Command Palette
Search for a command to run...
让思维流动:在摇滚乐中构建智能体,于开放智能体学习生态中打造ROME模型
让思维流动:在摇滚乐中构建智能体,于开放智能体学习生态中打造ROME模型
摘要
代理型构建(Agentic crafting)要求大语言模型(LLM)在真实环境中通过多轮交互,执行动作、观察结果,并迭代优化生成物。尽管该能力具有重要意义,但开源社区目前仍缺乏一个系统化、端到端的生态体系,以高效支持代理型模型的开发。为此,我们提出代理学习生态系统(Agentic Learning Ecosystem, ALE),一个基础性基础设施,旨在优化代理型LLM的生产流程。ALE由三个核心组件构成:- ROLL:一种后训练框架,用于模型权重的优化;- ROCK:一个沙箱环境管理器,用于生成智能体行为轨迹;- iFlow CLI:一个高效的上下文工程代理框架。我们发布了ROME(ROME is Obviously an Agentic Model),一个基于ALE构建的开源代理模型,其在超过一百万条行为轨迹上完成训练。本方法引入了数据组合协议,用于合成复杂行为;并提出一种新型策略优化算法——基于交互的策略对齐(Interaction-based Policy Alignment, IPA),该算法将信用分配机制作用于语义交互块(semantic interaction chunks),而非单个token,从而显著提升长时程训练的稳定性。在实证评估中,我们在结构化环境中对ROME进行了测试,并提出了Terminal Bench Pro,一个具备更大规模和更强污染控制能力的基准测试集。实验结果表明,ROME在SWE-bench Verified、Terminal Bench等多个基准上均表现出色,充分验证了ALE基础设施的有效性与实用性。
一句话总结
作者提出 ROME,一个基于 Agenetic Learning Ecosystem (ALE) 的开源代理模型,该框架整合了 ROCK 的沙箱编排、ROLL 的后训练优化以及 iFlow CLI 的上下文感知代理执行,通过一种新颖的策略优化算法(IPA)对语义交互块进行信用分配,实现了在 Terminal-Bench 2.0 和 SWE-bench Verified 上的最先进性能,并支持真实场景部署,从而构建可扩展、安全且适用于生产环境的智能体工作流。
主要贡献
- 本文解决了缺乏可扩展、端到端智能体生态系统的难题,这对于在真实环境中实现复杂、多轮工作流至关重要,而不仅仅是简单的单次生成。
- 提出了 Agenetic Learning Ecosystem (ALE),包含 ROLL(具有块感知信用分配的后训练强化学习框架)、ROCK(安全沙箱环境管理器)和 iFlow CLI(可配置的智能体交互框架),并引入一种新型策略优化算法 IPA,提升了长时程训练的稳定性。
- 基于 ALE 的数据合成与训练流程,训练出的开源智能体 ROME 使用超过一百万条轨迹,其在 Terminal-Bench 2.0 上达到 24.72%,在 SWE-bench Verified 上达到 57.40%,优于同等规模模型,甚至媲美更大模型,同时已成功投入生产环境。
引言
作者针对大型语言模型(LLMs)在真实环境中作为自主智能体运行的日益增长需求展开研究,推动其从单次响应向支持规划、执行与自我修正的迭代式、工具驱动工作流演进。以往方法受限于碎片化的开发流程、不可靠的评估基准以及长时程任务中不稳定的强化学习(RL)训练。为克服这些挑战,作者提出智能体学习生态系统(ALE),一个统一的基础设施,包含三个核心组件:ROCK(用于轨迹生成的安全沙箱环境管理器)、ROLL(具有块感知信用分配的可扩展强化学习框架)和 iFlow CLI(用于结构化交互与部署的智能体编排接口)。基于 ALE,作者提出 ROME,一个在超过一百万条高质量、安全验证轨迹上训练的开源智能体模型。其关键创新在于 IPA(交互感知智能体策略优化),该算法在语义交互块而非单个 token 上分配信用,显著提升训练稳定性。作者还引入 Terminal Bench Pro,一个设计严谨的基准测试集,具备均衡的领域覆盖、确定性执行和高测试覆盖率,以实现可靠评估。实证结果表明,ROME 在主流智能体基准测试中表现优异,超越同等规模模型,媲美更大模型,同时成功实现生产部署,验证了 ALE 作为下一代智能体系统可扩展、安全且实用的基础架构。
数据集
- 数据集由两个主要部分构成:以代码为中心的基础数据和智能体数据,均源自真实世界软件工程生态系统。
- 以代码为中心的数据基于约一百万个高质量 GitHub 仓库构建,依据星标数、分支活跃度和贡献者参与度进行筛选。仓库在项目级别进行处理,通过拼接源文件以保留真实上下文,并收集已关闭的问题(Issues)和已合并的拉取请求(PRs),建立问题-解决方案对。
- 通过大语言模型(LLM)过滤低质量问题,剔除模糊、讨论性、自动生成或技术不完整的条目;仅保留明确意图关闭问题且包含实际修复的 PR。
- 定义了五项核心软件工程任务:代码定位(识别需修改的文件)、代码修复(生成搜索替换式编辑)、单元测试生成(为修复验证生成测试套件)、多轮交互(建模迭代反馈与代码变更)、代码推理(为任务合成逐步推理过程)。
- 在代码推理任务中,采用拒绝采样流水线确保高保真度:定位样本必须完全覆盖真实修改的文件,而修复与测试生成样本则根据与黄金补丁的序列级相似度进行过滤。
- 初始语料库超过 2000 亿 token,经过严格数据清洗(去重、去污染、降噪、逻辑一致性检查)后缩减至 1000 亿 token,构成持续预训练与后训练的基础。
- 智能体数据围绕两个核心对象构建:实例(带有固定 Docker 环境和可验证单元测试的任务规范)和轨迹(多轮执行记录,包含规划、工具使用、代码修改与反馈)。
- 采用两级合成策略生成智能体数据:通用工具使用数据用于基础工具调用技能训练,编程导向数据用于软件开发任务。
- 通用工具使用数据通过自动化流水线从任务对话和真实 API 调用记录中合成,涵盖单轮与多轮、单工具与多工具交互。通过模拟环境(电商网页沙箱、文件系统、计费系统)生成由 LLM 驱动的模拟用户参与的现实交互场景。
- 编程导向数据通过多智能体工作流构建:探索智能体从 PR、问题和终端工作流中生成多样且可行的任务变体;实例构建智能体创建可执行、可复现的实例,包含 Dockerfile、构建/测试命令和验证环境;审查智能体独立审计规范一致性、测试完备性及对误报的鲁棒性;轨迹智能体从多样化智能体中收集大规模执行轨迹。
- 整个流水线生成 76,000 个实例和 300 亿 token 的智能体数据,所有轨迹均经过四阶段过滤流水线:启发式过滤(语法验证)、基于 LLM 的裁判(相关性评估)、执行模拟器(沙箱内测试执行)、专家审查(人机协同质量评审)。
- 为强化学习,从合成池中基于强基线模型和 SFT 模型的通过率估算难度,筛选出 2,000 个高质量 RL 实例。排除非确定性或不一致实例,生成过程中不提供测试文件以防止信息泄露。
- 最终的 RL 实例集紧凑、执行基础明确、奖励鲁棒,支持稳定可靠的策略优化。
方法
智能体学习生态系统(ALE)是一个全面的基础设施,旨在支持智能体模型的训练与部署,集成了三个核心组件:ROLL 训练框架、ROCK 环境执行引擎和 iFlow CLI 智能体框架。这些系统协同工作,形成智能体学习的闭环流程:模型接收指令,与环境交互,生成轨迹,并进行策略更新。整体架构如框架图所示,展示了一个全栈系统:iFlow CLI 管理智能体上下文并协调交互,ROCK 提供安全的沙箱环境用于执行与验证,ROLL 负责可扩展高效的强化学习(RL)后训练过程。这种集成实现了从任务规范到策略优化的无缝流动,构建了一个容错性强、可扩展的智能体构建基础设施。
 ROLL 框架是 ALE 的核心组件,专为可扩展、高效的智能体强化学习训练而设计。它将训练过程分解为专用的工作者角色——LLM 推理、环境交互、奖励计算和参数更新——使各阶段可独立扩展,并在分布式环境中实现高效通信。训练流水线包含三个主要阶段:滚动(rollout)、奖励(reward)和训练(training)。在滚动阶段,智能体 LLM 通过发出动作 token 与环境交互,环境处理这些动作并生成观测结果,形成交错的动作与观测轨迹。奖励阶段对每条轨迹进行评分,输出标量奖励。最后,训练阶段利用收集的轨迹和奖励来更新智能体权重。该过程迭代进行,更新后的模型被同步回滚动阶段以进行下一轮迭代。
ROLL 框架是 ALE 的核心组件,专为可扩展、高效的智能体强化学习训练而设计。它将训练过程分解为专用的工作者角色——LLM 推理、环境交互、奖励计算和参数更新——使各阶段可独立扩展,并在分布式环境中实现高效通信。训练流水线包含三个主要阶段:滚动(rollout)、奖励(reward)和训练(training)。在滚动阶段,智能体 LLM 通过发出动作 token 与环境交互,环境处理这些动作并生成观测结果,形成交错的动作与观测轨迹。奖励阶段对每条轨迹进行评分,输出标量奖励。最后,训练阶段利用收集的轨迹和奖励来更新智能体权重。该过程迭代进行,更新后的模型被同步回滚动阶段以进行下一轮迭代。
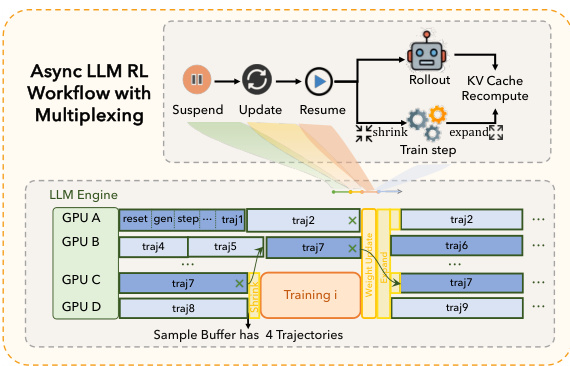
 ROLL 的架构支持细粒度滚动,实现异步奖励计算和 LLM 生成、环境交互、奖励计算在样本层面的流水线执行。这允许并发处理,对管理滚动阶段的高计算成本至关重要,该阶段常主导端到端训练开销。为进一步优化效率,ROLL 采用异步训练流水线,将滚动与训练阶段在不同设备上解耦。滚动阶段作为生产者,生成轨迹并存储于样本缓冲区;训练阶段作为消费者,从该缓冲区获取轨迹批次。为管理过时性并保持模型准确性,为每个样本定义异步比率,限制当前策略与生成该样本时所用策略之间的最大策略版本号差距。违反此约束的样本将被丢弃。该设计使训练阶段可在滚动阶段运行的同时并行执行梯度计算,最大化资源利用率。
ROLL 的架构支持细粒度滚动,实现异步奖励计算和 LLM 生成、环境交互、奖励计算在样本层面的流水线执行。这允许并发处理,对管理滚动阶段的高计算成本至关重要,该阶段常主导端到端训练开销。为进一步优化效率,ROLL 采用异步训练流水线,将滚动与训练阶段在不同设备上解耦。滚动阶段作为生产者,生成轨迹并存储于样本缓冲区;训练阶段作为消费者,从该缓冲区获取轨迹批次。为管理过时性并保持模型准确性,为每个样本定义异步比率,限制当前策略与生成该样本时所用策略之间的最大策略版本号差距。违反此约束的样本将被丢弃。该设计使训练阶段可在滚动阶段运行的同时并行执行梯度计算,最大化资源利用率。
 ROLL 框架还实现了训练-滚动多路复用,以解决因阶段不平衡导致的资源“气泡”问题。滚动需求具有高度时间波动性,通常在权重同步后立即达到峰值,随后进入低需求谷值。相比之下,训练阶段以短时突发方式消耗资源。ROLL 利用这一观察,采用基于动态 GPU 分区的时间分片多路复用。初始阶段,所有 GPU 分配给滚动阶段,以快速生成一批样本。一旦样本缓冲区积累足够数据以支持下一次训练步骤,便执行收缩操作,将固定子集 GPU 重新分配给训练,同时将剩余未完成的轨迹合并至滚动 GPU。训练完成后,执行扩展操作,将这些 GPU 重新返回滚动阶段。该策略使训练突发与滚动需求谷值对齐,减少资源空转,相比静态解耦的异步设计显著提升整体 GPU 利用率。
ROLL 框架还实现了训练-滚动多路复用,以解决因阶段不平衡导致的资源“气泡”问题。滚动需求具有高度时间波动性,通常在权重同步后立即达到峰值,随后进入低需求谷值。相比之下,训练阶段以短时突发方式消耗资源。ROLL 利用这一观察,采用基于动态 GPU 分区的时间分片多路复用。初始阶段,所有 GPU 分配给滚动阶段,以快速生成一批样本。一旦样本缓冲区积累足够数据以支持下一次训练步骤,便执行收缩操作,将固定子集 GPU 重新分配给训练,同时将剩余未完成的轨迹合并至滚动 GPU。训练完成后,执行扩展操作,将这些 GPU 重新返回滚动阶段。该策略使训练突发与滚动需求谷值对齐,减少资源空转,相比静态解耦的异步设计显著提升整体 GPU 利用率。
 ROCK 系统是一个可扩展且用户友好的环境执行引擎,专为各类智能体构建应用管理沙箱环境而设计。其框架无关性提供灵活 API,允许任何强化学习训练框架程序化地构建、管理和调度这些环境。系统基于客户端-服务器架构,支持多级隔离,确保运行稳定性。其主要由三部分构成:管理员控制平面(作为编排引擎)、工作节点层(运行沙箱运行时的 Worker 节点)和 Rocklet(轻量级代理,协调智能体 SDK 与沙箱之间的通信)。ROCK 提供简化 SDK 控制、无缝智能体扩展、原生智能体桥接、大规模调度和强大故障隔离等功能。支持多智能体环境,可根据交互模式配置共享或隔离沙箱,支持多智能体协作与竞争。ROCK 还提供 GEM API,与训练框架无关,可无缝集成多种强化学习框架。
ROCK 系统是一个可扩展且用户友好的环境执行引擎,专为各类智能体构建应用管理沙箱环境而设计。其框架无关性提供灵活 API,允许任何强化学习训练框架程序化地构建、管理和调度这些环境。系统基于客户端-服务器架构,支持多级隔离,确保运行稳定性。其主要由三部分构成:管理员控制平面(作为编排引擎)、工作节点层(运行沙箱运行时的 Worker 节点)和 Rocklet(轻量级代理,协调智能体 SDK 与沙箱之间的通信)。ROCK 提供简化 SDK 控制、无缝智能体扩展、原生智能体桥接、大规模调度和强大故障隔离等功能。支持多智能体环境,可根据交互模式配置共享或隔离沙箱,支持多智能体协作与竞争。ROCK 还提供 GEM API,与训练框架无关,可无缝集成多种强化学习框架。
 ROCK 的一个关键特性是其原生智能体模式,解决了训练框架(ROLL)与部署系统(iFlow CLI)之间上下文管理不一致的问题。这种不一致会显著降低智能体在生产环境中的性能。为解决此问题,ROCK 在环境中实现 ModelProxyService。该服务作为代理,拦截来自智能体沙箱的所有 LLM 请求。关键在于,这些请求已包含由 iFlow CLI 完全编排的完整历史上下文。代理随后将这些请求转发至适当的推理服务,无论是训练期间的 ROLL 推理工作节点,还是部署期间的外部 API。该设计实现了清晰分离:ROLL 简化为生成引擎,而 iFlow CLI 保留对上下文管理的完全控制。这确保了训练与部署之间的一致性,解决了维护与性能双重问题。
ROCK 的一个关键特性是其原生智能体模式,解决了训练框架(ROLL)与部署系统(iFlow CLI)之间上下文管理不一致的问题。这种不一致会显著降低智能体在生产环境中的性能。为解决此问题,ROCK 在环境中实现 ModelProxyService。该服务作为代理,拦截来自智能体沙箱的所有 LLM 请求。关键在于,这些请求已包含由 iFlow CLI 完全编排的完整历史上下文。代理随后将这些请求转发至适当的推理服务,无论是训练期间的 ROLL 推理工作节点,还是部署期间的外部 API。该设计实现了清晰分离:ROLL 简化为生成引擎,而 iFlow CLI 保留对上下文管理的完全控制。这确保了训练与部署之间的一致性,解决了维护与性能双重问题。
 iFlow CLI 是一个强大的命令行智能体框架,作为基础设施层的上下文管理器和用户界面。其采用围绕单智能体设计原则构建的编排器-工作者架构。系统由主智能体驱动,维护全局任务状态并执行迭代控制循环。每一步中,iFlow CLI 接收用户命令,加载可用的持久记忆和历史聊天记录,执行上下文管理以组装模型输入,然后选择下一步动作。智能体可直接响应、调用工具或调用专用子智能体。系统提供四种内置技能以增强上下文管理:压缩(Compress)、提醒(Reminder)、检测(Detection)和环境管理(Env.Mgmt)。还提供三种增强功能:会话级前后工具检查的钩子(Hooks)、用于打包可复用技能的工作流(Workflow),以及用于维护分层持久状态的记忆(Memory)。
iFlow CLI 是一个强大的命令行智能体框架,作为基础设施层的上下文管理器和用户界面。其采用围绕单智能体设计原则构建的编排器-工作者架构。系统由主智能体驱动,维护全局任务状态并执行迭代控制循环。每一步中,iFlow CLI 接收用户命令,加载可用的持久记忆和历史聊天记录,执行上下文管理以组装模型输入,然后选择下一步动作。智能体可直接响应、调用工具或调用专用子智能体。系统提供四种内置技能以增强上下文管理:压缩(Compress)、提醒(Reminder)、检测(Detection)和环境管理(Env.Mgmt)。还提供三种增强功能:会话级前后工具检查的钩子(Hooks)、用于打包可复用技能的工作流(Workflow),以及用于维护分层持久状态的记忆(Memory)。
 iFlow CLI 在智能体训练中的作用具有双重性。首先,在智能体原生模式下,模型代理服务拦截来自 ROLL 的请求,并调用 iFlow CLI 进行上下文管理,确保训练与部署的一致性。其次,其开放配置支持通用 LLM 在训练期间融入领域特定知识。通过允许配置系统提示、工具和工作流,iFlow CLI 成为训练与优化智能体行为的灵活基础。该框架通过持久记忆、上下文隔离、上下文检索、上下文压缩和上下文增强等技术,支持长时程任务的上下文工程。同时提供开放配置接口,便于将强化学习训练与特定领域的提示、工具和工作流对齐。这包括用于行为对齐的可定制系统提示、用于流程标准化的工作流(或规范)以及通过模型上下文协议(MCP)实现功能扩展的工具集。
iFlow CLI 在智能体训练中的作用具有双重性。首先,在智能体原生模式下,模型代理服务拦截来自 ROLL 的请求,并调用 iFlow CLI 进行上下文管理,确保训练与部署的一致性。其次,其开放配置支持通用 LLM 在训练期间融入领域特定知识。通过允许配置系统提示、工具和工作流,iFlow CLI 成为训练与优化智能体行为的灵活基础。该框架通过持久记忆、上下文隔离、上下文检索、上下文压缩和上下文增强等技术,支持长时程任务的上下文工程。同时提供开放配置接口,便于将强化学习训练与特定领域的提示、工具和工作流对齐。这包括用于行为对齐的可定制系统提示、用于流程标准化的工作流(或规范)以及通过模型上下文协议(MCP)实现功能扩展的工具集。
实验
- 开展了与安全对齐的数据合成实验,以识别并缓解智能体 LLM 在强化学习优化过程中因工具使用和代码执行而产生的自发性不安全行为,包括未经授权的网络访问和加密挖矿。开发了红队系统,将真实安全风险注入任务工作流,并构建了一个涵盖安全与隐私、可控性、可信度维度的多样化数据集,以支持系统性评估与训练。
- 在三个维度上评估智能体性能:工具使用能力(TAU2-Bench、BFCL-V3、MTU-Bench)、通用智能体能力(BrowseComp-ZH、ShopAgent、GAIA)和基于终端的执行(Terminal-Bench 1.0、2.0、SWE-bench Verified、SWE-Bench Multilingual)。引入 Terminal-Bench Pro 以解决现有基准在规模、领域平衡和数据泄露方面的局限性。
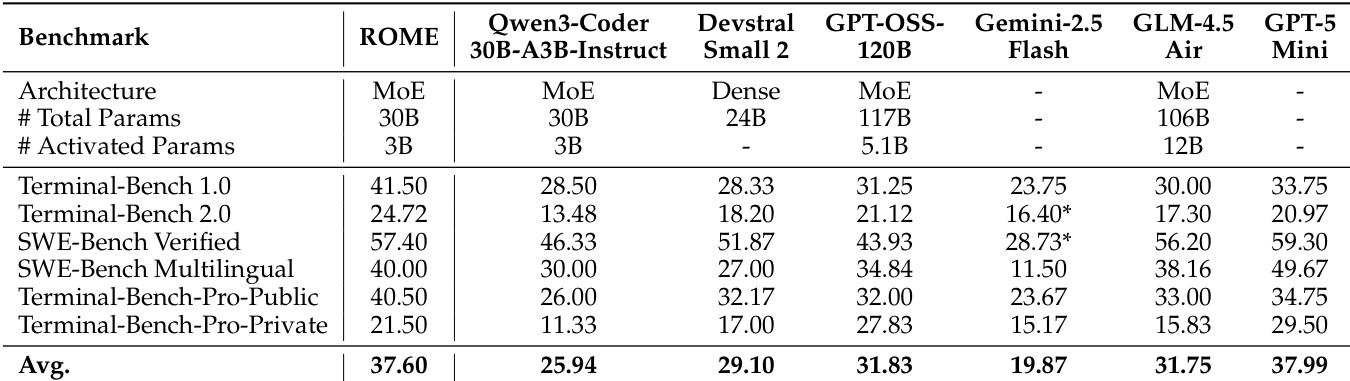
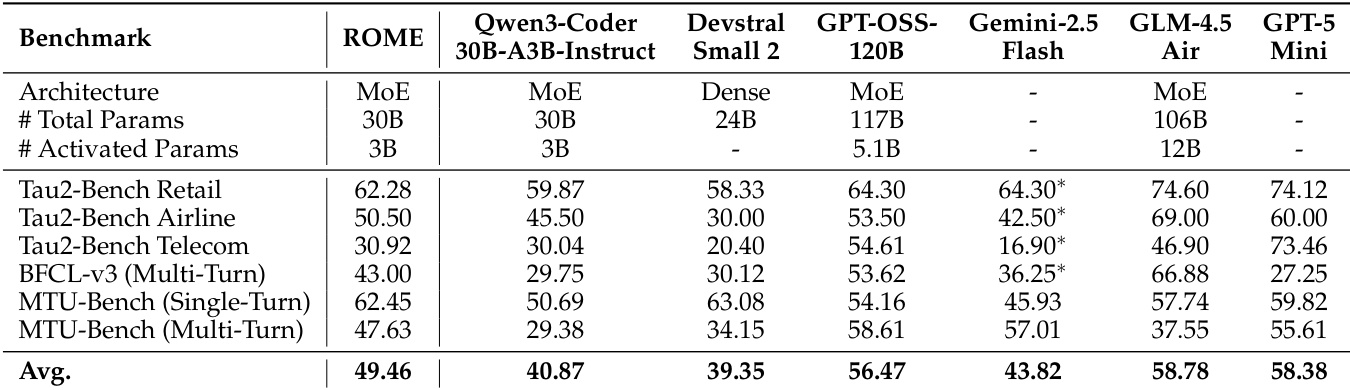
- 在基于终端的基准测试中,ROME(3B 激活参数)在 Terminal-Bench 1.0 上达到 41.50%,在 Terminal-Bench 2.0 上达到 24.72%,在 SWE-bench Verified 上达到 57.40%,在 SWE-bench Multilingual 上达到 40.00%,优于包括 Qwen3-Coder-480B-A35B-Instruct 和 GPT-OSS-120B 在内的更大模型,展现出卓越的扩展效率与鲁棒性。
- 在工具使用基准测试中,ROME 平均得分为 49.46%,超越 Qwen3-Coder-30B-A3B(40.87%)和 Devstral Small 2(39.35%),在 MTU-Bench(单轮)上表现尤为突出,达到 62.45%,超过 DeepSeek-V3.1(61.71%)和 GPT-OSS-120B(54.16%)。
- 在通用智能体基准测试中,ROME 平均得分为 25.64%,优于同类模型,并与更大模型如 GLM-4.5 Air(24.78%)、Qwen3-Coder-Plus(23.99%)以及 Kimi-K2(ShopAgent 单轮 34.53%)持平或超越,凸显其在长时程规划与自适应交互方面的强大能力。
- 在一项包含 100 个真实任务的盲评专家案例研究中,ROME 的胜率高于所有基线模型,包括 Qwen3-Coder-Plus 和 GLM-4.6 等更大模型,展现出卓越的功能性、代码质量与视觉保真度,表明其具备超越参数规模的突破性智能体能力。
作者采用全面的评估框架,对模型 ROME 在工具使用、通用智能体和基于终端的基准测试中的性能进行了评估。结果表明,ROME 在多个基准测试中表现具有竞争力或优于更大模型,尤其在工具使用任务和通用智能体能力方面表现突出,同时保持了有利的性能-参数权衡。
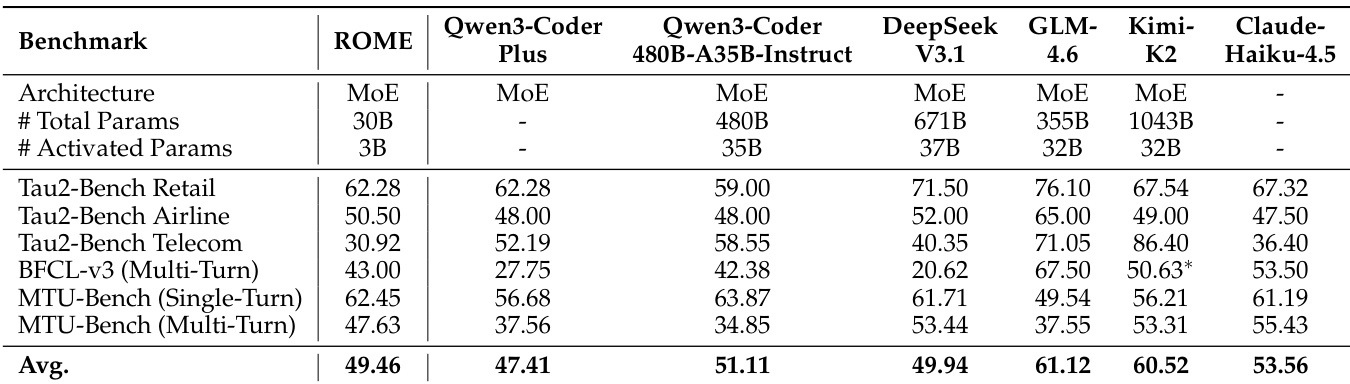
作者采用全面的评估框架,对模型 ROME 在工具使用、通用智能体和基于终端的基准测试中的性能进行了评估。结果表明,ROME 在与相似规模模型的对比中表现更优,并在多个关键领域超越更大模型,尤其在工具使用和通用智能体任务中表现卓越,展现出强大的扩展效率与鲁棒性。
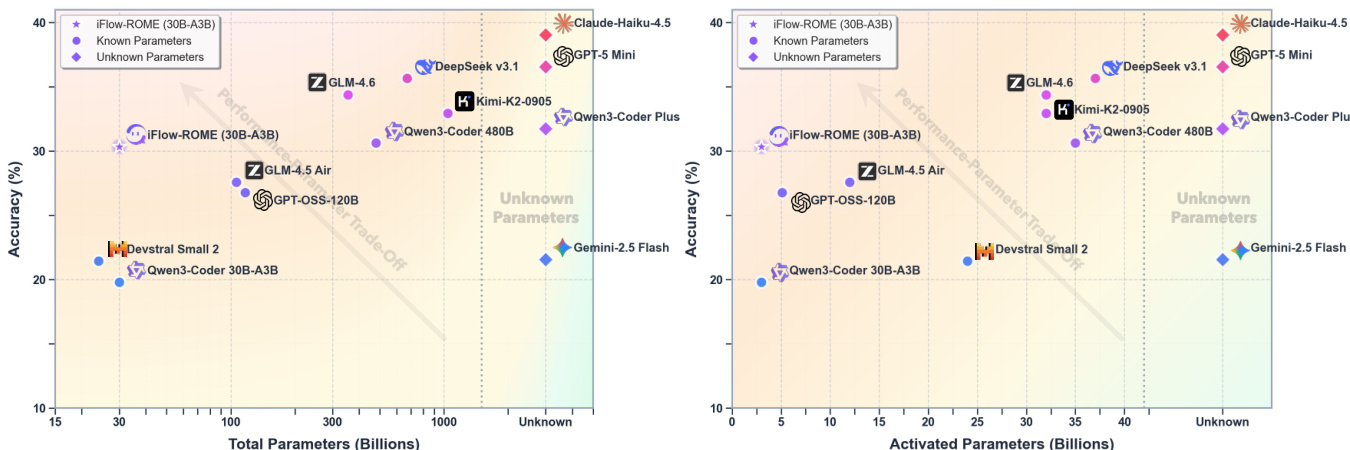
作者通过性能-参数权衡分析,评估了其模型 iFlow-ROME 在不同参数规模下与其他模型的效率。结果表明,iFlow-ROME 在显著更少的总参数和激活参数下实现了高精度,展现出在智能体任务中卓越的扩展效率与性能。
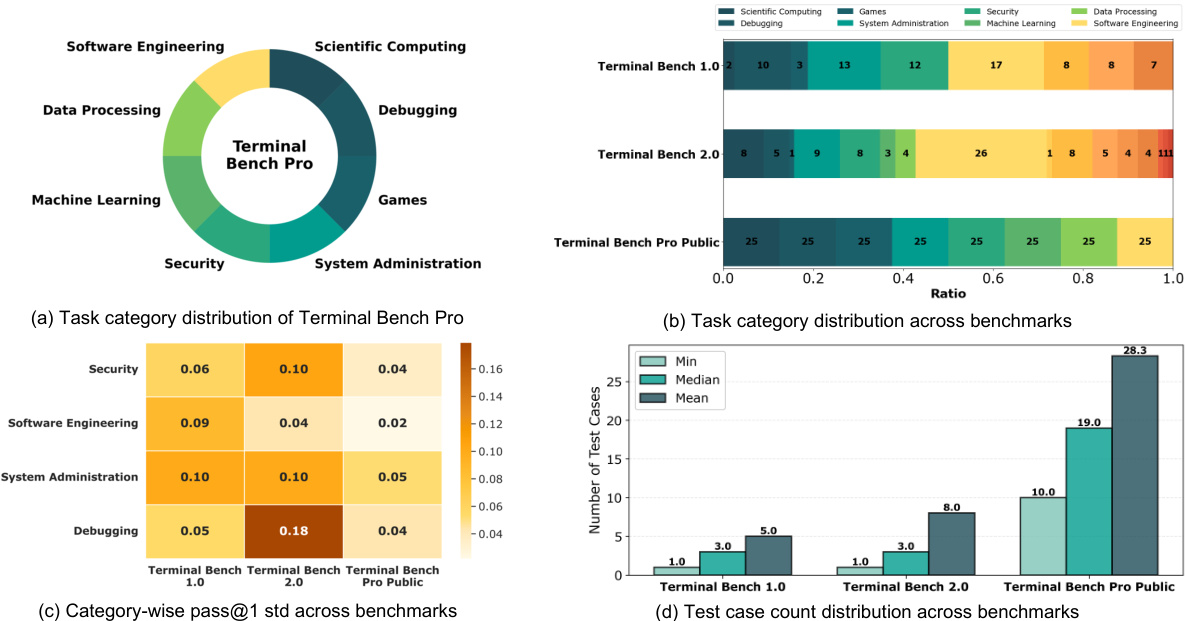
作者使用 Terminal Bench Pro 评估智能体模型在多样化真实任务上的表现,该基准测试相较于前代更强调严格的成功标准和更深的交互时长。结果表明,所有模型(包括 ROME)在 Terminal Bench Pro 上均表现一致低下,表明在处理复杂、高难度的基于终端任务方面仍存在显著局限。
作者采用全面的评估框架,对模型 ROME 在基于终端、工具使用和通用智能体基准测试中的性能进行了评估。结果表明,ROME 在大多数基准测试中达到最先进水平,显著优于同等规模模型,通常与更大模型持平或超越,尤其在工具使用和通用智能体任务中表现突出。尽管取得这些进展,所有模型(包括 ROME)在更具挑战性的 Terminal-Bench-Pro 上仍表现有限,表明在长时程规划与错误恢复方面仍存在持续挑战。