Command Palette
Search for a command to run...
GraphLocator:基于图引导的因果推理用于问题定位
GraphLocator:基于图引导的因果推理用于问题定位
Wei Liu Chao Peng Pengfei Gao Aofan Liu Wei Zhang Haiyan Zhao Zhi Jin
摘要
问题定位任务旨在根据自然语言描述的问题说明,识别软件仓库中需要修改的代码位置。该任务在自动化软件工程中具有基础性意义,但面临巨大挑战,主要源于问题描述与源代码实现之间的语义鸿沟。这一鸿沟具体表现为两种不匹配:(1)症状到原因的不匹配,即问题描述未能明确揭示其背后的根因;(2)一对多的不匹配,即单一问题可能对应多个相互依赖的代码实体。为应对上述两类不匹配,本文提出GraphLocator方法,通过挖掘因果结构来缓解症状到原因的不匹配,并借助动态问题解耦机制解决一对多的不匹配问题。该方法的核心构件是因果问题图(Causal Issue Graph, CIG),其中节点代表发现的子问题及其关联的代码实体,边则编码节点之间的因果依赖关系。GraphLocator的处理流程包含两个阶段:症状节点定位与动态CIG构建;首先在仓库图中识别出症状所在的位置,随后通过迭代推理邻近节点,动态扩展CIG结构。在三个真实世界数据集上的实验结果表明,GraphLocator具有显著有效性:(1)相较于基线方法,GraphLocator在函数级召回率上平均提升19.49%,精度提升11.89%;(2)在症状到原因及一对多不匹配场景下,GraphLocator均优于基线方法,分别实现召回率提升16.44%和19.18%,精度提升7.78%和13.23%;(3)由GraphLocator生成的CIG在下游问题修复任务中表现出最优性能,相较基线带来28.74%的相对性能提升。
一句话总结
北京大学与字节跳动提出 GraphLocator,一种基于大语言模型的方法,通过因果问题图(CIG)解决问题定位中的症状到原因错配及一对多错配问题,实现动态解耦与多跳因果推理,在函数级别召回率最高提升19.49%、精确率最高提升11.89%,同时使下游问题修复性能提升28.74%。
主要贡献
-
问题定位面临根本性挑战,源于两个关键错配:症状到原因错配,即问题描述揭示的是症状而非根本原因;一对多错配,即单个问题需在多个相互依赖的代码实体上进行修改,二者均加剧了自然语言与代码之间的语义鸿沟。
-
GraphLocator 引入因果问题图(CIG)以建模子问题及其因果依赖关系,利用在仓库依赖分形结构(RDFS)上的智能体工作流,通过迭代溯因推理动态发现并解耦复杂问题结构。
-
在三个真实世界 Python 和 Java 数据集上评估,GraphLocator 在函数级别召回率较基线提升 +19.49%,精确率提升 +11.89%,在两种错配场景下均有显著增益,并因解耦的因果结构使下游修复任务性能提升28.74%。
引言
软件工程中的问题定位任务旨在将自然语言问题描述映射到需要修改的相关代码位置,是自动化调试与维护的关键步骤。该任务具有挑战性,主要源于两个关键错配:症状到原因错配,即问题描述的是可观测症状而非根本原因,需多跳推理;一对多错配,即单个问题跨越多个相互依赖的代码实体。以往方法——基于嵌入与基于大语言模型的方法——难以应对这些错配:嵌入方法缺乏结构感知能力,而基于大语言模型的方法常依赖表面相关性,无法建模因果依赖或维持连贯的推理链。本文作者提出 GraphLocator,一种由大语言模型驱动的方法,构建因果问题图(CIG)以表示子问题及其因果关系。通过在仓库依赖分形结构(RDFS)上采用智能体工作流,GraphLocator 能够动态发现因果路径并借助迭代溯因推理解耦复杂问题。该方法可准确应对两类错配,相较基线实现最高达 +19.49% 的召回率与 +11.89% 的精确率提升,并使下游问题修复性能提升28.74%。
数据集
- 数据集包含三个公开可用的基准,涵盖 Python 和 Java,每个数据集均包含 GitHub 问题,包含问题描述、提交版本及基于 diff 的修复补丁,用于评估。
- SWE-bench Lite(Python):来自11个大型 Python 项目的300个问题,从完整 SWE-bench 数据集中选取,以平衡评估成本与质量;排除包含非文本内容(如图片或超链接)的问题。
- LocBench(Python):来自164个 Python 仓库的559个问题,涵盖多种问题类型,如缺陷报告、功能请求、安全问题与性能问题;已移除因不可访问而无法获取的仓库 NCSU-High-Powered-Rocketry-Club/AirbrakesV2 中的一个问题。
- Multi-SWE-bench(Java):来自9个开源 Java 项目的128个问题,通过严谨流程构建,包括基于星标数与可运行性的仓库筛选,随后进行双重标注与交叉评审,确保高质量、人工验证的真值。
- 真值位置通过 RDFS(仓库依赖与文件结构)在三个层级重新提取:文件级(文件路径)、模块级(所属类、枚举或接口)、函数级(包含函数/方法),确保细粒度且一致的监督。
- 模型使用这些数据集的混合进行训练与评估,训练划分来自完整问题集合,采用平衡混合比例以反映多样化的问类型与编程语言。
- 所有数据集均被处理为提取干净的文本输入与结构化元数据,使用 diff 补丁在多个粒度上定义真值位置。最终训练与评估数据中不包含图像或外部内容。
方法
作者提出一种混合式、基于大语言模型的框架 GraphLocator,用于函数级别的问题定位,该框架分为两个阶段:症状顶点定位与动态 CIG 构建。整体架构旨在通过显式建模仓库结构上下文中的因果依赖,解决症状到原因与一对多错配问题。框架首先构建仓库依赖分形结构(RDFS),这是一种异构属性图,捕捉代码实体在四个不同粒度层级上的层次与依赖关系。RDFS 作为整个流程的基础知识库。
第一阶段,GraphLocator 使用 SearchAgent(一个基于大语言模型的智能体)在 RDFS 中识别与问题描述对应的症状顶点。该智能体通过迭代调用一组图可执行搜索工具,自主定位相关代码实体。搜索工具集包括 search_vertex,支持基于名称与类型约束的顶点检索,具备通配符匹配与模糊字符串搜索能力;以及 search_edge,用于根据指定关系约束识别顶点间的边,实现依赖发现。智能体利用基于提示的语义推理对前 k 个候选结果进行筛选,确保仅保留语义最匹配的顶点。当调用 finish 工具时,该阶段结束,返回症状顶点集合至下一阶段。RDFS 通过使用 tree-sitter 解析代码库生成 AST,提取代码实体,并建立具有 HasMember 边的层次骨架。随后通过静态分析识别语义依赖(如导入与函数调用),编码为 ImportedBy、ExtendedBy 与 UsedBy 边。采用懒加载策略增量构建图结构,以保证效率并支持后续更新。
第二阶段,GraphLocator 从第一阶段识别的症状顶点出发,逐步构建因果问题图(CIG)。CIG 是一个有向图,顶点表示从问题描述中衍生出的子问题,并与 RDFS 顶点对齐;边表示子问题之间的概率性因果依赖。构建过程由优先级驱动的扩展策略引导,以确保因果一致性。每一步中,选择优先级得分最高的子问题进行扩展,其得分定义为 Ψ(x)=1−∏(x,y)∈Y(1−ψ(x,y)),该得分反映子问题对其他问题的因果影响潜力,其中 ψ(x,y) 为大语言模型估计的 x 导致 y 的概率。扩展由 CausalAgent 执行,其采用图引导的溯因推理。给定待扩展的子问题,该智能体在 RDFS 中识别尚未访问的邻接代码顶点作为其直接因果候选。随后为大语言模型构建结构化提示,包含问题描述、上一轮迭代的 CIG 序列化结果(Mermaid 格式)、目标子问题及新观察到的节点列表。该提示使大语言模型能够评估每个候选是否构成合理原因或中间环节,从而更新 CIG,添加新的子问题与因果边。该迭代过程持续至达到最大轮次,最终生成显式建模从症状到根本原因因果链的 CIG。框架最终输出为需修改的代码实体集合,来源于与最终 CIG 中子问题对齐的 RDFS 顶点。
实验
-
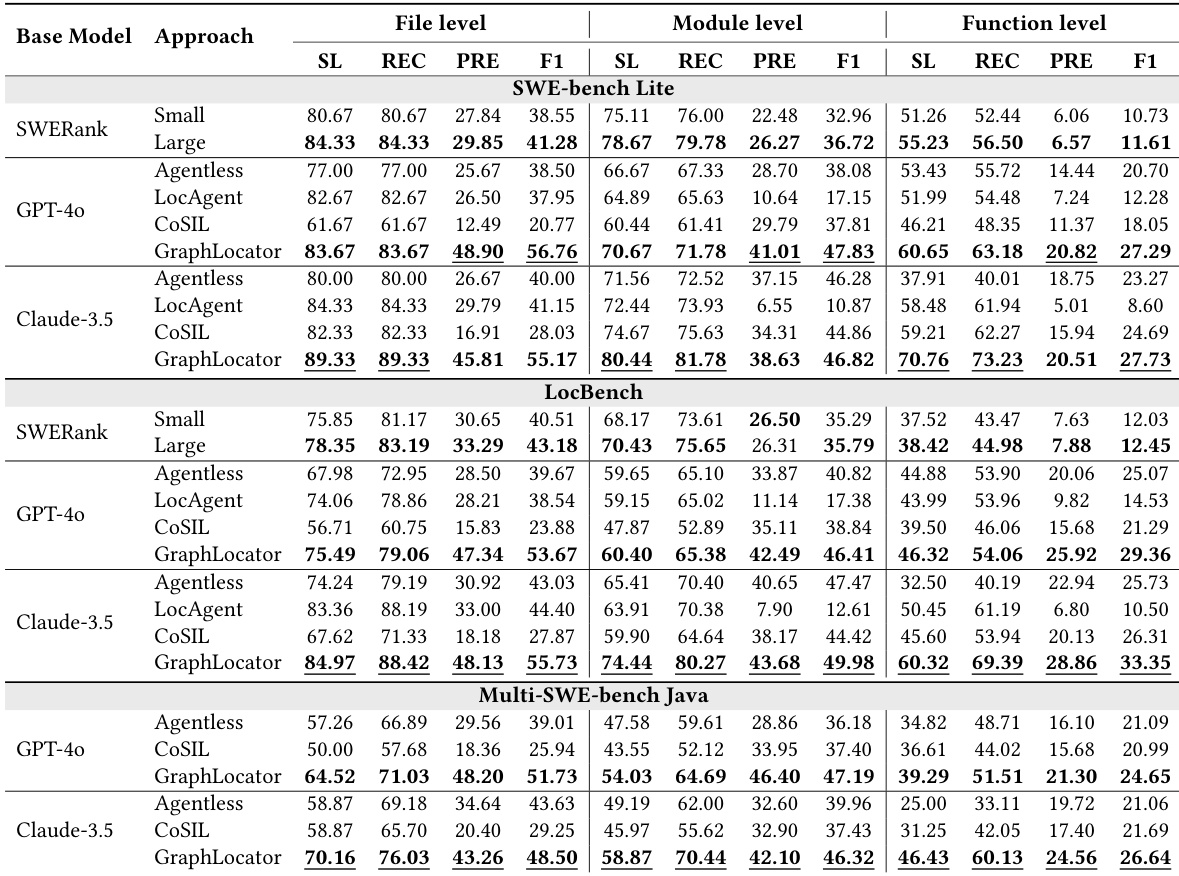
RQ1(有效性):GraphLocator 在 Python(SWE-bench Lite、LocBench)与 Java(Multi-SWE-bench Java)数据集上均优于基线,使用 GPT-4o 时函数级别 F1 分数最高提升21.33%,使用 Claude-3.5 时提升16.79%。通过因果图引导推理显著提升精确率(例如,使用 Claude-3.5 时函数级别精确率接近 LocAgent 的4倍),同时保持高召回率。在 SWE-bench Lite 与 LocBench 上,相比 SWERank-Large,函数级别 F1 提升15.68–21.32%,证明因果推理优于基于相似性的检索。
-
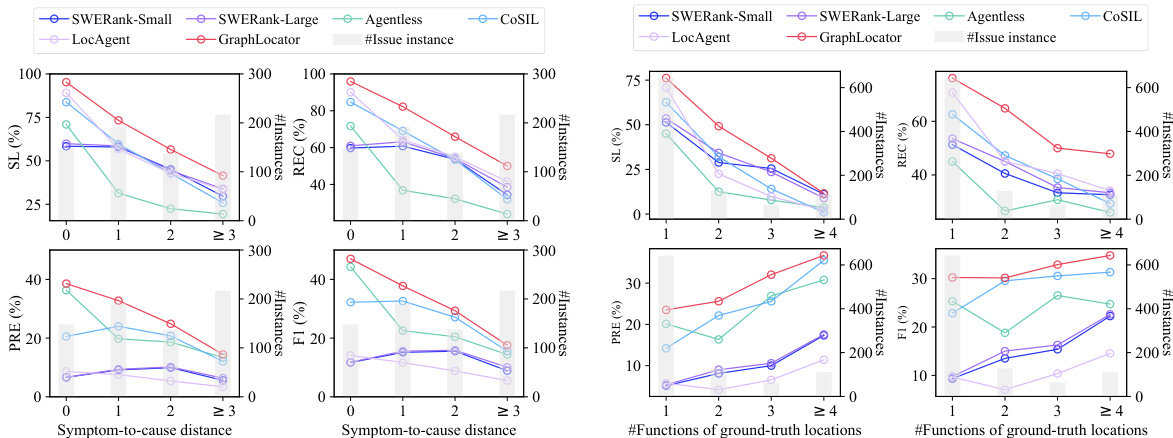
RQ2(泛化能力):GraphLocator 在任务复杂度增加时仍保持优越性能。在症状到原因距离方面,其在距离为0时达到最高召回率(95.59%),并在长距离情况下持续优于基线。在多函数问题上,其在召回率与精确率之间表现出最强的平衡性,优于 Agentless 与 LocAgent(随函数数量增加而急剧下降),也优于 CoSIL(以牺牲召回率为代价换取精确率)。
-
RQ3(消融实验):移除任意关键组件——searchVertex、searchEdge、优先队列或 CIG 引导——均显著降低性能。无 searchVertex 时,函数级别 F1 从30.91%降至14.23%;缺乏 CIG 引导或优先级驱动扩展时,精确率与召回率均下降,证实各组件在有效定位中的关键作用。
-
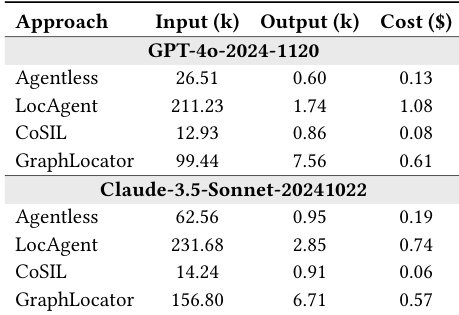
RQ4(成本):GraphLocator 实现高效图构建,在仓库函数数超过20时,时间性能优于 LocAgent(得益于懒加载)。相比 LocAgent,其输入 token 消耗减少52.9%(GPT-4o)与32.3%(Claude-3.5),成本最高降低43.5%,同时保持强准确性。
-
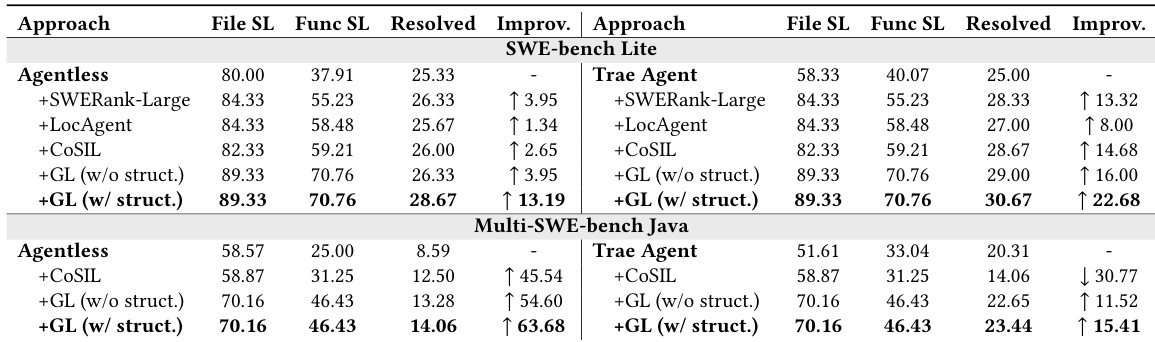
下游影响:将 GraphLocator 集成至 Trae Agent 与 Agentless 框架后,问题修复率显著提升,其中 Mermaid 序列化的 CIG 提供最高增益(如在 SWE-bench Lite 上提升+5.67%),证实结构化因果上下文能有效增强下游推理能力。
作者通过将 GraphLocator 集成至两个框架 Agentless 与 Trae Agent,评估其对下游问题修复的影响,并在 SWE-bench Lite 与 Multi-SWE-bench Java 上测量修复率。结果表明,GraphLocator 相较基线持续提升修复率,尤其在使用结构化 CIG 表示时提升最为显著,表明显式因果关系能增强大语言模型生成正确修复的能力。
结果表明,GraphLocator 在 Python 与 Java 数据集上均持续优于所有基线方法,在症状到原因距离增加及真实函数数量增长时,始终取得最高 F1 分数,并保持优异的精确率与召回率。在更细粒度层级上,性能差距进一步扩大,表明 GraphLocator 的图引导因果推理在复杂、多步定位任务中尤为有效。
结果表明,GraphLocator 在所有数据集与粒度层级上均持续优于所有基线方法,在文件级、模块级与函数级均取得最高 F1 分数。其显著提升了精确率,尤其在函数级表现突出,同时保持高召回率,充分证明其图引导因果推理的有效性。
结果表明,GraphLocator 在 token 消耗与成本方面显著低于 LocAgent,使用 GPT-4o 时输入 token 减少52.9%,成本降低43.5%,同时保持竞争力性能。其 token 消耗也低于 Agentless 与 CoSIL,展现出效率与准确性的良好权衡。
作者通过消融实验评估 GraphLocator 中各组件的贡献。结果表明,移除任意关键组件(如 search_vertex、search_edge、优先队列或 CIG 引导推理)均在所有粒度层级上显著降低性能,表明各组件对有效问题定位均不可或缺。
