GPT-5-mini 作为 vReasoner,并训练 vSearcher(InSight-o3-vS)协助其完成视觉推理任务。结果显示,InSight-o3-vS 显著提升了 GPT-5-mini 在 O3-BENCH 上的性能,当 vSearcher 与 vReasoner 联合使用时,其得分从 25.3% 提升至 61.5%。
作者利用提供的训练动态分析不同奖励设计选择对 InSight-o3-vS 性能的影响。结果显示,所提出的奖励设置在所有指标上均持续优于消融变体,其中“无反馈”变体表现最差。每 QA 的 vReasoner 调用次数随训练进程逐渐减少,表明模型在训练过程中学会更高效地使用 vSearcher。