Command Palette
Search for a command to run...
端到端的测试时训练用于长上下文
端到端的测试时训练用于长上下文
摘要
我们将长上下文语言建模问题重新定义为持续学习(continual learning)问题,而非依赖架构设计。在此框架下,我们仅采用标准架构——带有滑动窗口注意力机制的Transformer。然而,我们的模型在测试阶段通过基于给定上下文的下一个词预测实现持续学习,将所读取的上下文信息压缩至模型权重中。此外,我们通过在训练阶段引入元学习(meta-learning)优化模型初始化,从而提升其在测试阶段的学习能力。总体而言,我们的方法——一种测试时训练(Test-Time Training, TTT)的形式——在训练阶段(通过元学习)和测试阶段(通过下一个词预测)均实现端到端(End-to-End, E2E)学习,这与以往方法形成鲜明对比。我们开展了大量实验,重点关注模型的扩展特性。特别地,对于使用1640亿个标记(tokens)训练的30亿参数(3B)模型,我们的方法(TTT-E2E)在上下文长度扩展时的表现与采用全注意力机制(full attention)的Transformer一致;而其他方法如Mamba 2和Gated DeltaNet则不具备这一扩展特性。然而,与循环神经网络(RNN)类似,TTT-E2E的推理延迟保持恒定,不随上下文长度增加而增长。在128K上下文长度下,其推理速度比全注意力机制快2.7倍。相关代码已公开。
一句话总结
来自Astera Institute、NVIDIA、斯坦福大学、加州大学伯克利分校和加州大学圣地亚哥分校的作者提出了TTT-E2E,这是一种测试时训练方法,使具有滑动窗口注意力的标准Transformer能够通过持续的下一个词预测和元学习初始化,有效扩展至长上下文,实现全注意力性能的同时保持恒定延迟——在128K上下文下比全注意力快2.7倍,同时维持端到端训练与推理。
主要贡献
- 本文将长上下文语言建模重新定义为持续学习问题,采用标准Transformer结合滑动窗口注意力机制,并通过下一个词预测在测试时持续学习,从而将上下文压缩到模型权重中,无需架构改动。
- 提出一种新颖的端到端测试时训练(TTT)方法,在训练阶段使用元学习优化模型初始化,以实现高效的测试时适应,确保模型在新上下文中通过动态更新持续提升性能。
- 实验表明,TTT-E2E在上下文长度增加时,性能扩展与全注意力Transformer相当,同时保持恒定的推理延迟——在128K上下文下推理速度比全注意力快2.7倍,优于Mamba 2和Gated DeltaNet等替代方案。
引言
作者针对高效长上下文语言建模的挑战展开研究:传统Transformer因全自注意力机制导致计算成本呈二次增长,而基于RNN的替代方案如Mamba在长序列上性能下降。先前方法如滑动窗口或混合架构虽带来有限提升,但无法达到全注意力的有效性。核心洞察在于,人类能将海量经验压缩为可用直觉——由此启发一种模型在测试时通过下一个词预测持续适应的方法,实质上将上下文压缩为学习到的权重。作者提出端到端测试时训练(TTT)结合元学习:模型在训练阶段被初始化为在短时间测试时适应后表现最优,采用双层优化框架,外层优化初始化以最小化内层TTT后的损失。该方法在不依赖记忆或架构变更的前提下,实现了恒定的每标记成本,展现出TTT作为语言模型中持续学习通用机制的潜力。
方法
作者以带有滑动窗口注意力的Transformer架构作为方法基础,将其视为一种在训练和测试阶段均端到端(E2E)的测试时训练(TTT)形式。核心思想是通过在给定上下文中执行下一个词预测,使模型在测试时持续学习,从而将上下文压缩到其权重中。该过程通过两阶段优化实现:外层优化训练初始模型权重,使其适合测试时适应;内层优化在推理过程中对模型参数进行梯度更新。
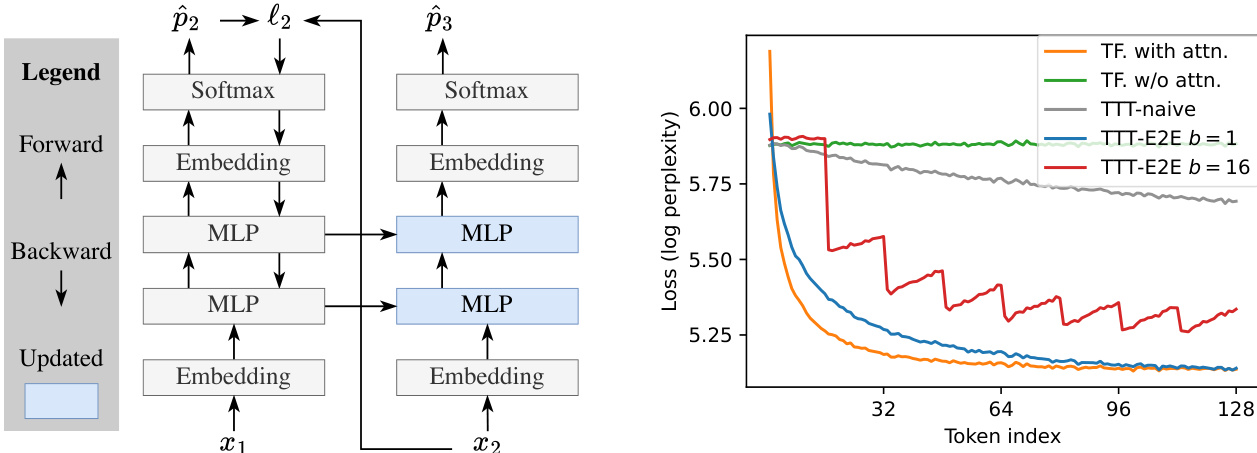
框架图展示了整体流程。模型按顺序处理输入标记,每个标记依次通过网络各层。关键创新在于反向传播过程:在每个标记处的损失梯度用于更新模型权重。该更新以小批量方式进行,模型处理一批标记后执行一次梯度步长更新权重,随后使用更新后的权重处理下一批标记,使模型逐步融入已见上下文。模型架构包含滑动窗口注意力机制,将注意力限制在固定窗口大小内,从而在保持局部上下文的同时,通过测试时训练过程学习长距离依赖。
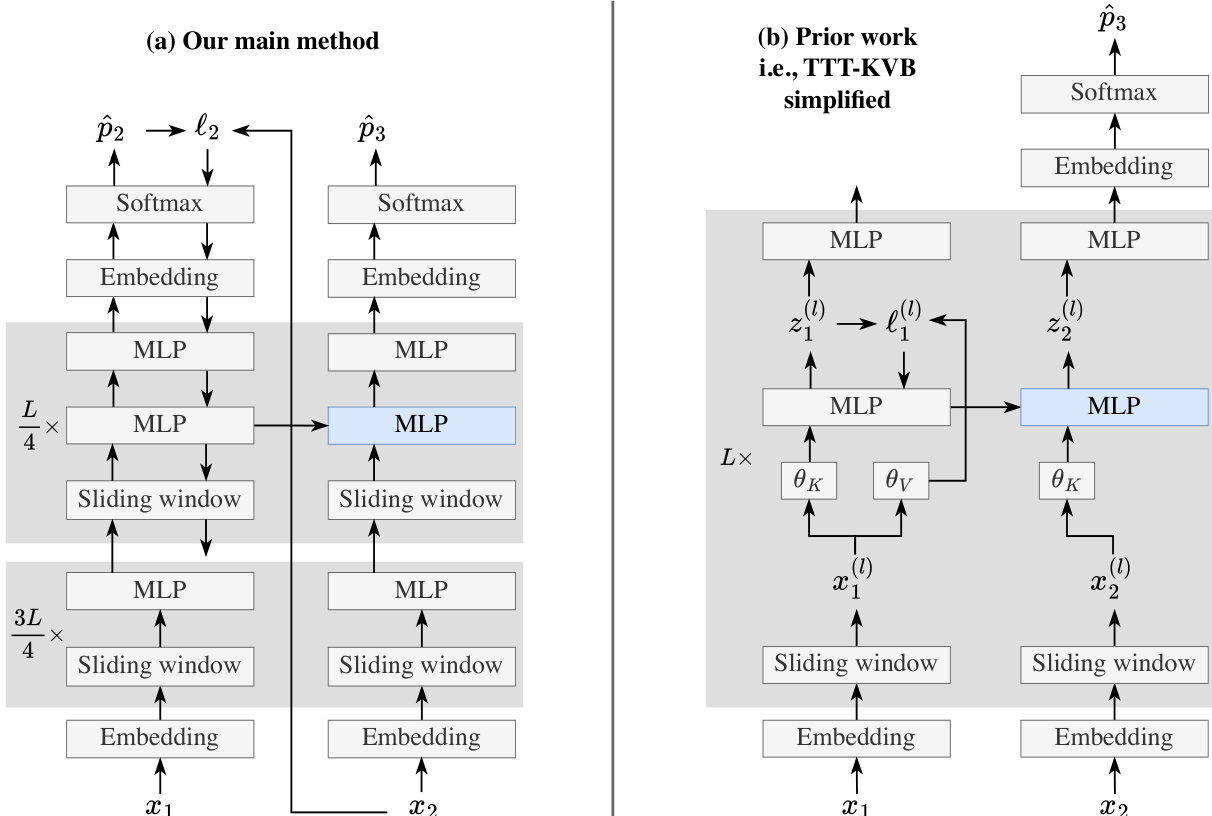
对比图突出了作者主要方法与先前工作(特别是TTT-KVB)的差异。主方法(a)采用标准Transformer架构与滑动窗口注意力,仅在测试时训练中更新模型层的子集(具体为最后四分之一层)。相比之下,先前工作(b)采用更复杂的架构,包含多个TTT层,每层具有独立参数和重建损失。主方法通过在网络末端使用单一下一个词预测损失简化了这一设计,实现测试时端到端。该简化使训练过程更高效稳定,因梯度仅回传至更新层,降低了计算成本与梯度爆炸风险。作者还指出,该方法可视为单层RNN,其中模型权重充当长期记忆,滑动窗口充当短期记忆。
实验
- 主实验:在测试时训练下对TTT-E2E进行下一个词预测评估,对比其预填充与解码效率与基线方法。
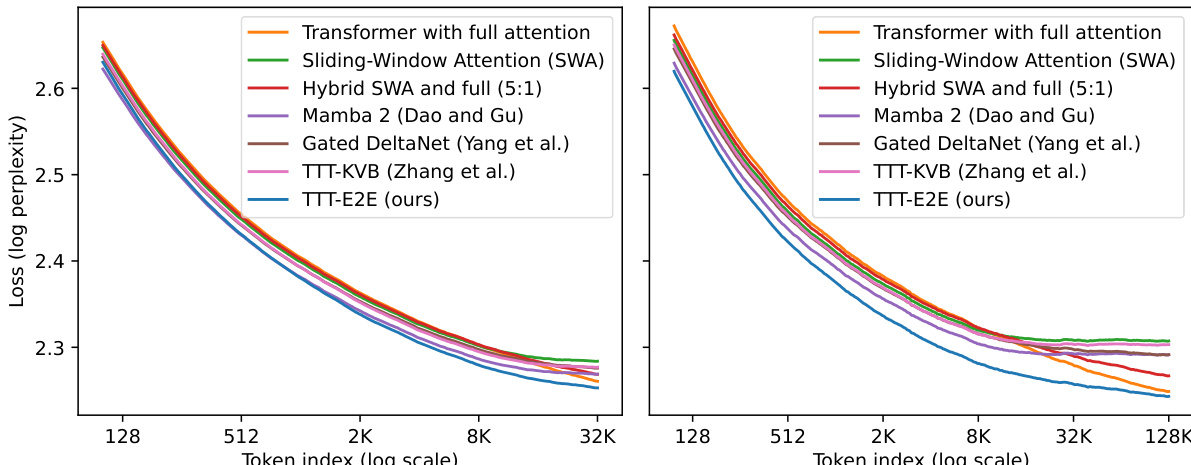
- 验证:TTT-E2E在所有上下文长度下测试损失均低于全注意力,尤其在早期标记上表现更优,尽管仅使用四分之一层和滑动窗口注意力。
- 核心结果:在128K上下文长度的Books数据集上,TTT-E2E损失为2.67,优于全注意力(2.70)及其他基线;在3B模型上,TTT-E2E在长达128K的上下文长度下持续优于全注意力。
- 消融实验确认最优超参数:滑动窗口大小 k=8K,小批量大小 b=1K,更新四分之一层。
- TTT-E2E在大训练预算下表现与全注意力相似,性能在48B训练标记后与全注意力持平。
- 解码评估显示,TTT-E2E在长序列生成过程中保持低于全注意力的损失,生成文本合理。
- 计算效率:TTT-E2E具有 O(T) 预填充延迟和 O(1) 解码延迟,硬件利用率优于先前RNN方法,但训练延迟仍是瓶颈,因涉及梯度的梯度计算。
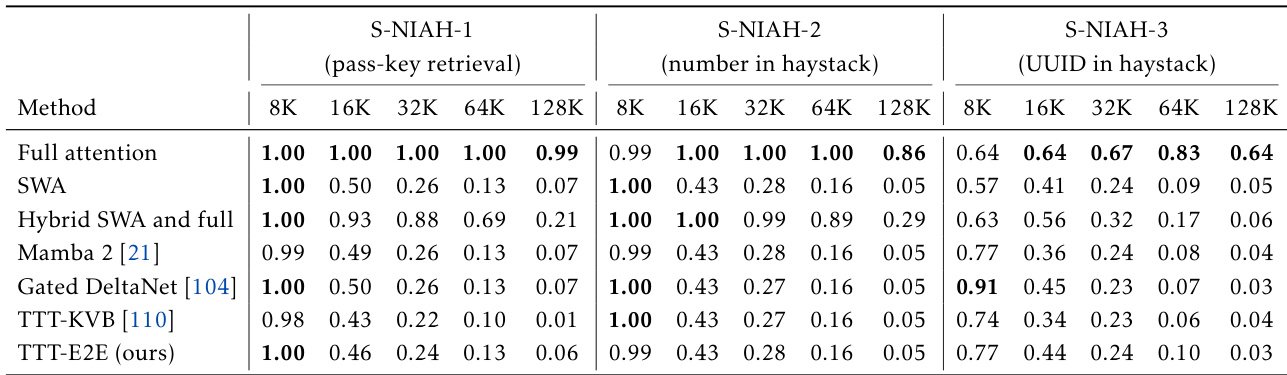
作者采用“针在 haystack”(NIAH)评估来检验模型从长上下文中检索特定信息的能力。结果表明,全注意力显著优于所有其他方法,包括提出的TTT-E2E,尤其在长上下文中表现突出,说明全注意力的优势在于近乎无损的召回能力。
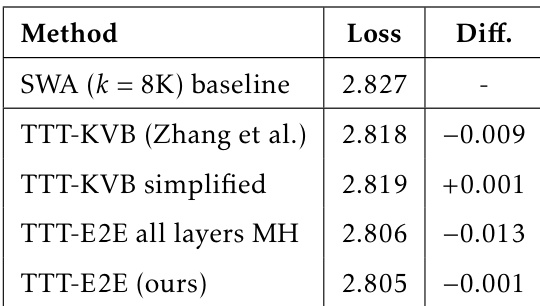
作者使用表格比较多种方法在语言建模任务上的表现,损失值反映模型准确性。结果显示,TTT-E2E(本文方法)在所列方法中损失最低,优于SWA基线及其他TTT变体,损失为2.805,较基线低-0.001。
作者在五个模型规模(从125M到2.7B参数)上采用一致的基础训练方案,模型配置与预训练超参数源自GPT-3和Mamba 2。预训练方案使用固定批量大小0.5M标记,学习率随模型规模变化;微调方案则采用更大批量大小,并在所有模型和上下文长度下使用固定学习率4e-4。
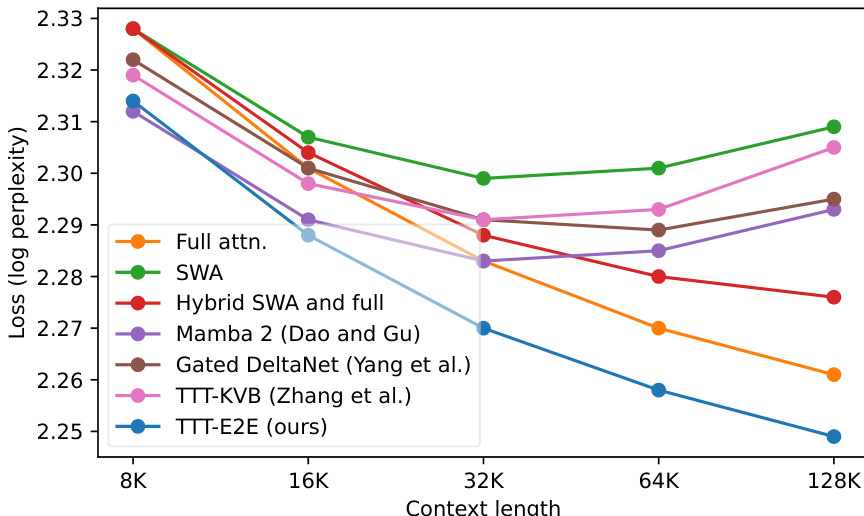
结果表明,TTT-E2E在所有上下文长度下损失均低于全注意力,优势在短上下文中最为显著。尽管全注意力在最长上下文长度上略有优势,TTT-E2E始终优于所有其他基线,包括Mamba 2和Gated DeltaNet,尤其在8K至32K范围内表现突出。
作者通过按标记索引划分损失来分析不同上下文长度下的模型性能。结果显示,TTT-E2E在所有标记位置均持续低于全注意力损失,优势主要来自上下文早期标记。这表明,即使在全注意力通常占优的长上下文场景中,TTT-E2E仍保持性能优势。