Command Palette
Search for a command to run...
扩散模型洞悉透明性:将视频扩散模型重用于透明物体的深度与法向估计
扩散模型洞悉透明性:将视频扩散模型重用于透明物体的深度与法向估计
摘要
透明物体对感知系统而言始终是一项严峻挑战:折射、反射与透射现象破坏了立体视觉(stereo)、飞行时间(ToF)以及纯判别性单目深度估计所依赖的基本假设,导致深度图中出现空洞且估计结果在时间上不稳定。我们的核心观察是,现代视频扩散模型已能合成逼真的透明现象,这表明它们内部已隐式学习到了光学规律。为此,我们构建了 TransPhy3D——一个面向透明与反射场景的合成视频数据集:包含11,000段由Blender/Cycles渲染的视频序列。场景由精心筛选的类别丰富静态资产与形状复杂的程序化资产组合而成,并搭配玻璃、塑料、金属等材质。我们采用基于物理的光线追踪技术生成RGB图像、深度图与法线图,并使用OptiX进行去噪处理。在大型视频扩散模型的基础上,我们通过轻量级LoRA适配器学习一个从视频到视频的深度(及法线)转换器。训练过程中,我们将RGB图像与(含噪)深度潜在表示在DiT主干网络中进行拼接,并联合在TransPhy3D与现有逐帧合成数据集上进行端到端训练,从而实现对任意长度输入视频的时序一致预测。由此得到的模型——DKT,在涉及透明性的真实与合成视频基准测试中均达到零样本SOTA性能:包括ClearPose、DREDS(CatKnown/CatNovel)以及TransPhy3D-Test。其在准确率与时间一致性方面均显著优于现有强基线模型;其法线版本在ClearPose上的视频法线估计任务中也取得了最佳结果。一个参数量仅为13亿的轻量级版本,可实现约0.17秒/帧的推理速度。将DKT集成至抓取系统中,其生成的深度信息显著提升了在透明、反光与漫反射表面下的抓取成功率,超越了以往所有深度估计算法。综上,这些成果支持一个更广泛的论断:“扩散模型懂透明。” 生成式视频先验可被高效、无需标注地重用于复杂现实世界操作任务中的鲁棒、时序一致感知。
一句话总结
来自北京人工智能研究院、清华大学等机构的作者,通过在新型合成视频数据集 TransPhy3D(包含11,000个透明/反射场景)上对视频扩散模型进行LoRA微调,提出DKT——一种用于透明物体视频深度与法向估计的基础模型,在真实与合成基准上实现零样本SOTA性能,可应用于跨透明、反射和漫反射表面的机器人抓取任务。
主要贡献
- 透明与反射物体因折射、反射等物理现象,持续对深度估计构成挑战,这些现象破坏了立体视觉、飞行时间(ToF)和单目方法的假设,导致预测结果出现孔洞和时间不稳定性。
- 作者提出TransPhy3D,一个全新的合成视频数据集,包含11,000个序列(共132万帧),通过基于物理的光线追踪与OptiX去噪技术实现透明与反射场景的高保真渲染,支持视频扩散模型在真实透明物体动态上的训练。
- 通过使用轻量级LoRA适配器复用大型视频扩散模型,并在TransPhy3D与现有帧级数据集上联合训练,所提出的DKT模型在真实与合成基准上实现零样本SOTA性能,显著提升视频深度与法向估计的准确率与时间一致性。
引言
准确估计透明与反射物体的深度仍是3D感知与机器人操作中的关键挑战,传统依赖立体或飞行时间传感器的方法因折射、反射与透射而失效。先前的数据驱动方法受限于小规模、静态数据集及泛化能力差,而现有视频模型则面临时间不一致问题。作者提出TransPhy3D,首个大规模合成视频数据集,涵盖11,000个序列(132万帧),采用基于物理的光线追踪与OptiX去噪技术进行渲染。他们利用该数据集,将预训练视频扩散模型(VDM)重构为DKT——一种用于视频深度与法向估计的基础模型,采用轻量级LoRA适配器。通过在视频与帧级合成数据集上联合训练,DKT在真实与合成基准上实现零样本SOTA性能,输出时间一致、高精度的预测结果。该模型每帧运行效率达0.17秒,显著提升在多种表面类型下的机器人抓取成功率,证明生成式视频先验可有效复用于复杂光学现象的鲁棒、无标签感知。
数据集
- 该数据集TransPhy3D是专为透明与反射物体设计的新型合成视频数据集,包含11,000个独特场景,每场景120帧,总计132万帧。
- 数据集由两个互补来源构建:从BlenderKit收集的574个高质量静态3D资产,经Qwen2.5-VL-7B模型筛选以识别透明或反射属性;以及通过参数化生成的程序化3D资产,可通过调节参数实现无限形状变化。
- 采用精心筛选的材质库,涵盖多种透明材质(如玻璃、塑料)与反射材质(如金属、釉面陶瓷),确保渲染结果高度逼真。
- 场景通过物理模拟生成:从M个资产中随机选取,在预设环境(如容器、桌面)中初始化6自由度位姿与缩放,并允许其下落与碰撞,以实现自然且物理合理的布局。
- 相机轨迹以物体几何中心为圆心生成圆形路径,并加入正弦扰动以引入动态视角变化;视频使用Blender的Cycles引擎渲染,采用光线追踪实现精确的光传输,包括折射与反射。
- 最终帧通过NVIDIA OptiX-Denoiser进行去噪,提升视觉质量。
- 作者使用TransPhy3D训练DKT——一个视频深度估计模型,方法为对预训练视频扩散模型进行LoRA微调。该数据集作为主要训练源,未明确提及数据划分或混合比例,但其多样化的场景构成支持强泛化能力。
- 未进行裁剪,直接使用完整渲染帧。物体类别、材质类型与相机参数等元数据通过场景生成流程隐式编码,并在训练中使用。
方法
作者以WAN框架为基础构建其视频扩散模型,包含三个核心组件:变分自编码器(VAE)、由多个DiT块组成的扩散Transformer(DiT)以及文本编码器。VAE负责将输入视频压缩至低维潜在空间,并将预测的潜在变量解码回图像域。文本编码器将文本提示处理为嵌入向量,用于引导生成过程。扩散Transformer作为速度预测器,根据带噪潜在变量与文本嵌入估计潜在变量的速度。
参考框架图  以理解整体架构。模型运行于流匹配框架中,统一了去噪扩散过程。训练阶段,从标准正态分布中采样带噪潜在变量 x0,并从数据集中获取干净潜在变量 x1。通过在随机采样的时间步 t 上对 x0 与 x1 进行线性插值,生成中间潜在变量 xt,其定义如下:
以理解整体架构。模型运行于流匹配框架中,统一了去噪扩散过程。训练阶段,从标准正态分布中采样带噪潜在变量 x0,并从数据集中获取干净潜在变量 x1。通过在随机采样的时间步 t 上对 x0 与 x1 进行线性插值,生成中间潜在变量 xt,其定义如下:
真实速度 vt(即插值路径的导数)计算如下:
vt=dtdxt=x1−x0.训练目标是最小化DiT模型预测速度 u 与真实速度 vt 之间的均方误差(MSE),损失函数为:
L=Ex0,x1,ctxt,tu(xt,ctxt,t)−vt2,其中 ctxt 表示文本嵌入。
训练策略采用在合成图像与视频数据(即TransPhy3D)上联合训练,以提升效率并降低渲染计算负担。如图所示,流程首先使用以下公式为当前批次的视频采样帧数 F:
F=4N+1N∼U(0,5).
若 F=1,则从图像与视频数据集中采样成对数据,其中视频仅含单帧;否则仅从视频数据集中采样。随后,将每对中的深度视频转换为视差图。RGB与深度视频均归一化至 [−1,1] 范围,以匹配VAE的训练空间。归一化后的视频由VAE编码为各自潜在变量:x1c(RGB)与 x1d(深度)。深度潜在变量 x1d 通过与干净潜在变量相同的插值方案转换为中间潜在变量 xtd。DiT块的输入由 xtd 与 x1c 沿通道维度拼接而成。训练损失计算为DiT输出与真实速度 vtd(由深度潜在变量推导)之间的MSE:
L=Ex0,x1d,x1c,ctxt,tu(Concat(xtd,x1c),ctxt,t)−vtd2.训练过程中,VAE与文本编码器等所有模型组件均保持冻结。仅在DiT块中训练一小部分通过LoRA实现的低秩权重适配,以实现高效微调。
实验
- 在合成数据集(HISS、DREDS、ClearGrasp、TransPhy3D)与真实数据集ClearPose上训练,使用AdamW优化器,学习率1e-5,批量大小8,共70K次迭代,部署于8张H100 GPU;推理阶段采用5步去噪与重叠片段拼接,支持任意长度视频处理。
- 在ClearPose与TransPhy3D-Test数据集上,DKT达到全新SOTA性能,相较第二优方法在ClearPose上δ₁.₀₅、δ₁.₁₀、δ₁.₂₅分别提升5.69、9.13、3.1,在TransPhy3D-Test上分别提升55.25、40.53、9.97,充分展现对透明与反射物体的卓越估计精度。
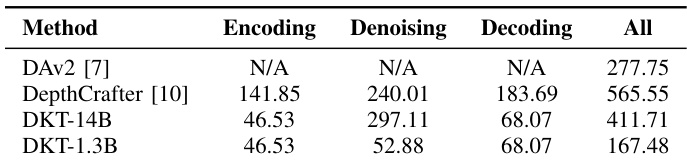
- DKT-1.3B在832×480分辨率下推理速度达167.48ms/帧,优于DAv2-Large的277.75ms,仅需11.19 GB峰值GPU内存,展现出适用于机器人平台的高效率。
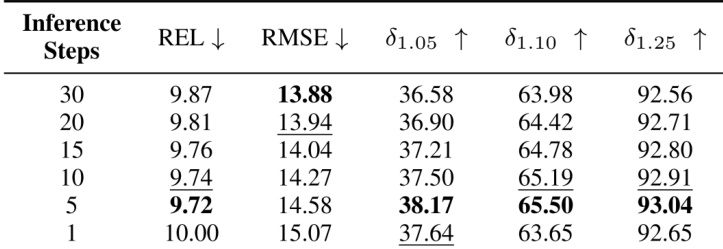
- 消融实验表明,LoRA微调优于朴素微调,5步推理在精度与效率间取得最佳平衡,进一步增加步数无显著提升。
- DKT-Normal-14B在ClearPose视频法向估计任务中创下新SOTA,显著优于NormalCrafter与Marigold-E2E-FT,在精度与时间一致性上均表现更优。
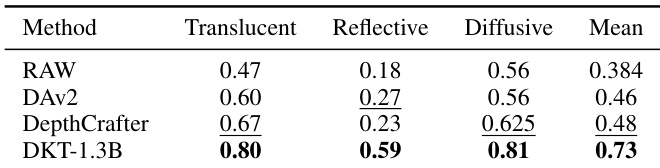
- 在反射、半透明与漫反射表面的真实抓取实验中,DKT-1.3B在所有设置下均持续优于基线模型(DAv2-Large、DepthCrafter),成功实现复杂场景下的机器人操作。
结果表明,增加推理步数可提升性能,但存在上限,5步达到最佳平衡——实现最低REL与RMSE,以及最高δ1.05、δ1.10与δ1.25得分。超过5步后性能下降,表明边际收益递减且可能损失细节。
作者采用LoRA微调策略提升模型性能,结果显示14B模型在所有指标上均表现最佳,REL与RMSE更低,δ1.05、δ1.10、δ1.25准确率高于1.3B模型。LoRA的引入显著降低计算成本,同时提升深度估计精度。

作者对比了不同深度估计模型的计算效率,结果显示DKT-1.3B在832×480分辨率下实现最快推理速度167.48ms/帧,较DAv2-Large快110.27ms。该效率仅需11.19 GB峰值GPU内存,适用于实时机器人应用。
结果表明,DKT在ClearPose与TransPhy3D-Test数据集上均取得最佳性能,多数指标超越所有基线方法。在ClearPose上,DKT实现最低REL与RMSE,所有误差指标排名第一;在TransPhy3D-Test上,其在REL、RMSE及所有δ指标上均最优,充分展现深度估计的卓越精度与一致性。

结果表明,DKT-1.3B在半透明、反射与漫反射三类物体中均取得最高性能,得分分别为0.80、0.59、0.81,显著优于RAW、DAv2与DepthCrafter。模型还取得0.73的平均得分,表明整体深度估计精度更优。