Command Palette
Search for a command to run...
基于超图记忆的多步RAG在长上下文复杂关系建模中的优化
基于超图记忆的多步RAG在长上下文复杂关系建模中的优化
Chulun Zhou Chunkang Zhang Guoxin Yu Fandong Meng Jie Zhou Wai Lam Mo Yu
摘要
多步检索增强生成(Multi-step Retrieval-Augmented Generation, RAG)已成为提升大语言模型(Large Language Models, LLMs)在需要全局理解与深度推理任务中表现的广泛采用策略。许多RAG系统引入了工作记忆模块,用于整合检索到的信息。然而,现有记忆设计主要作为被动存储机制,仅将孤立的事实累积起来,以压缩长输入并基于演绎生成新的子查询。这种静态结构忽视了原始事实之间至关重要的高阶关联,而这些关联的组合往往能为后续步骤提供更强的指导作用。因此,其表征能力与在多步推理及知识演化中的影响力受限,导致在长上下文场景下推理过程碎片化,全局语义理解能力较弱。为此,我们提出HGMem——一种基于超图(hypergraph)的记忆机制,将记忆的概念从简单的存储拓展为支持复杂推理与全局理解的动态、高表达力结构。在本方法中,记忆以超图形式表示,其中超边对应不同的记忆单元,从而支持记忆内部高阶交互的渐进式构建。该机制能够连接围绕核心问题的事实与思维,逐步演化为一个整合且情境化的知识结构,为后续步骤的深度推理提供有力的命题支撑。我们在多个专为全局语义理解设计的挑战性数据集上对HGMem进行了评估。大量实验与深入分析表明,所提方法在多步RAG任务中持续提升性能,并在多种任务上显著超越多个强基线系统。
一句话总结
香港中文大学与微信 AI 的研究人员引入了 HGMEM,这是一种基于超图的内存机制,通过动态建模事实间的高阶关联来增强多步检索增强生成。该方法将内存演变为集成的知识结构,在全局理解任务中优于基线系统。
主要贡献
- 多步 RAG 系统通常依赖静态工作内存被动存储孤立事实,无法捕捉信息间的高阶关联,导致在长上下文任务中推理碎片化。
- 作者引入 HGMEM,一种基于超图的内存机制,其中超边形成动态、高阶的交互,使内存演变为集成的知识结构,指导后续推理步骤。
- 在具有挑战性的全局理解数据集上的实验表明,HGMEM 持续提升多步 RAG 的性能,并在多种任务中大幅超越强基线系统。
引言
多步 RAG 系统已演进为使用工作内存跟踪推理,部分系统采用图结构来表示知识。然而,这些基于图的方法局限于建模实体间的二元关系,限制了其捕捉复杂、多路连接的能力,而这种连接对于深度、全局推理至关重要。为此,作者引入 HGMEM,一种新颖的基于超图的工作内存机制。其主要贡献在于构建了一个在查询执行过程中动态演进其内存的系统,能够灵活建模高阶、n 元关系,从而显著增强大语言模型(LLM)的推理能力。
数据集
-
数据集构成与来源:作者在两类需要长上下文全局理解的任务上评估其模型:生成式理解问题解答和长叙事理解。对于生成式理解问答,他们使用 Longbench V2 的过滤子集,保留来自金融、政府和法律领域超过 10 万个词元的文档。对于长叙事理解,他们利用三个公开基准:NarrativeQA、NoCha 和 Prelude。
-
各子集关键细节:
- 生成式理解问答:该子集源自 Longbench V2。作者筛选出超过 10 万个词元的单文档问答文档。他们使用 GPT-4o 为这些文档生成全局理解查询,确保查询需要对整个上下文进行高级理解和推理,而非聚焦于特定短语。
- 长叙事理解:该数据来自三个已建立的基准。
- NarrativeQA:作者从基准中随机抽取 10 本长书(超过 10 万个词元)及其相关查询。
- NoCha:他们使用该基准公开发布的子集,其中包含关于虚构书籍的真假声明对。
- Prelude:他们使用该基准中包含的所有英文书籍,用于测试角色前传与原创故事之间的一致性。
-
论文如何使用数据:论文将此数据用于评估,而非训练。作者评估其模型在这些任务上的表现,以证明其处理长文档中复杂多步检索和推理的能力。选择这些数据集 specifically 是因为它们要求模型从长上下文的不同部分综合信息,这与论文对复杂关系建模的关注相一致。
-
处理及其他细节:论文的核心方法论假设文档在使用前已预处理为图结构。文档
D被分割为文本块,并构建一个图G,其中节点代表实体,边代表关系。每个节点和边都链接到其源文本块,并且所有组件(节点、边和块)都被嵌入以用于基于向量的检索。这使得模型在检索增强生成过程中能够访问原始文本和结构化图。
方法
作者利用一个由基于超图的内存机制(称为 HGMEM)增强的多步检索增强生成(RAG)框架,来支持长上下文的复杂推理。整个系统以迭代步骤运行,其中大语言模型(LLM)与外部知识源(包括文档语料库 D 和知识图 G)交互,同时维护和演进一个工作内存 M。在每个步骤 t,LLM 评估当前内存 M(t) 是否足以回答目标查询 q^。如果不足,它会生成一组子查询 Q(t) 以指导进一步检索。这些子查询通过基于向量的相似性匹配(如公式 1 所定义)用于从 VG 中获取相关实体,其关联的关系和文本块则通过基于图的索引检索。检索到的信息随后被整合到内存中,通过 LLM 驱动的过程将其演变为 M(t+1),如公式 2 所形式化。
请参阅框架图,该图说明了在第 t 步的完整交互循环。LLM 根据当前内存状态在局部调查和全局探索之间做出决定。在局部调查中,子查询针对特定的内存点,检索被限制在与这些点相关的锚点顶点的邻域内。在全局探索中,子查询旨在发现当前内存范围之外的新信息,从 VG 中 VM(t) 的补集中检索实体。检索到的实体、关系和文本块随后被反馈给 LLM 以进行内存整合。
内存 M 被构建为一个超图 (VM,E~M),其中顶点 VM 对应于来自 VG 的实体,超边 E~M 代表内存点。每个顶点 vi 表示为 (Ωvient,Dvi),包含实体信息和关联的文本块。每条超边 e~j 表示为 (Ωe~jrel,Ve~j),其中 Ωe~jrel 是关系的描述,Ve~j 是从属顶点的集合。这种结构能够建模多个实体间的高阶关联,超越了二元图边的限制。
内存的动态演进涉及三种操作:更新、插入和合并。更新操作在不改变其从属实体的情况下,修订现有超边的描述。插入操作在检索到新的相关信息时,向内存添加新的超边。合并操作将两个或多个超边组合成一个更连贯的内存点,新的描述由 LLM 基于被合并点的描述和目标查询生成,如公式 3 所示。此过程允许内存逐步形成高阶、语义集成的知识结构。
如下图所示,内存通过这些操作从 M(t) 演变为 M(t+1)。该示例说明了对现有内存点的更新、新点的插入,以及随后将两个点合并为一个统一的、更全面的内存点。这种演进使系统能够捕捉复杂的关联模式,这对于全局理解至关重要。

当内存被认为是充足的或达到最大交互步骤时,LLM 生成最终响应。响应是使用所有内存点的描述和当前内存中所有实体的关联文本来生成的。用于内存演进操作(包括更新、插入和合并)的提示旨在指导 LLM 提取和组织有用信息,如提供的提示模板所示。来自 NarrativeQA 数据集的一个示例演示了完整的工作流程,其中内存通过迭代演进来完善理解并支持复杂推理,最终生成一个连贯且基于上下文的响应。

实验
- 主要实验将 HGMEM 与传统和多步 RAG 基线进行比较,包括 NaiveRAG、GraphRAG、LightRAG、HippoRAG v2、DeepRAG 和 ComoRAG,验证其在四个基准上的有效性。
- 在生成式理解问答上,使用 GPT-4o 评估 HGMEM 的全面性和多样性,而长叙事理解任务则使用 GPT-4o 判断的预测准确率。
- HGMEM 在所有数据集上持续优于所有比较方法。
- 在长叙事理解任务上,HGMEM 在步骤 t=3 时达到最佳性能,在所有步骤中都超越了 NaiveRAG 和 LightRAG。
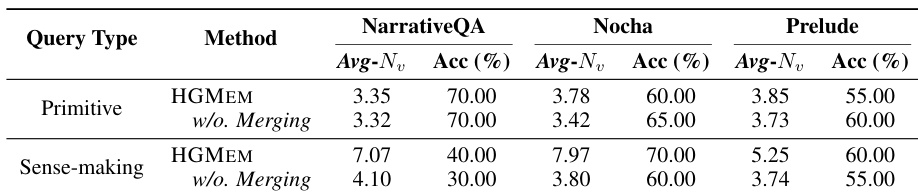
- 对原始查询和理解查询的针对性分析表明,HGMEM 通过形成高阶关联在理解查询上实现了更高的准确率,同时在原始查询上保持了可比的性能。
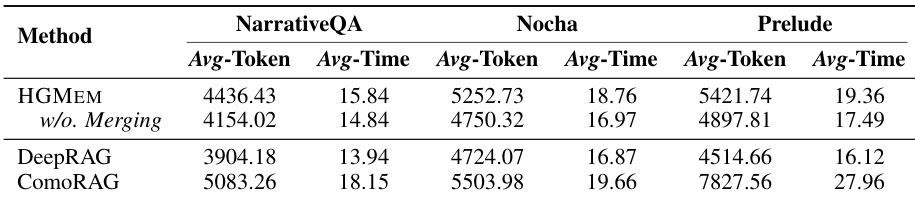
- HGMEM 在线多步 RAG 执行的成本与 DeepRAG 和 ComoRAG 相当,合并操作仅引入微小的计算开销。
- 案例研究表明,HGMEM 通过形成高阶关联和使用基于自适应内存的证据检索,实现了更深入、更准确的上下文理解。
作者使用两个 LLM(GPT-4o 和 Qwen2.5-32B-Instruct),在四个基准上将他们提出的 HGMEM 方法与传统和多步 RAG 基线进行比较。结果表明,HGMEM 在所有指标(包括全面性、多样性和准确率)上持续获得最高分,无论是否使用工作内存,均超越所有基线。性能提升在需要深度推理的复杂任务中尤为明显,其中 HGMEM 在内存中形成高阶关联的能力带来了更准确、更全面的回答。
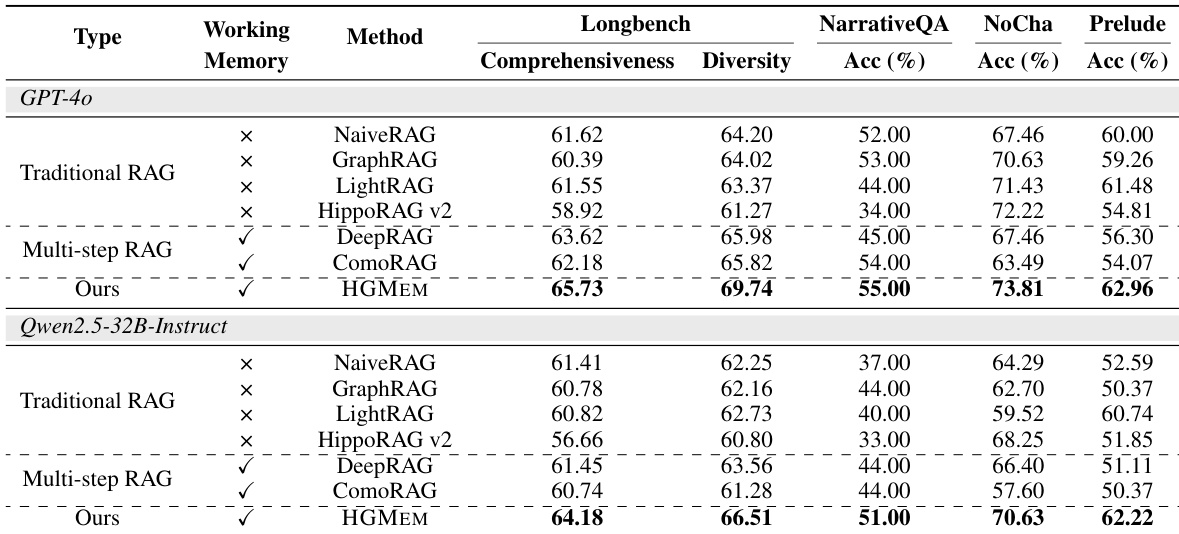
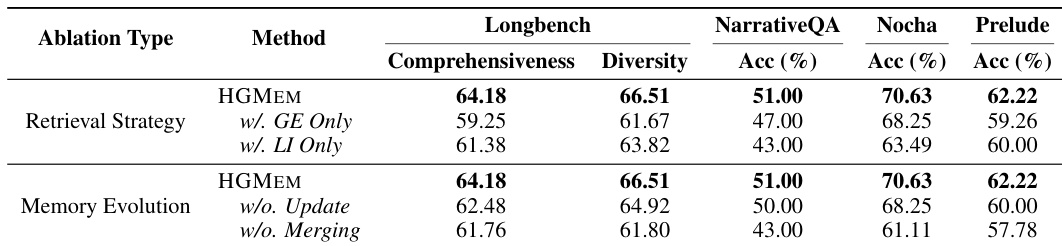
作者使用消融研究来评估 HGMEM 框架中不同组件的影响,重点关注检索策略和内存演进。结果表明,移除全局证据(GE)或局部调查(LI)检索策略会导致所有基准的性能显著下降,而禁用内存更新或合并操作也会降低性能,尤其是在 NarrativeQA 和 Prelude 上,这表明检索机制和内存演进对 HGMEM 的有效性都至关重要。
作者比较了 HGMEM 与 DeepRAG 和 ComoRAG 的计算成本,重点关注在线多步 RAG 执行期间的平均词元消耗和推理延迟。结果表明,HGMEM 的成本在所有三个基准上与 DeepRAG 和 ComoRAG 相当,仅合并操作带来微小的开销,同时持续实现更优的性能。
作者分析了 HGMEM 在三个数据集上针对原始查询和理解查询的性能,测量预测准确率和每个超边的平均实体数(Avg-Nv)作为关系复杂度的指标。结果表明,在理解查询上,HGMEM 实现了更高的准确率,并且与不合并的 HGMEM 相比,Avg-Nv 显著更大,这表明形成高阶关联改善了复杂推理任务的理解。相比之下,对于原始查询,HGMEM 产生与不合并版本相当或略低的准确率,可能是由于冗余的证据关联,而 Avg-Nv 仍略高。