HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

MEM1:学习协同记忆与推理以实现高效长时程Agent

AI-Trader:在实时金融市场的自主Agent基准测试



























MEM1:学习协同记忆与推理以实现高效长时程Agent
AI-Trader:在实时金融市场的自主Agent基准测试
潜在隐式视觉推理
LLM人格作为方法基准测试中实地实验的替代方案
DataFlow:一种面向以数据为中心的人工智能时代的统一数据准备与工作流自动化框架
HiStream:通过冗余消除流式传输实现高效高分辨率视频生成
TokSuite:衡量分词器选择对语言模型行为的影响
Nemotron 3 Nano:面向智能体推理的开源、高效混合专家Mamba-Transformer模型
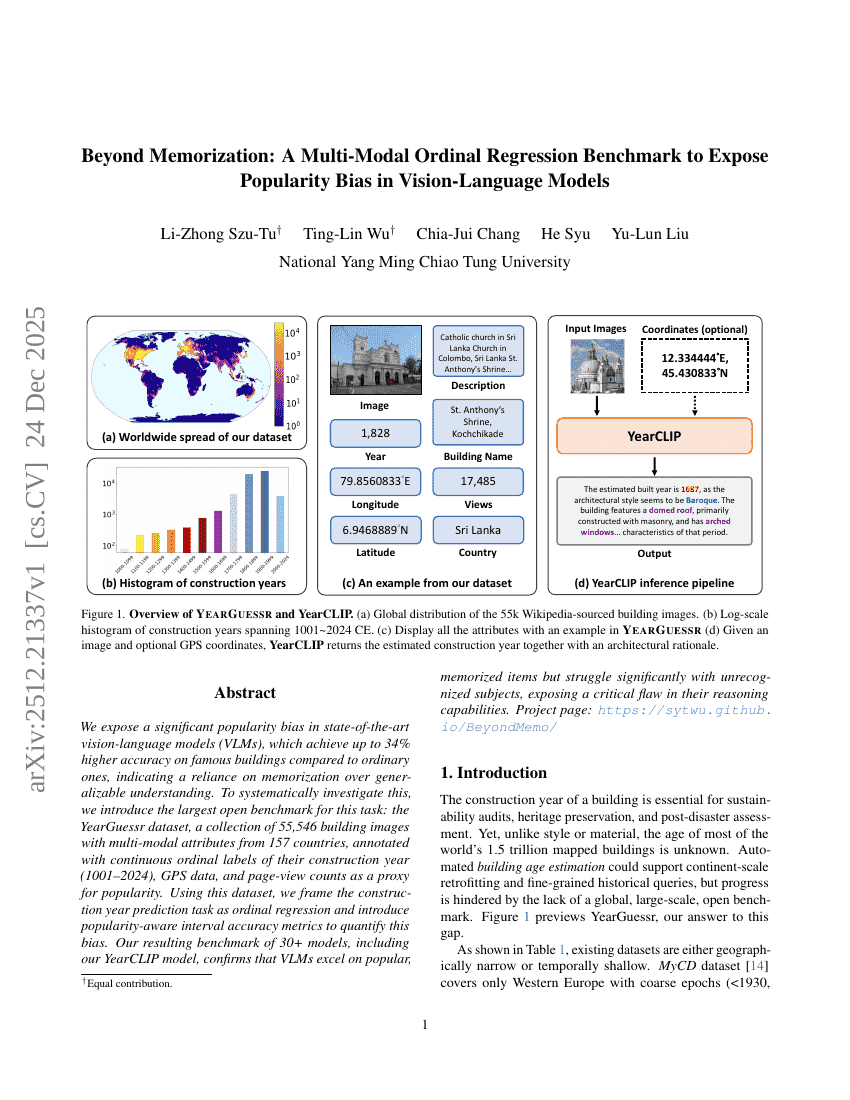
超越记忆:一种多模态序数回归基准以揭示视觉-语言模型中的流行度偏差
DreaMontage:任意帧引导的单次视频生成
T2AV-Compass:面向文本到音频视频生成的统一评估
TongSIM:一种用于模拟智能机器的通用平台
Qwen-Image-Layered:通过层分解实现固有可编辑性
RoboSafe:通过可执行安全逻辑保障具身Agent的安全
NHS基层医疗中LLM药物安全审查的现实世界评估
多LLM主题分析结合双重可靠性度量:基于Cohen's Kappa与语义相似性的定性研究验证
通过闭环世界建模实现视频虚拟人中的主动智能
FaithLens:检测与解释忠实性幻觉
SAM Audio:音频中的任意分割
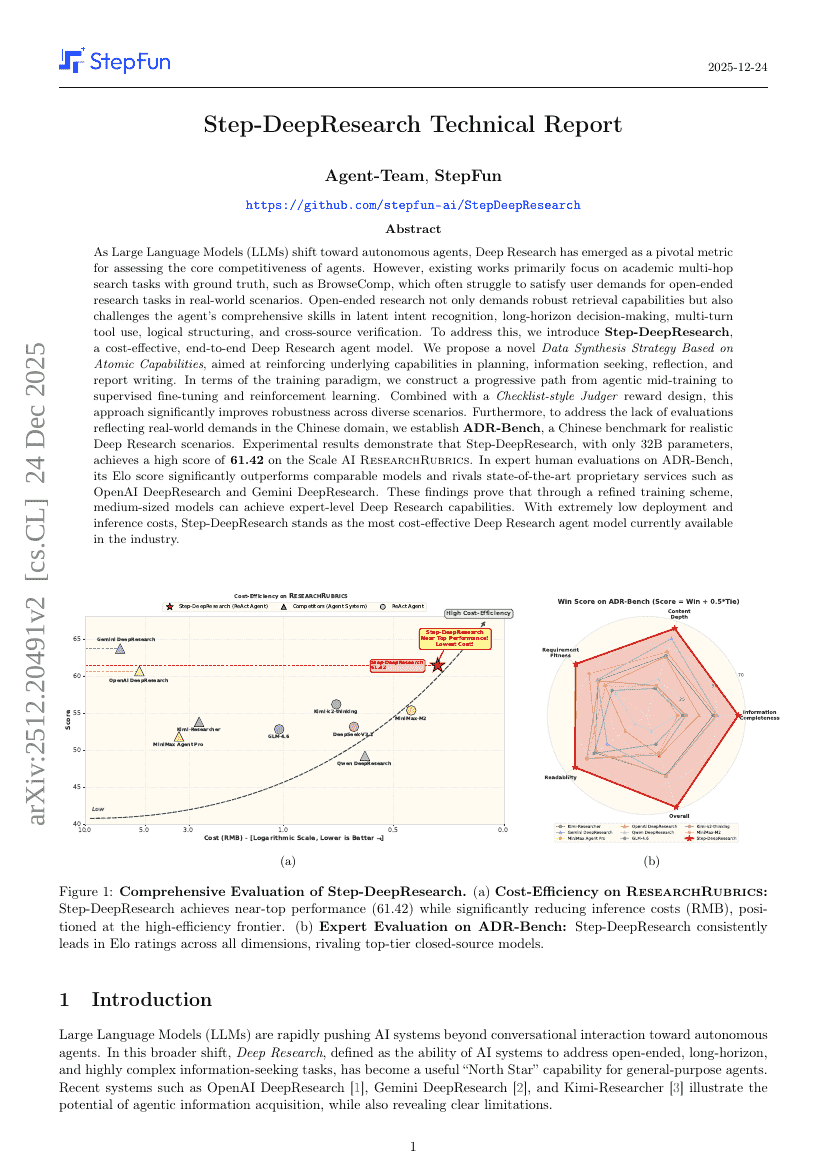
Step-DeepResearch 技术报告
SpatialTree:空间能力在MLLMs中的分支发展
SemanticGen:语义空间中的视频生成
基于人机协同推理大型语言模型Agent的自动化立体定向放射外科计划
LongVideoAgent:基于长视频的多Agent推理
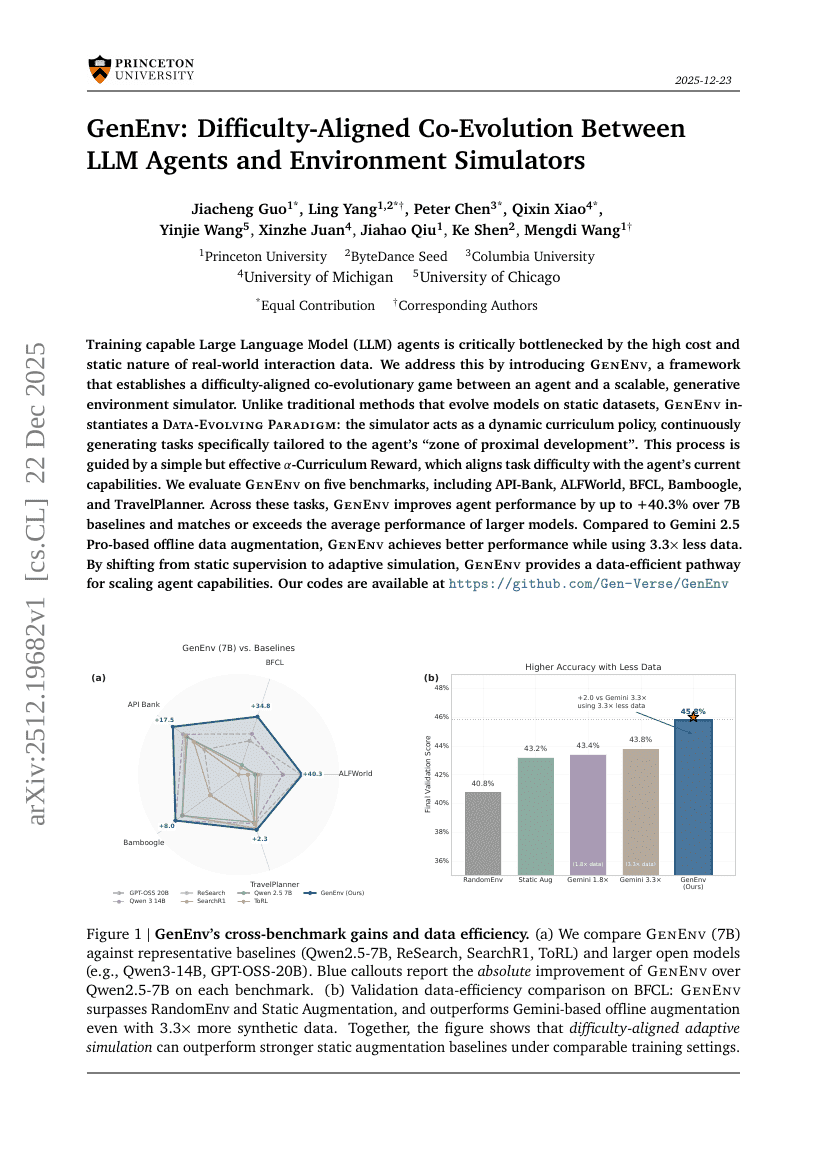
GenEnv:LLM Agent 与环境模拟器之间的难度对齐协同进化
WorldWarp:基于异步视频扩散的3D几何传播
LoGoPlanner:基于定位的度量感知视觉几何导航策略
LLM能否评估学生困难?基于能力模拟的师生AI难度对齐在题目难度预测中的应用
QuCo-RAG:基于预训练语料库量化不确定性以实现动态检索增强生成
棱镜假说:通过统一自编码实现语义与像素表征的融合
Med-Banana-50K:用于文本引导的医学图像编辑的跨模态大规模数据集
Kascade:一种面向长上下文LLM推理的实用稀疏注意力方法
潜在隐式视觉推理
LLM人格作为方法基准测试中实地实验的替代方案
DataFlow:一种面向以数据为中心的人工智能时代的统一数据准备与工作流自动化框架
HiStream:通过冗余消除流式传输实现高效高分辨率视频生成
TokSuite:衡量分词器选择对语言模型行为的影响
Nemotron 3 Nano:面向智能体推理的开源、高效混合专家Mamba-Transformer模型
超越记忆:一种多模态序数回归基准以揭示视觉-语言模型中的流行度偏差
DreaMontage:任意帧引导的单次视频生成
T2AV-Compass:面向文本到音频视频生成的统一评估
TongSIM:一种用于模拟智能机器的通用平台
Qwen-Image-Layered:通过层分解实现固有可编辑性
RoboSafe:通过可执行安全逻辑保障具身Agent的安全
NHS基层医疗中LLM药物安全审查的现实世界评估
多LLM主题分析结合双重可靠性度量:基于Cohen's Kappa与语义相似性的定性研究验证
通过闭环世界建模实现视频虚拟人中的主动智能
FaithLens:检测与解释忠实性幻觉
SAM Audio:音频中的任意分割
Step-DeepResearch 技术报告
SpatialTree:空间能力在MLLMs中的分支发展
SemanticGen:语义空间中的视频生成
基于人机协同推理大型语言模型Agent的自动化立体定向放射外科计划
LongVideoAgent:基于长视频的多Agent推理
GenEnv:LLM Agent 与环境模拟器之间的难度对齐协同进化
WorldWarp:基于异步视频扩散的3D几何传播
LoGoPlanner:基于定位的度量感知视觉几何导航策略
LLM能否评估学生困难?基于能力模拟的师生AI难度对齐在题目难度预测中的应用
QuCo-RAG:基于预训练语料库量化不确定性以实现动态检索增强生成
棱镜假说:通过统一自编码实现语义与像素表征的融合
Med-Banana-50K:用于文本引导的医学图像编辑的跨模态大规模数据集
Kascade:一种面向长上下文LLM推理的实用稀疏注意力方法